代码实现包括生成标签文件和处理训练集及测试集
之前项目的训练集和测试集通常由他人提供但是有时候需要读取本地数据,接下来,我们以实例食物分类案例,来介绍如何从本地读取数据的测试集和训练集,并为它们打上标签
- .训练数据集通常由他人提供,但有时需要读取本地数据。
- 实例分类案例中训练集和测试集分别存储在不同的目录中,目录结构清晰
 。
。 - 真实照片的识别更具挑战性,需要准确的标签来进行训练
- 标签文件通常包含图片的路径和对应的标签结果
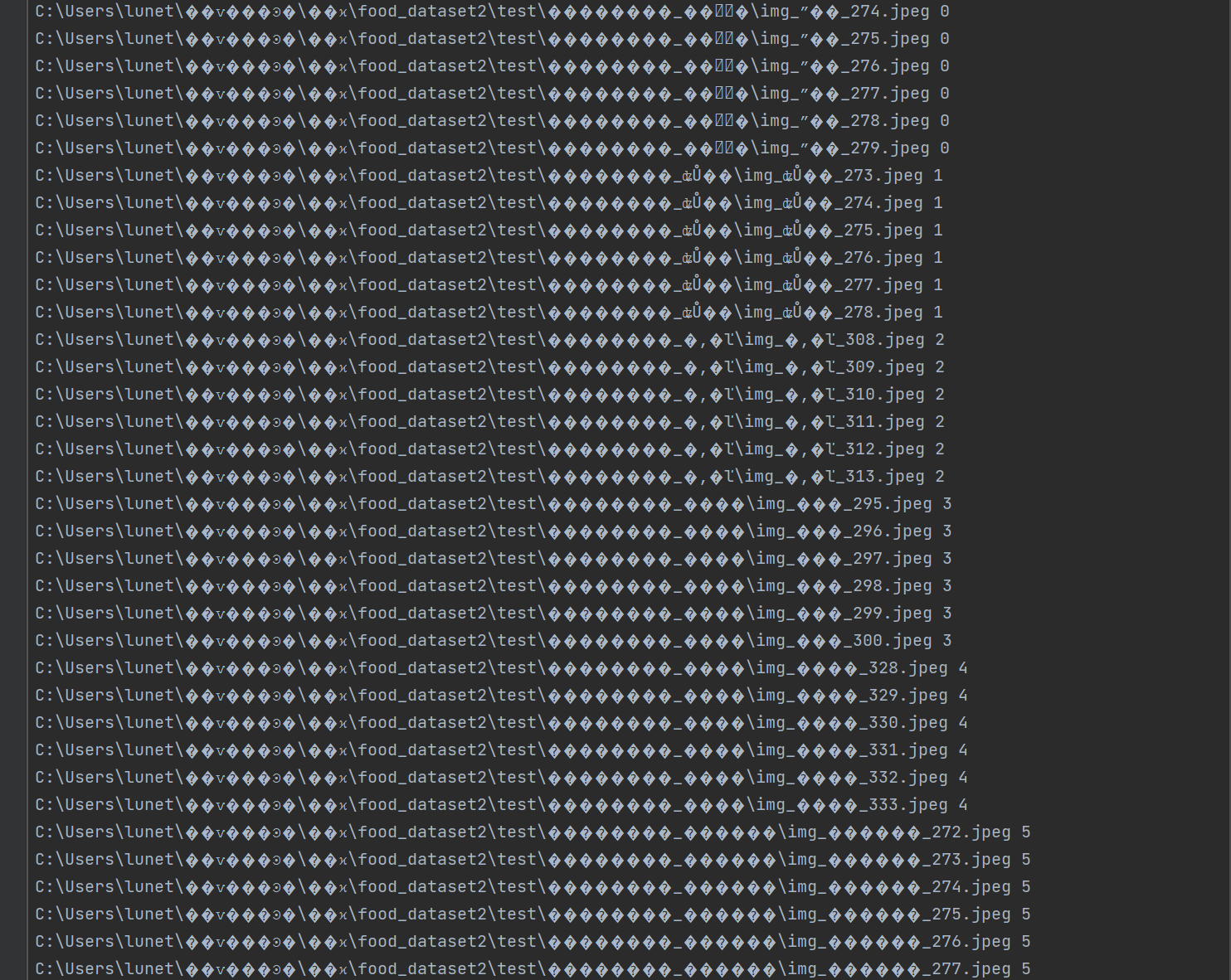
- 标签文件可以通过代码自动生成,包含图片的路径和标签结果
下面代码的目的是为图像分类任务生成训练集和测试集的标签文件。具体来说:
自动创建标签文件:根据输入的根目录和数据集类型(如"train"或"test"),在指定位置生成对应的文本文件(如
train.txt)。构建图片与标签的映射关系:通过遍历目录结构,将每个图片的完整路径与其所属类别建立对应关系。类别标签由父目录的子目录顺序决定(第一个子目录为0,第二个为1,依此类推)。
格式输出:将结果写入文本文件,每行格式为
<图片路径> <标签>(例如:"八宝粥/image1.jpg 0"),便于后续用于机器学习模型的训练数据加载。
代码实现:代码实现包括生成标签文件和处理训练集及测试集
import os # 导入操作系统相关模块,用于路径操作def train_test_file(root, dir): # 定义生成标签文件的函数,接收根目录和数据集类型(train/test)file_txt = open(dir+'.txt','w') # 创建以dir命名的文本文件(如train.txt),用于写入标签path = os.path.join(root, dir) # 组合根目录和数据集类型形成完整路径(如食物分类/food_dataset/train)for roots, directories, files in os.walk(path): # 遍历指定路径下的所有目录和文件if len(directories) != 0 : # 如果当前目录有子目录(非叶子节点)dirs = directories # 保存当前目录的子目录列表else: # 如果当前目录是叶子节点(无子目录)now_dir = roots.split('\\') # 将当前目录路径按反斜杠分割成列表(如['食物分类', 'food_dataset', '八宝粥'])for file in files: # 遍历当前目录下的所有文件path_1 = os.path.join(roots, file) # 组合出完整文件路径(如食物分类/food_dataset/八宝粥/image1.jpg)print(path_1) # 打印文件路径(调试用)file_txt.write(path_1+' '+str(dirs.index(now_dir[-1]))+'\n') # 写入文件路径和对应标签# 示例:八宝粥目录的文件会被标记为0,哈密瓜为1等file_txt.close() # 关闭文件流root = r'.\食物分类\food_dataset' # 图片存储根目录(相对路径),路径最好不包含空格,避免读取错误。
train_dir = 'train' # 训练集目录名
test_dir = 'test' # 测试集目录名
train_test_file(root, train_dir) # 生成训练集标签文件(train.txt)
train_test_file(root, test_dir) # 生成测试集标签文件(test.txt)
关键点说明:
路径处理
os.path.join自动适配不同操作系统的路径分隔符(Windows用\,Linux用/)roots.split('\\')将路径转换为层级列表,便于获取当前目录名称(now_dir[-1])
标签生成逻辑
- 当遇到叶子节点(无子目录)时,通过
dirs.index(now_dir[-1])确定标签 dirs是父级目录的子目录列表,索引值对应分类编号(如第一个子目录为0)
- 当遇到叶子节点(无子目录)时,通过
数据结构
- 生成的
