【完整源码+数据集+部署教程】陶瓷物品实例分割系统源码和数据集:改进yolo11-LVMB
背景意义
随着科技的不断进步,计算机视觉技术在各个领域的应用愈发广泛,尤其是在物品识别和实例分割方面。陶瓷艺术作为一种传统工艺,不仅承载着丰富的文化内涵,也在现代生活中占据了重要的地位。陶瓷物品的多样性和复杂性使得其在图像识别和分割中面临诸多挑战。因此,开发一个高效的陶瓷物品实例分割系统,不仅有助于提升计算机视觉技术在艺术品领域的应用,也为陶瓷产业的数字化转型提供了新的思路。
本研究旨在基于改进的YOLOv11模型,构建一个针对陶瓷物品的实例分割系统。该系统将使用包含1300张图像的陶瓷数据集,涵盖13个类别,包括碗、装饰花瓶、鱼尾花瓶、盘子等。这些类别的多样性为模型的训练提供了丰富的样本,有助于提高模型的泛化能力和识别精度。通过对数据集的深入分析和处理,结合YOLOv11的高效性和准确性,期望能够实现对陶瓷物品的精确分割和识别。
此外,陶瓷物品的实例分割不仅在艺术品鉴定、市场分析等领域具有重要意义,也为智能家居、虚拟现实等新兴应用提供了技术支持。通过将传统陶瓷与现代科技相结合,本研究不仅推动了计算机视觉技术的发展,也为陶瓷文化的传播和保护提供了新的工具和方法。因此,基于改进YOLOv11的陶瓷物品实例分割系统的研究,具有重要的学术价值和实际应用意义。
图片效果
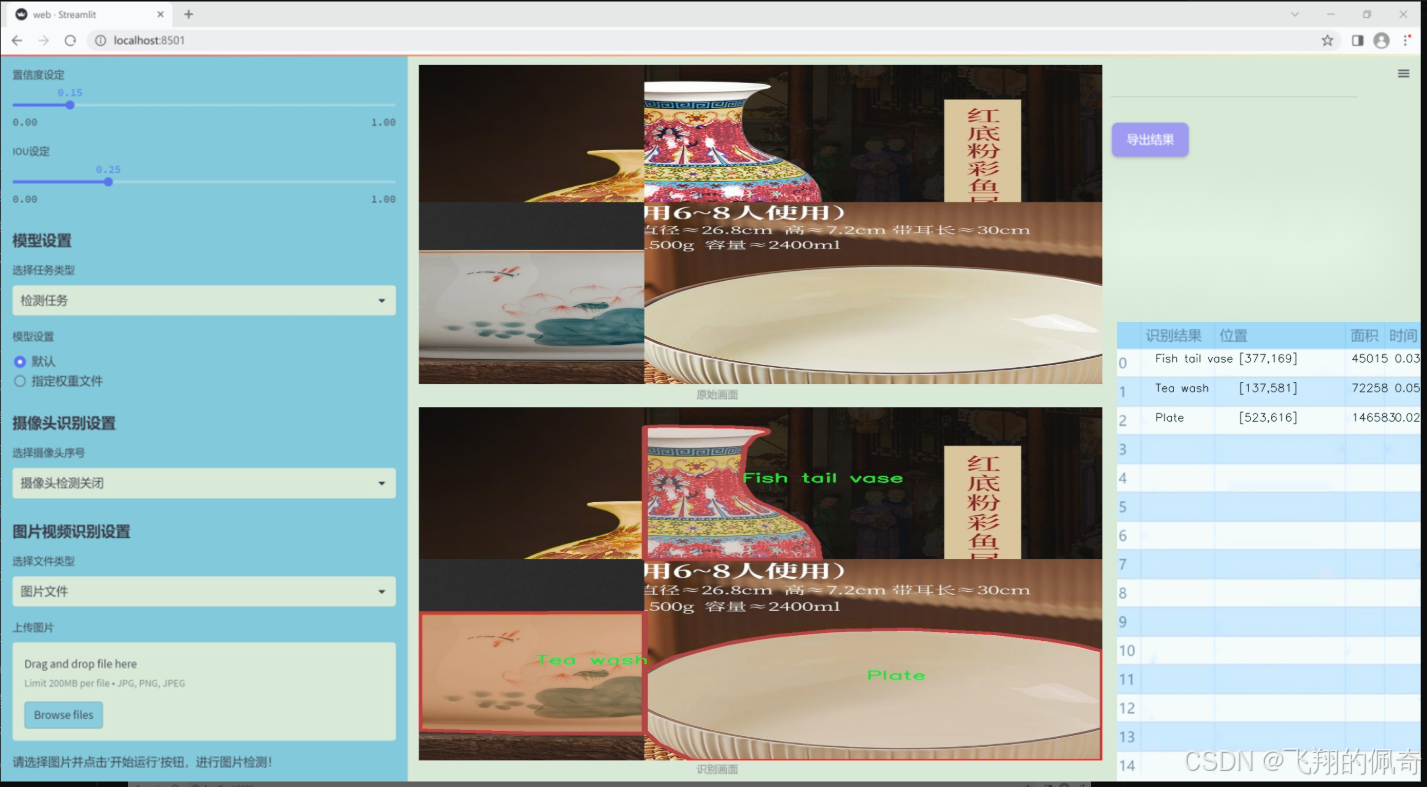
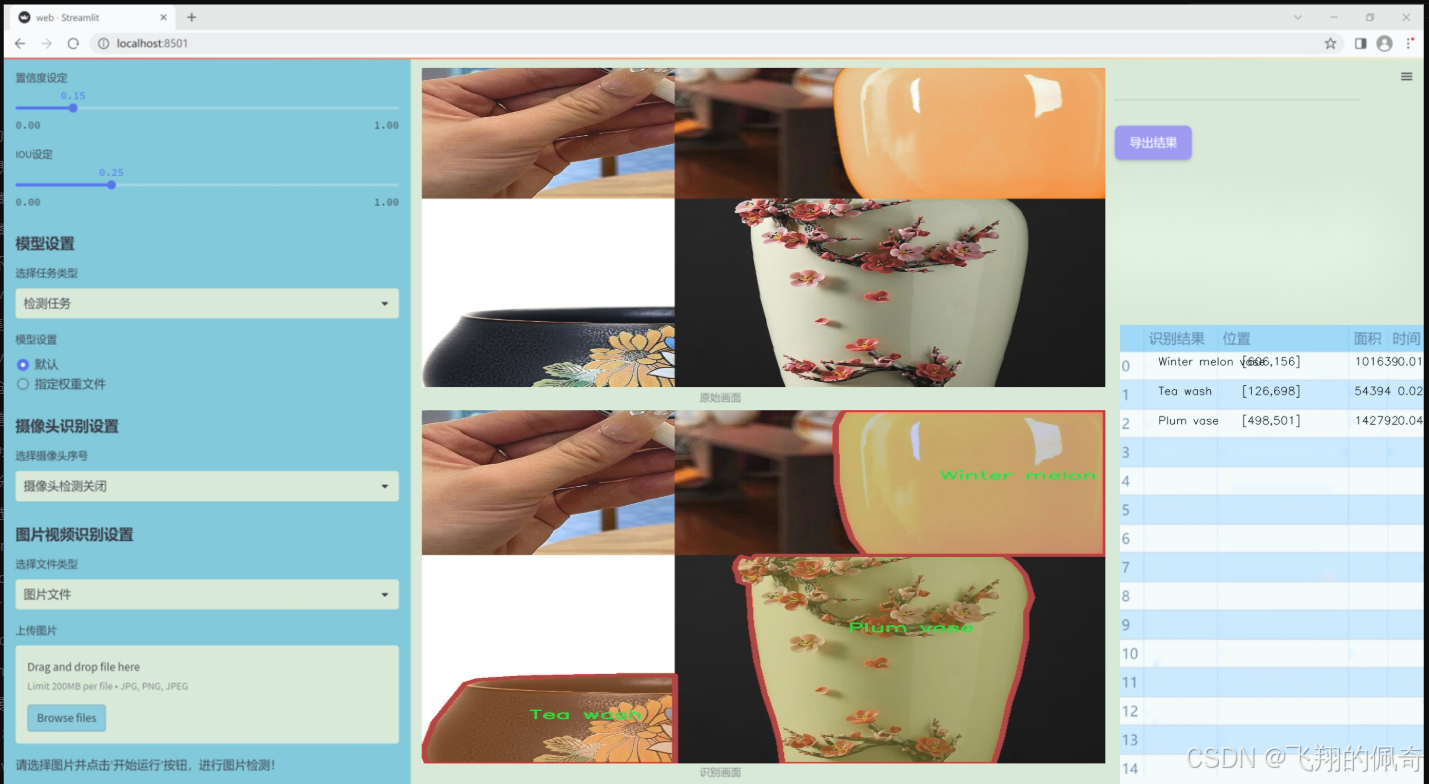
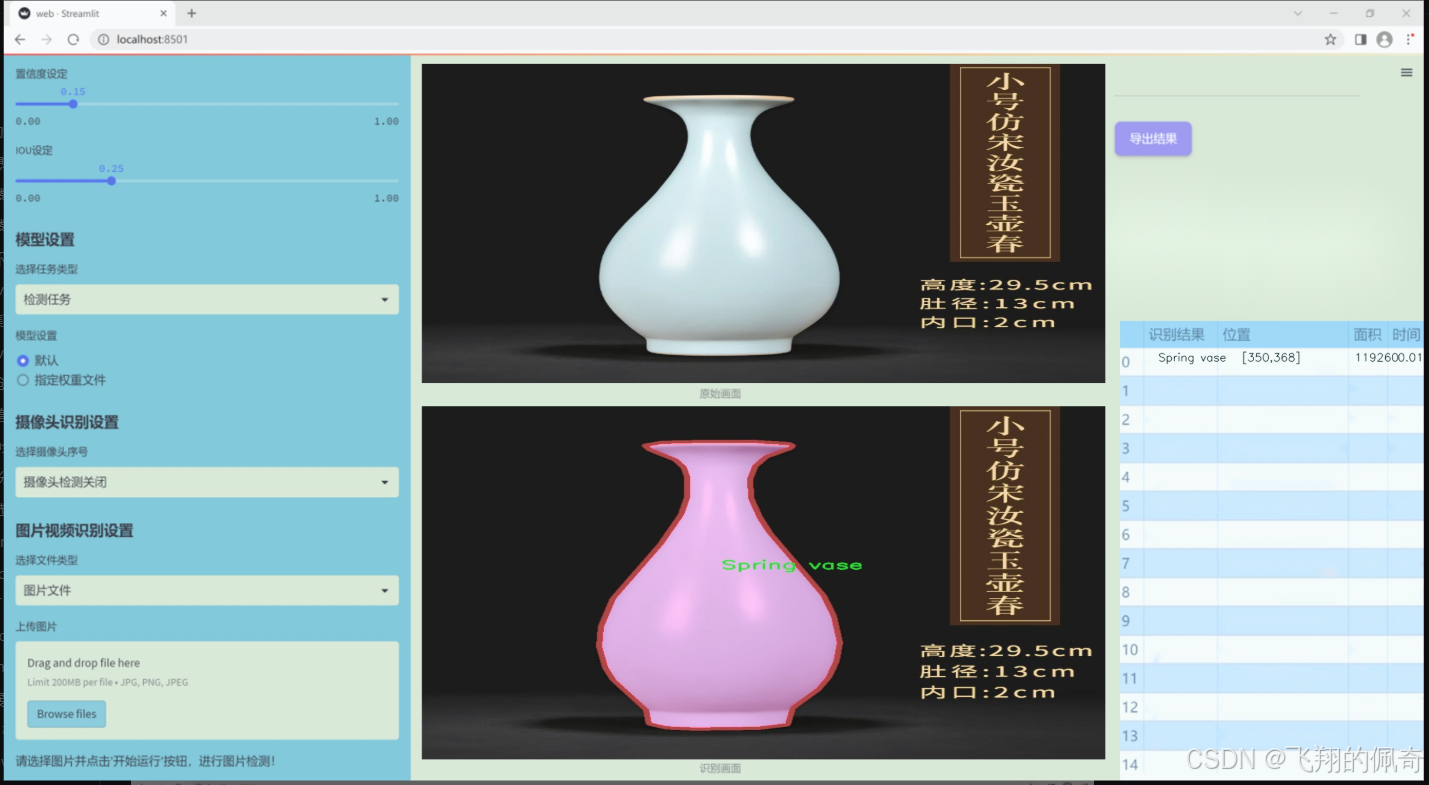
数据集信息
本项目旨在改进YOLOv11的陶瓷物品实例分割系统,所使用的数据集主题为“ceramics 2”。该数据集专注于多种陶瓷物品的识别与分割,包含13个不同的类别,涵盖了广泛的陶瓷制品。这些类别包括:碗(Bowl)、装饰花瓶(Decorative vase)、鱼尾花瓶(Fish tail vase)、盘子(Plate)、梅花花瓶(Plum vase)、石榴花瓶(Pomegranate vase)、汤勺(Soup spoon)、春季花瓶(Spring vase)、茶洗(Tea wash)、茶杯(Teacup)、茶壶(Teapot)、水杯(Water glass)以及冬瓜花瓶(Winter melon vase)。这些类别的选择不仅反映了陶瓷艺术的多样性,也为模型的训练提供了丰富的样本。
数据集中的每个类别均包含大量的图像,确保了模型在训练过程中能够接触到不同形状、颜色和纹理的陶瓷物品。这种多样性对于提高模型的泛化能力至关重要,使其能够在实际应用中更准确地识别和分割各种陶瓷物品。此外,数据集中的图像经过精心标注,确保每个物品的边界清晰可见,为实例分割任务提供了可靠的基础。
通过对“ceramics 2”数据集的深入分析和应用,我们期望能够提升YOLOv11在陶瓷物品实例分割方面的性能,进而推动相关领域的研究与应用。无论是在艺术品鉴定、陶瓷产品的自动化分类,还是在文化遗产保护中,这一改进都将具有重要的实际意义。





核心代码
以下是经过简化和注释的核心代码部分,保留了主要的类和方法,同时添加了详细的中文注释。
import torch
import torch.nn as nn
import numpy as np
from torch.nn import Dropout, Softmax, Conv2d, LayerNorm
