学习数据结构(15)插入排序+选择排序(上)
1、直接插入排序
(1)基本思想
把待排序的记录按其关键码值的大小逐个插入到一个有序序列中,直到所有的记录插入完为止,得到待排序记录的有序序列
(2)代码实现
定义end为有序序列的最后一个元素的下标,tmp为arr[end]的后一个元素,也是插入有序序列的元素,end从0遍历到n-2。在end>=0的情况下,若tmp比arr[end]小(假设是升序排序),则把arr[end]的值赋给arr[end+1],end向前遍历寻找比tmp小的数据,找到了就跳出循环,将tmp插入此数据后一位的位置。
//直接插入排序
//输入参数为待排序的数组地址以及待排序的数据总数
void InserSort(int* arr, int n)
{for (int i = 0; i< n - 1; i++){int end = i;int tmp = arr[end + 1];while (end >= 0){if (arr[end] > tmp){arr[end + 1] = arr[end]; end--;}else {break;}}arr[end + 1] = tmp;}
}直接插入排序的时间复杂度为,但优于冒泡排序
2、希尔排序
(1)基本思想
由直接插入排序可知,若待排序的记录较为接近有序的序列,那么直接插入排序的效率较高,近似于,故在直接排序之前,我们希望可以将数据预处理得到大致有序的序列。先选定一个整数(通常是gap = n/3+1,选择n/3是因为n/3比n/2需要排序的次数更少,最后+1是为了避免整除而gap=0),把待排序文件所有记录分成各组,所有的距离相等的记录分在同⼀组内,并对每⼀组内的记录进行排序,然后gap=gap/3+1得到下一个整数,再将数组分成各组,进行插入排序,当gap=1时,就相当于直接插入排序。 希尔排序是在直接插入排序算法的基础上进行改进而来的,综合来说它的效率肯定是要高于直接插入排序算法的。
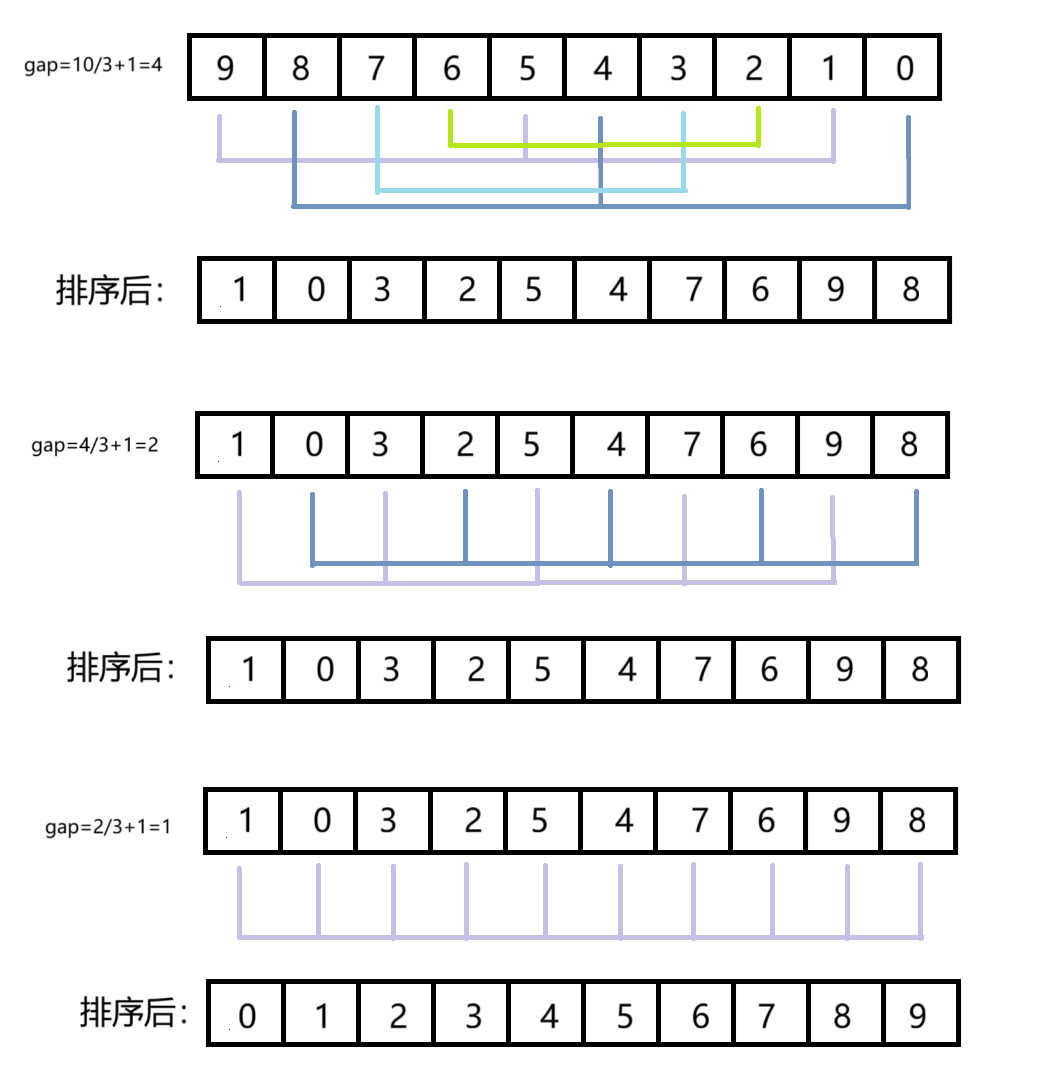
(2)代码实现
在直接插入排序的基础上进行修改
//希尔排序
//输入参数为待排序的数组地址以及待排序的数据总数
void ShellSort(int* arr, int n)
{int i = 0;int gap = n;while (gap > 1){gap = gap / 3 + 1;for (i = 0; i < n - gap; i++){int end = i;int tmp = arr[end + gap];while (end >= 0){if (arr[end] > tmp){arr[end + gap] = arr[end];end -= gap;}else{break;}} arr[end + gap] = tmp;}}
}希尔排序是对直接插入排序的优化,当 gap > 1 时都是预排序,目的是让数组更接近于有序
