【2025】ORM框架是什么?有哪些常用?Mybatis和Hibernate是什么样的?
一、ORM框架概述
1. ORM是什么?
ORM(Object-Relational Mapping)简称ORM,翻译过来是对象关系映射。对象关系映射是一种程序设计技术,用于在面向对象编程语言中实现不同系统数据之间的转换。它将数据库表结构映射为对象,使开发者可以用面向对象的方式操作数据库。
ORM 有下面这些优点:
●数据模型都在一个地方定义,更容易更新和维护,也利于重用代码。
●ORM 有现成的工具,很多功能都可以自动完成,比如数据消毒、预处理、事务等等。
数据消毒是指对用户输入的数据进行处理,以防止恶意数据或不合法数据对应用程序的攻击或错误影响。常见的数据消毒操作包括转义特殊字符、验证输入、限制输入长度等。ORM框架可以做参数化查询、数据类型验证等可以实现数据消毒
●它迫使你使用 MVC 架构,ORM 就是天然的 Model,最终使代码更清晰。
●基于 ORM 的业务代码比较简单,代码量少,语义性好,容易理解。
●你不必编写性能不佳的 SQL。
但是,ORM 也有很突出的缺点:
●ORM 库不是轻量级工具,需要花很多精力学习和设置。
●对于复杂的查询,ORM 要么是无法表达,要么是性能不如原生的 SQL。
●ORM 抽象掉了数据库层,开发者无法了解底层的数据库操作,也无法定制一些特殊的 SQL。
2. Java常用ORM框架
MyBatis、Hibernate、JPA、Spring Data JPA
二、MyBatis详解
1. MyBatis是什么?
MyBatis是一款优秀的半自动化ORM框架,它封装了JDBC操作,通过XML或注解配置SQL,将Java对象与SQL语句动态绑定。
2. MyBatis工作机制
核心组件
| 组件 | 作用 |
|---|---|
| SqlSessionFactory | 全局单例,生产SqlSession |
| SqlSession | 一次数据库会话,线程不安全 |
| Executor | SQL执行器(Simple/Reuse/Batch) |
| MappedStatement | 封装SQL和参数映射 |
| TypeHandler | 类型转换处理器 |
如何实现字段映射的呢?
四种方式:
使用列名映射:Mybatis默认使用列名来映射查询结果集中的列与Java对象中的属性。如果列名和Java对象属性名不完全一致,可以通过在SQL语句中使用“AS”关键字或使用别名来修改列名。
使用别名映射:如果查询语句中使用了别名,则Mybatis会优先使用列别名来映射Java对象属性名,而不是列名。
使用ResultMap映射:ResultMap是Mybatis用来映射查询结果集和Java对象属性的关系。可以在映射文件中定义ResultMap,指定Java对象和列之间的映射关系。通过ResultMap,可以实现复杂的字段映射关系和转换。
自定义TypeHandler映射:如果默认的字段映射方式无法满足需求,可以通过实现TypeHandler接口来自定义字段映射规则。TypeHandler可以将查询结果集中的列类型转换为Java对象属性类型,并将Java对象属性类型转换为SQL类型。可以通过在映射文件中定义TypeHandler,来实现自定义映射。
自动映射的底层原理:
Mybatis实现字段映射的代码主要在ResultSetHandler类中。该类是Mybatis查询结果集处理的核心类,负责将JDBC ResultSet对象转换为Java对象,并进行字段映射。
Mybatis实现字段映射的原理可以简单描述为以下几个步骤:
1:Mybatis通过JDBC API向数据库发送SQL查询语句,并获得查询结果集。
2:查询结果集中的所有数据封装到一个ResultSet对象中,Mybatis遍历ResultSet对象中的数据。
3:对于每一行数据,Mybatis根据Java对象属性名和查询结果集中的列名进行匹配。如果匹配成功,则将查询结果集中的该列数据映射到Java对象的相应属性中。
4:如果Java对象属性名和查询结果集中的列名不完全一致,Mybatis可以通过在SQL语句中使用“AS”关键字或使用别名来修改列名,或者使用ResultMap来定义Java对象属性和列的映射关系。
5:对于一些复杂的映射关系,例如日期格式的转换、枚举类型的转换等,可以通过自定义TypeHandler来实现。Mybatis将自定义TypeHandler注册到映射配置中,根据Java对象属性类型和查询结果集中的列类型进行转换。