class Channel_Embeddings(nn.Module):
“”“构建通道嵌入,包括补丁嵌入和位置嵌入。”“”
def init(self, patchsize, img_size, in_channels):
super().init()
img_size = (img_size, img_size) # 将图像大小转换为元组
patch_size = (patchsize, patchsize) # 将补丁大小转换为元组
n_patches = (img_size[0] // patch_size[0]) * (img_size[1] // patch_size[1]) # 计算补丁数量
# 定义补丁嵌入层self.patch_embeddings = nn.Sequential(nn.MaxPool2d(kernel_size=5, stride=5), # 最大池化层Conv2d(in_channels=in_channels,out_channels=in_channels,kernel_size=patchsize // 5,stride=patchsize // 5) # 卷积层)# 定义位置嵌入参数self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches, in_channels))self.dropout = Dropout(0.1) # dropout层def forward(self, x):"""前向传播,计算嵌入。"""if x is None:return Nonex = self.patch_embeddings(x) # 计算补丁嵌入x = x.flatten(2) # 展平x = x.transpose(-1, -2) # 转置embeddings = x + self.position_embeddings # 添加位置嵌入embeddings = self.dropout(embeddings) # 应用dropoutreturn embeddings
class Attention_org(nn.Module):
“”“自定义的多头注意力机制。”“”
def init(self, vis, channel_num):
super(Attention_org, self).init()
self.vis = vis # 可视化标志
self.KV_size = sum(channel_num) # K和V的大小
self.channel_num = channel_num # 通道数量
self.num_attention_heads = 4 # 注意力头的数量
# 定义查询、键、值的线性变换self.query_layers = nn.ModuleList([nn.Linear(c, c, bias=False) for c in channel_num])self.key = nn.Linear(self.KV_size, self.KV_size, bias=False)self.value = nn.Linear(self.KV_size, self.KV_size, bias=False)self.softmax = Softmax(dim=3) # softmax层self.attn_dropout = Dropout(0.1) # dropout层def forward(self, *embeddings):"""前向传播,计算注意力输出。"""