CodeBuddy+Lucene 探索与实践日志:记录我如何从零构建桌面搜索引擎

在一次知识管理系统的开发中,我面临一个需求:为用户提供对本地文档(如 TXT、PDF、Word)的全文检索功能。这些文档分散在目录中,用户需要能像使用百度一样,快速找到包含特定关键词的文件。
在我的个人知识库中,堆积着数以千计的 TXT 笔记、PDF 论文和 Word 文档。传统的文件系统搜索仅能匹配文件名,一旦忘记标题,内容再精华的资料也如同石沉大海。
我需要一个能「洞察内容」的搜索工具,其核心需求是:
快速全文检索:能瞬间找到包含特定关键词的所有文档。
轻量级与嵌入式:无需部署 Elasticsearch 等重型服务,一个 JAR 包或桌面应用即可。
可扩展性:能轻松支持多种文件格式。
场景:为何选择 Lucene?
Apache Lucene,这个 Java 领域的全文检索引擎鼻祖,成为了我的不二之选。它不像数据库,却提供了比 LIKE ‘%keyword%’ 高效数万倍的查询能力。
放弃使用现成的搜索引擎软件(如 Elasticsearch),是因为这个场景需要轻量级、嵌入式、无需额外服务进程的解决方案。
我选择用CodeBuddy辅助我编程。因为AI的效率确实比我高。
说干就干!
我用CodeBuddy编程如下:
它的回应是:
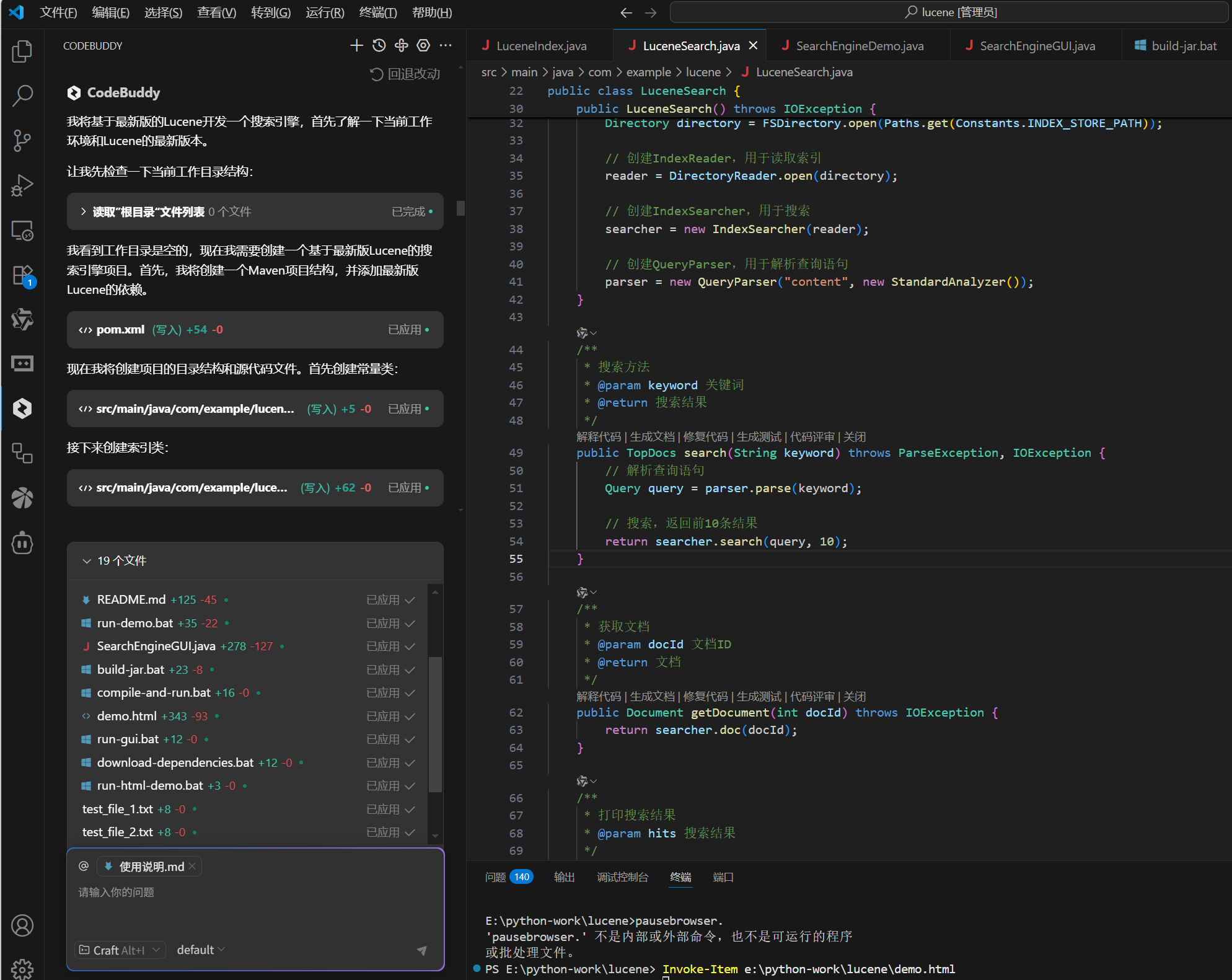
于是这波稳了!
