嵌入式面试题解析:二维数组,内容与总线,存储格式
在嵌入式系统领域,扎实掌握基础概念是应对面试的关键。本文通过典型面试题,详细解析核心知识,梳理易错点,并补充常见面试题,助力新手快速入门。
一、二维数组元素地址计算
题目
若二维数组 arr[0..M-1][0..N-1] 的首地址为 base,数组元素每个元素占用 K 个存储单元,则元素 arr[i][j] 在该数组空间的地址为( )
A. base+((i)*M+j)*K
B. base+((i)*N+j)*K
C. base+((j)*M+i)*K
D. base+((j)*N+i)*K
知识点详解
1. 存储方式与地址计算原理
-
行优先存储(C 语言默认方式):
- 数组元素按行连续存储,即先存储完一行元素,再存储下一行。
- 地址计算步骤:
- 计算完整行数:
arr[i][j]前面有i行完整的行。 - 每行元素数:每行包含
N个元素(列数),因此i行共有i * N个元素。 - 当前行偏移:第
i行中,j是第j+1个元素,因此当前行偏移量为j。 - 总偏移量:
i * N + j。 - 地址公式:
base + (i * N + j) * K。
- 计算完整行数:
-
列优先存储(如 Fortran 语言):
- 数组元素按列连续存储,即先存储完一列元素,再存储下一列。
- 地址计算步骤:
- 计算完整列数:
arr[i][j]前面有j列完整的列。 - 每列元素数:每列包含
M个元素(行数),因此j列共有j * M个元素。 - 当前列偏移:第
j列中,i是第i+1个元素,因此当前列偏移量为i。 - 总偏移量:
j * M + i。 - 地址公式:
base + (j * M + i) * K。
- 计算完整列数:
2. 内存布局与指针访问
- 内存布局:二维数组在内存中是连续存储的,例如
arr[3][4]的内存布局如下:plaintext
arr[0][0] → arr[0][1] → arr[0][2] → arr[0][3] ↓ arr[1][0] → arr[1][1] → arr[1][2] → arr[1][3] ↓ arr[2][0] → arr[2][1] → arr[2][2] → arr[2][3] - 指针访问示例:
int arr[3][4] = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}}; int *ptr = &arr[0][0]; // 指向首元素 printf("%d", *(ptr + i * 4 + j)); // 访问arr[i][j]
答案与解析
- 正确答案:B
- 解析:C 语言默认行优先存储,总偏移量为
i * N + j,因此地址为base + (i * N + j) * K。
- 解析:C 语言默认行优先存储,总偏移量为
易错点分析
- 混淆行优先与列优先:
- 行优先中每行元素数为
N(列数),而非M(行数)。例如arr[3][4]每行有 4 个元素。
- 行优先中每行元素数为
- 忽略元素大小
K:- 地址计算必须乘以元素大小
K,例如每个元素占 4 字节时,偏移量需乘以 4。
- 地址计算必须乘以元素大小
- 指针访问越界:
- 动态分配二维数组时,需确保
i < M且j < N,否则会导致内存越界。
- 动态分配二维数组时,需确保
常见用法与拓展
1. 三维数组地址计算
- 公式:对于三维数组
arr[x][y][z](行优先存储),地址为:plaintext
base + (x * Y * Z + y * Z + z) * KY:第二维长度,Z:第三维长度。
- 示例:
arr[2][3][4]中,arr[1][2][3]的地址为:plaintext
base + (1 * 3 * 4 + 2 * 4 + 3) * K = base + (12 + 8 + 3) * K = base + 23K
2. 动态分配二维数组
- 代码示例:
int** create_2d_array(int rows, int cols) { int** arr = (int**)malloc(rows * sizeof(int*)); for (int i = 0; i < rows; i++) { arr[i] = (int*)malloc(cols * sizeof(int)); } return arr; } // 访问元素:arr[i][j] - 注意事项:需逐层释放内存:
void free_2d_array(int** arr, int rows) { for (int i = 0; i < rows; i++) { free(arr[i]); } free(arr); }
3. 列优先存储的实际应用
- 场景:矩阵乘法中,列优先存储可减少缓存未命中,提升性能。
- 示例(C 语言模拟列优先访问):
int arr[3][4] = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}}; int element = arr[j][i]; // 手动转置索引,模拟列优先
总结
- 核心公式:行优先
base + (i * N + j) * K,列优先base + (j * M + i) * K。 - 关键技巧:通过指针偏移量访问元素,动态分配时注意内存释放。
- 拓展知识:三维数组地址计算、列优先存储的性能优化。
通过以上内容,新手可系统掌握二维数组地址计算的核心原理与实战技巧,为嵌入式面试与开发打下坚实基础。
二、内存容量与总线宽度
题目
若内存容量为 4GB,字长为 32,则( )
A. 数据总线和地址总线的宽度都为 32(bit)
B. 地址总线的宽度为 30,数据总线的宽度为 32(bit)
C. 地址总线的宽度为 30,数据总线的宽度为 8(bit)
D. 地址总线的宽度为 32,数据总线的宽度为 8(bit)
知识点详解
1. 地址总线与内存容量的关系
- 核心公式:
内存容量 = 2^ 地址总线宽度
例如,地址总线宽度为32位时,最大可寻址空间为2^32 = 4GB。 - 计算步骤:
- 单位换算:
4GB = 4 × 1024MB = 4 × 1024 × 1024KB = 4 × 1024 × 1024 × 1024B = 2^32B。 - 确定总线宽度:
2^32B对应地址总线宽度为32位。
- 单位换算:
- 实际应用:
- 32 位系统限制:虽然理论上可寻址
4GB,但实际可用内存可能因硬件映射(如显存、外设寄存器)减少至约3GB。 - 64 位系统扩展:64 位地址总线可支持
2^64B ≈ 16EB,但实际受限于硬件设计(如 Intel x86-64 支持46位地址线,对应64TB)。
- 32 位系统限制:虽然理论上可寻址
2. 数据总线与字长的关系
- 定义:
- 字长:CPU 一次能处理的数据位数(如
32位系统一次处理32位数据)。 - 数据总线宽度:决定一次能传输的数据量,必须与字长匹配。
- 字长:CPU 一次能处理的数据位数(如
- 示例:
- 字长为
32位时,数据总线宽度为32位,每次传输4字节(32/8)。 - 若数据总线宽度为
16位,需两次传输才能完成32位数据操作,效率降低。
- 字长为
3. 总线带宽计算
- 公式:
总线带宽 = 数据总线宽度 × 工作频率- 单位:
MB/s(兆字节 / 秒)。
- 单位:
- 示例:
- 数据总线宽度
32位(4B),工作频率100MHz,带宽为4B × 100MHz = 400MB/s。 - 若采用 DDR4 内存(双边沿传输),频率
1200MHz,带宽为32位 × 1200MHz × 2 = 7.68GB/s。
- 数据总线宽度
答案与解析
- 正确答案:A
- 解析:
- 地址总线:
4GB = 2^32B,需32位地址总线。 - 数据总线:字长
32位,数据总线宽度为32位。
- 地址总线:
- 解析:
易错点分析
- 内存容量换算错误:
- 错误:
4GB = 4 × 2^30B = 2^32B,误认为地址总线宽度为30位(忽略4 = 2^2)。 - 正确:
4GB = 2^32B,地址总线宽度为32位。
- 错误:
- 数据总线与字长不匹配:
- 错误:认为数据总线宽度与字长无关(如选项 D 中数据总线宽度为
