【KDD2025】时间序列|Merlin:不固定缺失率下时间序列预测新SOTA!

论文地址:https://arxiv.org/abs/2506.12459
代码地址:https://github.com/ChengqingYu/Merlin
为了更好地理解时间序列模型的理论与实现,推荐参考UP “ThePPP时间序列” 的教学视频。该系列内容系统介绍了时间序列相关知识,并提供配套的论文资料与代码示例,有助于理论与实践相结合。
https://space.bilibili.com/613453963
摘要
多变量时间序列预测 (MTSF) 涉及预测多个相互关联的时间序列的未来值。近年来,基于深度学习的 MTSF 模型因其在 MTS 数据中挖掘语义(全局和局部信息)的强大能力而受到广泛关注。然而,这些模型普遍容易受到数据采集器故障导致的缺失值的影响。这些缺失值不仅会破坏 MTS 的语义,而且它们的分布也会随时间变化。尽管如此,现有模型缺乏对这些问题的鲁棒性,导致预测性能欠佳。
为此,本研究提出了多视图表征学习 (Merlin),它可以帮助现有模型在 MTS 中实现不同缺失率的不完整观测值与完整观测值之间的语义对齐。具体来说,Merlin 由两个关键模块组成:离线知识蒸馏和多视图对比学习。前者利用教师模型指导学生模型从不完整观测值中挖掘语义,类似于从完整观测值中获得的语义。后者通过从不同缺失率的不完整观测值构建的正/负数据对中学习,提高了学生模型的鲁棒性,确保了不同缺失率之间的语义对齐。因此,Merlin 能够有效地增强现有模型针对未固定缺失率的鲁棒性,同时保持预测精度。在四个真实世界数据集上的实验结果证明了 Merlin 的优越性。
引言
本研究致力于提高现有预测模型在具有不固定缺失率的多元时间序列预测任务中的鲁棒性。多元时间序列预测 (MTSF) 涉及预测多个相互关联的时间序列的未来值。深度学习模型在 MTSF 中展现出强大的能力,然而,由于数据采集器故障等原因导致的缺失值会严重影响这些模型的性能。这些缺失值不仅会破坏 MTS 的语义信息(全局和局部信息),而且它们的分布也会随时间变化,导致不同的时间段有不固定的缺失率。现有模型缺乏对这些问题的鲁棒性,导致预测性能欠佳。本研究深入探讨了缺失值如何导致这些模型性能下降的问题,并发现大量缺失值会严重破坏 MTS 的语义,而现有模型在这种情况下表现出较差的鲁棒性。缺失值破坏了全局信息(如周期性),并引入了异常的局部信息,如从正常值到零的突变和异常的直线。现有模型容易捕捉到这些异常而不是原始语义,导致性能下降。此外,缺失值的分布可能随时间而变化,导致不同时间段的缺失率不固定。如果现有模型不对每个缺失率分别训练模型,它们的性能就会显著下降,表现出对不固定缺失率的鲁棒性较差。
为了提高预测模型的性能,一个直观的解决方案是使用插补方法来恢复缺失值,并提出两阶段或端到端建模方法。然而,这些方法面临两个挑战:1) 现有插补方法通常需要重建缺失值和正常值,这会破坏局部信息并导致误差累积;2) 当处理不固定缺失率时,现有插补方法需要针对不同的缺失率训练单独的模型,以确保数据恢复的准确性。当插补模型和预测模型没有针对每个缺失率训练单独的模型时,它们的预测性能会显著下降,在处理不固定缺失率时表现出较差的鲁棒性。
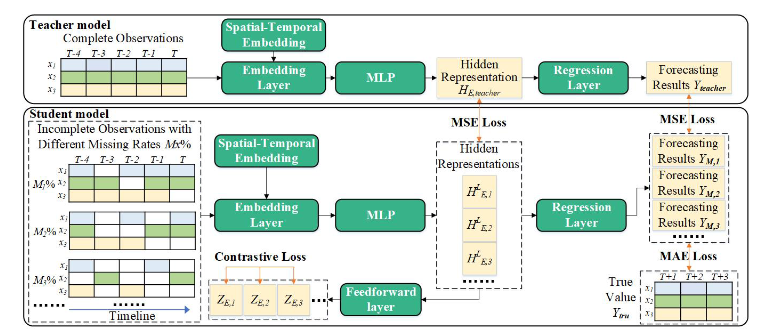
