规范编码策略以及AST的应用的学习
Git Hook实现代码规范
代码规范对于项目维护至关重要。通过Git Hook,我们可以在代码提交前自动执行规范检查,确保代码质量。
Git Hook原理
Git钩子是在Git执行特定操作时触发的脚本。它们位于项目的.git/hooks目录下,可以插入到Git工作流程的各个阶段,如pre-commit、commit-msg等。
通过编写这些钩子脚本,我们可以实现:
- 代码风格检查(驼峰命名、括号使用等)
- 自动格式化代码
- 提交前的单元测试执行
项目实践案例
在我们的APP项目中,主要使用了两个脚本来实现代码规范:
- 安装clang-format脚本:确保团队成员都安装了统一的代码格式化工具bash
| # 检查并安装clang-format if ! brew list | grep -q clang-format; then log "clang-format is not installed. Proceeding with installation..." if ! brew install clang-format; then handle_error "Failed to install clang-format" fi log "clang-format installed successfully." else log "clang-format is already installed. Skipping installation." fi |
- pre-commit钩子函数:在提交前自动格式化代码bash
| # 使用clang-format格式化代码 find ./Business ./Common -name "*.m" -o -name "*.h" -o -name "*.mm" | xargs clang-format -i |
这种方式确保了团队内代码风格的一致性,减少了因格式问题产生的冗余提交。
AST及其应用
AST概述
AST(抽象语法树)是源代码的树形表示,是编译过程中的关键产物。它通过两个阶段生成:
- 词法分析:将代码分解为标记(tokens)
- 语法分析:将标记组织成树状结构
AST作为源代码到汇编代码的桥梁,在编程工具中有广泛应用。
AST应用场景
- 代码语法检查
- 代码风格检查
- 代码格式化
- 代码高亮显示
- 错误提示
- 代码自动补全
AST的理解类比
我们可以将AST理解为语文分析。例如分析"你是猪,"这个句子:
- 词法分析:将句子拆分为各个部分javascript
| [ { type: "主语", value: "你" }, { type: "谓语", value: "是" }, { type: "宾语", value: "猪" }, { type: "标点符号", value: "," }, ] |
- 语法分析:生成树结构javascript
| { type: "语句", body: { type: "肯定陈述句", declarations: [ { type: "声明", person: { type: "Identifier", name: "你", }, name: { type: "animal", value: "猪", }, }, ], }, }; |
简易编译器设计
由于ast是编译过程的产物,为了加深对ast的理解,这边试着去设计一个简易的编译器
一个完整的编译器整体执行过程可以分为三个步骤:
- Parsing(解析过程):这个过程要经词法分析、语法分析、构建AST(抽象语法树)一系列操作;
- Transformation(转化过程):这个过程就是将上一步解析后的内容,按照编译器指定的规则进行处理,形成一个新的表现形式;
- Code Generation(代码生成):将上一步处理好的内容转化为新的代码;
举个例子,例如我们的源代码文件生成汇编代码.s文件,就是经过了这个流程