8位)。 - 正确:数据总线宽度必须等于字长(
32位)。
- 错误:认为数据总线宽度与字长无关(如选项 D 中数据总线宽度为
常见用法与拓展
1. 总线类型与功能
- 地址总线(AB):
- 作用:传输内存地址,单向(CPU → 内存)。
- 位数:决定最大寻址空间(如
32位 →4GB)。
- 数据总线(DB):
- 作用:传输数据,双向(CPU ↔ 内存)。
- 位数:决定单次传输数据量(如
32位 →4B)。
- 控制总线(CB):
- 作用:传输控制信号(如读 / 写命令、中断请求)。
- 信号示例:
RD#(读使能)、WR#(写使能)、CS#(片选)。
2. 内存层次结构对总线的影响
- 缓存(Cache):
- 作用:存储主存中常用数据,减少总线访问次数。
- 原理:缓存命中率越高,总线负载越低,系统性能越好。
- DMA(直接内存访问):
- 作用:外设绕过 CPU 直接访问内存,减轻总线负担。
- 场景:高速数据传输(如网络接口、硬盘)。
3. 实际应用案例
- DDR4 内存设计:
// DDR4 内存配置示例(伪代码) #define DDR4_DATA_WIDTH 32 // 数据总线宽度 32 位 #define DDR4_FREQ 1200 // 工作频率 1200MHz #define DDR4_BANDWIDTH (DDR4_DATA_WIDTH / 8) * DDR4_FREQ * 2 // 7.68GB/s - Linux 查看总线信息:
# 查看 CPU 地址总线宽度 cat /proc/cpuinfo | grep "address sizes" # 输出示例:address sizes : 36 bits physical, 48 bits virtual
4. 总线性能优化技巧
- 总线复用:
- 原理:同一组信号线分时传输地址和数据(如 8086 地址 / 数据复用总线)。
- 优点:减少引脚数量,降低硬件成本。
- 多通道技术:
- 原理:多个内存通道并行传输数据(如双通道 DDR4)。
- 效果:带宽翻倍(如单通道
7.68GB/s→ 双通道15.36GB/s)。
总结
- 核心公式:
- 地址总线宽度 = log₂(内存容量)
- 总线带宽 = 数据总线宽度 × 工作频率
- 关键技巧:
- 区分地址总线与数据总线的功能。
- 理解内存层次结构对总线性能的影响。
- 拓展知识:
- 总线时序(同步 / 异步)。
- 总线仲裁(多设备竞争总线使用权)。
通过以上内容,新手可全面掌握内存容量与总线宽度的核心原理,并结合实际案例和优化技巧提升系统设计能力。
三、存储格式判断
题目
对一个字,存储时低字节占低地址,高字节占高地址。则该种存储格式为( )
A. 小端方式
B. 大端方式
C. 低端方式
D. 高端方式
知识点详解
1. 存储格式核心定义
-
小端方式(Little-Endian):
- 定义:数据的低字节存放在内存低地址,高字节存放在内存高地址。
- 示例:16 位数据
0x1234(二进制0001 0010 0011 0100)的存储方式:- 低地址(假设为
0x1000)存低字节0x34(二进制0011 0100) - 高地址(
0x1001)存高字节0x12(二进制0001 0010)
- 低地址(假设为
-
大端方式(Big-Endian):
- 定义:数据的高字节存放在内存低地址,低字节存放在内存高地址。
- 示例:同上数据
0x1234的存储方式:- 低地址(
0x1000)存高字节0x12 - 高地址(
0x1001)存低字节0x34
- 低地址(
2. 存储格式的本质区别
| 特性 | 小端方式 | 大端方式 |
|---|---|---|
| 低地址存储 | 数据的最低有效字节(LSB) | 数据的最高有效字节(MSB) |
| 典型架构 | x86、ARM(默认配置)、ZigBee | PowerPC、MIPS、网络协议(TCP/IP) |
| 人类阅读习惯 | 不符合(低位在前) | 符合(高位在前,如 0x1234 正序) |
3. 为什么需要区分存储格式?
