时间序列分析
生成所需数据
时间序列分析是量化交易的基础,时间序列分析为量化交易提供了核心数据处理和建模工具,金融市场中的价格、成交量、波动率本质上都说金融时间序列,具有时序依赖性,周期性,和随机性等特点,时间序列分析也可以理解为投资策略从概率统计的维度以历史数据作为基础来进行检验
首先,我们先通过代码随机生成我们所需的数据
import pandas as pd
import numpy as np
from datetime import datetime, timedelta# 生成日期范围(5年工作日数据)
date_range = pd.date_range(start='2020-01-01', end='2025-06-13', freq='B')# 固定随机种子,确保结果可复现
np.random.seed(42)# 生成标普500模拟数据(带趋势)
spx_start = 3000
spx_returns = np.random.normal(0.0002, 0.01, len(date_range))
spx_values = spx_start * (1 + spx_returns).cumprod()# 生成VIX模拟数据(与标普500负相关)
vix_start = 20
vix_returns = -0.3 * spx_returns + np.random.normal(0, 0.015, len(date_range))
vix_values = vix_start * (1 + vix_returns).cumprod()
vix_values = np.maximum(vix_values, 10) # 确保VIX不低于10# 生成AAPL.0(苹果股票)模拟数据(与标普500正相关,波动更大)
aapl_start = 100
aapl_returns = 0.8 * spx_returns + np.random.normal(0, 0.02, len(date_range)) # 更高波动
aapl_values = aapl_start * (1 + aapl_returns).cumprod()# 创建包含三列的DataFrame
data = pd.DataFrame({'.SPX': spx_values,'.VIX': vix_values,'AAPL.0': aapl_values
}, index=date_range)# 保存为CSV文件
data.to_csv('data.csv')print("包含AAPL.0的完整数据已保存为data.csv!")读取基本数据
在读取数据后,我们需要从CLI的交互界面当中获取数据可以使用info()方法来获取
info() 是 pandas 中最简单但最实用的方法之一,它为数据分析师提供了数据的 “第一印象”,帮助快速发现数据质量问题(如缺失值、错误数据类型)和优化内存使用。在处理任何新数据集时,建议首先使用 info() 进行基础探查,为后续的分析和建模奠定基础。
import pandas as pd# 读取CSV文件