一个例子,将 lisp 的函数调用编译成类似 C 的函数
| LISP 代码: (add 2 (subtract 4 2)) C 代码 add(2, subtract(4, 2)) 释义: 2 + ( 4 - 2 ) |
解析
解析过程分为2个步骤:词法分析、语法分析。
词法分析是使用tokenizer(分词器)或者lexer(词法分析器),将源码拆分成tokens,tokens是一个放置对象的数组,其中的每一个对象都可以看做是一个单元(数字,标签,标点,操作符...)的描述信息。
| [ { type: "paren", value: "(" }, { type: "name", value: "add" }, { type: "number", value: "2" }, { type: "paren", value: "(" }, { type: "name", value: "subtract" }, { type: "number", value: "4" }, { type: "number", value: "2" }, { type: "paren", value: ")" }, { type: "paren", value: ")" }, ]; |
语法分析实际上就是将各个tokens整理成相互关联的表达式,实际上就是AST
| { type: 'Program', body: [{ type: 'CallExpression', name: 'add', params: [{ type: 'NumberLiteral', value: '2', }, { type: 'CallExpression', name: 'subtract', params: [{ type: 'NumberLiteral', value: '4', }, { type: 'NumberLiteral', value: '2', }] }] }] } |
转化
将源代码解析成抽象语法树后,为了生成我们的新代码,就需要改写当前抽象语法树,同时根据新的抽象语法树生成新代码,这个新代码既可以仍然是当前语言,也可以是新语言
Traversal(遍历):顾名思义这个过程就是,遍历这个AST(抽象语法树)的所有节点,这个过程使用深度优先遍历,大概执行顺序如下:
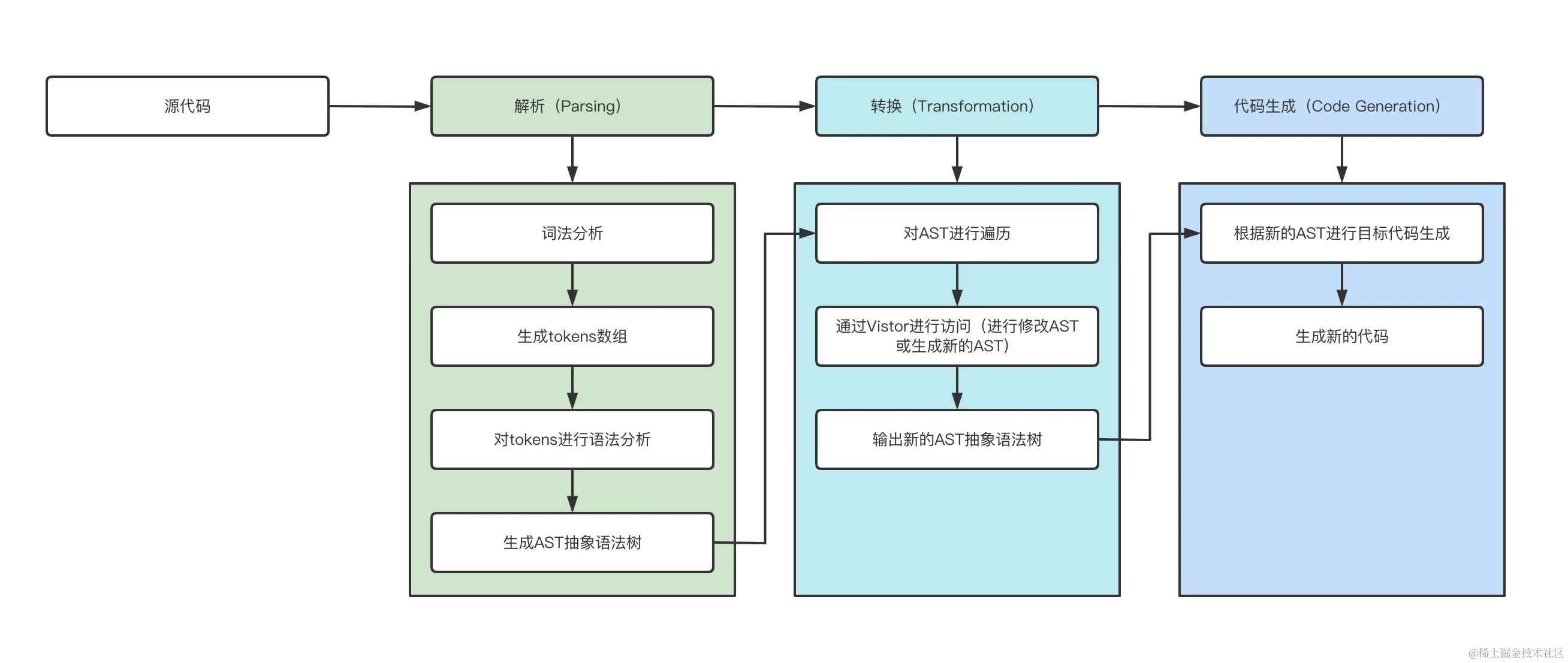
Visitors (访问器):访问器最基本的思想是创建一个“访问器”对象,这个对象可以处理不同类型的节点函数,如下所示
| const visitor = { NumberLiteral(node,parent){}, // 处理数字类型节点 CallExpression(node,parent){} // 处理调用语句类型节点 } |
在案例中我们是想将lisp语言转化为C语言,因此需要构建一个新的AST(抽象语法树)。这个创建的过程就需要遍历这个“树”的节点并读取其内容,由此引出 Traversal(遍历) 和 Visitors (访问器)。
如果并不需要转换语言,那么就不需要新建,只需要遍历原本AST,同时将对应节点替换为自己所需要的即可
生成阶段
最后就是代码生成阶段了,其实就是将生成的新AST树再转回代码的过程。大部分的代码生成器主要过程是,不断的访问Transformation生成的AST(抽象语法树)或者再结合tokens,按照指定的规则,将“树”上的节点打印拼接最终还原为新的code,自此编译器的执行过程就结束了。
简易编译器原理
生成tokens
这是词法分析的步骤,这个过程需要tokenzier(分词器)函数
思路:
遍历字符串,将每个字符按照规则抽离出来,最终生成tokens数组
简易来做就是遇到
- 括号生成新token,
- 检测字符是否有空格来进行分隔,但是在token中空格是无意义的
- 检测数字或函数name,持续向后匹配直到失败...