multi_head_Q = [query(emb) for query, emb in zip(self.query_layers, embeddings) if emb is not None]multi_head_K = self.key(torch.cat(embeddings, dim=2)) # 合并所有嵌入并计算Kmulti_head_V = self.value(torch.cat(embeddings, dim=2)) # 合并所有嵌入并计算V# 计算注意力分数attention_scores = [torch.matmul(Q, multi_head_K) / np.sqrt(self.KV_size) for Q in multi_head_Q]attention_probs = [self.softmax(score) for score in attention_scores] # 计算注意力概率# 应用dropout并计算上下文层context_layers = [torch.matmul(prob, multi_head_V) for prob in attention_probs]return context_layers
class Mlp(nn.Module):
“”“多层感知机(MLP)模块。”“”
def init(self, in_channel, mlp_channel):
super(Mlp, self).init()
self.fc1 = nn.Linear(in_channel, mlp_channel) # 第一层全连接
self.fc2 = nn.Linear(mlp_channel, in_channel) # 第二层全连接
self.act_fn = nn.GELU() # 激活函数
self.dropout = Dropout(0.0) # dropout层
def forward(self, x):"""前向传播,计算MLP输出。"""x = self.fc1(x) # 通过第一层x = self.act_fn(x) # 激活x = self.dropout(x) # 应用dropoutx = self.fc2(x) # 通过第二层return x
class Block_ViT(nn.Module):
“”“ViT块,包含注意力和前馈网络。”“”
def init(self, vis, channel_num):
super(Block_ViT, self).init()
self.attn_norm = LayerNorm(sum(channel_num), eps=1e-6) # 归一化层
self.channel_attn = Attention_org(vis, channel_num) # 注意力层
self.ffn = Mlp(channel_num[0], channel_num[0] * 4) # 前馈网络
def forward(self, *embeddings):"""前向传播,计算输出。"""emb_all = torch.cat(embeddings, dim=2) # 合并所有嵌入emb_all = self.attn_norm(emb_all) # 归一化context_layers = self.channel_attn(*embeddings) # 计算注意力上下文outputs = [emb + context for emb, context in zip(embeddings, context_layers)] # 残差连接return outputs