df = pd.read_csv('data.csv')print('数据基本信息:')
df.info()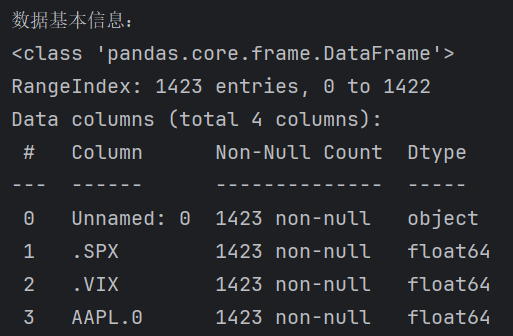
可视化处理
在上述数据处理当中,我们虽然能通过info方法和点击csv文件来直接查看数据,但数值堆叠的数据往往很难让人一看看出其中规律,而通过数据可视化,我们可以将数据、信息或知识转化为视觉形式,其核心作用是通过图形化手段增强人类对信息的理解、分析和传播效率。在数据分析、商业决策、科学研究等领域,可视化的价值体现在能够化抽象为具象,更好地帮助从业人员作出分析和决策。常见的图表类型有有很多,例如折线图,散点图,气泡图等,这里不过多展开(数据可视化部分图表)
数据读取与预处理
import pandas as pd
import matplotlib.pyplot as plt# 读取 CSV 文件
df = pd.read_csv('data.csv')# 将`Unnamed: 0`列转换为日期时间格式并设置为索引
df.set_index(pd.to_datetime(df['Unnamed: 0']), inplace=True)# 删除原来的`Unnamed: 0`列
df.drop('Unnamed: 0', axis=1, inplace=True)Unnamed: 0列处理:当 CSV 文件保存时没有指定索引列,pandas 会自动添加一个无名称的索引列(即Unnamed: 0)。这段代码将该列转换为日期时间格式并设置为 DataFrame 的索引,然后删除原列。- 索引意义:将日期设置为索引后,后续绘图时 x 轴会自动显示为时间轴,便于观察数据的时间序列特征。
图形设置
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300# 设置字体为 SimHei
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False- 图片清晰度和中文字体设置
创建子图并绘制散点图
# 创建一个包含 3 个子图的画布
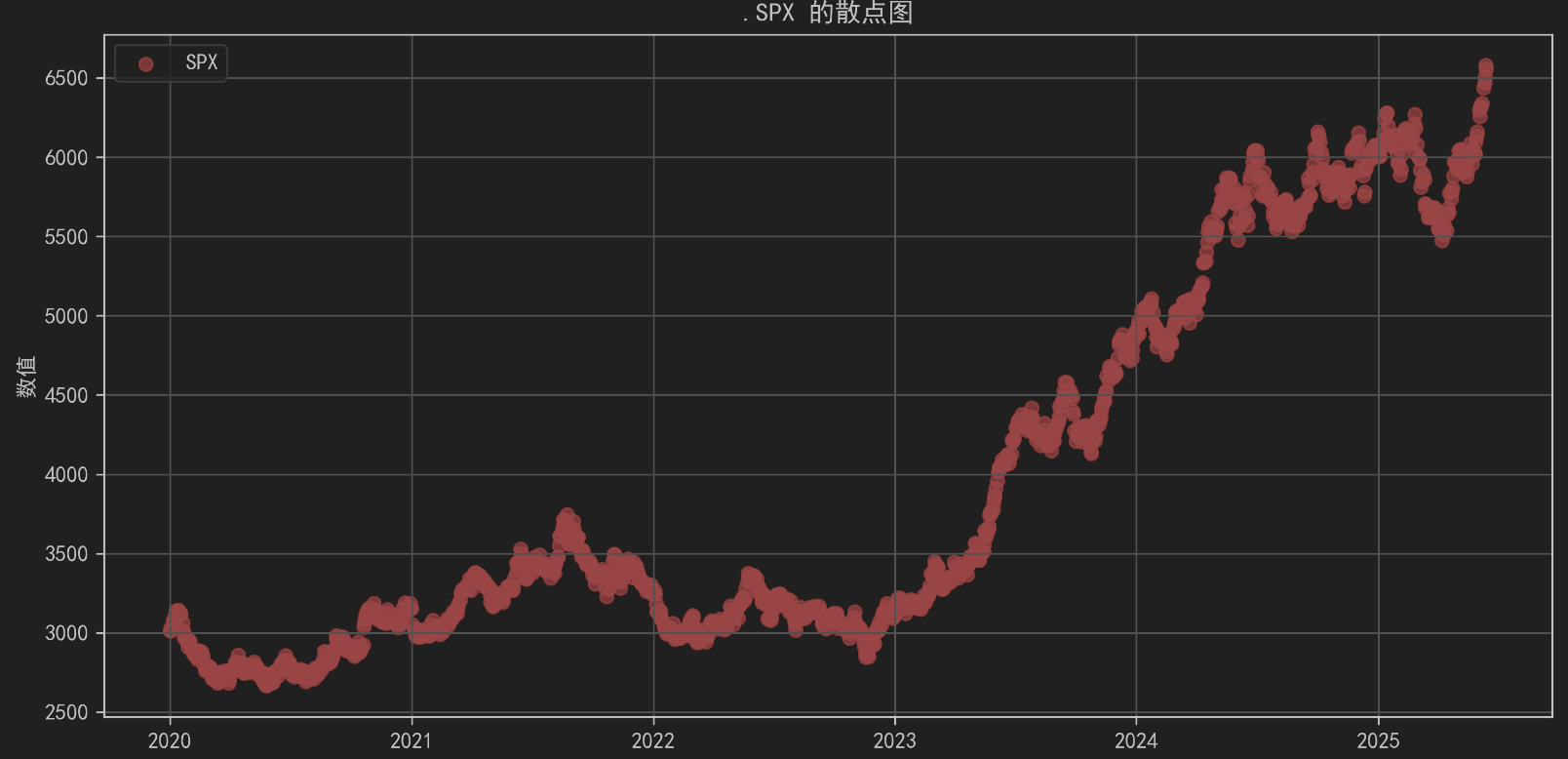
fig, axes = plt.subplots(3, 1, figsize=(10, 15))# 绘制.SPX 的散点图
axes[0].scatter(df.index, df['.SPX'], label='SPX', color='red', alpha=0.7)
axes[0].set_title('.SPX 的散点图')
axes[0].set_ylabel('数值')
axes[0].legend()
axes[0].grid(True)# 绘制.VIX 的散点图
axes[1].scatter(df.index, df['.VIX'], label='VIX', color='yellow', alpha=0.7)
axes[1].set_title('.VIX 的散点图')
axes[1].set_ylabel('数值')
axes[1].legend()