6:最终,Mybatis将所有映射成功的Java对象封装成一个List集合,返回给用户使用。
工作流程
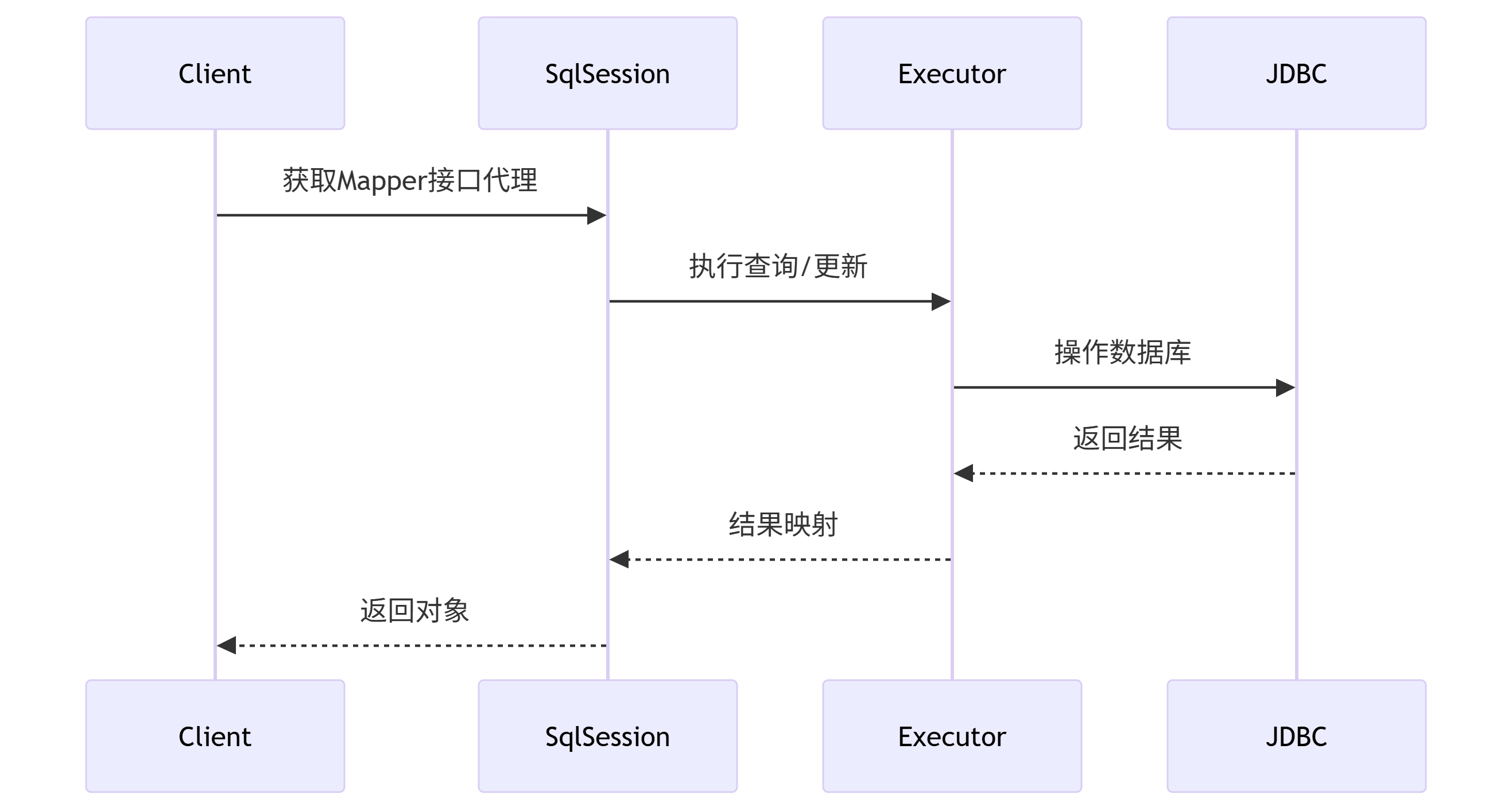
工作原理
启动阶段:
定义配置文件,如XML,注解
解析配置文件,将配置文件加载到内存当中
运行阶段:
读取内存中的配置文件,并根据配置文件实现对应的功能
在运行阶段执行一个具体的sql时,往往有以下步骤:
1:代理类的生成
首先Mybatis会根据我们传入接口通过JDK动态代理,生成一个代理对象。代理类的主要逻辑在MapperProxy中,而代理逻辑则是通过MapperMethod完成的。对于MapperMethod来说,它在创建的时候是需要读取XML或者方法注解的配置项,所以在使用的时候才能知道具体代理的方法的SQL内容。同时,这个类也会解析和记录被代理方法的入参和出参,以方便对SQL的查询占位符进行替换,同时对查询到的SQL结果进行转换。
2:执行SQL
代理类生成之后,就可以执行代理类的具体逻辑,也就是真正开始执行用户自定义的SQL逻辑了。
首先会进入到MapperMethod核心的执行逻辑。
主要逻辑是这个方法
public Object execute(SqlSession sqlSession, Object[] args) {/**/}
这里一共做了两件事情,一件事情是通过BoundSql将方法的入参转换为SQL需要的入参形式,第二件事情就是通过SqlSession来执行对应的Sql。下面我们通过select来举例。
3:缓存
Sqlsession是Mybatis对Sql执行的封装,真正的SQL处理逻辑要通过Executor来执行。Executor有多个实现类,因为在查询之前,要先check缓存是否存在,所以默认使用的是CachingExecutor类,顾名思义,它的作用就是二级缓存。
二级缓存是和命名空间绑定的,如果多表操作的SQL的话,是会出现脏数据的。同时如果是不同的事务,也可能引起脏读,所以要慎重。
如果二级缓存没有命中则会进入到BaseExecutor中继续执行,在这个过程中,会调用一级缓存执行。
4:查询数据库
如果一级缓存中没有的话,则需要调用JDBC执行真正的SQL逻辑。我们知道,在调用JDBC之前,是需要建立连接的,如下代码所示:
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}
我们会发现,Mybatis并不是直接从JDBC获取连接的,通过数据源来获取的,Mybatis默认提供了是那种种数据源:JNDI,PooledDataSource和UnpooledDataSource,我们也可以引入第三方数据源,如Druid等。包括驱动等都是通过数据源获取的。
获取到Connection之后,还不够,因为JDBC的数据库操作是需要Statement的,所以Mybatis专门抽象出来了StatementHandler处理类来专门处理和JDBC的交互,如下所示:
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
String sql = boundSql.getSql();
statement.execute(sql);
return resultSetHandler.<E>handleResultSets(statement);
}
其实这三行代码就代表了Mybatis执行SQL的核心逻辑:组装SQL,执行SQL,组装结果。仅此而已。
具体Sql是如何组装的呢?是通过BoundSql来完成的,
5:处理查询结果
此时我们已经拿到了执行结果ResultSet,同时我们也在应用启动的时候在配置文件中配置了DO到数据库字段的映射ResultMap,所以通过这两个配置就可以转换。核心的转换逻辑是通过TypeHandler完成的,流程如下所示:
1创建返回的实体类对象,如果该类是延迟加载,则先生成代理类
2根据ResultMap中配置的数据库字段,将该字段从ResultSet取出来
3从ResultMap中获取映射关系,如果没有,则默认将下划线转为驼峰式命名来映射
4通过setter方法反射调用,将数据库的值设置到实体类对象当中
3. 缓存机制
在Mybatis中,缓存分为PerpetualCache, BlockingCache, LruCache等,这些cache的实现则是借用了装饰者模式。一级缓存使用的是PerpetualCache,里面是一个简单的HashMap。一级缓存会在更新的时候,事务提交或者回滚的时候被清空。换句话说,一级缓存是和SqlSession绑定的。
一级缓存(本地缓存)