为了解决上述问题,并在具有不固定缺失率的情况下实现鲁棒的 MTSF,本研究认为关键在于增强预测模型的语义对齐能力,这包括两个目标:1) 完整观测值具有更准确的全局和局部信息,我们需要帮助预测模型从不完整观测值中挖掘类似的语义;2) 不同的缺失率对 MTS 原始语义的影响不同,我们需要帮助预测模型尽可能对齐不同缺失率之间的语义。为此,本研究提出了基于离线知识蒸馏 (KD) 和多视图对比学习 (CL) 的多视图表示学习方法 (Merlin)。对于目标 1,基于离线知识蒸馏的思想,本研究首先使用完整观测值训练教师模型,然后使用相同的架构获得学生模型,该模型在不完整观测值上进行训练。在训练学生模型时,本研究将完整观测值输入教师模型,并将生成的表示和预测结果作为知识来约束学生模型。这确保了学生模型从不完整观测值生成的表示和预测结果尽可能类似于教师模型生成的表示和预测结果(它们之间的损失尽可能小)。通过这种方式,学生模型可以从不完整观测值中挖掘出与从完整观测值中获得的语义相似的语义。对于目标 2,基于多视图对比学习的思想,本研究首先将同一时间点但缺失率不同的不完整观测值视为正数据对,将不同时间点的观测值视为负数据对。然后,本研究提出了一个对比损失作为学生模型的约束,以增强负数据对的差异性和正数据对的相似性。通过这种方法,学生模型可以在不同缺失率的不完整观测值之间对齐语义,而无需针对不同的缺失率训练多个单独的模型。Merlin 可以显著增强现有模型对不固定缺失率的鲁棒性,并提高其预测性能。
论文创新点
Merlin:一个用于不定缺失率多元时间序列预测的多视角表示学习框架
✨ 本研究提出了一个名为Merlin的多视角表示学习框架,旨在增强现有预测模型在处理不定缺失率的多元时间序列预测任务中的鲁棒性。其创新点主要体现在以下几个方面: ✨
-
🧩 针对不定缺失率的鲁棒性问题: 🧩
- 本研究首先指出现有模型在处理不定缺失率的多元时间序列预测任务中存在鲁棒性问题。
- 缺失值不仅会扰乱多元时间序列的语义(全局和局部信息),而且缺失率通常会随时间变化,现有模型需要针对不同的缺失率训练单独的模型,这在实际应用中非常不方便。
- 本研究旨在解决这两个关键挑战,提高模型的实用性和鲁棒性。
-
🗝️ 语义对齐的核心思想: 🗝️
- 本研究提出实现鲁棒多元时间序列预测的关键在于增强预测模型的语义对齐能力。
- 这包括两个目标:
- (1) 使从不完整观测数据中提取的语义与从完整观测数据中提取的语义尽可能相似;
- (2) 使不同缺失率下的不完整观测数据之间的语义尽可能对齐。
-
👨🏫 基于离线知识蒸馏的语义对齐: 👨🏫
- 为了实现第一个语义对齐目标,本研究采用了离线知识蒸馏技术。
- 首先使用完整观测数据训练一个教师模型,然后使用相同的架构训练一个学生模型,该学生模型使用不完整观测数据进行训练。
- 在训练学生模型的过程中,将完整观测数据输入教师模型,并将生成的表示和预测结果作为知识迁移到学生模型,以约束学生模型的学习过程。
- 这样可以确保学生模型从不完整观测数据中提取的表示和预测结果尽可能接近教师模型的结果,从而实现不完整观测数据和完整观测数据之间的语义对齐。
-
🌐 基于多视角对比学习的语义对齐: 🌐
- 为了实现第二个语义对齐目标,本研究引入了多视角对比学习。
- 将同一时间点但缺失率不同的不完整观测数据视为正数据对,将不同时间点的观测数据视为负数据对。
- 通过对比损失约束学生模型,增强负数据对之间的差异性,提高正数据对之间的相似性。
- 这种方法可以使学生模型在不同缺失率的不完整观测数据之间进行语义对齐,而无需针对每个缺失率训练单独的模型。
-
🚀 高效的单阶段训练: 🚀
- 与现有方法需要针对不同缺失率训练多个模型不同,本研究提出的Merlin框架只需要训练一次即可适应不定缺失率。
- 这大大提高了模型的训练效率和实用性。
- 在测试阶段,学生模型可以直接使用不同缺失率的不完整观测数据进行预测,无需教师模型的参与,进一步提高了预测效率。
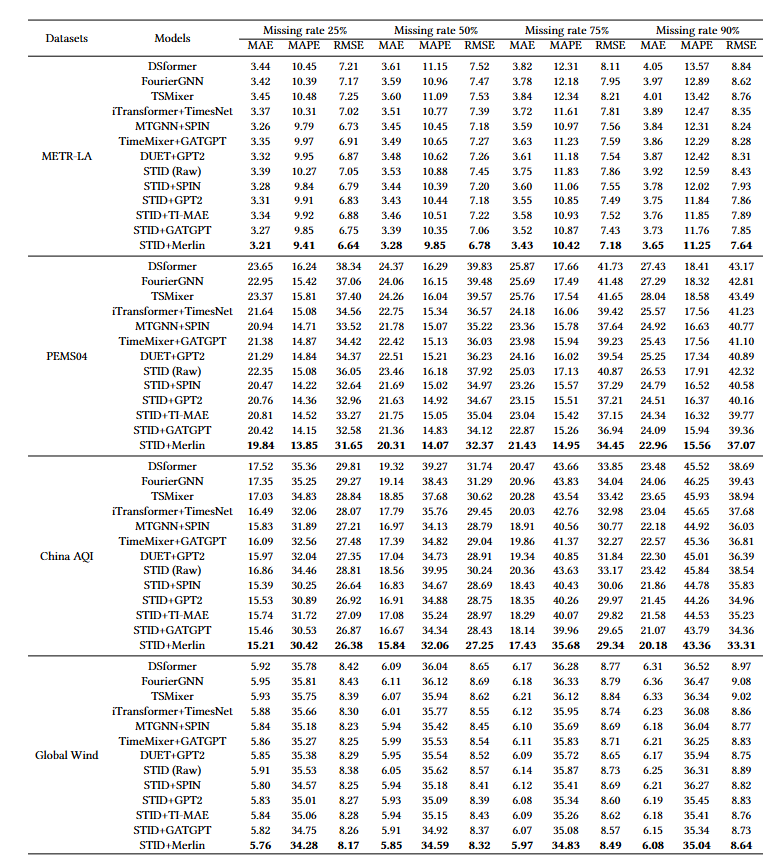
论文实验