axes[1].grid(True)# 绘制 AAPL.0 的散点图
axes[2].scatter(df.index, df['AAPL.0'], label='AAPL.0', color='blue', alpha=0.7)
axes[2].set_title('AAPL.0 的散点图')
axes[2].set_xlabel('时间')
axes[2].set_ylabel('数值')
axes[2].legend()
axes[2].grid(True)- 子图布局:使用
plt.subplots(3, 1)创建一个 3 行 1 列的子图布局,每个子图对应一个金融指标。 - 散点图参数:
- x 值:使用 DataFrame 的索引(即日期时间)作为 x 轴。
- y 值:分别使用
.SPX、.VIX和AAPL.0列的数据作为 y 轴。 - 颜色与透明度:通过
color参数设置不同的颜色,alpha=0.7使散点具有一定的透明度,便于观察数据的密度分布。
- 图表装饰:为每个子图添加标题、坐标轴标签、图例和网格线,增强图表的可读性。
图形显示
# 自动调整子图布局
plt.tight_layout()# 显示图形
plt.show()- 布局调整:
plt.tight_layout()自动调整子图之间的间距,避免标题、标签等元素重叠。 - 图形显示:
plt.show()显示绘制好的图形。
常见指标分析
在金融数据分析当中有很多指标,这里我们可以通过describe()来查看指标并且以此为依据来了解该数据的大致情况
describe() 是 pandas DataFrame 和 Series 的内置方法,用于生成数据的基本描述性统计量,包括:计数(count)、均值(mean)、标准差(std)、四分位数(25%、50%、75%)、最小值(min)、最大值(max)
aggregate()(或 agg())允许用户自定义需要计算的统计指标,可以:
对不同列应用不同函数
使用内置函数(如 sum、median)或自定义函数
同时计算多个指标
# 使用 describe 函数获取各项指标汇总
describe_result = df[['.SPX', '.VIX', 'AAPL.0']].describe()# 使用 aggregate 函数自定义统计指标
aggregate_result = df[['.SPX', '.VIX', 'AAPL.0']].aggregate(['sum', 'median', 'skew', 'kurt'])print('describe函数的结果:')
print(describe_result)
print('aggregate函数的结果:')
print(aggregate_result)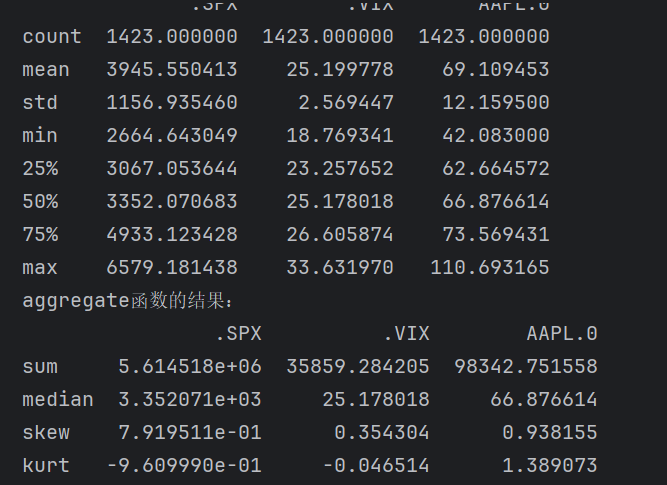
偏度(Skewness):衡量分布的对称性
偏度用于描述数据分布偏离对称形态的程度,直观表现为分布 “尾巴” 的偏向:
对称分布(如正态分布):偏度 = 0,左右两侧对称。
正偏(右偏):偏度 > 0,右侧尾巴更长,均值 > 中位数。
