Scikit-learn Python机器学习 - 特征预处理 - 标准化 (Standardization):StandardScaler
锋哥原创的Scikit-learn Python机器学习视频教程:
2026版 Scikit-learn Python机器学习 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili
课程介绍

本课程主要讲解基于Scikit-learn的Python机器学习知识,包括机器学习概述,特征工程(数据集,特征抽取,特征预处理,特征降维等),分类算法(K-临近算法,朴素贝叶斯算法,决策树等),回归与聚类算法(线性回归,欠拟合,逻辑回归与二分类,K-means算法)等。
Scikit-learn Python机器学习 - 特征预处理 - 标准化 (Standardization):StandardScaler
归一化是基于最大值和最小值的,因此异常值(outliers)会对归一化的结果产生较大影响。极端情况下,一个异常值可能会将整个特征的范围压缩到很小的范围,从而导致其他正常数据的表示能力下降。
所以我们引入能够尽可能降低异常值对数据处理结果影响的标准化计算操作。将特征缩放为均值为 0,方差为 1 的标准正态分布。
标准化(Standardization)公式是:
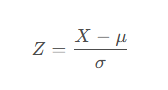
公式各部分详解

工作原理
标准化将原始数据转换为均值为0、标准差为1的标准正态分布。具体来说:

标准化的意义
-
统一量纲:将不同量纲、不同范围的特征转换到同一尺度上
-
中心化:转换后分布的中心在0点
-
标准化尺度
:转换后的值表示"偏离平均值多少个标准差"
-
Z = 0:表示该数据点恰好等于均值
-
Z = 1:表示该数据点比均值高出一个标准差
-
Z = -2:表示该数据点比均值低两个标准差
-
在Scikit-learn中,使用StandardScaler进行标准化操作。
初始化 StandardScaler 对象时,有以下参数:
-
with_mean: boolean, 默认为 True-
作用:是否对数据居中(减去均值)。如果设置为 False,则不会减去均值,计算过程变为
x / σ。对于稀疏矩阵,设置with_mean=False是推荐且默认的,因为居中会破坏矩阵的稀疏性。
-
-
with_std: boolean, 默认为 True-
作用:是否将数据缩放到单位方差(除以标准差)。如果设置为 False,则计算过程变为
x - μ,只进行居中处理。
-
在调用 fit 或 fit_transform 之后,StandardScaler 对象会获得以下属性:
-
mean_:每个特征(列)在训练数据中的均值(μ)。 -
var_:每个特征(列)在训练数据中的方差。 -
scale_:每个特征(列)在训练数据中的标准差(σ)。这是实际应用于transform的缩放比例。 -
n_samples_seen_:处理器在每个特征中处理的样本数(用于在线计算均值/方差)。 -
n_features_in_:训练时使用的特征数量。 -
feature_names_in_:训练时使用的特征名称(如果输入的是 Pandas DataFrame)。
我们看一个示例:
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler# 创建示例数据,包含不同类型的问题
data = {'age': [25, 30, np.nan, 45, 60, 30, 15], # 数值,含缺失值'salary': [50000, 54000, 60000, np.nan, 100000, 40000, 20000], # 数值,尺度大,含缺失值'country': ['USA', 'UK', 'China', 'USA', 'India', 'China', 'UK'], # 分类型'gender': ['M', 'F', 'F', 'M', 'M', 'F', 'F'] # 分类型
}df = pd.DataFrame(data)
print("原始数据:")
print(df)# 策略通常为 mean(均值), median(中位数), most_frequent(众数), constant(固定值)
imputer = SimpleImputer(strategy='mean')# 我们只对数值列进行填充
numeric_features = ['age', 'salary']
df_numeric = df[numeric_features]# fit 计算用于填充的值(这里是均值),transform 应用填充
imputer.fit(df_numeric)
df[numeric_features] = imputer.transform(df_numeric)print("\n处理缺失值后:")
print(df)standard_scaler = StandardScaler()df_numeric = df[['age', 'salary']]
# 根据数据训练生成模型
standard_scaler.fit(df_numeric)
# 根据模型训练数据
df_standardized = standard_scaler.transform(df_numeric)print("\n标准化后的数值特征:")
print(df_standardized)
print(f"标准化后的方差:{df_standardized.std()}")运行输出:
[[-0.68032458 -0.17837652][-0.30923844 0. ][ 0. 0.26756478][ 0.80401995 0. ][ 1.91727835 2.05132995][-0.30923844 -0.62431781][-1.42249684 -1.51620039]]数学知识,什么是标准正太分布:
正态分布的概率密度函数显示为典型的钟形曲线,这一形状类似于寺庙中的大钟,因此也常被称为钟形曲线。作为一种连续分布,正态分布拥有完备的概率密度函数、累积分布函数、矩生成函数和特征函数等表达形式,并且具备明确的期望(即均值)、方差、偏度和峰度等数值特征。
(我们可以参考动画学习 正太分布 转载自抖音成其老师)