在同一个会话中,Mybatis会将执行过的SQL语句的结果缓存到内存中,下次再执行相同的SQL语句时,会先查看缓存中是否存在该结果,如果存在则直接返回缓存中的结果,不再执行SQL语句。
-
作用域:SqlSession级别
-
特性:
-
默认开启
-
相同SQL和参数会命中缓存
-
执行任何INSERT/UPDATE/DELETE语句清空
-
执行commit()或rollback()清空
-
调用sqlSession.clearCache()清空
-
MyBatis一级缓存内部设计简单,只是一个没有容量限定的HashMap,在缓存的功能性上有所欠缺。
MyBatis的一级缓存最大范围是SqlSession内部,有多个SqlSession或者分布式的环境下,数据库写操作会引起脏数据,换句话说,当一个SqlSession查询并缓存结果后,另一个SqlSession更新了该数据,其他缓存结果的SqlSession是看不到更新后的数据的。所以建议设定缓存级别为Statement。或者 使用flushCache参数设为true:强制刷新缓存。或者直接不用一级缓存,给他禁止。或者结合二级缓存但是又会衍生出新的问题。或者使用插件拦截
二级缓存(全局缓存)
二级缓存是基于命名空间的缓存,它可以跨会话,在多个会话之间共享缓存,可以减少数据库的访问次数。要使用二级缓存,需要在Mybatis的配置文件中配置相应的缓存实现类,并在需要使用缓存的Mapper接口上添加@CacheNamespace注解。二级缓存的使用需要注意缓存的更新和失效机制,以及并发操作的问题。
-
作用域:Mapper级别(namespace)
-
配置方式:
<cache eviction="LRU" flushInterval="60000" size="512"/>
-
注意事项:
-
需要实体类实现Serializable
-
事务提交后才生效
-
多表操作需谨慎(可能脏读)假设:我们有两个表:student和class,我们为这两个表创建了两个namespace去对这两个表做相关的操作。同时,为了进行多表查询,我们在namespace=student的空间中,对student和class两张表进行了关联查询操作(sqlA)。此时就会在namespace=student的空间中把sqlA的结果缓存下来,如果我们在namespace=class下更新了class表,namespace=student是不会更新的,这就会导致脏数据的产生。
-
-
useCache:是否使用缓存预防脏数据
4. 分页机制
在MyBatis中,想要实现分页通常有四种做法:
1、在SQL中添加limit语句:(物理分页)
够直接,不多说了
2、基于PageHelper分页插件,实现分页:使用PageHelper时,不需要在mapper.xml文件中使用limit语句。(物理分页)
PageHelper.startPage(int pageNum, int pageSize)设置分页参数之后,其实PageHelper会把他们存储到ThreadLocal中。
PageHelper会在执行器的query方法执行之前,会从ThreadLocal中再获取分页参数信息,页码和页大小,然后执行分页算法,计算需要返回的数据块的起始位置和大小。最后,PageHelper会通过修改SQL语句的方式,在SQL后面动态拼接上limit语句,限定查询的数据范围,从而实现物理分页的效果。并且在查询结束后再清除ThreadLocal中的分页参数。
3、基于RowBounds实现分页(逻辑分页)
它包含两个属性offset和limit,分别表示分页查询的偏移量和每页查询的数据条数。
<select id="getUsers" resultType="User">
select * from user
<where>
<if test="name != null">
and name like CONCAT('%',#{name},'%')
</if>
</where>
order by id
</select>
然后,在查询的时候,将RowBounds当做一个参数传递:
int offset = 10; // 偏移量
int limit = 5; // 每页数据条数
RowBounds rowBounds = new RowBounds(offset, limit);
List<User> userList = sqlSession.selectList("getUserList", null, rowBounds);
