杭电oj(1180、1181)题解

目录
1180
题目
思路
问题概述
代码思路分析
1. 数据结构与全局变量
2. BFS 函数 bfs
3. 主函数 main
总结
代码
1181
题目
思路
1. 全局变量的定义
2. 深度优先搜索函数 dfs
3. 主函数 main
总结
代码
1180
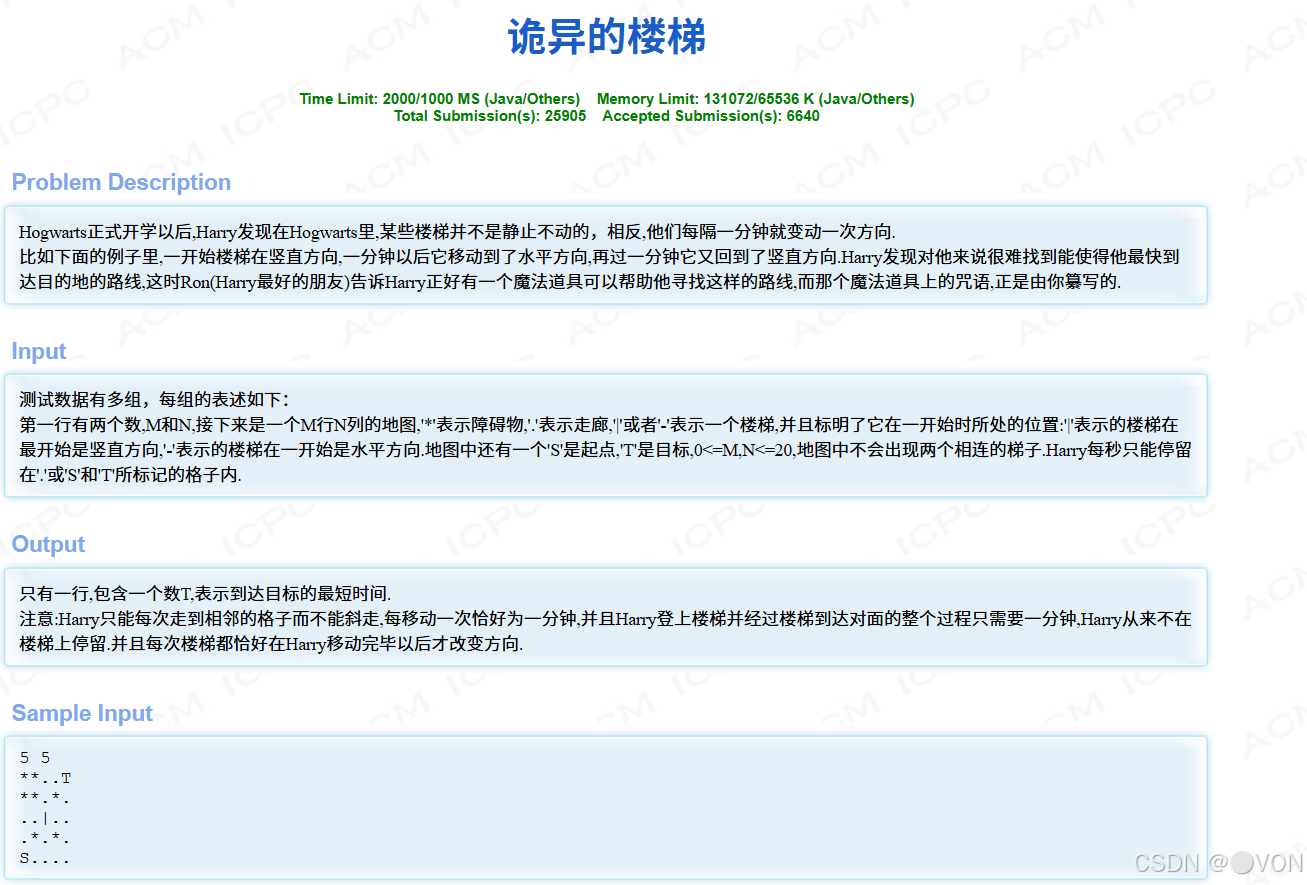
题目
思路
注:当走的方向和楼梯方向一致的时候不用等楼梯
问题概述
存在一个由字符构成的迷宫,每个字符代表不同的地形。起点用 S 表示,终点用 T 表示,障碍物用 * 表示,还有两种特殊地形:竖杠 | 和横杠 -,它们会依据时间(步数)的奇偶性来改变通行规则。代码的目的是找出从起点到终点的最短步数。
代码思路分析
1. 数据结构与全局变量
char map[25][25];
bool val[25][25];
int n,m;
int dxy[4][2]={{-1,0},{0,1},{1,0},{0,-1}};
struct node{int t;int x,y;
};
map:二维字符数组,用于存储迷宫地图。val:二维布尔数组,用于标记某个位置是否已经被访问过。n和m:分别代表迷宫的行数和列数。dxy:二维数组,存储四个方向(上、右、下、左)的偏移量,便于后续遍历相邻位置。node:结构体,用于存储当前位置的信息,包含时间t以及坐标(x, y)。
2. BFS 函数 bfs
int bfs(node temp){queue<node>q;while(!q.empty()){q.pop();}q.push(temp);while(!q.empty()){temp=q.front();q.pop();if(map[temp.x][temp.y]=='T') return temp.t;for(int i=0;i<4;i++){node next;next.x=temp.x+dxy[i][0];next.y=temp.y+dxy[i][1];next.t=temp.t+1;if(val[next.x][next.y] || map[next.x][next.y]=='*' || next.x<1 || next.x>n || next.y<1 || next.y>m) continue;if(map[next.x][next.y]=='|'){next.x+=dxy[i][0];next.y+=dxy[i][1];if(val[next.x][next.y] || map[next.x][next.y]=='*' || next.x<1 || next.x>n || next.y<1 || next.y>m) continue;if((temp.t%2==1 && dxy[i][1]==0) || (temp.t%2==0 && dxy[i][0]==0)) next.t++;}else if(map[next.x][next.y]=='-'){next.x+=dxy[i][0];next.y+=dxy[i][1];if(val[next.x][next.y] || map[next.x][next.y]=='*' || next.x<1 || next.x>n || next.y<1 || next.y>m) continue;if((temp.t%2==1 && dxy[i][0]==0) || (temp.t%2==0 && dxy[i][1]==0)) next.t++;}val[next.x][next.y]=true;q.push(next);}}
}
- 初始化一个队列
