论文阅读笔记——STDArm
STDArm 论文
将静态转化为动态时,面临几个问题:1)推理延迟高;2)Action Chunk 的方式导致对环境响应能力差。过去的方法都采用减少扩散策略的去噪步数以提升整体推理频率(加速策略本身推理频率),STDArm 则采用动作管理器和 插值动作补偿。——相比于压缩算法,优化执行架构的方式也可以提升频率。(STDArm 部署在边缘设备 Jetson Xavier 上)

策略网络的输入是 m o m_o mo 步观测数据 O,末端执行器的位置坐标(u)。采用 ResNet18作为视觉骨干,然后接 DP, m o = 2 , m a @ 5 H z = 8 m_o =2,m_a@5Hz=8 mo=2,ma@5Hz=8(与 DP 原文一致)。
当策略网络 π \pi π 在 t 1 t_1 t1 时刻读取观测 O t 1 − m o + 1 : O t 1 O_{t_1-m_o+1}:O_{t_1} Ot1−mo+1:Ot1 ,经过 t I n f t_{Inf} tInf 时延后生成动作序列 u t 1 : u t 1 + m a u_{t_1}:u_{t_1+m_a} ut1:ut1+ma,动作管理器在 t 2 ≈ t 1 + t I n f t_2≈t_1+t_{Inf} t2≈t1+tInf 时刻将其与缓冲区 A \mathcal{A} A ( A = { A t , t ∈ N } \mathcal{A}=\{A_t,t\in N\} A={At,t∈N} 按序存储已执行动作和待执行动作)融合。
在 t 1 t_1 t1 与 t 2 t_2 t2 对齐的过程中,直接时间戳对齐会导致动作回溯,通过滑动窗口搜索最佳对齐位置:
t u = a r g m i n t ∑ k ∈ K d ( u t + k , A t 2 + k ) ∣ K ∣ , t ∈ [ t 2 − m s , t 2 + m s ] t_u = argmin_{t} \frac{\sum_{k\in K} d(u_{t+k}, A_{t2+k})}{|K|}, \quad t\in[t2-m_s,t2+m_s] tu=argmint∣K∣∑k∈Kd(ut+k,At2+k),t∈[t2−ms,t2+ms]
其中 d(·) 表示欧式距离,K 为 u 与 A的重叠区间, m s m_s ms 为预设搜设范围。
然后模仿 ACT 的设计,进行时序平滑:
A t 2 + k = { w o l d ⋅ A t 2 + k + w n e w ⋅ u t u + k , 0 ≤ k ≤ ∣ A ∣ − t 2 u t u + k , k > ∣ A ∣ − t 2 A_{t2+k} = \begin{cases} w_{old}·A_{t2+k} + w_{new}·u_{t_u+k}, & 0\leq k\leq |A|-t2 \\ u_{t_u+k}, & k > |A|-t2 \end{cases} At2+k={wold⋅At2+k+wnew⋅utu+k,utu+k,0≤k≤∣A∣−t2k>∣A∣−t2
w t + i n e w = exp ( − α i ) , i ∈ [ 1 , m a ] , w t o l d = w t o l d + w t n e w . \begin{aligned} & w_{t+i}^{\mathrm{new}}=\exp(-\alpha i),i\in[1,m_{a}], \\ & w_{t}^{\mathrm{old}}=w_{t}^{\mathrm{old}}+w_{t}^{\mathrm{new}}. \end{aligned} wt+inew=exp(−αi),i∈[1,ma],wtold=wtold+wtnew.
针对策略输出频率与执行需求之间差距,在相邻动作间实时插值: A τ = ( τ − t ) A t + ( t + 1 − τ ) A t + 1 , τ ∈ [ t , t + 1 ] A_τ = (τ-t)A_t + (t+1-τ)A_{t+1}, \quad τ\in[t,t+1] Aτ=(τ−t)At+(t+1−τ)At+1,τ∈[t,t+1]

