Milvus(12):分析器
1 分析器概述
在文本处理中,分析器是将原始文本转换为结构化可搜索格式的关键组件。每个分析器通常由两个核心部件组成:标记器和过滤器。它们共同将输入文本转换为标记,完善这些标记,并为高效索引和检索做好准备。
在 Milvus 中,创建 Collections 时,将VARCHAR 字段添加到 Collections Schema 时,会对分析器进行配置。分析器生成的标记可用于建立关键字匹配索引,或转换为稀疏嵌入以进行全文检索。
使用分析器可能会影响性能:
-
全文搜索:对于全文搜索,数据节点和查询节点通道消耗数据的速度更慢,因为它们必须等待标记化完成。因此,新输入的数据需要更长的时间才能用于搜索。
-
关键词匹配:对于关键字匹配,索引创建速度也较慢,因为标记化需要在索引建立之前完成。
1.1 分析器剖析
Milvus 的分析器由一个标记化器和零个或多个过滤器组成。
-
标记化器:标记器将输入文本分解为称为标记的离散单元。根据标记符类型的不同,这些标记符可以是单词或短语。
-
过滤器:可以对标记符进行过滤,进一步细化标记符,例如将标记符变成小写或删除常用词。
标记符仅支持 UTF-8 格式。未来版本将增加对其他格式的支持。下面的工作流程显示了分析器如何处理文本。
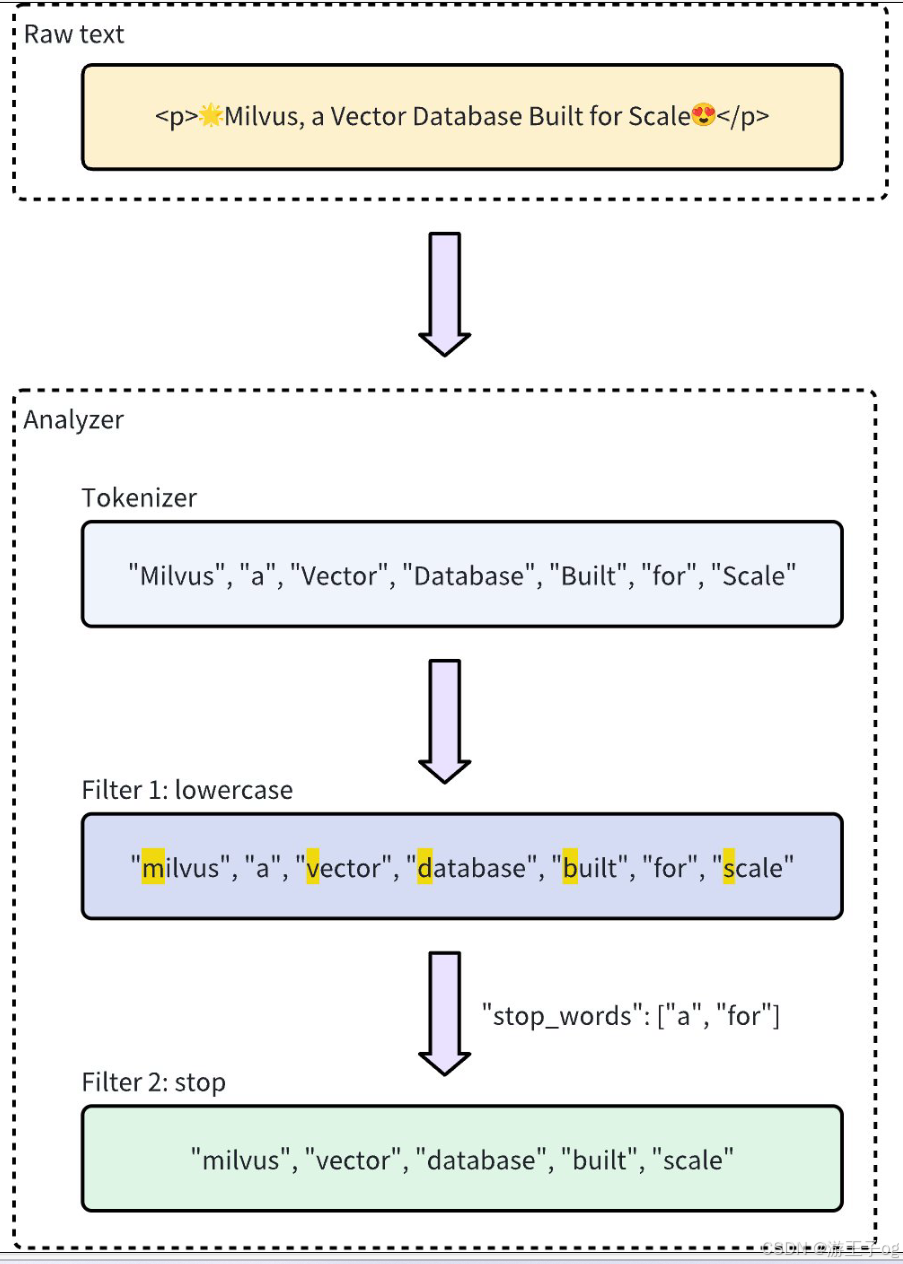
1.2 分析器类型
Milvus 提供两种类型的分析器,以满足不同的文本处理需求:
-
内置分析器:这些是预定义配置,只需最少的设置即可完成常见的文本处理任务。内置分析器不需要复杂的配置,是通用搜索的理想选择。
-
自定义分析器:对于更高级的需求,自定义分析器允许你通过指定标记器和零个或多个过滤器来定义自己的配置。这种自定义级别对于需要精确控制文本处理的特殊用例尤其有用。
如果在创建 Collections 时省略了分析器配置,Milvus 默认使用standard 分析器进行所有文本处理。
1.2.1 内置分析器
Milvus 中的内置分析器预先配置了特定的标记符号化器和过滤器,使你可以立即使用它们,而无需自己定义这些组件。每个内置分析器都是一个模板,包括预设的标记化器和过滤器,以及用于自定义的可选参数。
例如,要使用standard 内置分析器,只需将其名称standard 指定为type ,并可选择包含该分析器类型特有的额外配置,如stop_words :
analyzer_params = {"type": "standard", # 使用标准的内置分析器"stop_words": ["a", "an", "for"] # 定义要从标记化中排除的常用单词(停止词)列表
} 上述standard 内置分析器的配置等同于使用以下参数设置自定义分析器,其中tokenizer 和filter 选项是为实现类似功能而明确定义的:
analyzer_params = {"tokenizer": "standard","filter": ["lowercase",{"type": "stop","stop_words": ["a", "an", "for"]}]
}
Milvus 提供以下内置分析器,每个分析器都是为特定文本处理需求而设计的:
standard:适用于通用文本处理,应用标准标记化和小写过滤。english:针对英语文本进行了优化,支持英语停止词。chinese:专门用于处理中文文本,包括针对中文语言结构的标记化。
1.2.2 自定义分析器
对于更高级的文本处理,Milvus 中的自定义分析器允许您通过指定标记化器和过滤器来构建定制的文本处理管道。这种设置非常适合需要精确控制的特殊用例。
标记化器是自定义分析器的必备组件,它通过将输入文本分解为离散单元或标记来启动分析器管道。标记化遵循特定的规则,例如根据标记化器的类型用空白或标点符号分割。这一过程可以更精确、更独立地处理每个单词或短语。
例如,标记化器会将文本"Vector Database Built for Scale" 转换为单独的标记:
["Vector", "Database", "Built", "for", "Scale"]指定标记符的示例:
analyzer_params = {"tokenizer": "whitespace",
} 过滤器是可选组件,用于处理标记化器生成的标记,并根据需要对其进行转换或细化。例如,在对标记化术语["Vector", "Database", "Built", "for", "Scale"] 应用lowercase 过滤器后,结果可能是:
["vector", "database", "built", "for", "scale"]自定义分析器中的过滤器可以是内置的,也可以是自定义的,具体取决于配置需求。
-
内置过滤器:由 Milvus 预先配置,只需最少的设置。您只需指定过滤器的名称,就能立即使用这些过滤器。以下是可直接使用的内置过滤器:
-
lowercase:将文本转换为小写,确保不区分大小写进行匹配。 -
asciifolding:将非 ASCII 字符转换为 ASCII 对应字符,简化多语言文本处理。 -
alphanumonly:只保留字母数字字符,删除其他字符。 -
cnalphanumonly:删除包含除汉字、英文字母或数字以外的任何字符的标记。 -
cncharonly:删除包含任何非汉字的标记。
-
使用内置过滤器的示例:
analyzer_params = {"tokenizer": "standard", # 必选:指定标记器"filter": ["lowercase"], # 可选:内置过滤器,将文本转换为小写
} 自定义过滤器:自定义过滤器允许进行专门配置。您可以通过选择有效的过滤器类型 (filter.type) 并为每种过滤器类型添加特定设置来定义自定义过滤器。支持自定义的过滤器类型示例:
-
stop:通过设置停止词列表(如"stop_words": ["of", "to"])删除指定的常用词。 -
length:根据长度标准(如设置最大标记长度)排除标记。 -
stemmer:将单词还原为词根形式,以便更灵活地进行匹配。
配置自定义过滤器的示例:
analyzer_params = {"tokenizer": "standard", # 必选:指定标记器"filter": [{"type": "stop", # 指定‘stop’作为过滤器类型"stop_words": ["of", "to"], # 指定‘stop’作为过滤器类型}]
}1.3 使用示例
在本示例中,您将创建一个 Collections Schema,其中包括:
-
一个用于嵌入的向量字段。
-
两个
VARCHAR字段,用于文本处理:-
一个字段使用内置分析器。
-
其他使用自定义分析器。
-
1.3.1 初始化 MilvusClient 并创建 Schema
首先设置 Milvus 客户端并创建新的 Schema。
from pymilvus import MilvusClient, DataType# 设置一个Milvus客户端
client = MilvusClient(uri="http://localhost:19530")# 创建一个新模式
schema = client.create_schema(auto_id=True, enable_dynamic_field=False)1.3.2 定义和验证分析仪配置
配置并验证内置分析器(english):定义内置英文分析器的分析器参数。
# 内置分析器配置,用于英文文本处理
analyzer_params_built_in = {"type": "english"
}配置并验证自定义分析器:定义自定义分析器,该分析器使用标准标记符号生成器、内置小写过滤器以及标记符号长度和停用词自定义过滤器。
# 自定义分析器配置与标准标记器和自定义过滤器
analyzer_params_custom = {"tokenizer": "standard","filter": ["lowercase", # 内置过滤器:将令牌转换为小写{"type": "length", # 自定义过滤器:限制令牌长度"max": 40},{"type": "stop", # 自定义过滤:删除指定的停止词"stop_words": ["of", "for"]}]