q,并将起点加入队列。 - 持续从队列中取出元素,若当前位置为终点
T,则返回当前的时间t。 - 遍历当前位置的四个相邻位置:
- 若相邻位置已被访问、是障碍物或者越界,则跳过。
- 若相邻位置是
|或-,需要额外处理:- 先跨过该位置,检查新位置是否合法。
- 根据当前时间的奇偶性以及移动方向,判断是否需要额外增加时间。
- 标记新位置为已访问,并将其加入队列。
3. 主函数 main
int main(){while(cin>>n>>m){node sta;memset(val, false, sizeof(val));for(int i=1;i<=n;i++){for(int j=1;j<=m;j++){cin>>map[i][j];if(map[i][j]=='S'){val[i][j]=true;sta.t=0;sta.x=i;sta.y=j;}}}cout<<bfs(sta)<<endl;}return 0;
}
- 持续读取迷宫的行数和列数。
- 初始化
val数组为false,表示所有位置都未被访问。 - 读取迷宫地图,找到起点
S,并标记起点为已访问。 - 调用
bfs函数进行搜索,并输出最短步数。
总结
此代码运用 BFS 算法,从起点开始逐层扩展,直至找到终点。在扩展过程中,针对特殊地形 | 和 -,依据时间的奇偶性和移动方向来决定是否需要额外增加时间,最终输出从起点到终点的最短步数。
代码
#include<iostream>
#include<queue>
using namespace std;
char map[25][25];
bool val[25][25];
int n,m;
int dxy[4][2]={{-1,0},{0,1},{1,0},{0,-1}};
struct node{int t;int x,y;
};int bfs(node temp){queue<node>q;while(!q.empty()){q.pop();}q.push(temp);while(!q.empty()){temp=q.front();q.pop();if(map[temp.x][temp.y]=='T') return temp.t;for(int i=0;i<4;i++){node next;next.x=temp.x+dxy[i][0];next.y=temp.y+dxy[i][1];next.t=temp.t+1;if(val[next.x][next.y] || map[next.x][next.y]=='*' || next.x<1 || next.x>n || next.y<1 || next.y>m) continue;if(map[next.x][next.y]=='|'){next.x+=dxy[i][0];next.y+=dxy[i][1];if(val[next.x][next.y] || map[next.x][next.y]=='*' || next.x<1 || next.x>n || next.y<1 || next.y>m) continue;if((temp.t%2==1 && dxy[i][1]==0) || (temp.t%2==0 && dxy[i][0]==0)) next.t++;}else if(map[next.x][next.y]=='-'){next.x+=dxy[i][0];next.y+=dxy[i][1];if(val[next.x][next.y] || map[next.x][next.y]=='*' || next.x<1 || next.x>n || next.y<1 || next.y>m) continue;if((temp.t%2==1 && dxy[i][0]==0) || (temp.t%2==0 && dxy[i][1]==0)) next.t++;}val[next.x][next.y]=true;q.push(next);}}