class Encoder(nn.Module):
“”“编码器,包含多个ViT块。”“”
def init(self, vis, channel_num):
super(Encoder, self).init()
self.layer = nn.ModuleList([Block_ViT(vis, channel_num) for _ in range(1)]) # 添加ViT块
def forward(self, *embeddings):"""前向传播,计算编码输出。"""for layer in self.layer:embeddings = layer(*embeddings) # 通过每个块return embeddings
class ChannelTransformer(nn.Module):
“”“通道变换器模型。”“”
def init(self, channel_num=[64, 128, 256, 512], img_size=640, vis=False, patchSize=[40, 20, 10, 5]):
super().init()
self.embeddings = nn.ModuleList([Channel_Embeddings(patchSize[i], img_size // (2 ** (i + 2)), channel_num[i]) for i in range(len(channel_num))])
self.encoder = Encoder(vis, channel_num) # 编码器
self.reconstruct = nn.ModuleList([Reconstruct(channel_num[i], channel_num[i], kernel_size=1, scale_factor=(patchSize[i], patchSize[i])) for i in range(len(channel_num))]) # 重构层
def forward(self, en):"""前向传播,计算最终输出。"""embeddings = [emb(en[i]) for i, emb in enumerate(self.embeddings) if en[i] is not None] # 计算嵌入encoded = self.encoder(*embeddings) # 编码outputs = [recon(enc) + en[i] for i, (recon, enc) in enumerate(zip(self.reconstruct, encoded)) if en[i] is not None] # 重构并添加残差return outputs
class GetIndexOutput(nn.Module):
“”“获取特定索引的输出。”“”
def init(self, index):
super().init()
self.index = index
def forward(self, x):"""前向传播,返回指定索引的输出。"""return x[self.index]
代码说明:
Channel_Embeddings:负责将输入图像分割成补丁并生成对应的嵌入。
