#Paper Reading# DeepSeek-V3
论文题目: DeepSeek-V3
论文地址: https://arxiv.org/pdf/2412.19437
论文发表于: arXiv 2024年12月
论文所属单位: DeepSeek
论文大体内容
本文发布了DeepSeek-V3模型,框架遵循了V2模型[3],包括MLA和MoE。除此之外,本文融合了MTP(Multi-Token Prediction)的优化点,让模型训练更稠密。经过14.8T的token训练,得到一个671B的模型,共花费557.6万美元,取得了开源模型SOTA的效果,并与闭源模型GPT-4o效果相当。
Motivation
本文继续沿着DeepSeek经济实用同时效果非凡的路子去走,探索效果更佳更经济的开源大模型。
Contribution
①负载均衡的训练策略:开创了一种用于负载均衡的辅助无损策略,该策略可以最大限度地减少因鼓励负载均衡而引起的性能下降。
②MTP训练目标:让模型训练更稠密,并通过消融发现是对模型效果有提升。
③FP8混合精度训练框架。
④通过计算和通信的重叠,克服跨节点的MoE通信瓶颈。
⑤对DeepSeek-R1的知识蒸馏,提升效果。
⑥模型效果很强:开源模型SOTA,与闭源模型GPT-4o相当。
1. DeepSeek-V3整体框架沿用V2的,包括MLA和MoE。对于MLA和MoE的原理详见[3][4]

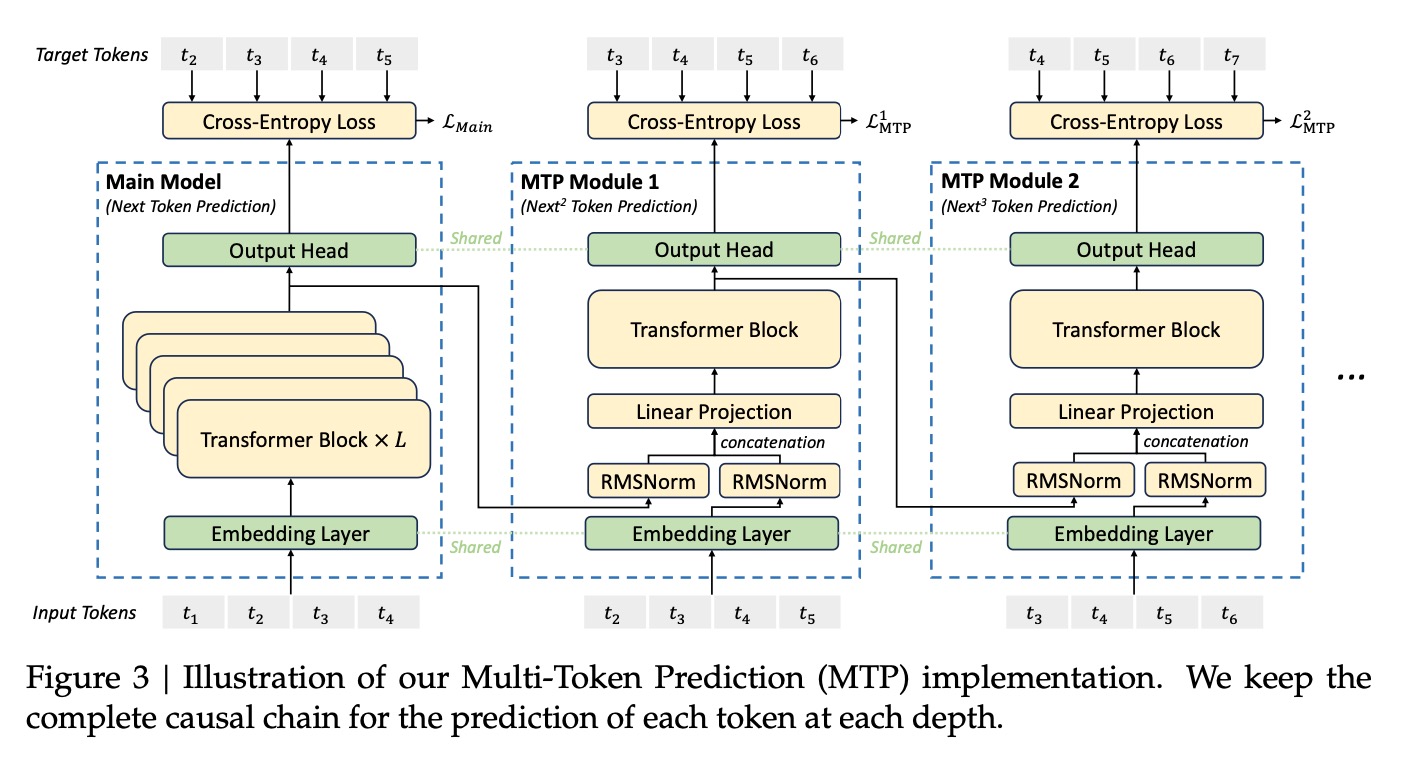
2. MTP(Multi-Token Prediction)模块
