LoRA 微调技术详解:参数高效的大模型轻量化适配方案
一、技术背景
在人工智能领域,大模型如 GPT-3、BERT 等展现出了强大的能力,但在实际应用中,对这些大模型进行微调却面临着诸多难题。大模型参数规模动辄数十亿甚至上万亿,以 GPT-3 为例,其参数规模达到了 1750 亿。传统的全量微调方法需要更新模型的所有参数,这不仅需要大量的计算资源,训练成本极高,而且对存储设备的要求也非常苛刻,普通的硬件设备难以承担。同时,在一些场景下,我们可能只需要对大模型进行针对特定任务的适配,并不需要改变其核心的通用能力,全量微调显得过于浪费。因此,寻找一种参数高效的大模型微调方法成为了研究的热点。LoRA(Low-Rank Adaptation)微调技术应运而生,它为大模型的轻量化适配提供了有效的解决方案。
二、LoRA 基本概念
LoRA,即低秩适应,是由微软在 2021 年提出的一种针对大模型微调的技术。其核心思想是在大模型的训练过程中,仅对部分权重矩阵进行低秩分解,引入可训练的低秩矩阵来替代原始高秩矩阵的更新,从而在保持模型性能的同时,极大地减少可训练参数的数量。
(一)核心思想
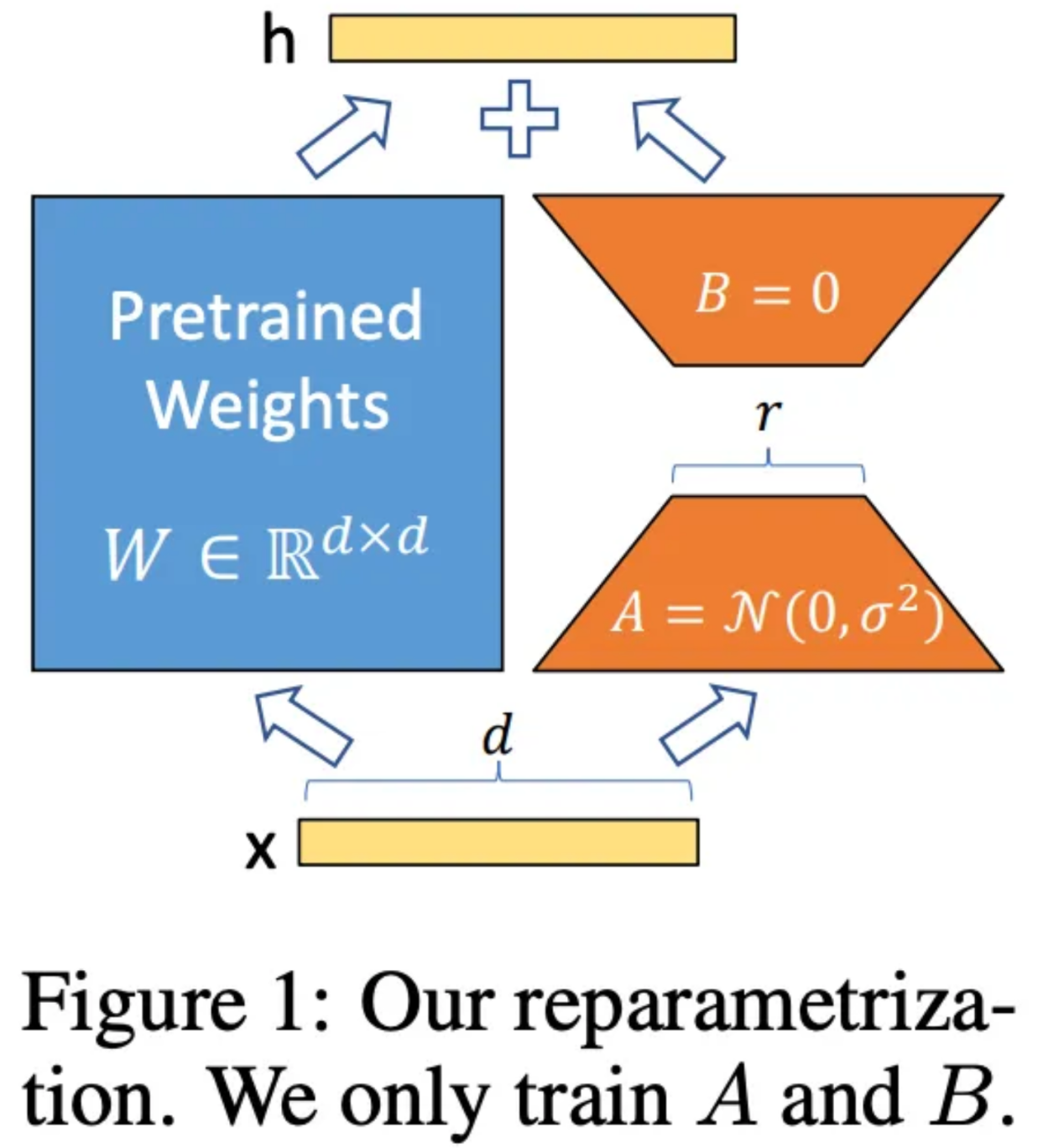
大模型中的权重矩阵通常具有较高的秩,而 LoRA 假设在微调过程中,模型权重的变化可以用一个低秩矩阵来表示。具体来说,对于一个原始的权重矩阵 W,我们将其分解为两个低秩矩阵 A 和 B 的乘积,即 W = W0 + AB,其中 W0 是预训练后的初始权重矩阵,A 和 B 是新引入的可训练的低秩矩阵。在训练过程中,只更新 A 和 B 这两个低秩矩阵,而原始的权重矩阵 W0 保持不变。这样,通过低秩分解,将原本需要更新的高秩矩阵转化为对两个低秩矩阵的更新,从而大大减少了可训练参数的数量。
(二)提出背景
随着大模型的不断发展,模型参数规模呈指数级增长,传统的微调方法在计算资源和时间成本上越来越难以承受。为了实现大模型在实际应用中的高效适配,需要一种能够在不显著降低模型性能的前提下,大幅减少微调参数的技术。LoRA 正是在这样的背景下提出的,它通过巧妙的低秩分解,在保持模型表达能力的同时,实现了参数的高效更新。
三、LoRA 核心原理与技术优势
(一)核心原理
- 低秩分解:对大模型中需要微调的权重矩阵进行低秩分解。假设原始权重矩阵的维度为 d×k,我们引入两个低秩矩阵 A(维度为 r×d)和 B(维度为 k×r),其中 r 是远小于 d 和 k 的秩。这样,通过 A 和 B 的乘积,我们可以近似表示原始权重矩阵的变化量。在训练过程中,只更新 A 和 B 这两个低秩矩阵,而原始的权重矩阵保持不变。
- 秩的选择:秩 r 的大小决定了低秩矩阵的表达能力和参数数量。较小的 r 会减少可训练参数的数量,但可能会影响模型的性能;较大的 r 则会增加参数数量,但能更好地捕捉权重矩阵的变化。在实际应用中,需要根据具体的任务和模型规模来选择合适的 r 值。
(二)技术优势
- 参数效率高:与传统的全量微调相比,LoRA 只更新少量的低秩矩阵参数,可训练参数数量大幅减少。例如,在对一个具有 d×k 维度的权重矩阵进行微调时,传统方法需要更新 dk 个参数,而 LoRA 仅需要更新 r (d + k) 个参数,当 r 远小于 d 和 k 时,参数数量得到显著压缩。