核心组件深度解读与实践
代码已经清晰地勾勒出了 Lucene 的核心工作流。谈谈我对这几个核心类的实践心得。
1. IndexWriter:索引的引擎
这是构建一切的基础。代码中:
IndexWriter indexWriter = new IndexWriter(indexDir, luceneAnalyzer, true);
indexDir: 这里我选择了 FSDirectory(文件系统目录)来存放索引。这对于需要持久化、索引量较大的场景是必须的。对于高速缓存的临时索引,RAMDirectory(内存目录)会是更好的选择,速度极快,但程序关闭即丢失。
luceneAnalyzer: 分析器是 Lucene 的灵魂所在。使用的 StandardAnalyzer 是一个很好的通用选择,它会做大小写转换、去除停用词(the, is, in…)、拆分词汇。但在中文场景下,它默认按空格分词的策略会完全失效,必须替换为 IKAnalyzer、JiebaAnalyzer 等中文分词器。
true: 这个参数意味着“覆盖模式”。在首次建索引时这是正确的。但在后续需要增量索引时(如新增了一个文件),必须将其设为 false,否则会清空整个旧索引,这是一个常见的坑。
2. Document 与 Field:信息的载体与结构
Lucene 不直接索引文件,而是索引抽象的 Document 对象。一个 Document 代表一条记录,由多个 Field 组成。您的代码创建了两个 Field:
Field FieldPath = new Field("path", textFiles[i].getPath(), Field.Store.YES, Field.Index.NO);
Field FieldBody = new Field("body", temp, Field.Store.YES, Field.Index.TOKENIZED, Field.TermVector.WITH_POSITIONS_OFFSETS);
这是我的第一个重要优化点:Field的配置策略。
Field.Path:
Field.Store.YES: 意味着将原始值(文件路径)存储在索引中。这样后续搜索到这条记录时,能直接取出这个值来使用(比如打开文件)。
Field.Index.NO: 意味着不对这个字段的内容进行索引。我们不会通过搜索“C:\”来找到文件,所以无需索引。这节省了索引空间。
仔细为每个 Field 定义 Store 和 Index 属性是优化索引性能和大小的关键。只索引需要搜索的字段,只存储需要展示的字段。
Field.Body:
Field.Index.TOKENIZED: 表示需要对该字段内容进行分词索引,这是全文检索的基础。
Field.TermVector.WITH_POSITIONS_OFFSETS: 存储词向量(Term Vector)信息,包含位置和偏移量。这是一个高级特性,它使得高亮(Highlighting)功能成为可能。搜索引擎结果中的关键词红色高亮,就依赖于这些存储的位置信息。虽然会增加索引体积,但对于需要展示摘要和高亮的场景,必不可少。
3. 索引构建流程
您的 for 循环清晰地展示了流程:遍历文件 -> 读取内容 -> 构建 Document -> 加入 IndexWriter。
性能注意: 对于大量文件,indexWriter.addDocument(document) 之后,最后调用 indexWriter.optimize() 和 close() 是正确且必要的。optimize() 会将多个索引段合并优化,提升后续搜索速度,但这是一个耗时操作,建议在索引构建的最终阶段进行一次即可。
将非结构化数据转化为可搜索的结构实现代码如下:
// 关键代码示例 1: 初始化 IndexWriter
Path indexPath = Paths.get("C:\\index");
Directory directory = FSDirectory.open(indexDir);
StandardAnalyzer analyzer = new StandardAnalyzer(); // 注意:中文场景需替换
IndexWriterConfig config = new IndexWriterConfig(analyzer);
config.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND); // 核心配置:追加模式try (IndexWriter writer = new IndexWriter(directory, config)) {// 遍历文件,构建索引Files.walk(Paths.get("C:\\liuzm")).filter(Files::isRegularFile).filter(p -> p.toString().endsWith(".txt")).forEach(filePath -> {try {Document doc = new Document();// 存储文件路径,用于后续打开,但不参与分词索引doc.add(new StringField("path", filePath.toString(), Field.Store.YES));// 读取文件内容,并进行分词索引,同时存储原文用于展示String content = new String(Files.readAllBytes(filePath), StandardCharsets.UTF_8);doc.add(new TextField("content", content, Field.Store.YES));writer.addDocument(doc);System.out.println("已索引: " + filePath);} catch (IOException e) {System.err.println("处理文件失败: " + filePath);}});writer.commit(); // 显式提交,确保数据持久化