.txt文件每行格式:<文件路径> <标签>(如八宝粥/image1.jpg 0) - 标签体系基于目录层级顺序自动分配,无需手动维护映射关系
- 生成的
适用场景
- 适合图像分类任务的数据预处理,尤其适用于多类别、多子目录存储的图片数据集
训练自己的数据集
训练数据集通常由他人提供,但有时需要读取本地数据。
实例分类案例中,训练集和测试集分别存储在不同的目录中,目录结构清晰。
真实照片的识别
真实照片的识别更具挑战性,需要准确的标签来进行训练。
标签文件通常包含图片的路径和对应的标签结果。
标签文件的创建
标签文件可以通过代码自动生成,包含图片的路径和标签结果。
路径最好不包含空格,避免读取错误。
小数据集的训练
小数据集包含较少的图片,易于处理和训练。
通过小数据集验证代码的正确性,再扩展到大数据集。
本地数据读取代码实现
代码实现包括生成标签文件和处理训练集及测试集。
使用
os库遍历目录,获取图片路径和标签结果。
主函数和文件操作
主函数负责调用其他函数,完成文件操作。
创建标签文件时使用
w模式,打开文件并写入内容。
遍历目录和子目录
os.walk()函数用于遍历目录和子目录。在遍历过程中,判断文件夹是否为空,并处理其中的文件。
写入标签文件
将图片路径和标签结果写入标签文件。
根据目录的编号给图片分配标签。
测试集的处理
测试集的处理与训练集类似,生成测试集的标签文件。
测试集包含较少的图片,用于验证模型的性能。
数据集的下载和使用
提供小数据集和大数据集的下载链接。
小数据集用于白天上课时的测试,大数据集用于晚上训练。
图片的读取和打包
使用 OpenCV 或 Pillow 库读取图片。
# '''补充1个PIL(pillow图像处理库)的使用介绍 # PIL可以做很多和图像处理相关的事情: # 1、图像归档(Image Archives):PIL非常适合于图像归档以及图像的批处理任务。你可以使用PIL创建缩略图,转换图像格式,打印图像等等。 # 2、图像展示(Image Display):支持包括Tk PhotoImage,BitmapImage还有Windows DIB等接口。PIL支持众多的GUI框架接口,可以用于图像展示。 # 3、图像处理(Image Processing):支持图像的大小转换,图像旋转,以及任意的仿射变换。PIL还有一些直方图的方法,允许你展 # 4、示图像的一些统计特性。这个可以用来实现图像的自动对比度增强,还有全局的统计分析等。 # ''' from PIL import Image img = Image.open(r'.\食物分类\food_dataset\train\薯条\img_薯条_35.jpeg') img.show()#图片显示 print(img.format, img.size, img.mode) #打印图片属性 img.save(r'.\食物分类\food_dataset\train\薯条\img_薯条_36.png') #保存为将64张图片打包成一个包裹,并放到 GPU 中进行训练。
__getitem__方法的应用__getitem__方法允许通过中括号索引的方式获取列表、字典或字符串中的元素。在 PyTorch 中,
__getitem__方法用于从数据集中提取指定索引的图片。class USE_getitem(): #定义一个类,python if __name__def __init__(self, text): #调用类的时候,就运行init,初始化textself.text = textdef __getitem__(self, index):# 可以通过列表索引的方式获取类对象的数据result = self.text[index].upper()#字符串中一个方法,将字符串大写return resultdef __len__(self):return len(self.text) p = USE_getitem("pytorch") #对象数据, 列表 、字符串 print(p[0],p[1]) #对数据对象p进行[]的操作,就会执行__getitem的函数# 字符串,列表 print(len(p))#当对数据对象p执行len函数操作时,就会自动运行__len__方法。
自定义类的长度检测
自定义类可以通过实现
__len__方法来检测其长度。该方法允许使用
len()函数来获取自定义类的长度。