Qwen2-Plus与DeepSeek-V3深度测评:从API成本到场景适配的全面解析
在大模型驱动创新的时代,企业技术决策者面临着一个前所未有的局面:模型选择已不再仅仅依赖于品牌知名度或学术排名,而是直接关系到产品的用户体验、成本结构和市场竞争力。随着Qwen、DeepSeek等一系列优秀模型的崛起,AI大模型领域正式进入“百花齐放”的时代,选型也成为CTO、产品负责人和AI战略规划者必须严肃对待的核心决策。
一、从“追名牌”到“看匹配”:建立理性的三维选型框架
很多团队过去习惯于盲目追求“最强模型”或“排名第一”的解决方案,但在落地实践中我们发现,脱离具体场景的能力比较和成本考量往往是徒劳的。一个更具操作性的选型方法论应基于以下三个维度:
能力维度:不仅看综合评分,更要看与自身业务相关的能力长板;
成本维度:单价背后隐藏着规模化应用的巨大成本差异,必须精确测算;
场景维度:模型是否有针对特定场景优化,例如多语言、代码生成或长文本处理。
盲目追求参数规模或榜单排名,是一种过于粗放的决策方式,往往导致“杀鸡用牛刀”或“小马拉大车”的错配现象。
二、案例剖析:Qwen2-Plus-Latest vs. DeepSeek-V3
我们以当前备受关注的两个模型——Qwen2-Plus-Latest和DeepSeek-V3为例,基于AIbase模型选型对比平台的客观数据,用三维框架进行深度分析。
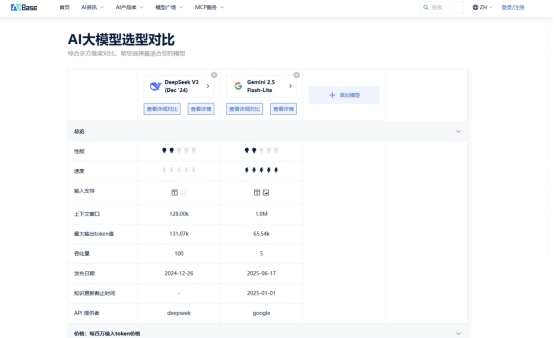
1. 能力维度:综合评分与长短版分析
根据AIbase平台提供的多维度评测数据:
Qwen2-Plus-Latest在通用推理和多语言能力上表现优异,特别是在中文理解和生成任务上保持了强劲水准,适合国际化业务和复杂指令跟随场景。
DeepSeek-V3在代码生成、数学推理和长上下文处理方面优势明显,128K的上下文窗口使其在代码库分析、长文档摘要等任务中表现突出。
两者综合能力接近,但能力倾向显著不同,选型应基于业务对特定能力的要求。
2. 成本维度:定价策略与规模化成本测算
价格是企业规模化应用的核心考量因素。通过AIbase平台获取的最新定价数据显示:
Qwen2-Plus-Latest:输入 $0.10 / 1M tokens,输出 $0.40 / 1M tokens
DeepSeek-V3:输入 $0.12 / 1M tokens,输出 $0.36 / 1M tokens
假设某企业日均处理1亿token(输入输出合计),月均成本差异显著:
Qwen2-Plus月成本约:$15,000
DeepSeek-V3月成本约:$14,400
尽管单次调用成本差异微小,但在规模化应用中,成本差距会被显著放大。企业需结合自身业务流量,进行精确的成本模拟。
3. 场景维度:特性与适用场景分析
Qwen2-Plus-Latest更适合:
多语言产品(特别是中日英韩语种)
对话式应用和复杂指令处理
对语言细腻度要求较高的创作类场景
DeepSeek-V3更适合:
开发者工具和编程辅助应用
长文档处理、知识库问答和学术研究
对长上下文连贯性要求高的分析任务
三、结论与建议:让模型选型从“艺术”变为“科学”
面对众多优秀模型,企业决策者应避免主观偏好或盲目跟风,而是建立数据驱动的选型流程:
明确核心需求:识别业务对模型能力的真实需求,避免过度追求无关指标;
开展并行测试:使用真实业务数据,对候选模型进行AB测试;
精确成本测算:基于业务流量预测,计算总体拥有成本(TCO);
利用专业工具:采用AIbase模型对比平台https://model.aibase.com/zh/compare等工具,获取客观的性能数据和定价信息。
我们建议技术决策者亲自访问AIbase,使用其提供的并行测试和成本计算功能,基于自身业务场景进行验证。只有将模型选型建立在客观数据和科学方法的基础上,才能在AI应用中获得持续竞争优势。
本文数据均来源于AIbase模型选型对比平台,实际性能可能因使用场景而异。建议读者以平台最新数据和自身测试结果为准,做出最终决策。