}
1.3.3 向 Schema 添加字段
在验证了分析器配置后,请将其添加到 Schema 字段中:
# 使用内置分析器配置添加VARCHAR字段‘title_en’
schema.add_field(field_name='title_en',datatype=DataType.VARCHAR,max_length=1000,enable_analyzer=True,analyzer_params=analyzer_params_built_in,enable_match=True,
)# 使用自定义分析器配置添加VARCHAR字段“title”
schema.add_field(field_name='title',datatype=DataType.VARCHAR,max_length=1000,enable_analyzer=True,analyzer_params=analyzer_params_custom,enable_match=True,
)# 为嵌入添加矢量场
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3)# 添加主键字段
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)1.3.4 准备索引参数并创建 Collections
# 为矢量场设置索引参数
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", metric_type="COSINE", index_type="AUTOINDEX")# 使用已定义的模式和索引参数创建集合
client.create_collection(collection_name="my_collection",schema=schema,index_params=index_params
)2 内置分析器
2.1 标准
standard 分析器是 Milvus 的默认分析器,如果没有指定分析器,它将自动应用于文本字段。它使用基于语法的标记化,对大多数语言都很有效。
2.1.1 定义
standard 分析器包括
- 标记化器:使用
standard标记符号化器,根据语法规则将文本分割成离散的单词单位。 - 过滤器:使用
lowercase过滤器将所有标记转换为小写,从而实现不区分大小写的搜索。
standard 分析器的功能相当于以下自定义分析器配置:
analyzer_params = {"tokenizer": "standard","filter": ["lowercase"]
}2.1.2 配置
要将standard 分析器应用到一个字段,只需在analyzer_params 中将type 设置为standard ,并根据需要加入可选参数即可。
analyzer_params = {"type": "standard", # 指定标准分析器类型
} standard 分析器接受以下可选参数:
| 参数 | 说明 |
|---|---|
|
| 一个数组,包含将从标记化中删除的停用词列表。默认为 |
自定义停止词配置示例:
analyzer_params = {"type": "standard", # 指定标准分析器类型"stop_words", ["of"] # 可选:要从标记化中排除的单词列表analyzerParams = map[string]any{"type": "standard", "stop_words": []string{"of"}} 定义analyzer_params 后,您可以在定义 Collections Schema 时将其应用到VARCHAR 字段。这样,Milvus 就能使用指定的分析器处理该字段中的文本,从而实现高效的标记化和过滤。
2.1.3 示例
分析器配置