在处理高频动作时,传统方法实时监测机械臂的运动并利用他们来细化动作,但由于计算、通信、控制延迟的问题,数据是过时的。设计了一个基于预测补偿的稳定器,预测平台在短时间内未来的运动,并修改动作以有效抵消运动。
采用实时高频 SLAM(立体相机+IMU)输出位姿序列,以当前位姿 p 0 p_0 p0 为基准坐标系,计算过去 l 0 l_0 l0 帧的相对位姿序列: Δ P − l 0 : − 1 = { Δ p − l 0 , … , Δ p − 1 } , Δ p − i = p 0 − 1 p − i \Delta P_{-l_0:-1} = \{\Delta p_{-l_0}, \dots, \Delta p_{-1}\}, \quad \Delta p_{-i} = p_0^{-1} p_{-i} ΔP−l0:−1={Δp−l0,…,Δp−1},Δp−i=p0−1p−i
预测网络采用 LSTM 与 GRU 并行处理输入,特征为维度拼接后经全连接层输出:(1.2ms,相比纯 LSTM 降低 37% 计算负载)
Δ P 1 : l 1 ∗ = M ( Δ P − l 0 : − 1 ) M ( x ) = FC ( concat ( LSTM ( x ) , GRU ( x ) ) ) \begin{aligned} \Delta P^*_{1:l_1} &= \mathcal{M}(\Delta P_{-l_0:-1}) \\ \mathcal{M}(x) &= \text{FC}(\text{concat}(\text{LSTM}(x), \text{GRU}(x))) \end{aligned} ΔP1:l1∗M(x)=M(ΔP−l0:−1)=FC(concat(LSTM(x),GRU(x)))
对于目标动作 A τ A_\tau Aτ ,计算由机器人运动引起的动作偏移量: δ ( τ , Δ t , E ) = E − 1 ( Δ p ⌈ − Δ t τ / f ⌉ − 1 Δ p ⌊ Δ t / f ⌋ ∗ ) − 1 E \delta(\tau, \Delta t, E) = E^{-1} \left( \Delta p^{-1}_{\lceil -\Delta t_\tau /f \rceil} \Delta p^*_{\lfloor \Delta t/f \rfloor} \right)^{-1} E δ(τ,Δt,E)=E−1(Δp⌈−Δtτ/f⌉−1Δp⌊Δt/f⌋∗)−1E
- E:视觉SLAM坐标系与机械臂坐标系的外参(预先标定);
- Δ t τ \Delta t_\tau Δtτ:策略网络生成 A τ A_\tau Aτ 到执行的时间间隔;
- f:SLAM系统输出频率;
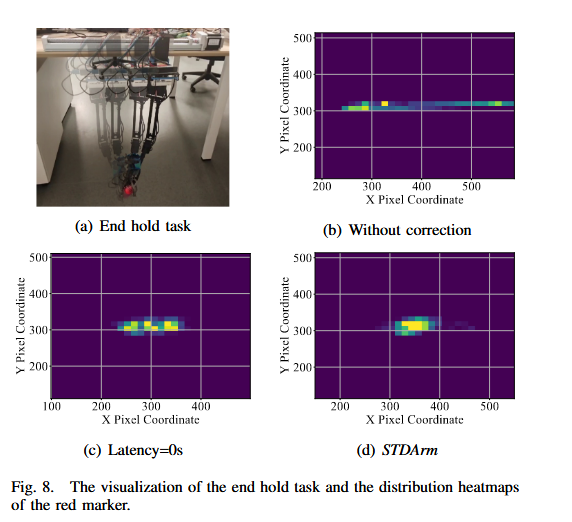
- Δt:位姿估计到动作执行的总延迟。采用从零开始的延迟线性搜索方法,将标记物移动最小时的延迟确定为系统延迟。为确保机器人运动变化不影响延迟估计的准确性,我们采用标记物像素平面运动速度与VSLAM估计平台运动速度之比作为评估指标。 ρ = ∥ v marker ∥ pixel ∥ v platform ∥ VSLAM \rho = \frac{\|v_{\text{marker}}\|_{\text{pixel}}}{\|v_{\text{platform}}\|_{\text{VSLAM}}} ρ=∥vplatform∥VSLAM∥vmarker∥pixel
补偿后的动作为: A τ ′ = δ ( τ , Δ t , E ) A τ A'_\tau = \delta(\tau, \Delta t, E) A_\tau Aτ′=δ(τ,Δt,E)Aτ
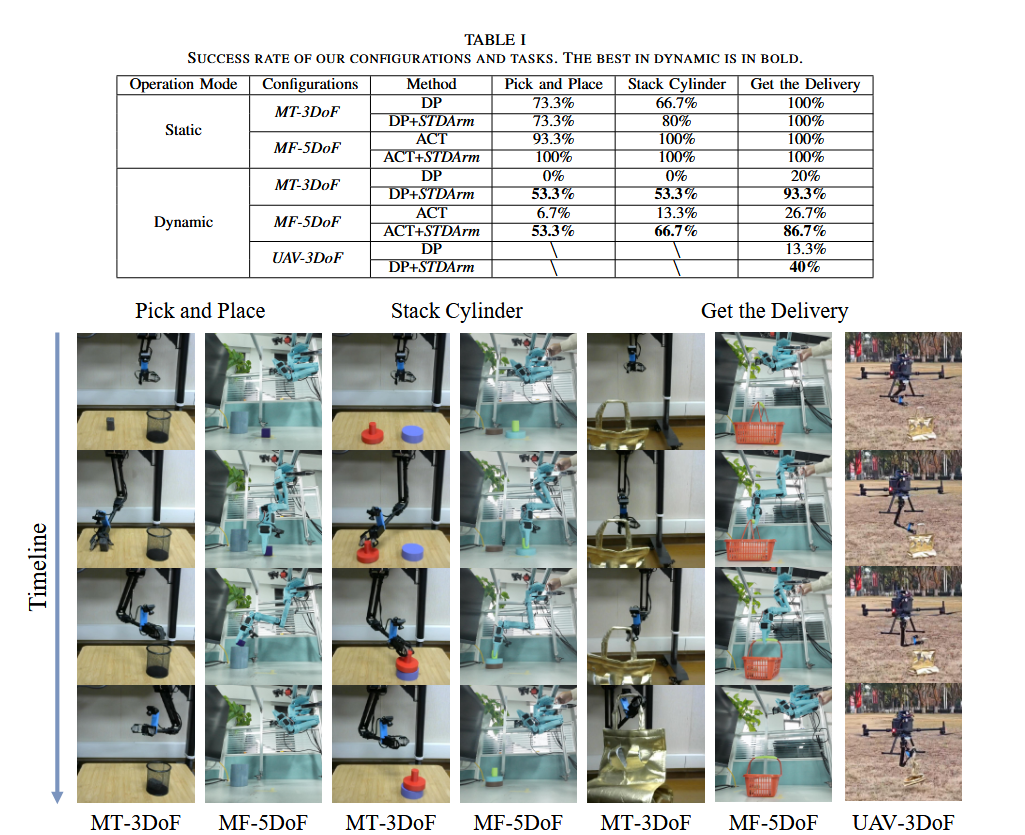
设计了三个任务,验证精度:
- 方块投放:抓取3cm宽度的木块并投入直径8cm的笔筒;
- 圆柱堆叠:将两个直径8cm的圆柱体垂直堆叠;
- 外卖取件:准确抓取外卖袋提手并完成提升动作。
实验结果