架构思维:利用全量缓存架构构建毫秒级的读服务
文章目录
- 一、引言
- 二、全量缓存架构概述
- 三、基于 Binlog 的缓存同步方案
- 1. Binlog 原理
- 2. 同步中间件
- 3. 架构整合
- 核心收益
- 四、Binlog 全量缓存的优缺点与优化
- 优点
- 缺点与取舍
- 优化策略
- 五、其他进阶优化点
- 六、总结

一、引言
架构思维:使用简洁的架构实现高性能读服务介绍了介绍了懒加载读服务架构及其四大挑战,其中两大难题尚未彻底解决:
- 分布式事务——写操作后缓存更新的事务一致性风险;
- 性能毛刺——缓存过期瞬间穿透到数据库带来的延迟洪峰。
接下来将带来 全量缓存 方案:在缓存中存储数据库所有热点数据,无需降级到数据库,从根本上消除毛刺,并通过 Binlog 同步解决事务一致性问题。
二、全量缓存架构概述
全量缓存即在 缓存中保留数据库中所有 需要高性能读取的数据,并不设置过期。
其架构示意如下:
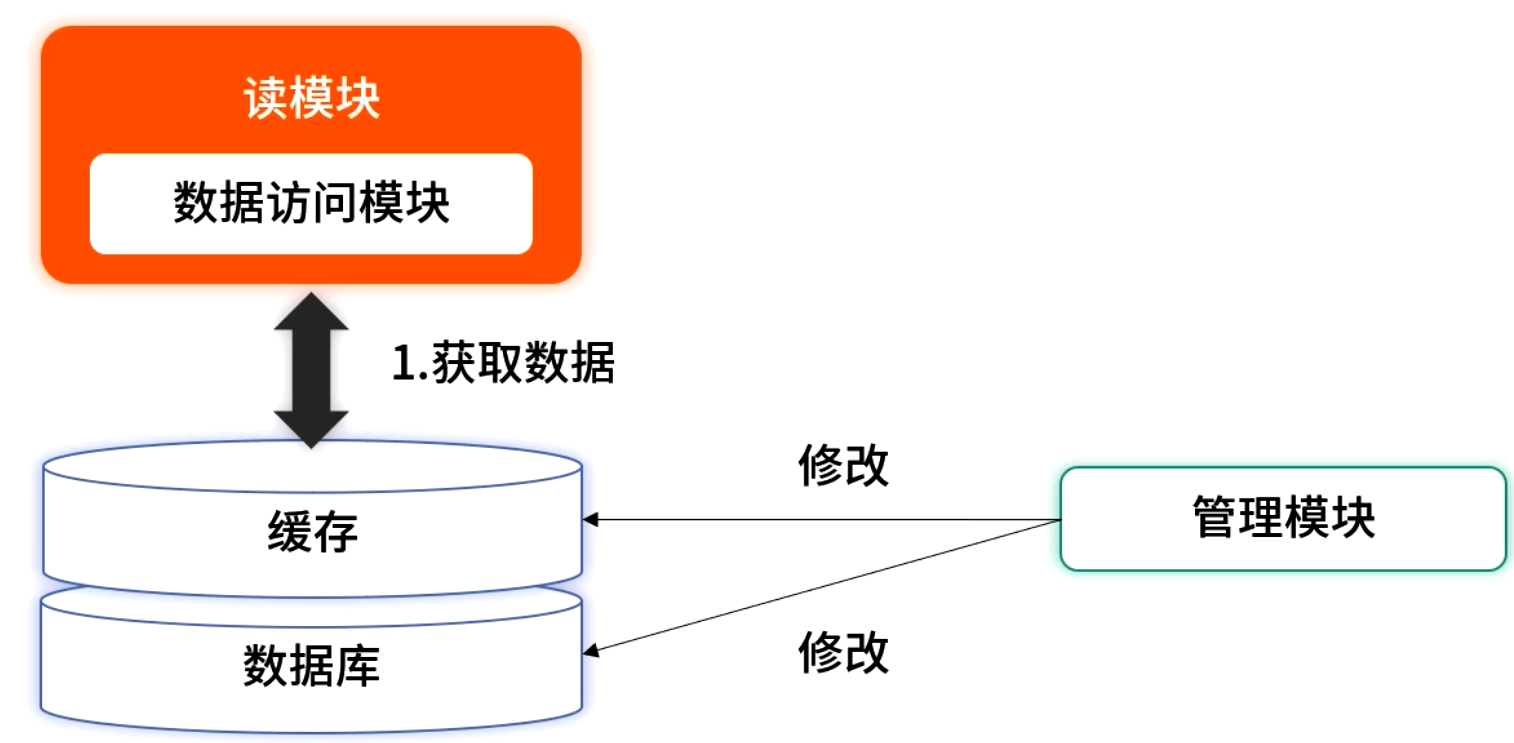