①训练时增加MTP模块,增加交叉熵损失到Loss里面,提升训练效果。
②推理时丢弃该模块,也就是一次还是只预测了一个token。
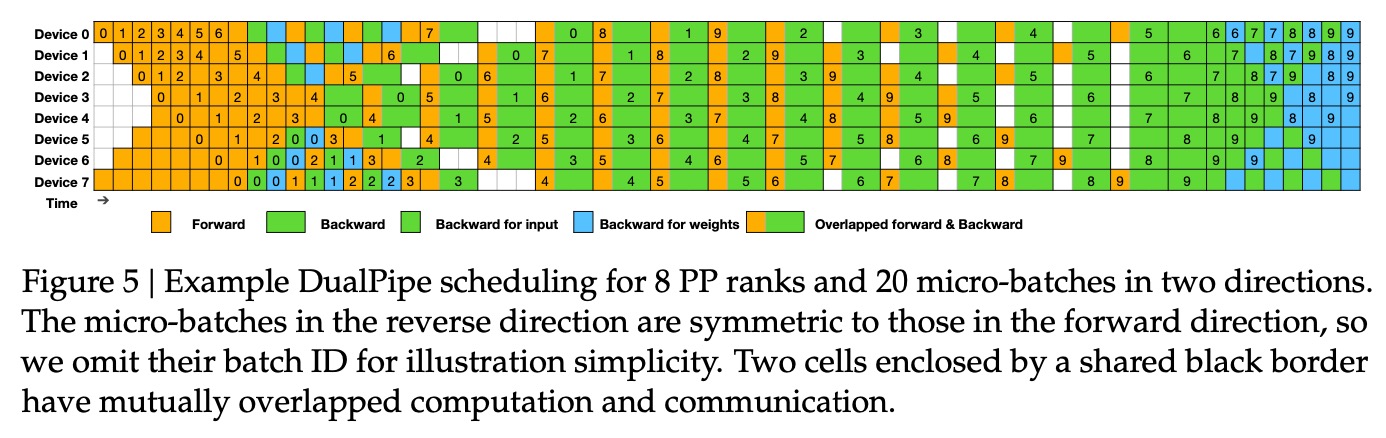
3. 训练框架:通过计算和通信的重叠,克服跨节点的MoE通信瓶颈。
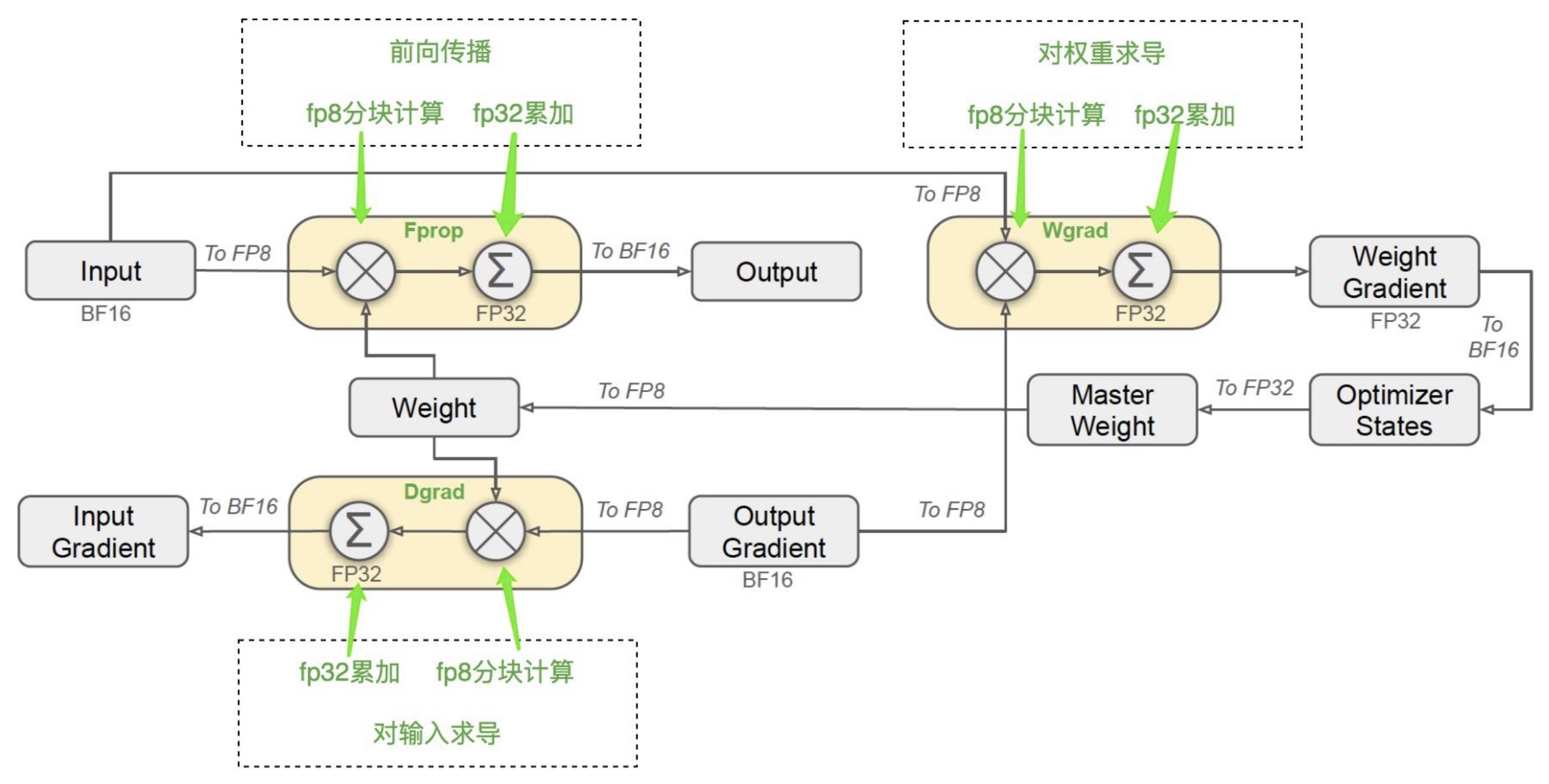
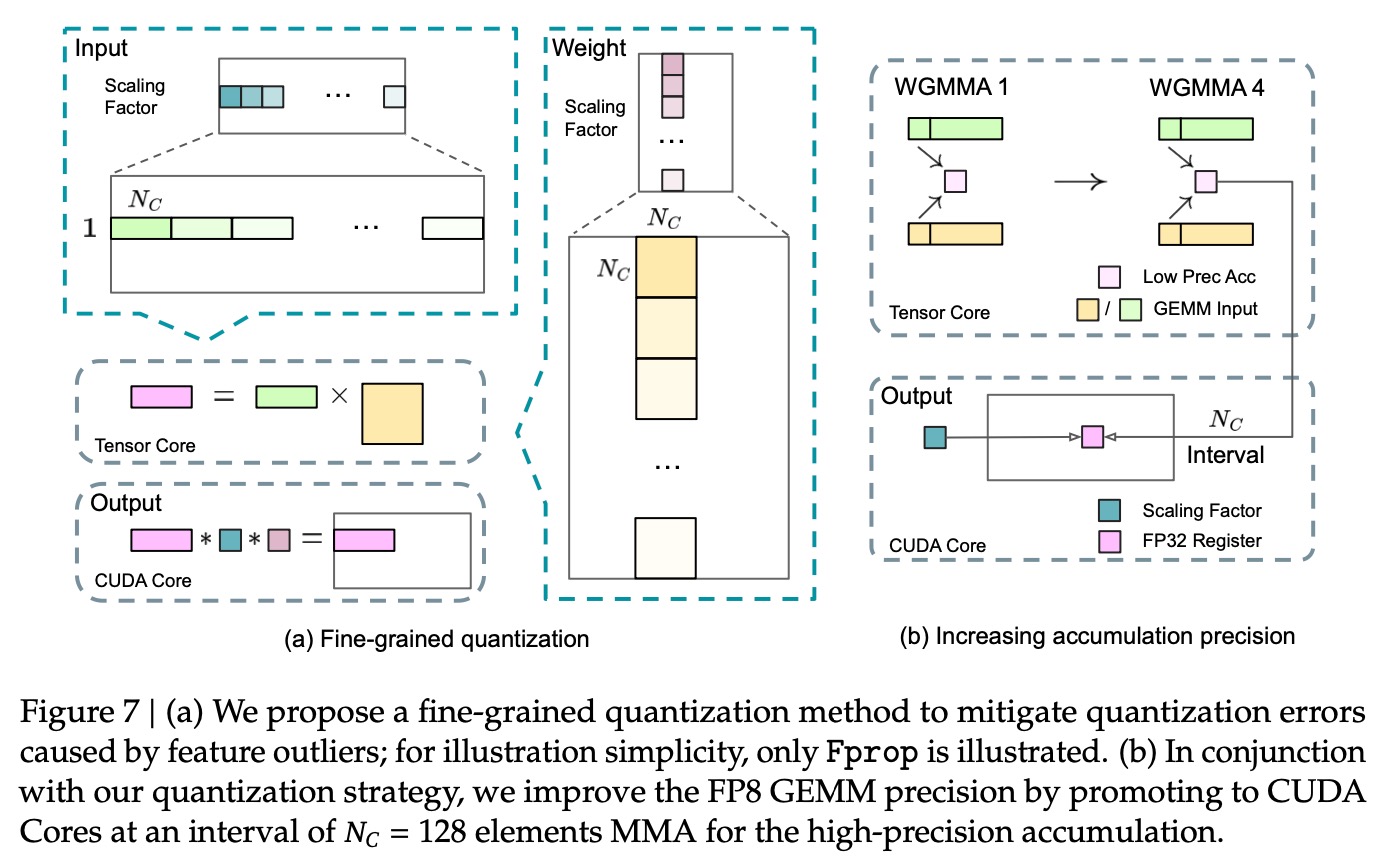
4. FP8混合精度训练:之前常见的方式是模型训练完成后,再进行量化,但本文在训练过程中就已经使用了FP8量化精度,相对损失低于0.25%。主要应用在3个部分:前向传播,对权重求导和对输入求导。这种方式能提升计算速度一倍,并减少内存消耗。