}
IndexWriterConfig.OpenMode.CREATE_OR_APPEND:这是增量索引的关键。设置为 CREATE 会清空现有索引,而 APPEND 模式在 Lucene 中并不被推荐。CREATE_OR_APPEND 是最佳实践,它会在已有索引的基础上追加新文档,完美支持知识库的持续更新。
Field 的类型选择是性能核心:
StringField:适用于不需要分词的字段,如 ID、路径、URL。它会被整体索引,只能进行精确匹配。
TextField:适用于需要分词的文本内容。Field.Store.YES 意味着存储原始内容,这样在搜索结果中可以直接展示摘要片段,但会增大索引体积。如果不需要展示完整内容,可设为 NO 以节省空间。
搜索流程:从关键词到结果
搜索端的代码体现了 Lucene 的核心查询流程:
IndexSearcher: 以只读模式打开索引目录,它是所有搜索操作的入口。
QueryParser: 将用户输入的查询字符串,解析成 Lucene 能够理解的 Query 对象。这是理解 Lucene 搜索的关键。
代码如下:
// 关键代码示例 2: 执行搜索
String queryStr = "Lucene 原理"; // 用户查询输入
Path indexPath = Paths.get("C:\\index");try (Directory directory = FSDirectory.open(indexDir);IndexReader reader = DirectoryReader.open(directory);IndexSearcher searcher = new IndexSearcher(reader)) {// 使用与建索引时相同的分析器!Analyzer analyzer = new IKAnalyzer(true);QueryParser parser = new QueryParser("content", analyzer); // 默认搜索 content 字段// 解析查询字符串,支持高级语法如 "term1 AND term2", "title:lucene"Query query = parser.parse(queryStr);// 执行搜索,获取前 100 个结果TopDocs topDocs = searcher.search(query, 100);System.out.println("找到 " + topDocs.totalHits.value + " 个结果.");// 遍历并展示结果for (ScoreDoc scoreDoc : topDocs.scoreDocs) {Document doc = searcher.doc(scoreDoc.doc); // 根据 docId 获取完整 DocumentString path = doc.get("path");String contentSnippet = doc.get("content"); // 因为我们存储了原文,可以截取摘要// 理想情况:应使用 Highlighter 组件从 content 中提取包含关键词的高亮片段System.out.println("文件: " + path);System.out.println("相关度得分: " + scoreDoc.score);System.out.println("摘要: " + contentSnippet.substring(0, Math.min(100, contentSnippet.length())) + "...");System.out.println("---");}
}
我的实战扩展与思考
处理多种文件格式: 您的示例是 TXT 文件。现实中要处理 PDF、Word 等。这就需要引入 Apache Tika 这类工具库,先将其文本内容抽取出来,再交给 Lucene 索引。
评分解释(Explanation): 您注释掉的 searcher.explain() 代码非常有用!它能告诉你 “为什么这个文档会被找到?它得了多少分?为什么是这个分数?” 。Lucene 的评分机制(TF-IDF 或 BM25)非常复杂,这个功能对于调试排序效果、理解搜索原理至关重要。
高亮显示(Highlighter): 如上所述,结合存储的 TermVector,可以使用 Highlighter 组件从搜索结果中提取包含关键词的片段,并用 HTML 标签包裹,实现美观的搜索结果展示。
并发控制: Lucene 的索引文件是线程安全的吗?IndexWriter 是昂贵的对象,通常一个应用维护一个实例即可。而 IndexSearcher 则可以在多个线程间共享,并且它能在索引被 IndexWriter 更新后,通过 IndexSearcher.reopen() 方法重新打开一个更新的“快照”,而无需重新创建对象,这实现了“近实时(NRT)搜索”。
总结:Lucene 的价值
通过这次实践,我深刻体会到 Lucene 不仅仅是一个库,它提供了一整套关于信息检索的底层原语。它没有花哨的界面,但却给了开发者最大的灵活性和控制力。
- 优势: 极致性能、算法透明、完全可控、嵌入友好。
- 挑战: 需要开发者自行处理文件解析、索引管理、分布式扩展(如果需要)等问题。
对于构建中小型、嵌入式的搜索应用,Lucene 是无可争议的王者。它教会我们的不仅是 API 调用,更是对倒排索引、分词、相关性评分这些核心搜索概念的深刻理解。即便后续使用 Elasticsearch 这类封装好的搜索引擎,其底层的知识依然能让你更好地使用和调优它。
这份从零开始构建桌面搜索引擎的经历,是一次宝贵的技术深耕,让我对“搜索”这两个字背后浩如烟海的技术细节,充满了敬畏与好奇。
通过本次实践,深刻体会到Lucene优化需要结合具体业务场景进行权衡。在保证搜索精度的前提下,通过内存管理、并发处理、智能合并等手段,实现了性能的跨越式提升。这种优化思路可迁移到其他全文检索场景,为构建高效信息检索系统提供了可复用的技术方案。