jmeter学习
jmeter学习
文章目录
- jmeter学习
- 0. 简介
- 1. 安装配置
- 2. 线程组
- 3. 结果提取
- 1. json提取器
- 2. 跨线程引用
- 3. 正则表达式提取
- 4. 参数化
- 1. CSV Data Set Config方式
- 5. 断言
- 1. json断言
- 2. 响应断言
- 3. 大小断言和持续时间断言
- 6. 定时器
- 参考
0. 简介
Apache JMeter是一款由Apache组织开发的基于Java的开源性能测试工具,主要用于对软件系统进行压力测试、负载测试和功能测试,支持多种协议和技术(如HTTP、FTP、JDBC等),广泛应用于Web应用、数据库及服务器性能评估。
jmeter优点:
- 开源,免费
- 跨平台
- 支持多协议
- 小巧
- 功能强大
jmeter缺点:
- 不支持ip欺骗
- 无法验证js程序,无法验证页面UI,需要与selenium搭配。
性能测试类型:
性能测试,指标测试。
基准测试:在1个用户的情况下进行压测(相当于功能测试)。
负载测试:10,100,1000,10000,最优并发数。最大可接妥的并发数。
压力测试:10万,100万,直到系统奔溃,最大并发数。
稳定性测试:持续压测8-24小时。最优井发数。
1. 安装配置
确保java环境配置好。
https://jmeter.apache.org/download_jmeter.cgi

新建环境变量JMETER_HOME
C:\Users\21609\Downloads\apache-jmeter-5.6\apache-jmeter-5.6.3
打开"C:\Users\21609\Downloads\apache-jmeter-5.6\apache-jmeter-5.6.3\bin\jmeter.bat"
选一下语言

2. 线程组
右键添加一个线程组。
setUp线程组:最优先执行的线程组。
tearDown线程组:最后执行的线程组。


线程数:虚拟用户数。一个虚拟用户占用一个进程或线程。
Ramp-Up准备时长:设置的虚拟用户数需要多长时间全部启动。如果线程数为20 ,准备时长为10 ,那么需要10秒钟启动20个线程。也就是每秒钟启动2个线程。
循环次数:每个线程发送请求的次数。如果线程数为20 ,循环次数为100 ,那么每个线程发送100次请求。总请求数为20*100=2000 。如果勾选了“永远”,那么所有线程会一直发送请求,一到选择停止运行脚本。
持续时间:每个采样器持续执行时间。
启动延迟:点击启动按钮后,延迟多少秒才开始执行采样器。
登录万维易源网站,使用天气预报接口
应用:just_test_app
应用id:18xxxxx
appKey: 70EBxxxxx
jmeter添加http请求

尝试根据地名查询天气
接口地址: https://route.showapi.com/9-2?appKey={your_appKey}
返回格式: json

根据接口文档填写参数,也可以把appKey写在/9-2?后面。

如果需要编写消息头,可以添加消息头管理器
如果需要编写cookie,可以添加cookie管理器
如果需要编写几个采样器通用的默认值,可以添加http请求默认值。

添加监听器,查看结果树,用来显示返回信息。

运行一下查看结果。

3. 结果提取
1. json提取器
Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器。
Main sample only:仅作用于父节点的取样器。(选默认的 main sample only 就行了)
Sub-samples only:仅作用于子节点的取样器。
JMeter Variable Name to use:作用于JMeter变量(输入框内可输入JMeter的变量名称),从指定变量中提取需要的值。
Match No.(0 for Random):表示取值是第几个匹配结果,因为有可能XPath表达式会匹配到多个值。0表示随机,-1表示全部,1代表第一个,2代表第二个,以此类推。(非必填项)
Compute concatenation var (suffix _ALL): 如果 JSON 表达式提取了多组数据,那么自动拼接所有数据,以都逗号做分隔符,然后保存到变量名_ALL中。
| Json Path | |
|---|---|
$ | 表示根元素 |
@ | 表示当前节点 |
. | 表示子节点 |
.. | 选择所有符合条件的节点 |
* | 所有节点 |
[] | 迭代器标识,如数组下标 |
[,] | 支持迭代器中的多选 |
[start:end:step] | 数组切片 |
?() | 支持过滤 |
() | 支持表达式计算 |
目标:使用地名-查未来15天预报接口,提取第一个day_wind_direction字段并赋值给变量day_wd,在第二个http请求里使用该变量。
接口地址: https://route.showapi.com/9-9?appKey={your_appKey}
返回格式: json

新建线程组:地名-查未来15天预报
添加http请求和查看结果树

运行一下可以看到返回结果

线程组添加调试取样器(Debug Sample)

http请求右键添加->后置处理器->json提取器
再次添加http请求,调整一下顺序

构造
$.showapi_res_body.dayList[*].day_wind_direction
提取匹配到的第一个结果,给变量day_wd(需要是英文)。
在第二个http请求里使用该变量

查看结果树的第二个请求。

查看结果树的调试取样器。

如果匹配所有结果,则变量名后面会添加后缀。

2. 跨线程引用
目标:A线程组查询白天风向转化为全局变量,然后b线程组调用该变量。
调整线程组顺序,添加后置处理器中的BeanShell PostProcessor

${__setProperty(global_day_wd,${day_wd},)};

信息头管理器调用全局变量
day_wd=${__property(global_day_wd)}

成功!