5. 推理和部署:本文在各个阶段尝试了不同的工程优化手段去提升性能。
①预填充(Prefilling):冗余Expert部署策略,尽可能平衡GPU的负载。
②解码(Decoding):每个GPU只涉及1个Expert,提高吞吐量。
6. 本文还对GPU硬件提出了一些建议,包括计算和通信等,探讨怎样才能更合理的榨干硬件的利用率。
7. 预训练
①DeepSeek-V3模型使用了1个shared expert和256个experts。
②上下文扩展:利用YaRN方法将上下文窗口从4k扩展到32k,再扩展到128k,
8. 评估
①多选题Multi-subject multiple-choice:MMLU、C-Eval、CMMLU
②语言理解和推理Language understanding and reasoning:HellaSwag、PIQA、ARC、OpenBookQA、BigBench Hard
③闭卷问答Closed-book question answering:TriviaQA、NaturalQuestions
④阅读理解Reading comprehension:RACE、DROP、C3
⑤消歧Reference disambiguation:WinoGrande、CLUEWSC
⑥语言建模Language modeling:Pile
⑦中文Chinese understanding and culture:CHID、CCPM
⑧数学Math:GSM8K、MATH、CMATH
⑨代码Code:HumanEval、MBPP
⑩考试Standardized exams:AGIEval
9. 评测结果:671B的模型,每个token激活37B参数量。
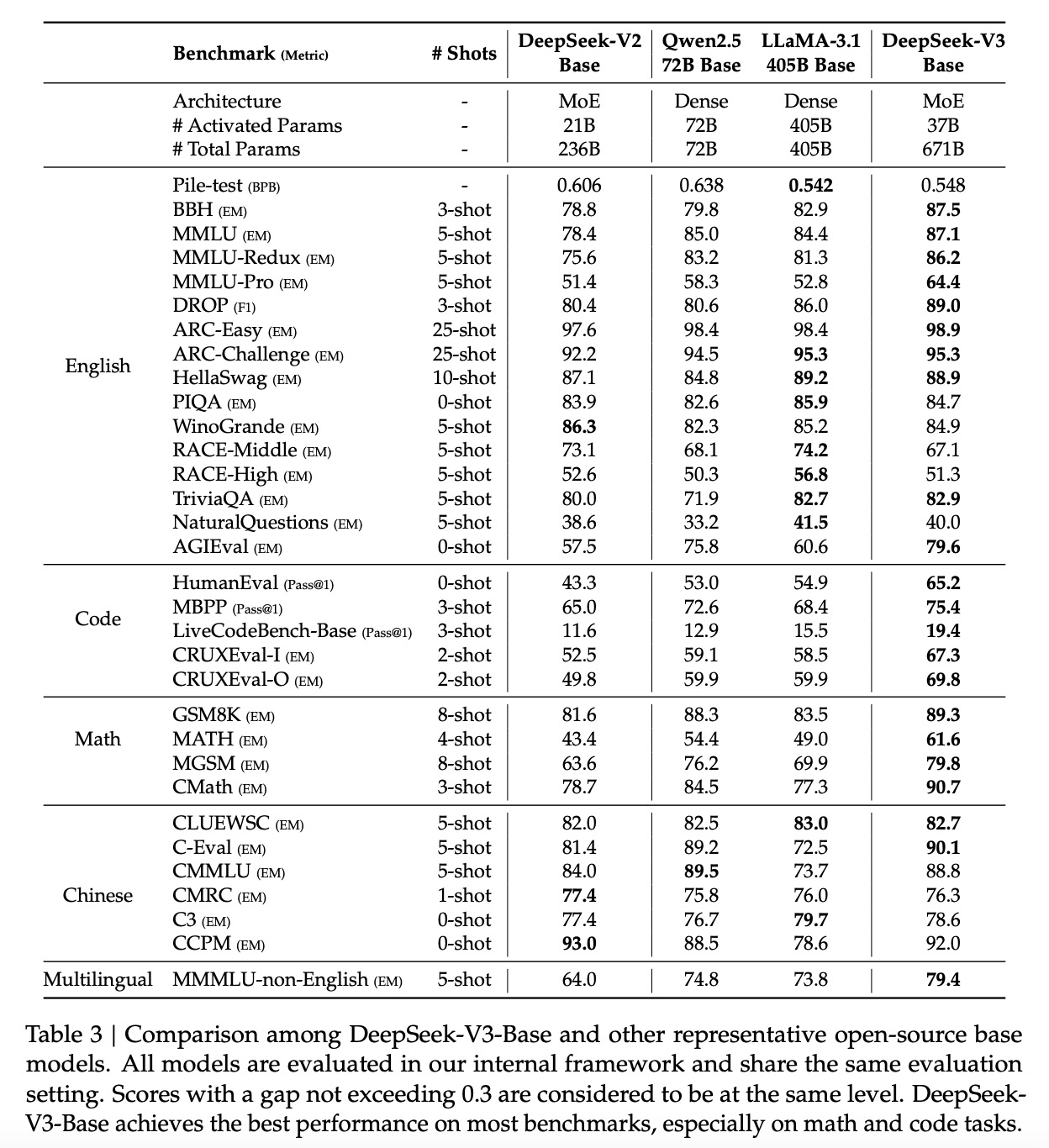
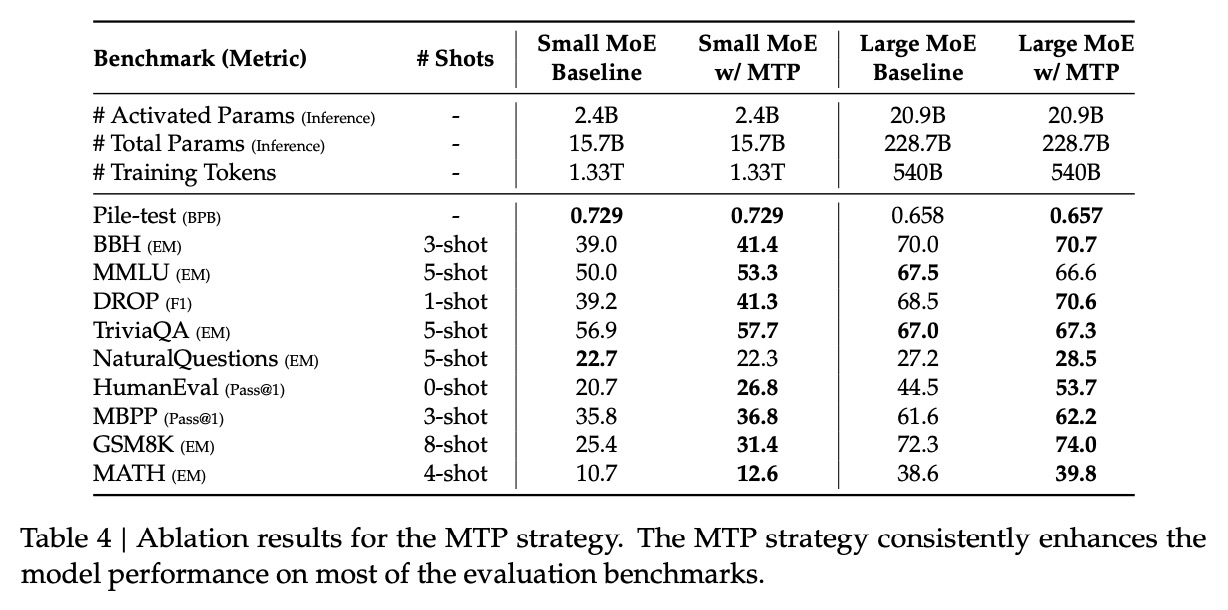
10. MTP的消融作用:增加MTP对模型的效果有明显提升。
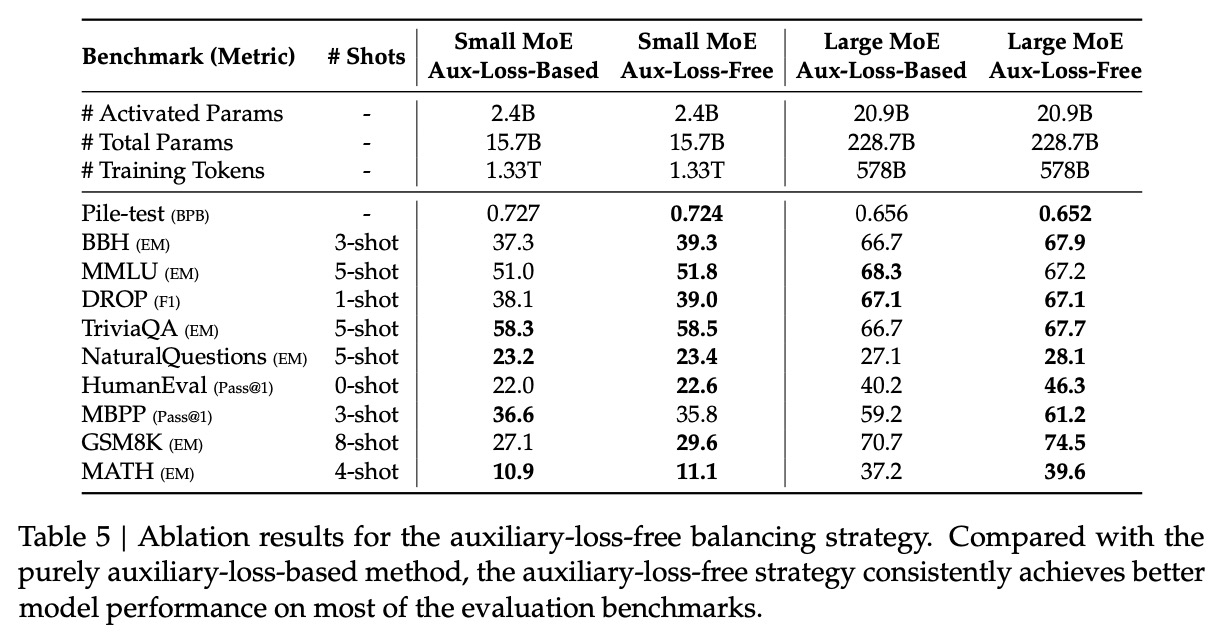
11. 负载均衡的无损平衡策略消融:相比原有的有损策略,无损的效果更好。
12. 后训练(Post-Training)
①SFT:本文使用了1.5M的实例去SFT。
i) 推理数据:使用DeepSeek-R1去生成。
ii) 非推理数据(例如创意写作、角色扮演和简单的问答):使用DeepSeek-V2.5生成,并进行人工评测和验证修改。