(3)希尔排序的时间复杂度
外层循环: 外层循环的时间复杂度可以直接给出为: 或者
,即
内层循环:
假设一共有n个数据,合计gap组,则每组为n/gap个;在每组中,插入移动的次数最坏的情况下为 1 + 2 + 3 + .... + (n/gap-1),一共有gap组,因此: 总计最坏情况下移动总数为: gap ∗ [1 + 2 + 3 + .... + ( n/gap-1)], gap取值有(以除3为例):n/3,n/9,n/27,...,2,1,
当gap为n/3时,移动总数为:
当gap为n/9时,移动总数为:
最后gap=1,直接插入排序,内层循环近似为n
因此,希尔排序在最初和最后的排序的次数都为n,即前一阶段排序次数是逐渐上升的状态,当到达某一顶点时,排序次数逐渐下降至n,而该顶点的计算暂时无法给出具体的计算过程
3、直接选择排序
(1)基本思想
每一次从待排序的数据元素中选出最小和最大的两个元素,存放在序列的起始位置和末尾位置,直到全部待排序的数据元素排完。
(2)代码实现
分别将待排序数据的第一个元素和最后一个元素的下标定义为begin和end,当begin<end时,进入循环,先将最小值和最大值下标定义在begin的位置,for循环i从begin后一个元素开始遍历直到end,若有arr[i]<arr[imin],则将i赋给imin,若有arr[i]>arr[imax],则将i赋给imax。最后将arr[imin]的值和arr[begin]的值交换,arr[imax]的值和arr[end]的值交换,begin往前移一位,end往后移一位。有一个需要注意的点:当最大值就是arr[begin]时,此时arr[imin]先和arr[begin]交换,那么imax标记的是最小值,arr[imax]再和arr[end]交换就会出错,解决方法是把imin赋给imax,此时arr[imin]先和arr[begin]交换,imax标记的就是最大值,再将arr[imax]和arr[end]交换
//直接选择排序
//输入参数为待排序的数组地址以及待排序的数据总数
void SelectSort(int* arr, int n)
{int begin = 0, end = n - 1;while (begin < end){int imin = begin, imax = begin;for (int i = begin + 1; i <= end; i++){if (arr[i] < arr[imin]){imin = i;}if (arr[i] > arr[imax]){imax = i;}}if (begin == imax){imax = imin;}swap(&arr[imin], &arr[begin]);swap(&arr[imax], &arr[end]);begin++;end--;}
}直接选择排序的时间复杂度为