- 跨架构通信:不同处理器可能采用不同存储格式,例如 x86(小端)与 PowerPC(大端)通信时需转换字节序。
- 网络传输:网络协议(如 TCP/IP)规定使用大端序(又称网络字节序),确保不同设备兼容。
- 二进制文件解析:如图片、音频文件的头部信息可能包含多字节数据,需按指定格式解析。
答案与解析
- 正确答案:A
- 解析:题目描述 “低字节占低地址” 符合小端方式的定义,口诀 “小端低对低” 可辅助记忆。
易错点分析
-
定义混淆:
- 错误:认为 “大端是低位在前”,或记反高低字节与地址的对应关系。
- 正确:通过 “小端低对低,大端高对低” 口诀强化记忆(小端低字节对低地址,大端高字节对低地址)。
-
网络传输忽略字节序转换:
- 错误:在 x86(小端)上直接发送本地数据到网络,导致接收端(如大端设备)解析错误。
- 正确:发送前用
htonl()/htons()转换为网络字节序(大端),接收后用ntohl()/ntohs()转换回本地字节序。
-
联合体 / 指针检测时的类型错误:
- 错误:使用
int类型指针强制转换时未考虑字节对齐,导致检测失败。 - 正确:使用
char类型指针或联合体(利用内存共享特性)进行检测(见下方示例)。
- 错误:使用
常见用法与拓展
1. 检测当前系统的存储格式
-
方法 1:使用联合体(推荐,简洁直观)
#include <stdio.h> int check_endian() { union { int i; char c[sizeof(int)]; } u; u.i = 0x12345678; // 假设int为4字节 return u.c[0]; // 小端返回0x78(低地址存LSB),大端返回0x12(低地址存MSB) } int main() { if (check_endian() == 0x78) { printf("Little-Endian\n"); } else { printf("Big-Endian\n"); } return 0; }- 原理:联合体成员共享内存,
u.c[0]访问低地址字节,根据值判断格式。
- 原理:联合体成员共享内存,
-
方法 2:使用指针强制类型转换
int is_little_endian() { int num = 0x12345678; char *p = (char *)# return (*p == 0x78); // 小端返回1,大端返回0 }
2. 字节序转换函数(C 语言标准库)
-
函数列表:
函数名 作用 参数解释 返回值 htonl()主机字节序 → 网络字节序(长整型) hostlong:本地 4 字节数据网络字节序的 4 字节数据 htons()主机字节序 → 网络字节序(短整型) hostshort:本地 2 字节数据网络字节序的 2 字节数据 ntohl()网络字节序 → 主机字节序(长整型) netlong:网络 4 字节数据本地字节序的 4 字节数据 ntohs()网络字节序 → 主机字节序(短整型) netshort:网络 2 字节数据本地字节序的 2 字节数据 -
示例:网络传输中的字节序转换
// 发送端(x86小端):将本地IP地址转换为网络字节序(大端) unsigned int local_ip = 0x01020304; // 本地格式1.2.3.4(小端存储为04 03 02 01) unsigned int net_ip = htonl(local_ip); // 转换后为01 02 03 04(大端) // 接收端:将网络字节序转换为本地字节序 unsigned int received_ip = ntohl(net_ip); // 恢复为0x01020304(与平台无关)
3. 嵌入式场景中的典型应用
-
场景 1:多架构设备通信
- 设备 A(小端 ARM)与设备 B(大端 PowerPC)通信时:
- 设备 A 发送数据前,将整数 / 短整数通过
htonl()/htons()转为大端。 - 设备 B 接收后,用
ntohl()/ntohs()转为本地格式。
- 设备 A 发送数据前,将整数 / 短整数通过
- 设备 A(小端 ARM)与设备 B(大端 PowerPC)通信时:
-
场景 2:解析二进制协议包
- 假设协议包中包含 2 字节的大端整数
0x1234,在小端设备上解析:
char buf[2] = {0x12, 0x34}; // 大端存储(低地址0x12,高地址0x34) unsigned short num = (buf[0] << 8) | buf[1]; // 手动转换为小端数值0x3412 - 假设协议包中包含 2 字节的大端整数
-
场景 3:内存调试中的数据查看
- 通过调试工具(如 GDB)查看内存时,需根据存储格式解读多字节数据:
bash
# 假设内存地址0x1000处存储4字节数据(小端):0x78 0x56 0x34 0x12 (gdb) x/4xb 0x1000 0x1000: 0x78 0x56 0x34 0x12 # 解读为整数:0x12345678(小端格式)
4. 进阶知识:存储格式与结构体对齐
- 当结构体包含多字节数据时,存储格式不影响结构体对齐方式,但会影响字段的内存顺序:
// 小端系统中结构体的内存布局(假设int为4字节,char为1字节) struct Data { char a; // 地址0x1000: 0x01 int b; // 地址0x1001: 0x02 0x03 0x04 0x05(小端存储0x05040302) };
总结
- 核心定义:小端(低字节→低地址)vs 大端(高字节→低地址),口诀 “小端低对低” 辅助记忆。
- 关键用法:
- 用联合体 / 指针检测系统存储格式。
- 网络编程中必须使用
htonl()/ntohl()等函数转换字节序。
- 拓展场景:跨架构通信、二进制协议解析、内存调试数据解读。
通过以上内容,新手可深入理解存储格式的本质,掌握检测方法和实际应用技巧,避免嵌入式开发中因字节序问题导致的错误。
四、补充嵌入式常见面试题
1. 结构体对齐(内存对齐)
题目
以下结构体的大小是多少?