Attention_org:实现多头注意力机制,计算输入嵌入之间的注意力分数。
Mlp:实现多层感知机,包含两个全连接层和激活函数。
Block_ViT:包含注意力层和前馈网络的组合,形成一个基本的ViT块。
Encoder:由多个ViT块组成的编码器,负责处理输入的嵌入。
ChannelTransformer:整个模型的主类,负责输入的嵌入、编码和重构。
GetIndexOutput:用于获取特定索引的输出。
这些类和方法共同构成了一个通道变换器模型,能够处理图像数据并提取特征。
这个程序文件 CTrans.py 实现了一个名为 ChannelTransformer 的深度学习模型,主要用于图像处理任务。该模型的设计灵感来源于 Transformer 架构,特别是在处理图像数据时的应用。以下是对文件中各个部分的详细说明。
首先,文件引入了一些必要的库,包括 PyTorch 和 NumPy。这些库提供了构建和训练深度学习模型所需的基础功能。
接下来,定义了多个类,其中 Channel_Embeddings 类用于构建图像的嵌入表示。它通过对输入图像进行最大池化和卷积操作,将图像划分为多个小块(patch),并为每个小块生成位置嵌入。该类的 forward 方法将输入图像转换为嵌入表示,并添加位置嵌入。
Reconstruct 类用于重建特征图。它通过卷积层和上采样操作,将嵌入表示转换回原始图像的尺寸。这个过程有助于在模型的最后阶段恢复图像的空间信息。
Attention_org 类实现了多头自注意力机制。它通过查询(query)、键(key)和值(value)三个部分来计算注意力分数,并生成上下文层。该类的 forward 方法处理多个输入嵌入,计算注意力权重,并通过线性变换输出结果。
Mlp 类是一个简单的多层感知机,包含两个全连接层和一个激活函数(GELU)。它用于在 Transformer 的每个块中进行特征转换。
Block_ViT 类是一个 Transformer 块,包含自注意力机制和前馈网络。它通过残差连接和层归一化来增强模型的稳定性和性能。该类的 forward 方法接收多个嵌入并返回经过处理的嵌入。
Encoder 类由多个 Block_ViT 组成,负责将输入的嵌入进行编码。它的 forward 方法依次通过每个块处理输入,并返回最终的编码结果。
ChannelTransformer 类是整个模型的核心。它初始化了多个嵌入层、编码器和重建层。该类的 forward 方法接收输入特征,生成嵌入,经过编码器处理后,再通过重建层恢复到原始尺寸。
最后,GetIndexOutput 类用于从模型的输出中提取特定索引的结果。这在模型需要返回特定层的输出时非常有用。
总体而言,这个程序文件实现了一个复杂的图像处理模型,结合了卷积、注意力机制和多层感知机等多种深度学习技术,旨在提高图像特征提取和重建的效果。
10.4 shiftwise_conv.py
以下是经过简化和注释的核心代码部分,主要包括卷积层、批归一化、LoRA机制以及重参数化的大核卷积。注释详细解释了每个部分的功能和实现逻辑。
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
def get_conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias):
“”"
创建一个2D卷积层
“”"
return nn.Conv2d(