-
读流程:所有读请求只访问缓存,零数据库依赖 → 毛刺消失;
-
写流程:写入数据库后,需确保同样更新至缓存;
这实现了平均延迟可控在 100 ms 内的目标,但对缓存更新一致性提出了更高要求,也带来了新的技术挑战。
三、基于 Binlog 的缓存同步方案
1. Binlog 原理
MySQL 等主流数据库使用 Binlog 完成主从复制:
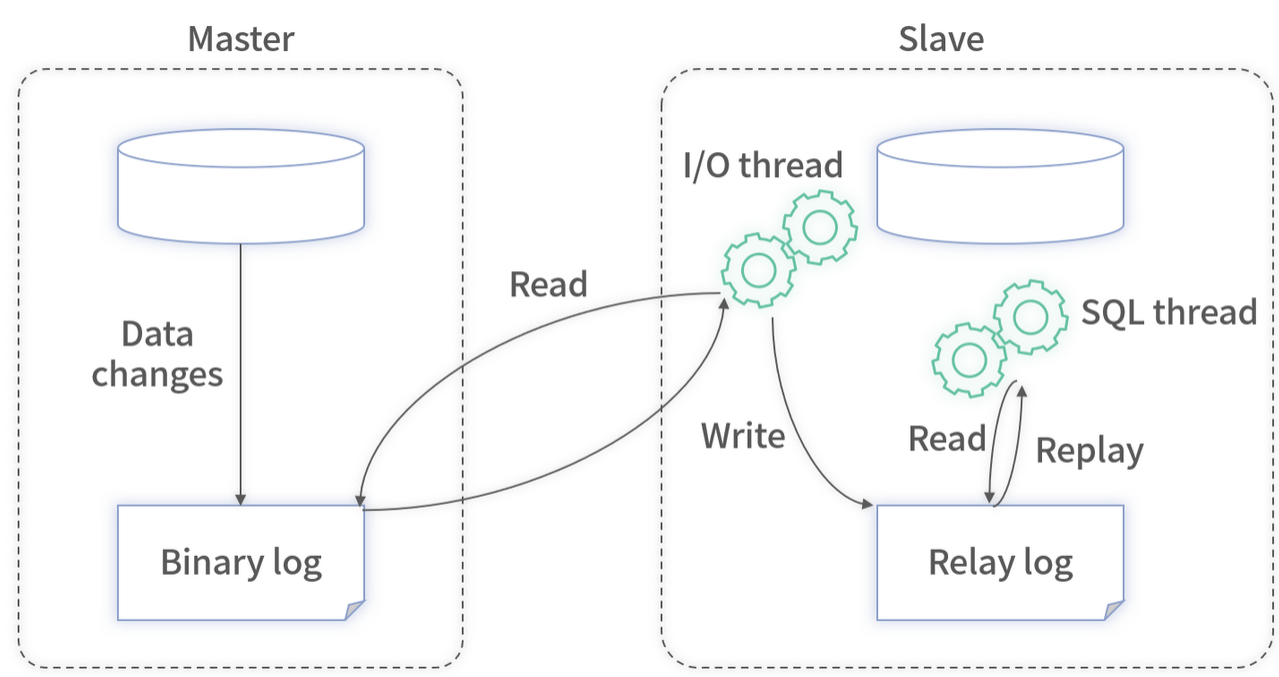
- 主库:将所有 DML 写入本地 Binlog 文件;
- 从库:通过复制协议读取并回放主库 Binlog;
2. 同步中间件
借助开源工具(Canal、Maxwell、MySQL_Streamer 等)模拟从库协议,从主库实时消费 Binlog,并将增量写入下游系统。
3. 架构整合
把 Binlog 消费端与缓存写入结合,构建如下全链路:

- 写操作 → 数据库持久化 → Binlog 生成 → 中间件消费 → 缓存更新。