在内存中进行分页,分页的方式是根据RowBounds中指定的offset和limit进行数据保留,即抛弃掉不需要的数据再返回。
4、基于MyBatis-Plus实现分页(逻辑分页和物理分页)
MyBatis-Plus支持分页插件——PaginationInnerInterceptor
PaginationInnerInterceptor采用的是物理分页方式,物理分页是在数据库中进行分页,即直接在SQL语句中加入LIMIT语句,只查询所需的部分数据。
物理分页的优点是可以减少内存占用,减轻数据库的负载,缺点是无法对结果进行任意操作,比如说在分页过程中做二次过滤、字段映射、json解析等。
PaginationInnerInterceptor这个分页插件就会自动拦截所有的SQL查询请求,计算分页查询的起始位置和记录数,并在SQL语句中加入LIMIT语句。
用法:需要添加分页插件:首先,在 MyBatis-Plus 的配置中添加分页插件,在 Spring Boot 应用中,可以这样配置:
@Configuration
@MapperScan("scan.your.mapper.package")
public class MybatisPlusConfig {
/**
* 添加分页插件
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));//如果配置多个插件,切记分页最后添加
return interceptor;
}
}
然后先定义接口
public interface UserMapper extends BaseMapper<User> {
// 这里可以添加其他数据库操作的方法
}
然后直接用
@Autowired
private UserMapper userMapper;
public IPage<User> selectUserPage(int currentPage, int pageSize) {
Page<User> page = new Page<>(currentPage, pageSize);
IPage<User> userPage = userMapper.selectPage(page, null);
return userPage;
}
selectPage 方法是 MyBatis-Plus 提供的内置方法,用于执行分页查询。null 作为第二个参数表示没有查询条件,即查询所有记录。
selectPage 方法返回的 IPage 对象包含了分页信息(如当前页码、总页数、每页记录数、总记录数等)和查询结果。
5. #{}和${}的区别
#{}类似jdbc中的PreparedStatement,对于传入的参数,在预处理阶段会使用?代替,可以有效的避免SQL注入。除了#还可以怎么预防SQL注入呢
参数验证:在将变量传递到 SQL 语句之前,对输入的参数进行严格的验证。确保输入符合预期的格式,并且移除或转义可能的 SQL 控制字符。例如,如果你知道一个参数应该是一个整数,你可以先将其转换为整数。
使用枚举或固定列表:如果可能的参数值是已知且数量有限的,比如排序字段(ASC, DESC),可以使用枚举或预定义的字符串列表来限制输入。比如说字段名,那么也可以定义一个枚举或者常量类,然后用户输入时做判断,是否规定的枚举项或者常量。
使用 $ 传递参数时,MyBatis 会将其视为字面量,并在构建 SQL 语句时直接替换成参数的实际值。这意味着参数值会直接拼接到 SQL 语句中。
| 特性 | #{} | ${} |
|---|---|---|
| 处理方式 | 预编译(PrepareStatement) | 字符串替换 |
| 安全性 | 防SQL注入 | 有注入风险 |
| 使用场景 | 参数值 | 动态表名/列名 order by、group by 等语句后面的时候。 |
| 示例 | WHERE name = #{name}name被替换为 ?并且 userId 的值在执行时会被安全地设置为参数值。 | ORDER BY ${column} |
6. 插件机制
实现原理(拦截器)
Mybatis插件的运行原理主要涉及3个关键接口:Interceptor、Invocation和Plugin。
Mybatis插件的运行原理主要涉及3个关键接口:Interceptor、Invocation和Plugin。
Interceptor:拦截器接口,定义了Mybatis插件的基本功能,包括插件的初始化、插件的拦截方法以及插件的销毁方法。
Invocation:调用接口,表示Mybatis在执行SQL语句时的状态,包括SQL语句、参数、返回值等信息。