负偏(左偏):偏度 < 0,左侧尾巴更长,均值 < 中位数。
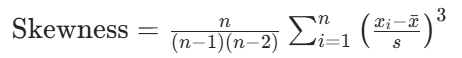
峰度(Kurtosis):衡量分布的 “尖陡” 程度
峰度用于描述数据分布在均值附近的集中程度和尾部厚度,与正态分布对比:
正态分布:峰度 = 3(皮尔逊定义,或 0,若使用 “超额峰度”)。
尖峰分布(Leptokurtic):峰度 > 3,数据更集中于均值附近,尾部更厚(极端值更多)。
平峰分布(Platykurtic):峰度 < 3,数据更分散,尾部更薄(极端值更少)。
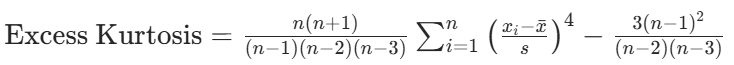
对股价可进行的基本数据处理
指标增长率计算
# 计算每个指标的增长率
growth_rates = df[['.SPX', '.VIX', 'AAPL.0']].pct_change()print('各指标的增长率:')
growth_rates
数据重采样
# 按每周(1W)对数据进行重采样
resampled_df = df.resample('1m').mean()结果为每月的均值
窗口序列获取
# 删除包含缺失值的行
data2 = df.dropna()
# 设置窗口大小
windows = 100
# 创建 AAPL.0 列的窗口序列
window_sequence = data2['AAPL.0'].rolling(window=windows).min()
print('AAPL.0 列的窗口序列:')
print(window_sequence)散点矩阵生成
# 生成散点矩阵图
pd.plotting.scatter_matrix(data2,alpha=0.2,diagonal='hist',hist_kwds={'bins': 50},figsize=(10, 6))plt.show()关键参数解释:
alpha=0.2:
散点的透明度(0-1),值越小越透明。当数据点密集时,低透明度可减少重叠,更清晰地显示数据分布。
diagonal='hist':
对角线上的子图类型为直方图(Histogram),用于展示单个变量的分布情况。
.SPX 的直方图显示标普 500 指数的数值分布。
.VIX 的直方图显示恐慌指数的数值分布。
hist_kwds={'bins': 50}:
直方图的参数设置,将数据分为 50 个区间(bins),控制直方图的粒度。
figsize=(10, 6):
图形的整体尺寸(宽 × 高),单位为英寸。
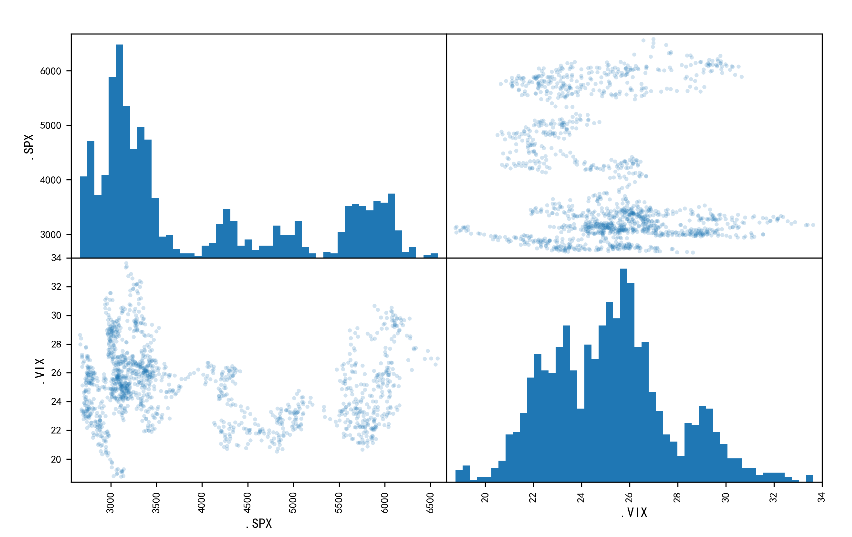
- 右上:
.SPX(y 轴) vs.VIX(x 轴)的散点图。 - 左下:
.VIX(y 轴) vs.SPX(x 轴)的散点图,与左上对称。
一元线性回归方程拟合参数生成
# 构建一元线性回归方程,拟合数据
coefficients = np.polyfit(rets['.SPX'], rets['.VIX'], deg=1)# 提取斜率和截距
slope = coefficients[0]
intercept = coefficients[1]# 输出回归方程
