AI瘦身狂魔!微软推出原生1-bit大模型,性能不减,内存仅需同行零头!
瘦身之言:
在当今人工智能领域,大型语言模型(LLM)的发展日新月异。然而,随着模型规模的不断扩大,内存占用、能耗以及解码延迟等问题也日益凸显。为了应对这些挑战,微软研究院近日宣布了一个重大突破——发布了首个开源的、原生的1 bit大型语言模型:BitNet b1.58 2B4T。这款模型以其卓越的性能和高效的资源利用,为行业树立了新的标杆。
具体来说,BitNet b1.58 2B4T在多个关键指标上表现出色。首先,在内存占用方面,该模型的非嵌入层内存占用仅为0.4GB,这一数字远低于其他全精度模型。这意味着BitNet b1.58 2B4T能够在有限的硬件资源下运行,极大地降低了部署成本。其次,在能耗方面,BitNet b1.58 2B4T的估计解码能耗仅为0.028焦耳,这一能耗水平远低于其他同类模型,使其在大规模应用中更具经济性和可持续性。最后,在解码延迟方面,该模型在CPU上的平均延迟仅为29毫秒,这一速度远低于其他模型,确保了在实际应用中的高效性和实时性。
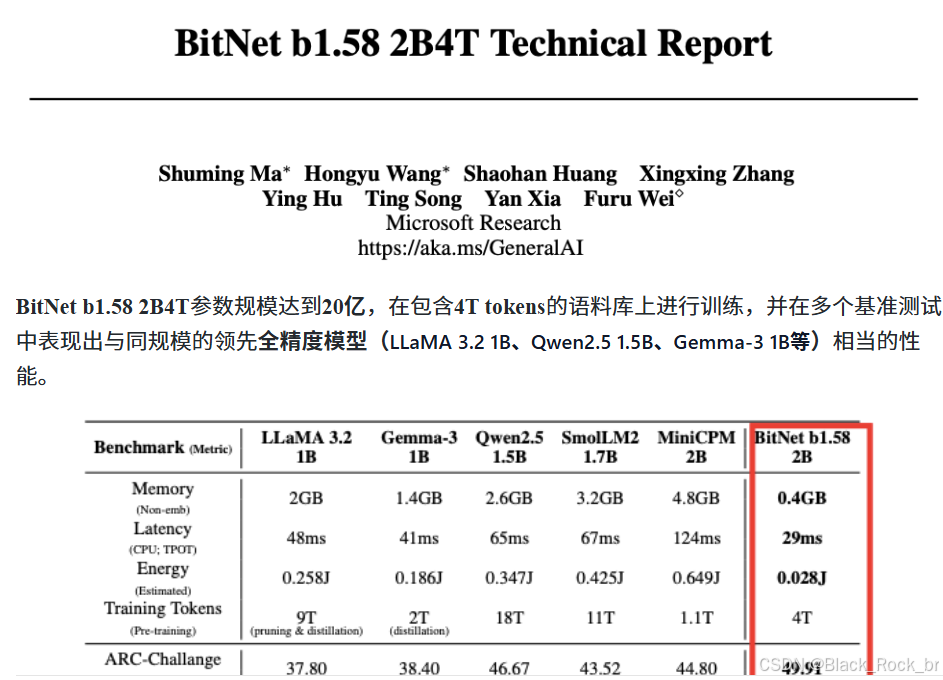
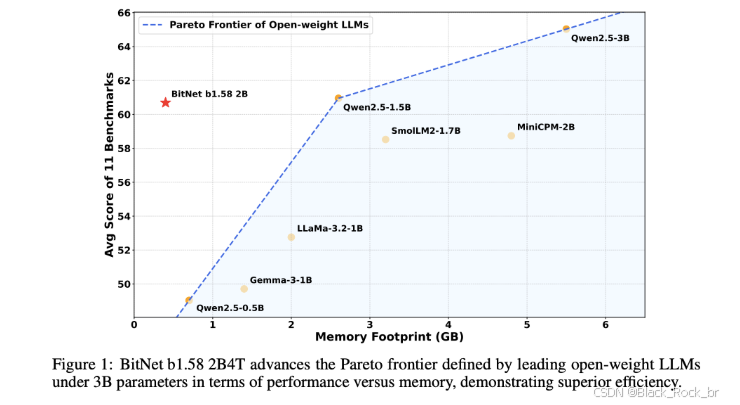
BitNet b1.58 2B4T 模型具备约20亿参数,在4万亿token的海量语料上完成训练,展现出与同级别全精度大模型(如 LLaMA 3.2 1B、Qwen2.5 1.5B、Gemma-3 1B)相媲美的性能,验证了极低比特模型在大规模训练下的潜力。
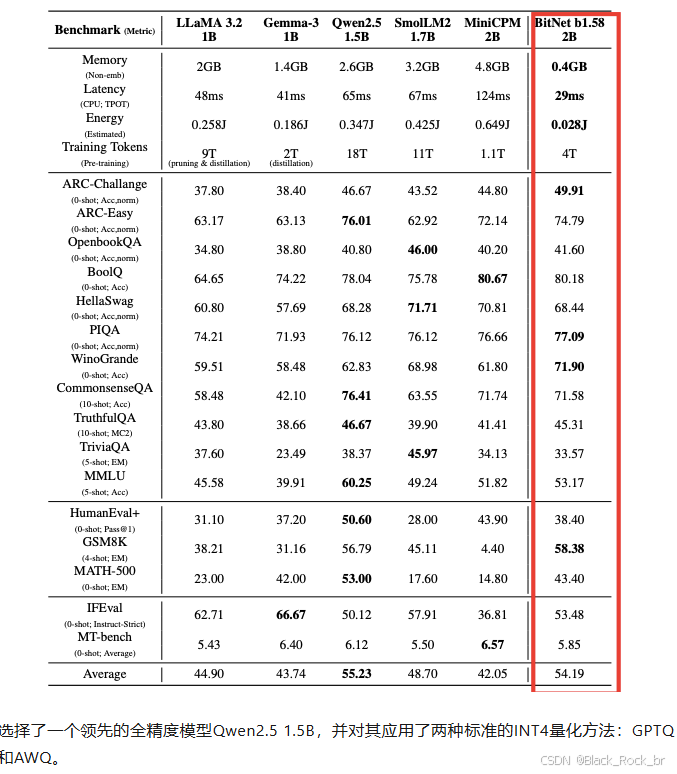
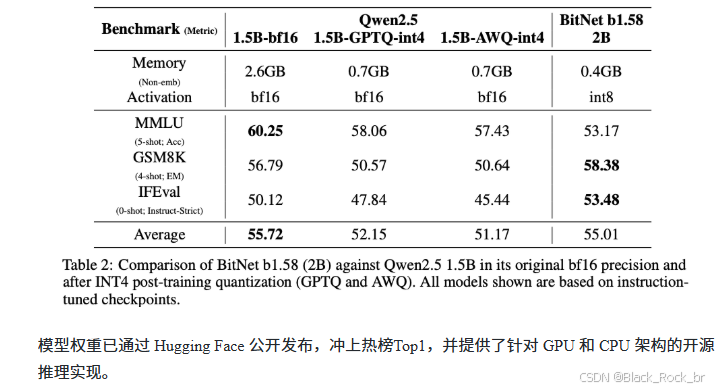
为了进行对比分析,我们选取了性能卓越的全精度模型Qwen2.5 1.5B,并对其分别应用了两种广泛认可的INT4量化技术:GPTQ和AWQ。
在内存占用方面,BitNet b1.58 2B4T展现出显著优势。其非嵌入层的内存占用仅为0.4GB,相较于Qwen2.5 1.5B的2.6GB大幅降低。即使Qwen2.5 1.5B经过INT4量化后,内存占用降至0.7GB,仍远高于BitNet b1.58 2B4T。