| function tokenizer (input) { let current = 0; //记录当前访问的位置 let tokens = [] // 最终生成的tokens // 循环遍历input while (current < input.length) { let char = input[current]; // 如果字符是开括号,我们把一个新的token放到tokens数组里,类型是`paren` if (char === '(') { tokens.push({ type: 'paren', value: '(', }); current++; continue; } // 闭括号做同样的操作 if (char === ')') { tokens.push({ type: 'paren', value: ')', }); current++; continue; } //空格检查,我们关心空格在分隔字符上是否存在,但是在token中他是无意义的 let WHITESPACE = /\s/; if (WHITESPACE.test(char)) { current++; continue; } //接下来检测数字,这里解释下 如果发现是数字我们如 add 22 33 这样 //我们是不希望被解析为2、2、3、3这样的,我们要遇到数字后继续向后匹配直到匹配失败 //这样我们就能截取到连续的数字了 let NUMBERS = /[0-9]/; if (NUMBERS.test(char)) { let value = ''; while (NUMBERS.test(char)) { value += char; char = input[++current]; } tokens.push({ type: 'number', value }); continue; } // 接下来检测字符串,这里我们只检测双引号,和上述同理也是截取连续完整的字符串 if (char === '"') { let value = ''; char = input[++current]; while (char !== '"') { value += char; char = input[++current]; } char = input[++current]; tokens.push({ type: 'string', value }); continue; } // 最后一个检测的是name 如add这样,也是一串连续的字符,但是他是没有“”的 let LETTERS = /[a-z]/i; if (LETTERS.test(char)) { let value = ''; while (LETTERS.test(char)) { value += char; char = input[++current]; } tokens.push({ type: 'name', value }); continue; } // 容错处理,如果我们什么都没有匹配到,说明这个token不在我们的解析范围内 throw new TypeError('I dont know what this character is: ' + char); } return tokens } |
生成AST
将生成好的token转换为AST
遍历访问生成好的AST,同时根据自己需要进行转化
| * Original AST | Transformed AST * ---------------------------------------------------------------------------- * { | { * type: 'Program', | type: 'Program', * body: [{ | body: [{ * type: 'CallExpression', | type: 'ExpressionStatement', * name: 'add', | expression: { * params: [{ | type: 'CallExpression', * type: 'NumberLiteral', | callee: { * value: '2' | type: 'Identifier', * }, { | name: 'add' * type: 'CallExpression', | }, * name: 'subtract', | arguments: [{ * params: [{ | type: 'NumberLiteral', * type: 'NumberLiteral', | value: '2' * value: '4' | }, { * }, { | type: 'CallExpression', * type: 'NumberLiteral', | callee: { * value: '2' | type: 'Identifier', * }] | name: 'subtract' * }] | }, * }] | arguments: [{ * } | type: 'NumberLiteral', * | value: '4' * ---------------------------------- | }, { * | type: 'NumberLiteral', * | value: '2' * | }] * | } * | } * | }] * | } |
| function transformer (ast) { // 将要被返回的新的AST let newAst = { type: 'Program', body: [], }; // 这里相当于将在旧的AST上创建一个_content,这个属性就是新AST的body,因为是引用,所以后面可以直接操作就的AST ast._context = newAst.body; // 用之前创建的访问器来访问这个AST的所有节点 traverser(ast, { // 针对于数字片段的处理 NumberLiteral: { enter (node, parent) { // 创建一个新的节点,其实就是创建新AST的节点,这个新节点存在于父节点的body中 parent._context.push({ type: 'NumberLiteral', value: node.value, }); }, }, // 针对于文字片段的处理 StringLiteral: { enter (node, parent) { parent._context.push({ type: 'StringLiteral', value: node.value, }); }, }, // 对调用语句的处理 CallExpression: { enter (node, parent) { // 在新的AST中如果是调用语句,type是`CallExpression`,同时他还有一个`Identifier`,来标识操作 let expression = { type: 'CallExpression', callee: { type: 'Identifier', name: node.value, }, arguments: [], }; // 在原来的节点上再创建一个新的属性,用于存放参数 这样当子节点修改_context时,会同步到expression.arguments中,这里用的是同一个内存地址 node._context = expression.arguments; // 这里需要判断父节点是否是调用语句,如果不是,那么就使用`ExpressionStatement`将`CallExpression`包裹,因为js中顶层的`CallExpression`是有效语句 if (parent.type !== 'CallExpression') { expression = { type: 'ExpressionStatement', expression: expression, }; } parent._context.push(expression); }, } }); return newAst; } |