print(f'回归方程为: y = {slope:.4f}x + {intercept:.4f}')相关图表生成
# 使用numpy的polyfit函数进行一次多项式拟合,即线性回归
reg = np.polyfit(rets['.SPX'], rets['.VIX'], deg=1)# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300# 设置字体为WenQuanYi SimHei
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 创建一个散点图,x轴为'.SPX',y轴为'.VIX'
ax = rets.plot(kind='scatter', x='.SPX', y='.VIX', figsize=(10, 6))# 在散点图上绘制拟合的直线
# np.polyval函数用于计算在给定的x值上多项式的值
ax.plot(rets['.SPX'], np.polyval(reg, rets['.SPX']), 'r')plt.show()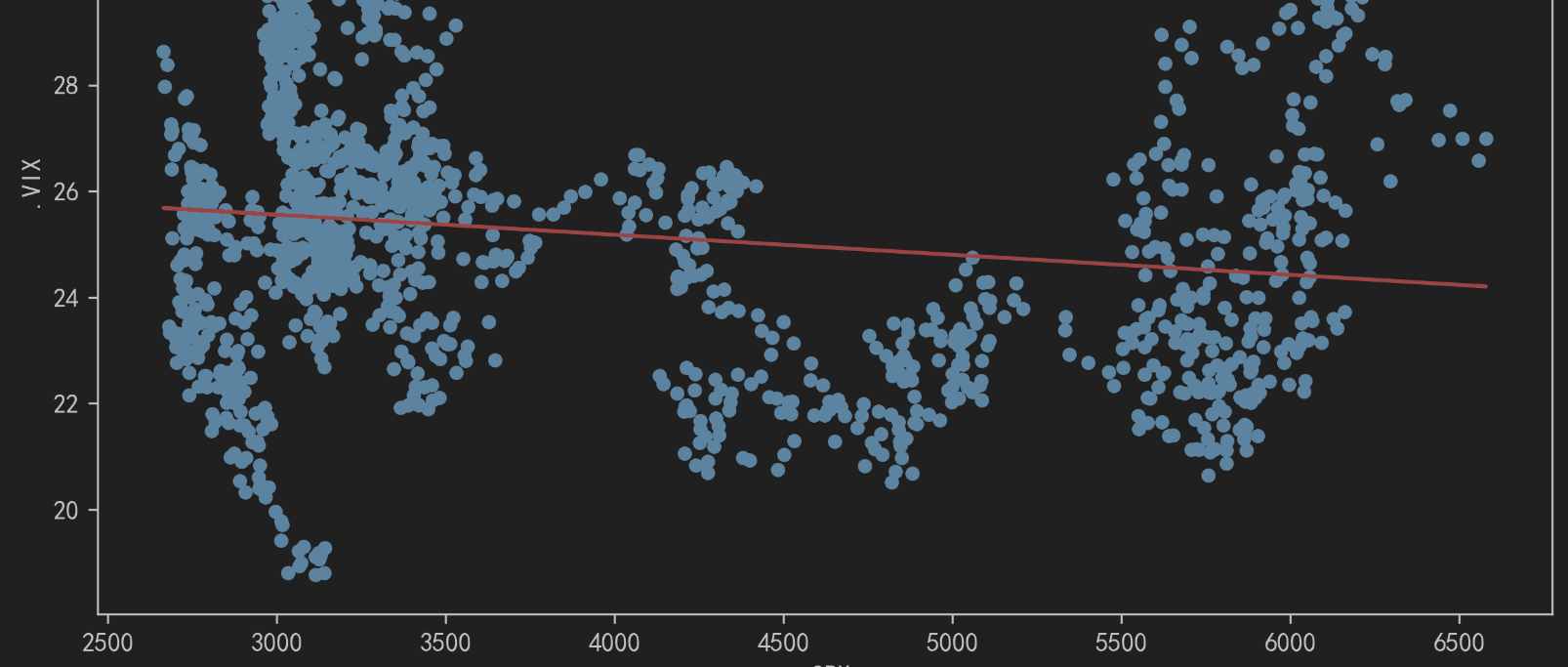
指标相关性分析
# 计算'.SPX'列的250天滚动窗口的相关性与'.VIX'列
rolling_corr = rets['.SPX'].rolling(window=250).corr(rets['.VIX'])# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300# 设置字体为WenQuanYi SimHei
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 绘制相关性图,设置图形大小为10x6
rolling_corr.plot(figsize=(10, 6))plt.show()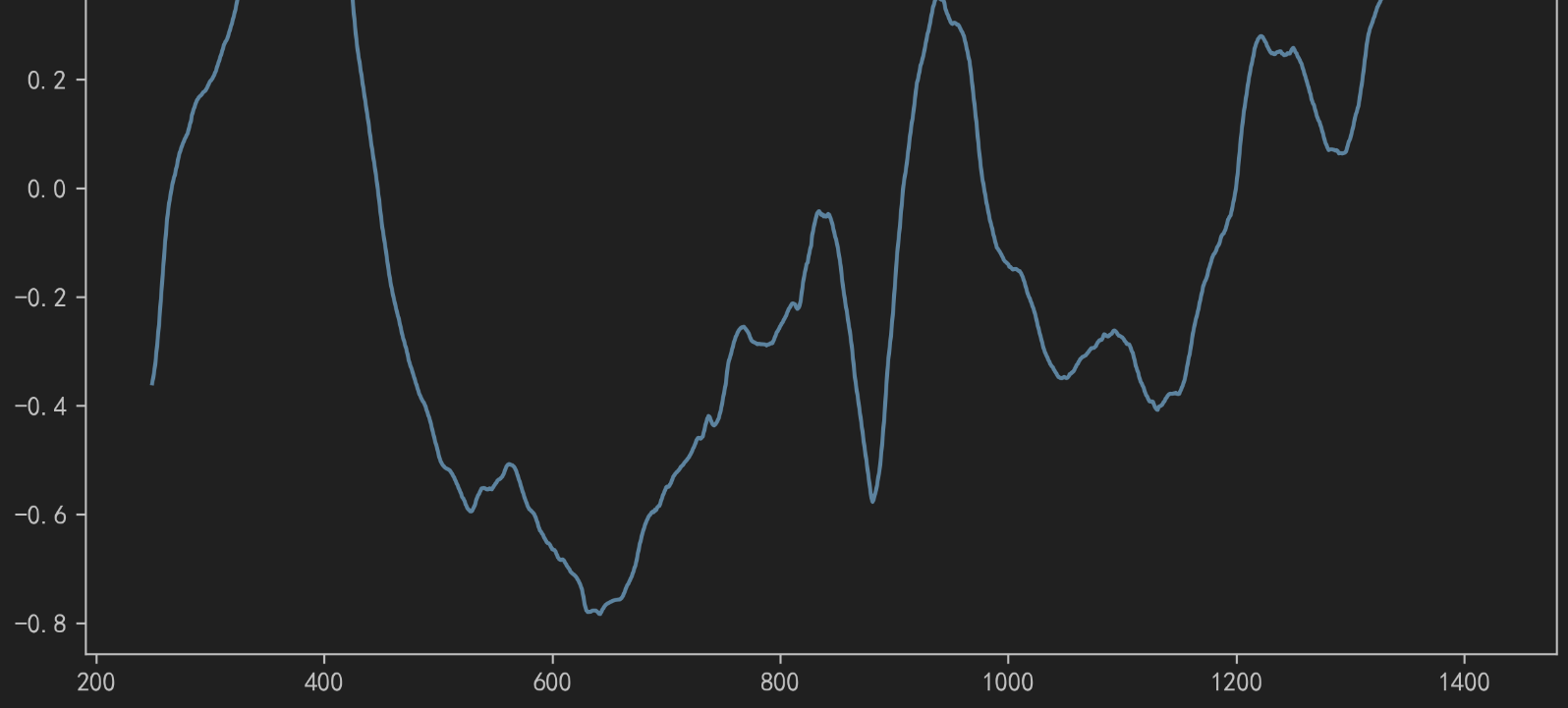
均线策略示例分析
该策略基于双均线交叉原理:
当短期均线从下方穿过长期均线时(金叉),产生买入信号
当短期均线从上方穿过长期均线时(死叉),产生卖出信号
策略步骤
1. 数据准备与预处理
# 导入必要的库
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 忽略警告信息
warnings.filterwarnings("ignore")# 设置图片清晰度和中文字体
plt.rcParams['figure.dpi'] = 300
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 读取数据并处理缺失值
data = pd.read_csv('data.csv', index_col=0, parse_dates=True)
data = data[['AAPL.0']].dropna()导入了数据处理、数值计算和可视化所需的库
设置了图片清晰度和中文字体,确保图表能正常显示中文