in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias
)
def get_bn(channels):
“”"
创建一个批归一化层
“”"
return nn.BatchNorm2d(channels)
class Mask(nn.Module):
“”"
定义一个Mask类,用于生成可学习的权重掩码
“”"
def init(self, size):
super().init()
# 初始化权重参数,范围在-1到1之间
self.weight = torch.nn.Parameter(data=torch.Tensor(*size), requires_grad=True)
self.weight.data.uniform_(-1, 1)
def forward(self, x):# 应用sigmoid激活函数并与输入相乘w = torch.sigmoid(self.weight)masked_wt = w.mul(x)return masked_wt
class ReparamLargeKernelConv(nn.Module):
“”"
重参数化的大核卷积类
“”"
def init(self, in_channels, out_channels, kernel_size, small_kernel=5, stride=1, groups=1, small_kernel_merged=False, Decom=True, bn=True):
super(ReparamLargeKernelConv, self).init()
self.kernel_size = kernel_size
self.small_kernel = small_kernel
self.Decom = Decom
padding = kernel_size // 2 # 计算填充大小
# 根据是否合并小卷积选择创建方式if small_kernel_merged:self.lkb_reparam = get_conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=kernel_size,stride=stride,padding=padding,dilation=1,groups=groups,bias=True,)else:if self.Decom:# 使用LoRA机制self.LoRA = conv_bn(in_channels=in_channels,out_channels=out_channels,kernel_size=(kernel_size, small_kernel),stride=stride,padding=padding,groups=groups,bn=bn)else:# 创建原始的大核卷积self.lkb_origin = conv_bn(in_channels=in_channels,out_channels=out_channels,kernel_size=kernel_size,stride=stride,padding=padding,groups=groups,bn=bn,)# 创建小卷积层if (small_kernel is not None) and small_kernel < kernel_size:self.small_conv = conv_bn(in_channels=in_channels,out_channels=out_channels,kernel_size=small_kernel,stride=stride,padding=small_kernel // 2,groups=groups,bn=bn,)self.bn = get_bn(out_channels) # 批归一化层self.act = nn.SiLU() # 激活函数def forward(self, inputs):# 前向传播if hasattr(self, "lkb_reparam"):out = self.lkb_reparam(inputs)elif self.Decom:out = self.LoRA(inputs)if hasattr(self, "small_conv"):out += self.small_conv(inputs)else:out = self.lkb_origin(inputs)if hasattr(self, "small_conv"):out += self.small_conv(inputs)return self.act(self.bn(out)) # 返回经过激活和批归一化的输出def get_equivalent_kernel_bias(self):# 获取等效的卷积核和偏置eq_k, eq_b = fuse_bn(self.lkb_origin.conv, self.lkb_origin.bn)if hasattr(self, "small_conv"):small_k, small_b = fuse_bn(self.small_conv.conv, self.small_conv.bn)eq_b += small_beq_k += nn.functional.pad(small_k, [(self.kernel_size - self.small_kernel) // 2] * 4)return eq_k, eq_bdef switch_to_deploy(self):# 切换到部署模式,使用等效卷积核和偏置if hasattr(self, 'lkb_origin'):eq_k, eq_b = self.get_equivalent_kernel_bias()self.lkb_reparam = get_conv2d(in_channels=self.lkb_origin.conv.in_channels,out_channels=self.lkb_origin.conv.out_channels,kernel_size=self.lkb_origin.conv.kernel_size,stride=self.lkb_origin.conv.stride,padding=self.lkb_origin.conv.padding,dilation=self.lkb_origin.conv.dilation,groups=self.lkb_origin.conv.groups,bias=True,)self.lkb_reparam.weight.data = eq_kself.lkb_reparam.bias.data = eq_bself.__delattr__("lkb_origin")if hasattr(self, "small_conv"):self.__delattr__("small_conv")
代码说明:
卷积层和批归一化层的创建:get_conv2d和get_bn函数用于创建卷积层和批归一化层。