analyzer_params = {"type": "standard", # 标准分析仪配置"stop_words": ["for"] # 可选:自定义停止词参数
}预期输出
Standard analyzer output: ['the', 'milvus', 'vector', 'database', 'is', 'built', 'scale']2.2 英语
Milvus 中的english 分析器旨在处理英文文本,应用特定语言规则进行标记化和过滤。
2.2.1 定义
english 分析器使用以下组件:
-
标记化器:使用
standard标记化器将文本分割成离散的单词单位。 -
过滤器:包括多个过滤器,用于全面处理文本:
-
lowercase:将所有标记转换为小写,从而实现不区分大小写的搜索。 -
stemmer:将单词还原为词根形式,以支持更广泛的匹配(例如,"running "变为 "run")。 -
stop_words:删除常见的英文停止词,以便集中搜索文本中的关键词语。
-
english 分析器的功能相当于以下自定义分析器配置:
analyzer_params = {"tokenizer": "standard","filter": ["lowercase",{"type": "stemmer","language": "english"}, {"type": "stop","stop_words": "_english_"}]
}2.2.2 配置
要将english 分析器应用到一个字段,只需在analyzer_params 中将type 设置为english ,并根据需要加入可选参数即可。
analyzer_params = {"type": "english",
} english 分析器接受以下可选参数:
| 参数 | 说明 |
|---|---|
|
| 一个数组,包含将从标记化中删除的停用词列表。默认为 |
自定义停止词配置示例:
analyzer_params = {"type": "english","stop_words": ["a", "an", "the"]
} 定义analyzer_params 后,您可以在定义 Collections Schema 时将其应用到VARCHAR 字段。这样,Milvus 就能使用指定的分析器处理该字段中的文本,以实现高效的标记化和过滤。
2.2.3 示例
分析器配置
analyzer_params = {"type": "english","stop_words": ["a", "an", "the"]
}预期输出
English analyzer output: ['milvus', 'vector', 'databas', 'built', 'scale']2.3 中文
chinese 分析器专为处理中文文本而设计,提供有效的分段和标记化功能。
2.3.1 定义
chinese 分析器包括
- 标记化器:使用
jieba标记化器,根据词汇和上下文将中文文本分割成标记。 - 过滤器:使用
cnalphanumonly过滤器删除包含任何非汉字的标记。
chinese 分析器的功能相当于以下自定义分析器配置:
analyzer_params = {"tokenizer": "jieba","filter": ["cnalphanumonly"]
}2.3.2 配置
要将chinese 分析器应用到一个字段,只需在analyzer_params 中将type 设置为chinese 即可。chinese 分析器不接受任何可选参数。
analyzer_params = {"type": "chinese",
}2.3.3 示例
分析器配置
analyzer_params = {"type": "chinese",
}预期输出
Chinese analyzer output: ['Milvus', '是', '一个', '高性', '性能', '高性能', '可', '扩展', '的', '向量', '数据', '据库', '数据库']