从CSV文件读取数据,设置日期为索引,并只保留苹果公司股票价格列,同时删除缺失值
2. 计算技术指标(双均线)
# 定义短期和长期均线的周期
SMA1 = 42 # 短期均线周期
SMA2 = 252 # 长期均线周期
# 计算长短期均线
data['SMA1'] = data['AAPL.0'].rolling(SMA1).mean()
data['SMA2'] = data['AAPL.0'].rolling(SMA2).mean()# 绘制价格与均线图
data.plot(figsize=(10, 6))
plt.title('AAPL.0价格与长短期均线')
plt.xlabel('时间')
plt.ylabel('价格与均线值')
plt.show()定义了42天短期均线和252天长期均线(约等于一年的交易日数量)
使用pandas的rolling()函数计算移动平均线
绘制了包含股票价格和两条均线的图表,帮助直观理解价格与均线的关系
3. 生成交易信号
# 去除因计算均线产生的缺失值
data.dropna(inplace=True)
# 根据长短期均线关系确定持仓信号
data['Position'] = np.where(data['SMA1'] > data['SMA2'], 1, -1)# 绘制包含持仓信号的数据图
data.plot(secondary_y='Position', figsize=(10, 6))
plt.title('AAPL.0价格、长短期均线与持仓信号')
plt.xlabel('时间')
plt.ylabel('价格、均线值与持仓信号')
plt.show()去除了因计算均线而产生的缺失值
当短期均线高于长期均线时,生成买入信号(1);反之生成卖出信号(-1)
绘制了包含价格、均线和持仓信号的图表,便于观察交易信号的产生时机
4. 计算策略收益
# 计算对数收益率
data['Returns'] = np.log(data['AAPL.0'] / data['AAPL.0'].shift(1))
# 计算策略收益
data['Strategy'] = data['Position'].shift(1) * data['Returns']# 去除因计算收益产生的缺失值
data.dropna(inplace=True)计算股票价格的对数收益率作为基准收益
使用前一天的持仓信号乘以当日收益率得到策略收益
再次删除因计算产生的缺失值
5. 评估策略绩效
# 计算累计收益
cumulative_returns = np.exp(data[['Returns', 'Strategy']].sum())
print("累计基准收益:", cumulative_returns['Returns'])
print("累计策略收益:", cumulative_returns['Strategy'])
# 计算年化收益率
years = len(data) / 252
annualized_returns = np.exp(data[['Returns', 'Strategy']].sum() / years) - 1