struct Data { char a; int b; short c;
};
A. 8 字节
B. 12 字节
C. 16 字节
D. 7 字节
知识点详解
- 核心规则:
- 成员对齐:每个成员按其类型的大小(或编译器默认对齐系数)对齐。
- 结构体整体对齐:结构体大小为最大成员类型的整数倍。
- 计算步骤:
char a(1 字节)→ 偏移 0,占 1 字节。int b(4 字节)→ 需对齐到 4 的倍数,填充 3 字节,偏移 4,占 4 字节。short c(2 字节)→ 需对齐到 2 的倍数,偏移 8,占 2 字节。- 总大小:8 字节(未达最大成员 4 字节的整数倍,需补 0)。
- 实际应用:
- 硬件兼容性:某些 CPU(如 ARM)要求特定对齐,否则访问会失败。
- 空间优化:合理调整结构体成员顺序可减少内存占用。
答案与解析
- 正确答案:A
- 解析:结构体总大小为 8 字节(1+3 填充 + 4+2=8),满足最大成员 4 字节的整数倍。
易错点分析
- 未考虑填充字节:
- 错误:直接相加 1+4+2=7 字节。
- 正确:需填充 3 字节使
int b对齐到 4 的倍数。
- 结构体整体对齐遗漏:
- 错误:认为总大小为 8 字节已满足条件(实际确实满足)。
常见用法与拓展
- 手动控制对齐:
// 使用GCC的__attribute__((packed))取消填充 struct __attribute__((packed)) Data { char a; int b; short c; }; // 大小为7字节(1+4+2) - 嵌套结构体对齐:
struct Nested { int a; struct { char b; short c; } nested; }; // 嵌套结构体内部对齐后占4字节(1+1填充+2),整体对齐到4字节,总大小8字节 - 内存布局查看:
# 使用GCC编译时添加-fno-strict-aliasing选项 gcc -c -fdump-struct-details file.c # 查看生成的*.o.d文件,显示结构体布局
2. volatile 关键字的作用
题目
在嵌入式开发中,为什么需要使用volatile关键字?
A. 提高代码执行效率
B. 防止编译器优化变量访问
C. 确保变量操作的原子性
D. 定义全局变量
知识点详解
- 核心定义:
volatile告知编译器该变量可能被外部因素(如中断、硬件寄存器)修改,禁止优化其访问。
- 典型场景:
- 硬件寄存器操作:
volatile uint32_t *GPIO_REG = (uint32_t *)0x40020000; // 映射GPIO寄存器 *GPIO_REG = 0x1; // 直接写入硬件寄存器,必须使用volatile - 中断服务程序(ISR)共享变量:
volatile int flag = 0; // 标志位由ISR修改 void ISR() { flag = 1; } // 主程序中读取flag时,编译器不会缓存旧值
- 硬件寄存器操作:
- 底层原理:
- 编译器优化可能导致变量被缓存到寄存器,而不是每次都从内存读取。
volatile强制每次访问内存,确保数据一致性。
- 编译器优化可能导致变量被缓存到寄存器,而不是每次都从内存读取。
答案与解析
- 正确答案:B
- 解析:
volatile的核心作用是禁止编译器优化,确保变量访问的实时性。
- 解析:
易错点分析
- 误认为保证原子性:
- 错误:认为
volatile能防止多线程竞争。 - 正确:
volatile仅保证可见性,不保证原子性(如i++仍需同步机制)。
- 错误:认为
- 滥用
volatile:- 错误:对普通变量使用
volatile,降低性能。 - 正确:仅用于可能被外部修改的变量(如寄存器、ISR 共享变量)。
- 错误:对普通变量使用
常见用法与拓展
- 编译器优化示例:
int x = 10; while(x > 0) { x--; } // 编译器可能优化为死循环(假设x未被修改) volatile int x = 10; while(x > 0) { x--; } // 每次循环读取内存,确保x递减 - 与
const结合使用:const volatile uint32_t *READ_ONLY_REG = (uint32_t *)0x40020004; // 寄存器值只读且可能被硬件修改 - 跨平台差异:
- 不同编译器对
volatile的处理可能不同(如 GCC、Keil MDK),需查阅文档。
- 不同编译器对
3. UART、SPI、I2C 通信协议对比
题目
以下哪种通信协议支持多主设备仲裁?