②RL
i) Rule-based的Reward Model:可以使用特定规则来验证的问题,如数学题、编程代码题等,使用Rule-based的模型。
ii) Model-based的Reward Model:具有自由格式的ground-truth答案的问题,使用Model-based模型确认是否匹配;而写作创意类的问题,模型提供反馈。
iii) 使用GRPO(Group Relative Policy Optimization)去进行RL。
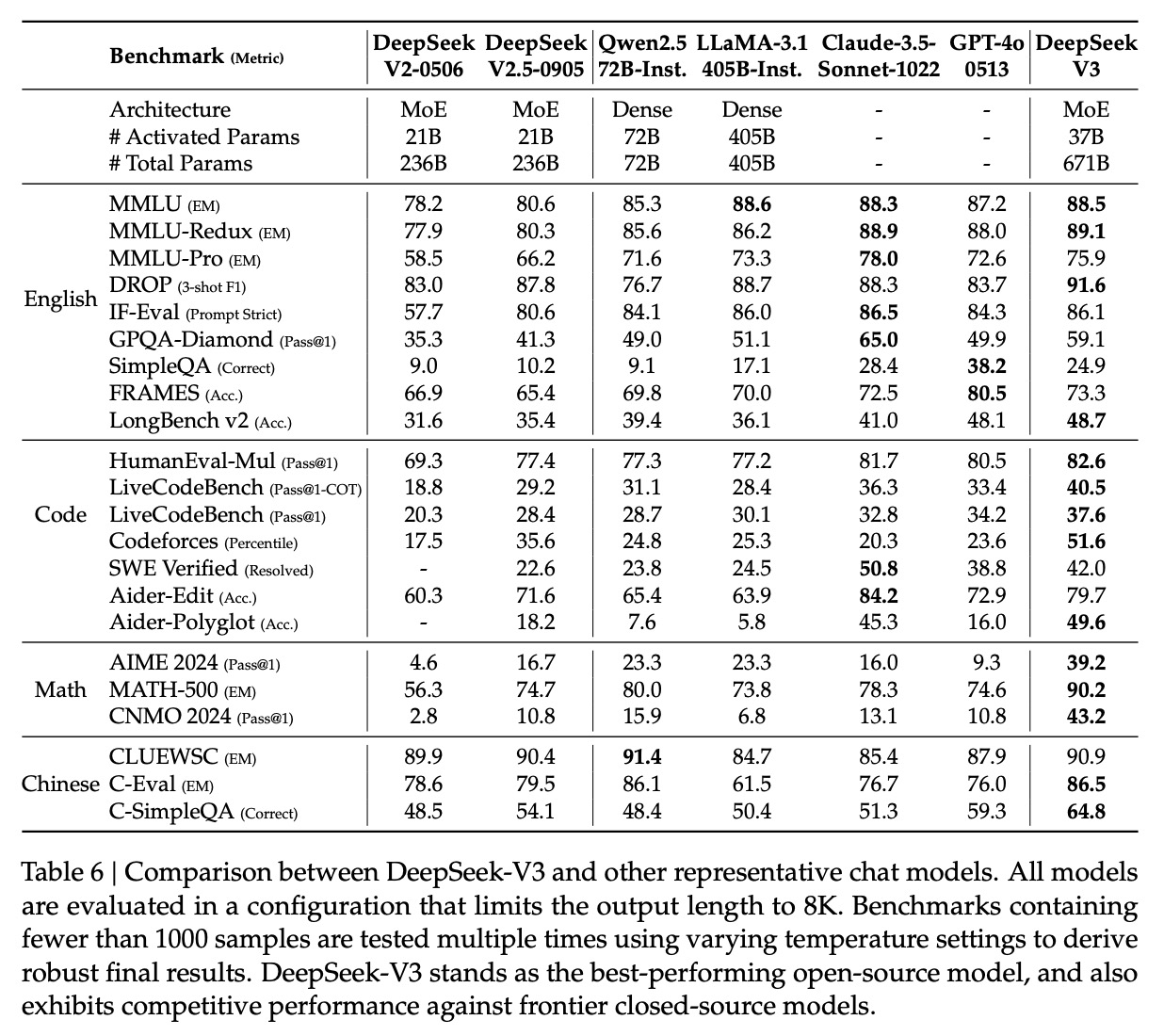
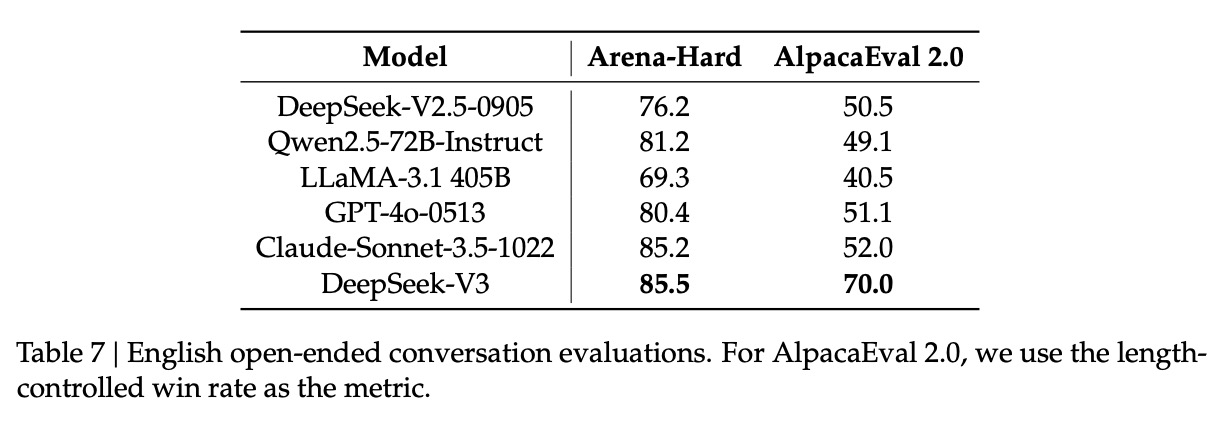