在性能表现上,尽管INT4量化有效减少了Qwen2.5 1.5B的内存占用,但BitNet b1.58 2B4T在多数基准测试中依然保持了更优的性能表现。
目前,大多数1bit模型要么是通过全精度模型的后训练量化(PTQ)实现的,但这种方法往往会显著降低模型性能;要么是规模较小的原生1bit模型,难以满足大规模应用的需求。而BitNet b1.58 2B4T模型则另辟蹊径,它完全从头开始训练,其核心创新在于用自定义的BitLinear层取代了传统的全精度线性层。这些BitLinear层具体包括:
模型在前向计算中实现极致量化:权重经absmean归一后映射至1.58-bit三值域 {-1, 0, +1},激活则通过token-wise absmax策略量化为8-bit整型,兼顾动态表达与计算效率。配合SubLN架构设计,有效缓解低比特训练中的梯度波动,提升整体收敛稳定性
除核心的 BitLinear 层外,BitNet b1.58 2B4T 还融合了一系列成熟的 LLM 架构优化技术:在前馈网络(FFN)中采用 ReLU² 激活函数以增强非线性表达能力,使用旋转位置编码(RoPE)支持序列建模,并移除了所有线性层及归一化层中的偏置项,以简化结构并提升训练稳定性。
该模型的训练分为三个阶段,逐步提升模型能力。
- 预训练:旨在构建模型的基础语言理解与世界知识,采用包含公共文本和代码数据的多样化语料库。训练过程中使用两阶段学习率调度与权重衰减策略,以优化收敛性能。
- 监督微调(SFT):基于多样化的指令遵循与对话数据集,提升模型对指令的理解能力及在对话场景中的响应质量。
- 直接偏好优化(DPO):利用人类偏好数据直接优化模型输出,使其在有用性与安全性方面更符合人类期望,省去训练独立奖励模型的复杂流程。
参考链接:
https://arxiv.org/pdf/2504.12285https://hf-mirror.com/microsoft/bitnet-b1.58-2B-4TBitNet b1.58 2B4T Technical Report