print("年化基准收益率:", annualized_returns['Returns'])
print("年化策略收益率:", annualized_returns['Strategy'])# 假设无风险利率为2%,计算夏普比率
risk_free_rate = 0.02
returns_std = data[['Returns', 'Strategy']].std()
sharpe_ratio = (np.exp(data[['Returns', 'Strategy']].sum()) - 1 - risk_free_rate) / returns_std
print("基准夏普比率:", sharpe_ratio['Returns'])
print("策略夏普比率:", sharpe_ratio['Strategy'])# 绘制基准收益和策略收益的累计收益曲线
data[['Returns', 'Strategy']].cumsum().apply(np.exp).plot(figsize=(10, 6))
plt.title('累计收益曲线')
plt.xlabel('时间')
plt.ylabel('累计收益')
plt.show()计算并打印累计收益,展示策略相对于基准的总体表现
计算并打印年化收益率,便于不同时间周期的策略比较
计算并打印夏普比率,评估风险调整后的收益能力,值越高表示单位风险获得的收益越高
绘制累计收益曲线,直观展示策略在整个回测期内的表现
均线范围选择
在上一个环节,我们的策略当中,均线长度是主观设定的,并没有经过严格的检验,因此,我们需要遍历各种移动平均的参数选择来得到合适的参数
from itertools import product
import numpy as np
import pandas as pd# 读取数据
data = pd.read_csv('data.csv', index_col=0, parse_dates=True)sma1 = range(20, 61, 4)
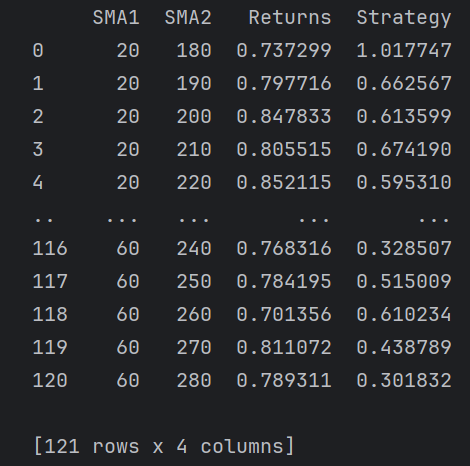
sma2 = range(180, 281, 10)results_list = []for SMA1, SMA2 in product(sma1, sma2):# 提取需要的列数据df = data[['AAPL.0']].copy()df.dropna(inplace=True)# 计算对数收益率df['Returns'] = np.log(df['AAPL.0'] / df['AAPL.0'].shift(1))# 计算不同周期的均线df['SMA1'] = df['AAPL.0'].rolling(SMA1).mean()df['SMA2'] = df['AAPL.0'].rolling(SMA2).mean()df.dropna(inplace=True)# 根据均线关系确定持仓信号df['Position'] = np.where(df['SMA1'] > df['SMA2'], 1, -1)# 