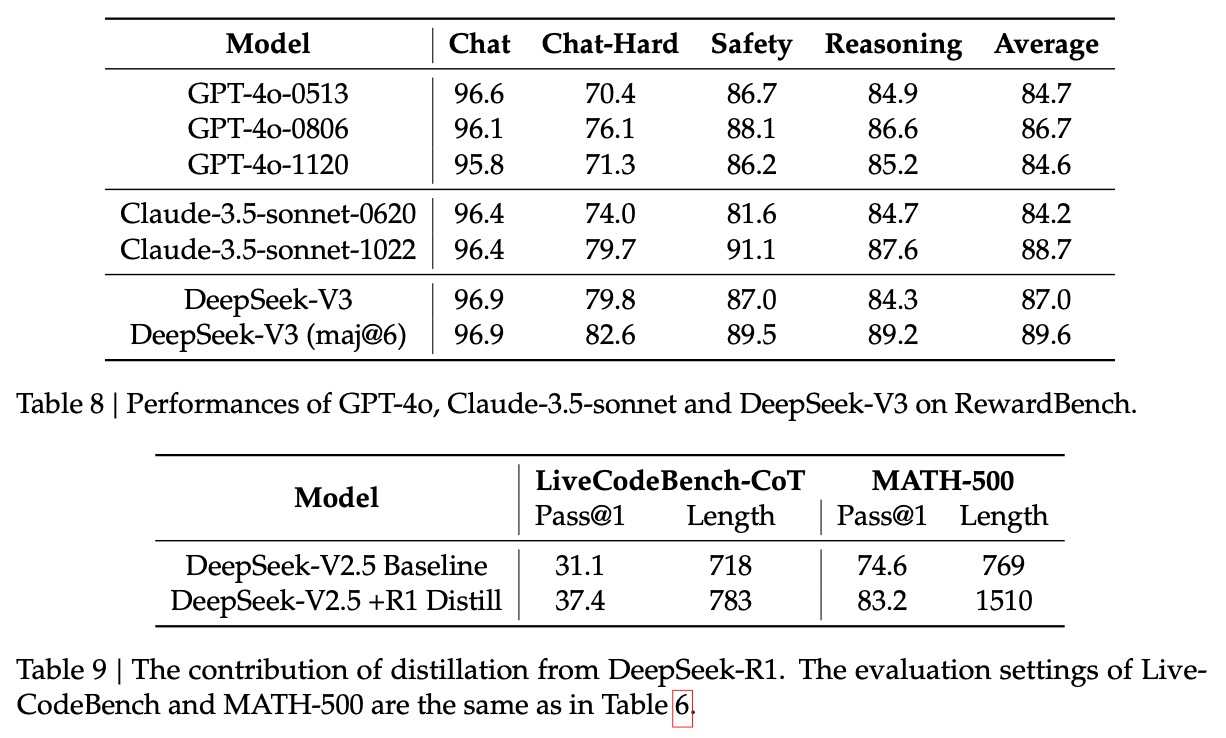
13. 聊天模型评测结果
参考资料
[1] 深度求索DeepSeek背后的底层逻辑:https://zhuanlan.zhihu.com/p/29573646728
[2] 逐篇讲解DeepSeek关键9篇论文及创新点——“勇敢者的游戏”:https://www.bilibili.com/video/BV1xuK5eREJi/
[3] DeepSeek-V2:https://blog.csdn.net/John159151/article/details/147200272
[4] DeepSeek MoE:https://blog.csdn.net/John159151/article/details/147199203