}
int main(){while(cin>>n>>m){node sta;memset(val, false, sizeof(val));for(int i=1;i<=n;i++){for(int j=1;j<=m;j++){cin>>map[i][j];if(map[i][j]=='S'){val[i][j]=true;sta.t=0;sta.x=i;sta.y=j;}}}cout<<bfs(sta)<<endl;}return 0;
}1181
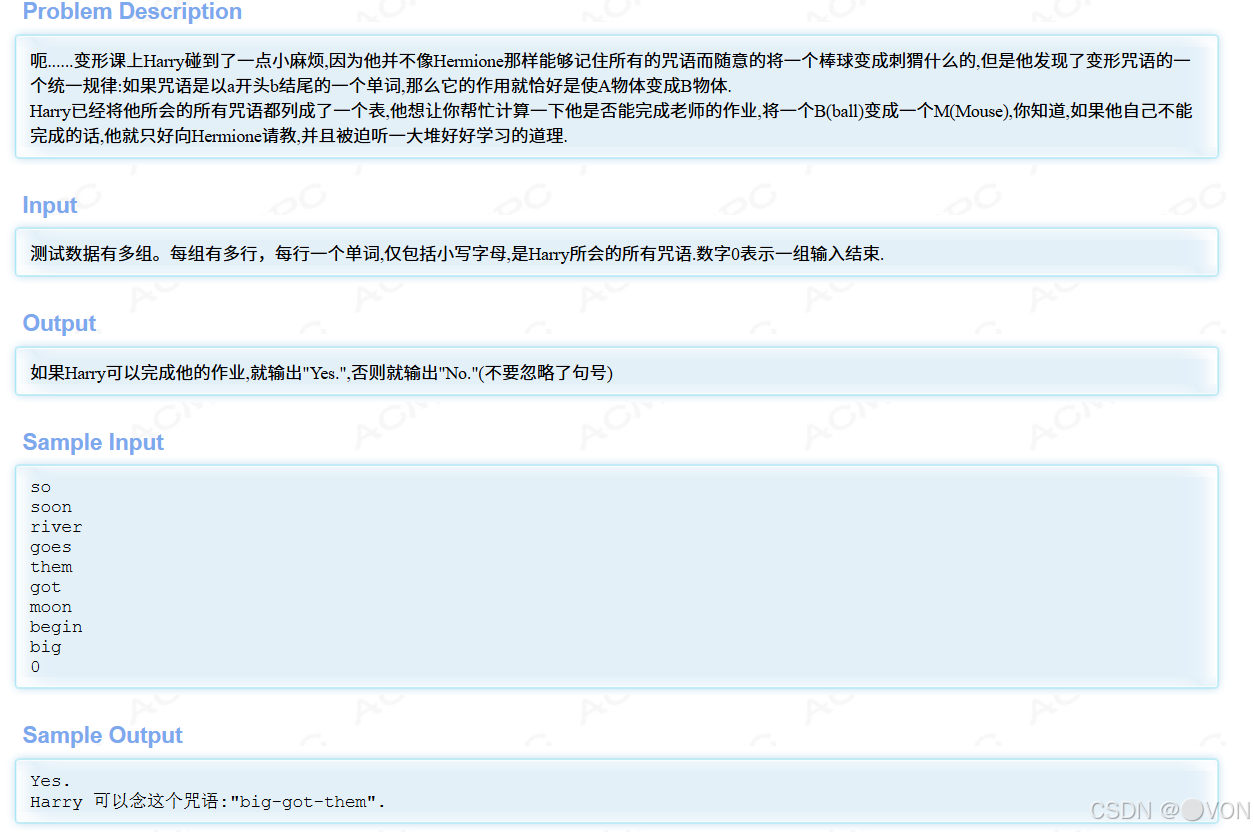
题目
思路
核心思路:将所有满足条件的情况放到动态数组中,如果数组为空输出no否则输出yes
这段 C++ 代码的核心思路是利用深度优先搜索(DFS)算法来判断输入的字符串集合中是否存在以 'b' 开头且以 'm' 结尾的字符串序列,并且序列中相邻字符串满足前一个字符串的最后一个字符与后一个字符串的第一个字符相同。下面为你详细剖析代码思路:
1. 全局变量的定义
vector<vector<string>> allSequences;
vector<string> ans;
vector<bool> val;
vector<string> arr;
allSequences:这是一个二维向量,用于存储所有满足条件(以'b'开头且以'm'结尾,相邻字符串首尾字符匹配)的字符串序列。ans:这是一个一维向量,用于存储当前正在搜索的字符串序列。val:这是一个布尔类型的向量,其长度与输入的字符串数量相同,用于标记每个字符串在当前搜索路径中是否已经被使用过。arr:这是一个一维向量,用于存储所有输入的字符串。
2. 深度优先搜索函数 dfs
void dfs(string s) {if (s[s.size() - 1] == 'm') {allSequences.push_back(ans);return;}for (int i = 0; i < arr.size(); i++) {if (s[s.size() - 1] == arr[i][0] && val[i] == false) {val[i] = true;ans.push_back(arr[i]);dfs(arr[i]);val[i] = false;ans.pop_back();}}
}
- 终止条件:当当前字符串
s的最后一个字符是'm'时,意味着找到了一个满足条件的字符串序列,将当前的ans序列添加到allSequences中,然后返回。 - 搜索过程:
- 遍历
arr中的每个字符串。 - 检查当前字符串
s的最后一个字符是否等于arr[i]的第一个字符,并且arr[i]还未被使用过(即val[i]为false)。 - 如果满足条件,将
arr[i]标记为已使用(val[i] = true),并将其添加到ans序列中。 - 递归调用
dfs函数,继续以arr[i]为当前字符串进行搜索。 - 递归返回后,进行回溯操作,将
arr[i]标记为未使用(val[i] = false),并从ans序列中移除。
- 遍历
3. 主函数 main