Plugin:插件接口,Mybatis框架在执行SQL语句时,会将所有注册的插件封装成Plugin对象,通过Plugin对象实现对SQL语句的拦截和修改。
插件的运行流程如下:
首先,当Mybatis框架运行时,会将所有实现了Interceptor接口的插件进行初始化。
初始化后,Mybatis框架会将所有插件和原始的Executor对象封装成一个InvocationChain对象。(这里使用的是责任链模式)
每次执行SQL语句时,Mybatis框架都会通过InvocationChain对象依次调用所有插件的intercept方法,实现对SQL语句的拦截和修改。
最后,Mybatis框架会将修改后的SQL语句交给原始的Executor对象执行,并将执行结果返回给调用方。
通过这种方式,Mybatis插件可以对SQL语句进行拦截和修改,实现各种功能,例如查询缓存、分页、分库分表等。
具体实现一个插件时
@Intercepts({@Signature(type=Executor.class, method="query", args={MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class})
})
public class MyPlugin implements Interceptor {@Overridepublic Object intercept(Invocation invocation) throws Throwable {// 前置处理Object result = invocation.proceed(); // 后置处理return result;}
}
常用插件
-
分页:PageHelper
-
性能分析:P6Spy
-
多租户:TenantLineInnerInterceptor
7. 连接池机制
什么是连接池呢
一般应用程序在连接数据库的时候,会有三步:
1:输入url,name,pwd产生一个connection
2:然后在这个connection中完成对应的sql操作
3:完成事务的提交或者回滚
为了对这三步进行抽象,诞生了数据源的概念,一般被定义为DataSource。数据源负责和实体数据库的连接,如(内存数据库,mysql等),所以数据源是被第三方数据库实现的。同时,因为通过数据源对数据库操作做了抽象,我们也可以在数据源中完成对数据库连接的池化,这就是数据库连接池。
借用javaDoc对DataSource的注释:
数据源用于连接到此DataSource对象所表示的物理数据源的工厂。作为DriverManager功能的替代方案,DataSource对象是获取连接的首选方式。实现DataSource接口的对象通常会向基于Java的命名服务注册™ 命名和目录(JNDI)API。
DataSource接口由驱动程序供应商实现。有三种类型的实现:
1基本实现--生成一个标准Connection对象
2连接池实现--生成一个Connection对象,该对象将自动参与连接池。此实现与中间层连接池管理器一起工作。
3分布式事务实现--生成一个Connection对象,该对象可以用于分布式事务,并且几乎总是参与连接池。此实现使用中间层事务管理器,并且几乎总是使用连接池
内置连接池
-
PooledDataSource:MyBatis自带简单连接池
-
UnpooledDataSource:每次新建连接
自带的数据库连接池有三个缺点:
空闲连接占用资源:连接池维护一定数量的空闲连接,这些连接会占用系统的资源,如果连接池设置过大,那么会浪费系统资源,如果设置过小,则会导致系统并发请求时连接不够用,影响系统性能。
连接池大小调优困难:连接池的大小设置需要根据系统的并发请求量、数据库的性能和系统的硬件配置等因素综合考虑,而这些因素都是难以预测和调整的。
连接泄漏:如果应用程序没有正确关闭连接,那么连接池中的连接就会泄漏,导致连接池中的连接数量不断增加,最终导致系统崩溃。
集成第三方
<!-- Druid配置示例 -->
<dataSource type="com.alibaba.druid.pool.DruidDataSource"><property name="url" value="${jdbc.url}"/><property name="maxActive" value="20"/>
</dataSource>
在执行SQL之前,Mybatis会获取数据库连接Connection,也就是数据源,而此时获得的Connection则是应用的启动的时候,已经通过配置项中的文件加载到内存中了:
一般情况下,我们不会使用Mybatis默认的PooledDataSource,而是会用Hikari,如果要增加Sql监控功能的话,也可以使用Druid。
常用连接池对比:
| 连接池 | 特点 |
|---|---|
| HikariCP | 高性能,SpringBoot默认 |
| Druid | 带监控功能,阿里开源 |
| Tomcat JDBC | Web容器集成 |
8. 其他关键技术
动态SQL(支持if标签
choose、when、otherwise标签:
foreach标签)
<select id="findUsers">SELECT * FROM user<where><if test="name != null">AND name = #{name}</if><choose><when test="role == 'admin'">AND level > 10</when><otherwise>AND level > 5</otherwise></choose></where>
</select>
结果集映射
<resultMap id="userMap" type="User"><id property="id" column="user_id"/><result property="name" column="user_name"/><association property="dept" javaType="Department"><id property="id" column="dept_id"/></association> </resultMap>
批量操作(也可以使用什么的foreach操作)
try(SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH)) {UserMapper mapper = session.getMapper(UserMapper.class);for(User user : userList) {mapper.insert(user);}session.commit();
}
延时加载;MyBaits支持延迟加载,延迟加载允许在需要时按需加载关联对象,而不是在查询主对象时立即加载所有关联对象。这样做可以提高查询性能和减少不必要的数据库访问。在 MyBatis 中,关于延迟加载的配置可以分为全局配置和局部配置。默认延迟加载是不开启的。
全局配置:全局配置影响整个 MyBatis 会话,通常在 mybatis-config.xml 中设置。这些设置会应用于所有的 SQL 映射,除非在映射文件中对某些操作进行了覆盖。
局部配置:局部配置是在具体的映射文件中进行的,针对单独的操作或关联定义。你可以在映射文件中针对特定的查询或关联覆盖全局设置,例如在 <association> 或 <collection> 中指定 fetchType。
延迟加载的主要原理就是当开启了延迟加载功能时,当查询主对象时,MyBatis会生成一个代理对象,并将代理对象返回给调用者。
当后面需要访问这些关联对象时,代理对象会检查关联对象是否已加载。如果未加载,则触发额外的查询。
查询结果返回后,MyBatis会将关联对象的数据填充到代理对象中,使代理对象持有关联对象的引用。这样,下次访问关联对象时,就可以直接从代理对象中获取数据,而无需再次查询数据库。
三、MyBatis最佳实践
-
SQL优化:
-
避免
SELECT * -
复杂查询拆分为多个简单SQL
-
合理使用索引提示
-
-
事务管理:
@Transactional public void updateUser(User user) {userMapper.update(user);logMapper.insertLog(user); } -
性能监控:
-
集成Druid监控
-
使用MyBatis-Plus性能分析插件
-
-
代码生成:
-
MyBatis Generator
-
MyBatis-Plus代码生成器
-
四、MyBatis与Hibernate对比
| 特性 | MyBatis | Hibernate |
|---|---|---|
| SQL控制 | 开发者编写 | 自动生成 |
| 性能 | 更优(可控SQL) | ORM转换有开销 |
| 学习曲线 | 简单 | 较复杂 |
| 缓存 | 二级缓存较弱 | 完善的缓存体系 |
| 适用场景 | 复杂SQL/高性能 | 快速开发/简单CRUD |
MyBatis因其灵活性和对SQL的精确控制,在需要复杂查询和高性能场景下更具优势。