核心收益
- 准实时更新:主从延迟在毫秒级;
- 最终一致性保障:消费失败不 ACK,自动重试 → 零丢数据; 解决了分布式事务的问题 , Binlog 的主从复制是基于 ACK 机制,如果同步缓存失败了,被消费的 Binlog 不会被确认,下一次会重复消费,数据最终会写入缓存中。这就解决了因无法满足分布式事务而导致的丢数据问题,保障了数据的最终一致性。
- 维护成本低:所有写接口无需主动嵌入缓存逻辑,只需维护 Binlog 解析程序。
四、Binlog 全量缓存的优缺点与优化
优点
- 消除毛刺:无缓存穿透至数据库;
- 事务一致性:借助 ACK 重试保证最终一致;
- 简化代码:写业务无需关心缓存更新。
缺点与取舍
-
系统复杂度上升
- 新增 Binlog 中间件 → 监控、运维成本增加;
-
缓存容量激增
- 全量数据驻留,资源成本高。
优化策略
-
业务筛选:只缓存“有查询价值”字段,剔除记录性字段(创建时间、修改人等);
-
数据压缩:
- JSON 序列化时用短字段标识(
{"1":…,"2":…}); - Redis Hash Field 同样可用短标识;
- JSON 序列化时用短字段标识(
-
异步校准:对极端丢缓存场景,配合 MQ 异步补齐:
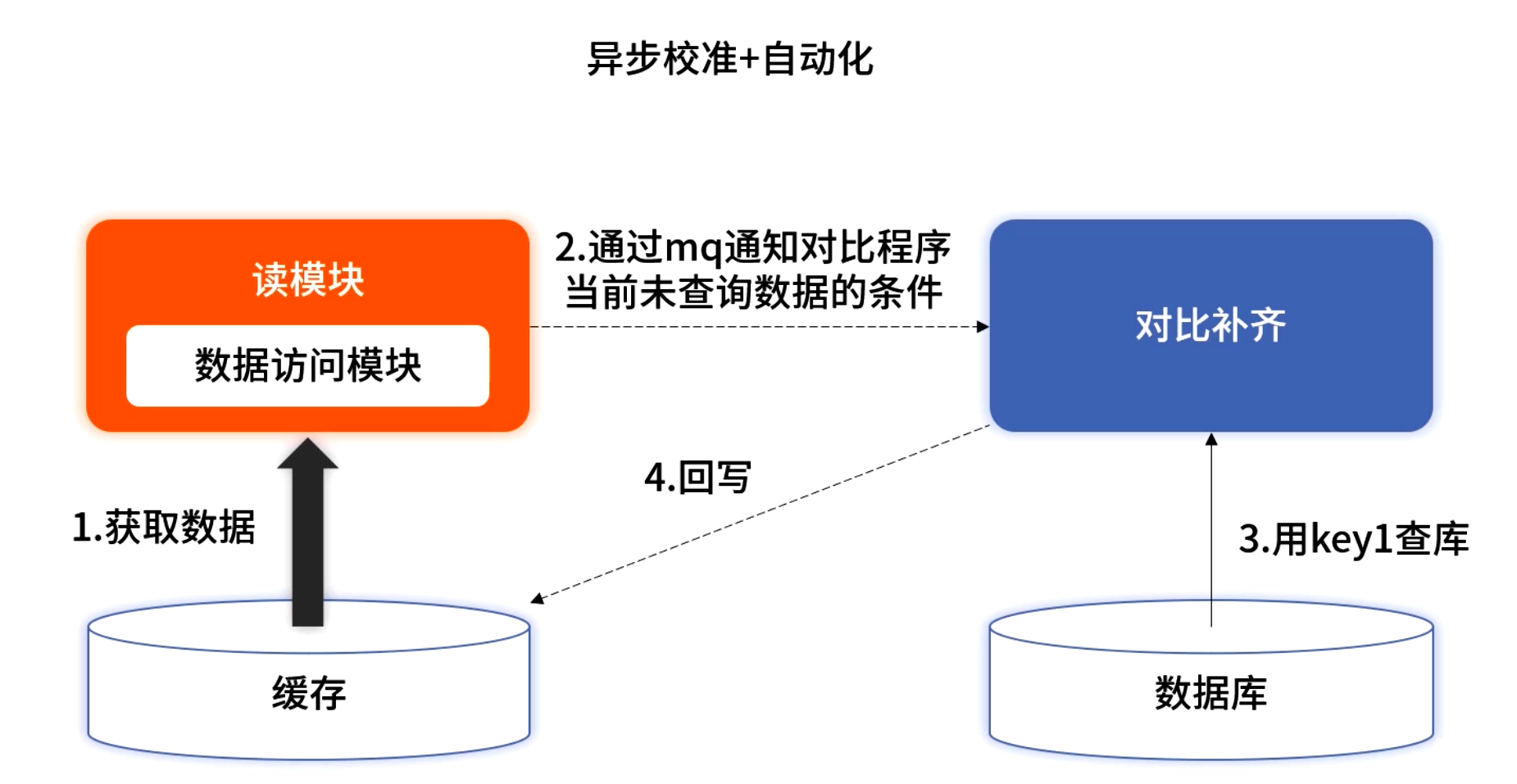
- 缓存未命中即返回空结果;
- 同时发 MQ 请求校验数据库并补入缓存;
- 实际生产可视业务价值和丢失概率决定取舍。
此方案是一个有损方案,如果数据在数据库中真实存在而在缓存中不存在,调用方第一次调用请求获取到的是空数据,那我们为什么还要使用此方案呢?
其实这种情况在现实场景中出现的概率极低。在实战经历里,在线上已经关闭了此异步校准方案,主要从以下 4 个方面来考虑。
- 根据数据统计, 数据在数据库中存在而在缓存中不存在的概率几乎为零。
- 对数据库大量无效的异步校准查询会导致数据库性能变差。
- 即使缓存里数据丢失,只要此条数据存在变更,Binlog 都会把它再次刷新至缓存里。如果此条数据一直不存在变更,说明它是死数据,价值也不会太大。