int main() {string s;while (true) {arr.clear();allSequences.clear();while (cin >> s) {if (s == "0") break;arr.push_back(s);}if (arr.empty()) break;val.assign(arr.size(), false);for (int i = 0; i < arr.size(); i++) {if (arr[i][0] == 'b') {ans.clear();ans.push_back(arr[i]);val[i] = true;dfs(arr[i]);val[i] = false;}}if(!allSequences.empty()) cout<<"Yes."<<endl;else cout<<"No."<<endl;}return 0;
}
- 输入处理:
- 持续读取输入的字符串,直到遇到
"0"为止,将这些字符串存储在arr中。 - 如果
arr为空,说明没有输入有效字符串,程序结束。
- 持续读取输入的字符串,直到遇到
- 初始化标记数组:将
val数组的所有元素初始化为false,表示所有字符串都未被使用。 - 启动搜索:
- 遍历
arr中的每个字符串,若其以'b'开头,则将其作为起始字符串,清空ans并将该字符串添加到ans中,标记其为已使用,然后调用dfs函数开始搜索。 - 搜索结束后,将该字符串标记为未使用,以便后续可能的其他搜索路径使用。
- 遍历
- 输出结果:
- 如果
allSequences不为空,说明找到了满足条件的字符串序列,输出"Yes."。 - 否则,输出
"No."。
- 如果
总结
该代码通过深度优先搜索算法,从以 'b' 开头的字符串开始,不断尝试寻找满足首尾字符匹配条件且以 'm' 结尾的字符串序列,最终根据是否找到这样的序列输出相应的结果。
代码
#include <iostream>
#include <vector>
#include <string>
using namespace std;
vector<vector<string>> allSequences;
vector<string> ans;
vector<bool> val;
vector<string> arr;void dfs(string s) {if (s[s.size() - 1] == 'm') {allSequences.push_back(ans);return;}for (int i = 0; i < arr.size(); i++) {if (s[s.size() - 1] == arr[i][0] && val[i] == false) {val[i] = true;ans.push_back(arr[i]);dfs(arr[i]);val[i] = false;ans.pop_back();}}
}int main() {string s;while (true) {arr.clear();allSequences.clear();while (cin >> s) {if (s == "0") break;arr.push_back(s);}if (arr.empty()) break;val.assign(arr.size(), false);for (int i = 0; i < arr.size(); i++) {if (arr[i][0] == 'b') {ans.clear();ans.push_back(arr[i]);val[i] = true;dfs(arr[i]);val[i] = false;}}if(!allSequences.empty()) cout<<"Yes."<<endl;else cout<<"No."<<endl;}return 0;
}