3. 正则表达式提取
正则表达式
():要提取的内容
.:匹配任意单个字符串
*: 匹配(*之前的符号)0次或多次
+:匹配(+之前的符号)1次或多次
?:不要太贪婪,在找到第一个匹配项后停止。
.*:匹配连续0个/多个字符
.+:匹配连续1个/多个字符
\ :转义,\.表示匹配字符.本身
模板
$1$:提取第1个分组匹配的内容,如:0-3级
$2$:提取第2个分组匹配的内容
$0$:提取整个正则表达式匹配的完整内容,如:"night_wind_power":"0-3级"
**$1$-$2$**:结果会将两个分组内容用-连接。
目标:提取night_wind_power并输出。

地名-查未来15天预报的http请求添加后置处理器中的正则表达式提取器。

调整提取器顺序并填写参数
"night_wind_power":\s*"(.*?)"


4. 参数化
1. CSV Data Set Config方式
新建1.csv

注意另存为csv格式。

选择测试计划(Test Plan),右键->添加–>元件–>CSV data Sat config

调整csv数据文件设置位置,填写参数

http请求添加参数

线程组地名-查未来15天预报设置4个线程。


5. 断言
断言:让程序代替人工判断响应结果是否符合预期。
1. json断言
JSON断言只能针对响应结果是applicaton/json格式的请求进行断言。

http请求添加json断言,勾选Additionally assert value
我们正则匹配一下area字段的值,发现成功

如果改成错误的值,比如四川,则会失败

2. 响应断言
响应断言:断言状态码和响应体
http请求添加响应断言

判断响应代码是否同时等于200,201,404,显然不可能。


勾上或者后就行了

3. 大小断言和持续时间断言
大小断言:判断响应内容的字节长度
断言持续时间:判断响应时间是否在指定时间内
在http请求上添加大小断言,判断相应字段是否>10000,显然不可能。



添加断言持续时间,判断操作是否在1ms以内,一般不会这么短。


6. 定时器
Random Delay Maximum:最大随机延迟时间;
Constant Delay Offset: 固定延迟时间。
QPS:Queries Per Second意思是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
TPS:每秒事务数。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
吞吐量:在一定时间内系统能够处理的数据量或请求量,通常以每秒处理的数据量或请求量来衡量。
固定定时器:设置每个请求之间的固定延迟时间(执行间隔)(单位毫秒)。
统一随机定时器:设置延时时间上下限范围和基础延时时间。每个线程的延迟时间是符合标准正态分布的随机时间停顿。
同步定时器:Synchronizing Timer,
准确的吞吐量定时器:Precise Throughput Timer。
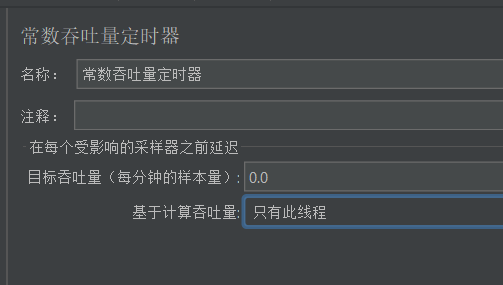
常数吞吐量定时器:Constant Throughput Timer。它通过动态调整请求的等待时间,确保被测系统的吞吐量尽可能接近用户设定的目标值(如请求数/分钟或请求数/小时)。
Precise Throughput Timer的目标吞吐量(Target throughput):每个吞吐期的样本。比如周期5s,目标吞吐量1000,表示要求每5秒发送1000个请求。
吞吐量周期(Throughput period):在多少秒内执行测试的TPS,通常设置为1秒。例如周期=10s,表示统计每10秒的事务总数,再换算为平均每秒事务数(总事务数/10)。
测试持续时间(Test duration):测试时长,与前面线程组的数值保持一致。
批处理中的线程数(Number of threads in the batch):准备好多少个线程数一起发起请求,通常取与TPS保持一致的数值(如果TPS是小数,则向上取整)。
批处理中的线程之间的延迟(Delay between threads in the batch):第一批与第二批处理之间的延迟时间,默认即可。
随机种子(Random seed):非0随机种子可以重复,0不可重复,默认即可。

Constant Throughput Timer的目标吞吐量:每分钟的样本量。
目标:同步定时器模拟高并发,模拟100个用户同时访问服务器资源,要求平均响应时间在3000ms内,且错误率为0。
不用的线程组右键->禁用。
新建线程组,http请求,同步定时器,聚合报告。




参考
jmeter教程 Mr. G K
10分钟讲完Jmeter接口测试 乔治的杰克船长