- 计算成本低:由于减少了可训练参数的数量,LoRA 在训练过程中所需的计算资源和时间也相应减少。这使得在普通的硬件设备上进行大模型微调成为可能,降低了应用门槛。
- 存储需求小:在存储方面,LoRA 只需保存原始的预训练模型权重和少量的低秩矩阵参数,无需存储整个模型的所有可训练参数,大大节省了存储空间。
- 适配灵活:LoRA 可以灵活地应用于大模型的不同层和不同模块,例如在 Transformer 模型中,可以对注意力层或前馈神经网络层进行 LoRA 微调,根据具体任务的需求选择需要适配的部分。
- 性能保持良好:大量实验表明,LoRA 在保持与全量微调相近性能的同时,实现了参数的高效更新。这是因为低秩分解能够有效地捕捉模型在微调过程中所需的权重变化,而不会破坏预训练模型已经学习到的通用知识。
四、LoRA 与其他微调技术对比
(一)与全量微调对比
全量微调需要更新模型的所有参数,参数数量庞大,计算成本高,存储需求大,但在理论上能够充分利用训练数据,可能在某些任务上取得更好的性能。而 LoRA 仅更新少量的低秩矩阵参数,参数数量少,计算成本低,存储需求小,虽然性能可能略逊于全量微调,但在大多数情况下能够保持相近的性能,具有更高的效率和实用性。
(二)与适配器(Adapter)技术对比
适配器技术通常是在大模型中插入一个小型的神经网络模块(适配器),通过训练适配器来实现对特定任务的适配。适配器技术也能减少可训练参数的数量,但适配器的结构和位置需要精心设计,不同的模型可能需要不同的适配器配置。相比之下,LoRA 的低秩分解方法更加简洁通用,不需要插入额外的模块,只需对现有权重矩阵进行分解,更容易在不同的模型和任务中应用。
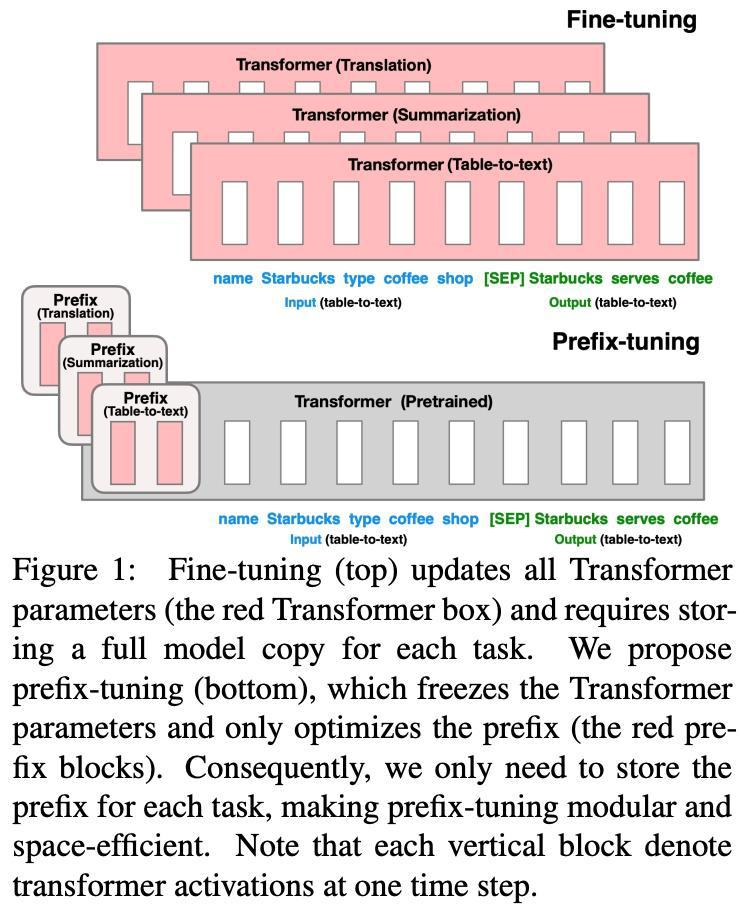
(三)与前缀微调(Prefix Tuning)对比
前缀微调是在输入数据前添加一段可训练的前缀序列,通过训练前缀来引导大模型的输出。前缀微调的参数数量也较少,但前缀的长度和设计会影响模型的性能,且主要适用于自然语言处理任务。LoRA 则可以应用于更广泛的领域,包括计算机视觉等,具有更强的通用性。
五、LoRA 应用场景
(一)自然语言处理领域
- 文本分类:在对大模型进行文本分类任务微调时,使用 LoRA 技术可以减少参数数量,提高训练效率。例如,在对 BERT 模型进行特定领域的文本分类时,通过对注意力层和前馈神经网络层进行 LoRA 微调,能够在保持分类精度的同时,快速完成模型适配。
- 机器翻译:机器翻译需要模型能够准确捕捉不同语言之间的语义和语法差异。LoRA 技术可以针对翻译任务对大模型的编码器和解码器进行局部微调,减少计算成本,提高翻译效率和质量。
- 问答系统:构建问答系统时,使用 LoRA 对大模型进行微调,可以使其更好地理解问题和生成准确的回答。通过对特定的问题处理模块进行低秩适应,能够在有限的计算资源下实现高效的模型优化。
(二)计算机视觉领域