Mask类:用于生成可学习的权重掩码,通过sigmoid函数将权重限制在0到1之间。
ReparamLargeKernelConv类:实现了重参数化的大核卷积,支持小卷积的合并和LoRA机制。它在初始化时根据参数选择不同的卷积结构,并在前向传播中计算输出。
前向传播:根据不同的模式(重参数化、LoRA、原始卷积)计算输出,并应用激活函数和批归一化。
等效卷积核和偏置的获取:通过get_equivalent_kernel_bias方法计算等效的卷积核和偏置,以便在部署时使用。
切换到部署模式:switch_to_deploy方法用于将模型切换到部署模式,使用等效的卷积核和偏置进行推理。
这个程序文件 shiftwise_conv.py 实现了一个自定义的卷积神经网络模块,主要用于处理大卷积核的卷积操作,并通过小卷积核进行优化。以下是对代码的详细讲解。
首先,文件导入了必要的库,包括 math、torch 及其子模块 torch.nn 和 torch.nn.functional。这些库提供了构建和训练神经网络所需的基础功能。
接下来,定义了一个函数 get_conv2d,用于创建一个二维卷积层。该函数接受多个参数,包括输入通道数、输出通道数、卷积核大小、步幅、填充、扩张、分组和偏置等。函数内部会根据卷积核大小计算填充,并返回一个 nn.Conv2d 对象。
另一个函数 get_bn 用于创建批归一化层 BatchNorm2d,以帮助提高模型的训练稳定性和收敛速度。
接下来定义了一个 Mask 类,它是一个可学习的参数模块。该模块在前向传播中通过对输入进行掩码操作来生成加权输出。掩码权重通过 sigmoid 函数进行归一化处理。
conv_bn_ori 函数用于创建一个包含卷积层和可选的批归一化层的序列。根据输入参数,决定是否添加批归一化层。
LoRAConvsByWeight 类实现了一种新的卷积结构,结合了大卷积核和小卷积核的特性。它通过对输入进行分组卷积和通道重排来实现特征提取。该类的构造函数接受多个参数,包括输入输出通道数、卷积核大小、步幅、分组等。它使用 Mask 类来生成两个掩码,并在前向传播中计算出最终的输出。
forward 方法实现了前向传播逻辑,首先通过小卷积层进行卷积,然后分别对输出进行处理,最后将结果相加。
rearrange_data 方法用于根据索引重排数据,计算填充和步幅,以确保卷积操作的正确性。
shift 方法用于计算填充和卷积窗口的索引,以确保卷积操作不会改变特征图的大小。
conv_bn 函数根据输入的卷积核大小决定使用哪种卷积结构,如果是单一卷积核大小则调用 conv_bn_ori,否则使用 LoRAConvsByWeight。
fuse_bn 函数用于将卷积层和批归一化层融合,以减少推理时的计算量。
ReparamLargeKernelConv 类是整个模块的核心,它实现了大卷积核的重参数化。构造函数中根据输入参数设置卷积层、批归一化层和激活函数。前向传播方法根据是否启用重参数化或小卷积核进行计算。
get_equivalent_kernel_bias 方法用于获取等效的卷积核和偏置,以便在推理阶段使用。
最后,switch_to_deploy 方法用于将模型切换到推理模式,融合卷积和批归一化层,并删除不再需要的层。
总体来说,这个文件实现了一个复杂的卷积结构,旨在通过组合大卷积核和小卷积核的优点来提高模型的性能和效率。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