新代码生成
用新的AST遍历每一个节点,根据对应规则生成最终代码
| function codeGenerator(node) { // 我们以节点的种类拆解(语法树) switch (node.type) { // 如果是Progame,那么就是AST的最根部了,他的body中的每一项就是一个分支,我们需要将每一个分支都放入代码生成器中 case 'Program': return node.body.map(codeGenerator) .join('\n'); // 如果是声明语句注意看新的AST结构,那么在声明语句中expression,就是声明的标示,我们以他为参数再次调用codeGenerator case 'ExpressionStatement': return ( codeGenerator(node.expression) + ';' ); // 如果是调用语句,我们需要打印出调用者的名字加括号,中间放置参数如生成这样"add(2,2)", case 'CallExpression': return ( codeGenerator(node.callee) + '(' + node.arguments.map(codeGenerator).join(', ') + ')' );
// 如果是识别就直接返回值 如: (add 2 2),在新AST中 add就是那个identifier节点 case 'Identifier': return node.name; // 如果是数字就直接返回值 case 'NumberLiteral': return node.value; // 如果是文本就给值加个双引号 case 'StringLiteral': return '"' + node.value + '"'; // 容错处理 default: throw new TypeError(node.type); } } |
实际应用
使用Babel修改函数名
| //源代码 const hello = () => {}; //需要修改为: const world = () => {}; |
思路:
- 先将源代码转化成AST
- 遍历AST上的节点,找到 hello 函数名节点并修改
- 将转换过的AST再生成JS代码
实现:
找到name为hello的节点,进行修改
| const parser = require("@babel/parser"); const traverse = require("@babel/traverse"); const generator = require("@babel/generator"); // 源代码 const code = ` const hello = () => {}; `; // 1. 源代码解析成 ast const ast = parser.parse(code); // 2. 转换 const visitor = { // traverse 会遍历树节点,只要节点的 type 在 visitor 对象中出现,变化调用该方法 Identifier(path) { const { node } = path; //从path中解析出当前 AST 节点 if (node.name === "hello") { node.name = "world"; //找到hello的节点,替换成world } }, }; traverse.default(ast, visitor); // 3. 生成 const result = generator.default(ast, {}, code); console.log(result.code); //const world = () => {}; |
手写监控系统中的日志上传插件
在监控系统的日志上传过程中,我们需要往每个函数的作用域中添加一行日志执行函数
源代码:
| //四种声明函数的方式 function sum(a, b) { return a + b; } const multiply = function (a, b) { return a * b; }; const minus = (a, b) => a - b; class Calculator { divide(a, b) { return a / b; } } |
期望转换后的代码:
| import loggerLib from "logger" function sum(a, b) { loggerLib() return a + b; } const multiply = function (a, b) { loggerLib() return a * b; }; const minus = (a, b) =>{ loggerLib() return a - b; } class Calculator { divide(a, b) { loggerLib() return a / b; } } |
整体思路:
- 第一步:先判断源代码中是否引入了logger库
- 第二步:如果引入了,就找出导入的变量名,后面直接使用该变量名即可
- 第三步:如果没有引入我们就在源代码的顶部引用一下
- 第四步:在函数中插入引入的函数
前端工程化基石 -- AST(抽象语法树)以及AST的广泛应用🔥本文将从一道小学语文题出发,由浅入深的讲述AST的设计 - 掘金
AST静态分析的工作原理
- 代码解析:首先将源代码解析成AST
- 遍历AST:使用访问者模式(Visitor Pattern)遍历AST树
- 规则检查:在遍历过程中编写脚本同时使用各种规则来检查代码问题
- 报告生成:收集发现的问题并生成报告
AST静态分析的优势
- 全面性:可以分析整个代码库,而不仅仅是执行路径
- 早期发现:在编码阶段就能发现潜在问题,而不是等到运行时
- 规则可定制:可以根据项目需求定制检查规则
- 自动化:可以集成到CI/CD流程中自动检查代码
clang-format代码格式化原理
与完整编译器不同,Clang-Format 执行的是轻量级解析,主要关注代码结构而非完整语义,但同样的,它也会执行词法分析语法分析,都会将代码分割为tokens,并且生成抽象语法树
但clang-format主要关注的是
- 计算标记间应放置的空格和换行数量
- 基于代码嵌套结构确定缩进量
以此来优化代码格式,同时提供了一些可选的决策来帮助我们格式化,同时还确保格式化不改变代码含义
clang-format的介绍和使用 - JindouBlog - 博客园