- 图像分类:对于大规模的视觉模型,如 ViT(Vision Transformer),使用 LoRA 进行微调可以显著减少参数数量。在对新的图像数据集进行分类任务时,只需对模型中的部分权重矩阵进行低秩分解和更新,即可快速适应新的任务,降低训练成本。
- 目标检测:目标检测任务需要模型能够准确识别和定位图像中的物体。LoRA 技术可以应用于目标检测模型的特征提取层和检测头,通过对这些部分进行低秩适应,在保持检测精度的同时,提高模型的训练速度和效率。
(三)跨模态任务
在跨模态任务中,如图文匹配、多模态生成等,大模型需要处理多种类型的数据。LoRA 可以针对不同模态的输入和输出模块进行微调,减少跨模态适配时的参数更新量,提高模型在跨模态任务中的性能和效率。
(四)资源受限环境
在移动设备、嵌入式设备等资源受限的环境中,大模型的直接应用受到限制。LoRA 技术通过减少可训练参数的数量,降低了模型对计算资源和存储的需求,使得大模型能够在这些设备上进行微调和部署,拓展了大模型的应用场景。
六、LoRA 实现与实践
(一)实现步骤
- 安装相关库:首先需要安装支持 LoRA 的深度学习库,如 Hugging Face 的 Transformers 库,其中已经集成了 LoRA 的实现模块。可以通过以下命令进行安装:
| pip install transformers |
- 加载预训练模型:选择合适的大模型进行加载,例如 BERT、GPT-2 等。以 BERT 为例,可以使用以下代码加载预训练模型:
| from transformers import BertModel, BertTokenizer model = BertModel.from_pretrained('bert-base-uncased') tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') |
- 定义 LoRA 层:在模型中需要进行微调的层上应用 LoRA 技术。在 Hugging Face 的 Transformers 库中,可以通过设置lora_config参数来定义 LoRA 的配置,包括秩 r、缩放因子、 dropout 率等。例如,对 BERT 的注意力层应用 LoRA:
| from peft import LoraConfig, get_peft_model lora_config = LoraConfig( r=8, # 秩r lora_alpha=32, target_modules=["query", "value"], # 目标模块 lora_dropout=0.1, bias="none", task_type="SEQ_CLASSIFICATION", ) peft_model = get_peft_model(model, lora_config) |
- 设置训练参数:包括学习率、批次大小、训练轮数等。根据任务的需求和模型的规模进行合理设置。
| training_args = TrainingArguments( output_dir='./results', learning_rate=3e-4, per_device_train_batch_size=8, per_device_eval_batch_size=8, num_train_epochs=3, logging_dir='./logs', ) |