- 如果将此方案应用到生产环境里,同时开启了异步校准,依然存在大量数据丢失的情况,那说明对于缓存中间件的使用和调优还有很大的提升空间。毕竟,此类数据丢失大多都是中间件自身导致的。我们不应该本末倒置,为了弥补缓存中间件的问题,而让业务团队做太多的补偿工作。
五、其他进阶优化点
-
多机房热备
- 双集群部署于不同机房,各自写入 → 本地读取 → 秒级切换故障域;
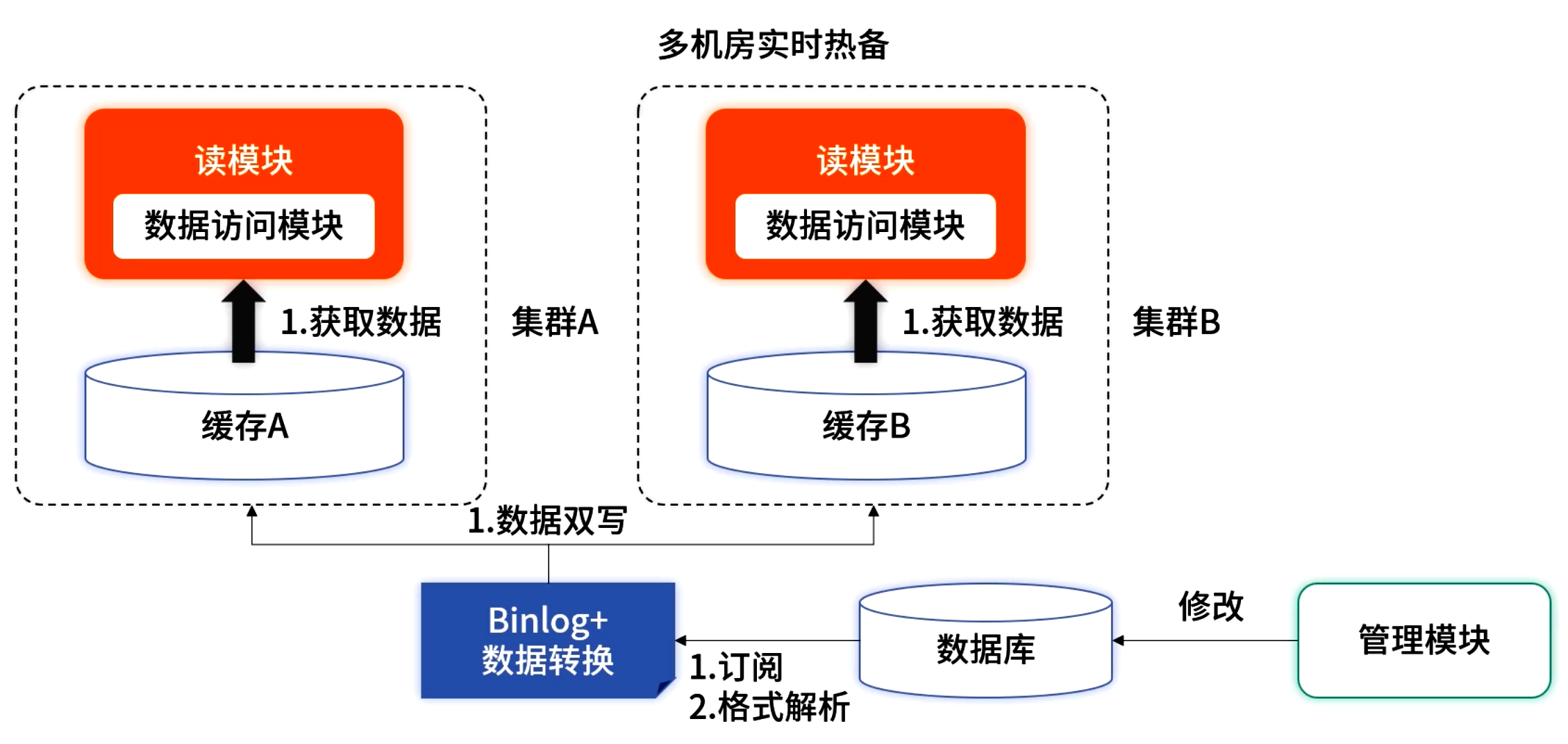
- 双集群部署于不同机房,各自写入 → 本地读取 → 秒级切换故障域;
-
异步并行化读
- 将多次存储交互并行化,缩短总时延;
- 适用于完全独立查询或批量拆分场景;
- 需权衡线程/CPU 开销与编程复杂度
六、总结
- 全量缓存 彻底消除毛刺,依赖 Binlog 保证数据最终一致;
- 同时需在系统复杂度与资源成本之间做平衡,并可结合压缩、筛选与异步校准等措施优化;
- 进阶可进一步利用机房热备和并行化提升性能与可用性。