计算策略收益df['Strategy'] = df['Position'].shift(1) * df['Returns']df.dropna(inplace=True)# 计算累计收益perf = np.exp(df[['Returns', 'Strategy']].sum())results_list.append({'SMA1': SMA1,'SMA2': SMA2,'Returns': perf['Returns'],'Strategy': perf['Strategy']})results = pd.DataFrame(results_list)
print(results)
常见指标分析
import pandas as pd
import numpy as np# 读取数据
df = pd.read_csv('data.csv', index_col=0, parse_dates=True)# 计算回测收益率
df_new = df / df.iloc[0]
df_new.plot(figsize=(10, 6))
total_ret = df_new.iloc[-1] - 1
total_return_df = pd.DataFrame(total_ret.values, columns=['回测收益率'], index=total_ret.index)# 计算回测年化收益
annual_ret = pow(1 + total_ret, 250 / len(df_new)) - 1
annual_return_df = pd.DataFrame(annual_ret.values, columns=['回测年化收益'], index=total_ret.index)# 计算最大回撤
max_drawdown = ((df['AAPL.0'].cummax() - df['AAPL.0']) / df['AAPL.0'].cummax()).max()# 无风险收益率,这里假设为年化0.05%
risk_free_rate = 0.05 / 250# 计算每只股票的超额收益率
exReturns = df.sub(risk_free_rate, axis=0)# 计算每只股票的年化收益率
annualized_returns = np.power(1 + exReturns, 250) - 1# 计算每只股票收益率的标准差
std_devs = np.std(exReturns, axis=0, ddof=1)# 计算每只股票的夏普比率
sharpe_ratios = (annualized_returns.mean(axis=0) - risk_free_rate) / std_devs# 计算所有股票夏普比率的平均值
average_sharpe_ratio = np.mean(sharpe_ratios)print("回测收益率:")
print(total_return_df)
print("回测年化收益:")
print(annual_return_df)
print("最大回撤:", max_drawdown)
print("所有股票夏普比率的平均值:", average_sharpe_ratio)