- 准备训练数据:将训练数据处理成模型所需的输入格式,例如对于文本分类任务,需要将文本转换为 Token ID,并添加相应的标签。
- 进行训练:使用定义好的模型和训练参数进行训练。
| from transformers import Trainer, Dataset trainer = Trainer( model=peft_model, args=training_args, train_dataset=train_dataset, data_collator=data_collator, ) trainer.train() |
- 推理应用:训练完成后,使用微调后的模型进行推理,处理新的输入数据。
(二)实践技巧
- 选择合适的目标模块:在大模型中,不同的模块对任务的影响不同。通常,注意力层和前馈神经网络层是进行 LoRA 微调的重点模块。需要根据具体的模型结构和任务需求,选择需要应用 LoRA 的目标模块,以达到最佳的适配效果。
- 调整秩 r 的值:秩 r 的选择是 LoRA 微调中的一个重要超参数。较小的 r 会减少参数数量,但可能导致模型性能下降;较大的 r 则会增加参数数量,但能更好地捕捉权重变化。可以通过实验来确定最佳的 r 值,一般可以从较小的值开始尝试,逐步调整。
- 结合其他技术:LoRA 可以与其他技术相结合,如知识蒸馏、模型量化等,进一步提高模型的效率和性能。例如,在 LoRA 微调后,对模型进行量化处理,可以减少模型的存储空间和推理时间,使其更适合在资源受限的环境中部署。
- 监控训练过程:在训练过程中,要及时监控损失函数、准确率等指标的变化,观察模型是否收敛,是否存在过拟合或欠拟合现象。根据监控结果,调整训练参数和 LoRA 的配置,确保训练过程的稳定性和有效性。
七、总结与展望
(一)总结
LoRA 微调技术作为一种参数高效的大模型轻量化适配方案,通过低秩分解的方法,在保持模型性能的同时,显著减少了可训练参数的数量,降低了计算成本和存储需求。它具有广泛的应用场景,在自然语言处理、计算机视觉、跨模态任务等领域都展现出了良好的效果,为大模型的实际应用提供了有力的支持。
(二)优势与局限性
- 优势
- 参数高效:极大地减少了微调过程中的可训练参数数量,使大模型微调在普通硬件上成为可能。
- 适配灵活:可以灵活地应用于大模型的不同层和模块,适用于多种任务和场景。
- 成本低廉:降低了训练过程中的计算资源和时间成本,以及模型的存储成本。
- 性能保持良好:在大多数情况下,能够保持与全量微调相近的性能。
- 局限性
- 性能上限:由于仅更新部分参数,LoRA 的性能可能在一些复杂任务上略低于全量微调。
- 秩的选择:秩 r 的选择需要通过实验确定,增加了一定的调参成本。
- 适用场景:对于需要对模型进行大规模结构调整的任务,LoRA 可能不太适用。
总之,LoRA 微调技术为大模型的高效适配提供了一条可行的路径,随着技术的不断发展和完善,它将在人工智能领域发挥更加重要的作用,推动大模型在各个行业的落地应用。