A. UART
B. SPI
C. I2C
D. CAN
知识点详解
| 协议 | 类型 | 线数 | 同步 / 异步 | 多主支持 | 典型应用 |
|---|---|---|---|---|---|
| UART | 异步 | 2-3 | 异步 | 不支持 | 串口通信、调试输出 |
| SPI | 同步 | 3-4 | 同步 | 不支持 | 高速外设(如 SD 卡、ADC) |
| I2C | 同步 | 2 | 同步 | 支持 | 低速外设(如传感器、EEPROM) |
- I2C 仲裁机制:
- 多个主设备竞争总线时,通过 “线与” 逻辑仲裁(发送
0的设备获胜)。 - 示例:
// I2C写操作伪代码 void i2c_write(uint8_t addr, uint8_t data) { start_condition(); send_byte(addr << 1 | 0); // 写命令 send_byte(data); stop_condition(); }
- 多个主设备竞争总线时,通过 “线与” 逻辑仲裁(发送
答案与解析
- 正确答案:C
- 解析:I2C 通过总线仲裁支持多主设备。
易错点分析
- 混淆同步 / 异步:
- 错误:认为 SPI 是异步。
- 正确:SPI 需时钟线(同步),UART 无需时钟线(异步)。
- 线数记忆错误:
- 错误:SPI 仅需 2 线。
- 正确:SPI 至少需 3 线(SCLK、MOSI、MISO),片选线可选。
常见用法与拓展
- UART 配置示例:
// STM32 UART初始化(伪代码) USART_InitTypeDef uart; uart.BaudRate = 115200; uart.WordLength = USART_WordLength_8b; uart.StopBits = USART_StopBits_1; uart.Parity = USART_Parity_No; USART_Init(USART1, &uart); - SPI 模式设置:
- CPOL(时钟极性):0(空闲低电平)或 1(空闲高电平)。
- CPHA(时钟相位):0(数据在第一个边沿采样)或 1(数据在第二个边沿采样)。
- I2C 从机地址:
- 7 位地址(如
0x50)+ 读写位(0 = 写,1 = 读)。
- 7 位地址(如
4. RTOS 任务调度策略
题目
RTOS 中 “优先级反转” 的解决方案是?
A. 时间片轮转
B. 优先级继承
C. 动态优先级调整
D. 抢占式调度
知识点详解
- 优先级反转现象:
- 高优先级任务被低优先级任务阻塞,而中优先级任务抢占低优先级任务的 CPU。
- 示例:
- 任务 C(低优先级)持有资源。
- 任务 A(高优先级)请求资源,阻塞。
- 任务 B(中优先级)抢占任务 C,导致任务 A 长时间阻塞。
- 解决方案:
- 优先级继承:任务 C 暂时提升优先级至任务 A 的级别,避免任务 B 抢占。
- 优先级天花板:资源设置最高优先级,任务获取资源时提升优先级至天花板。
答案与解析
- 正确答案:B
- 解析:优先级继承是解决优先级反转的常用方法。
易错点分析
- 误认为抢占式调度能解决:
- 错误:抢占式调度无法解决资源竞争导致的优先级反转。
- 正确:需结合同步机制(如互斥量)和优先级继承。
- 混淆时间片轮转与优先级调度:
- 错误:时间片轮转适用于同优先级任务,与优先级反转无关。
常见用法与拓展
- FreeRTOS 互斥量示例:
// 创建互斥量 SemaphoreHandle_t mutex = xSemaphoreCreateMutex(); // 任务A(高优先级)尝试获取互斥量 if(xSemaphoreTake(mutex, portMAX_DELAY) == pdTRUE) { // 执行临界区代码 xSemaphoreGive(mutex); } - 任务状态转换:
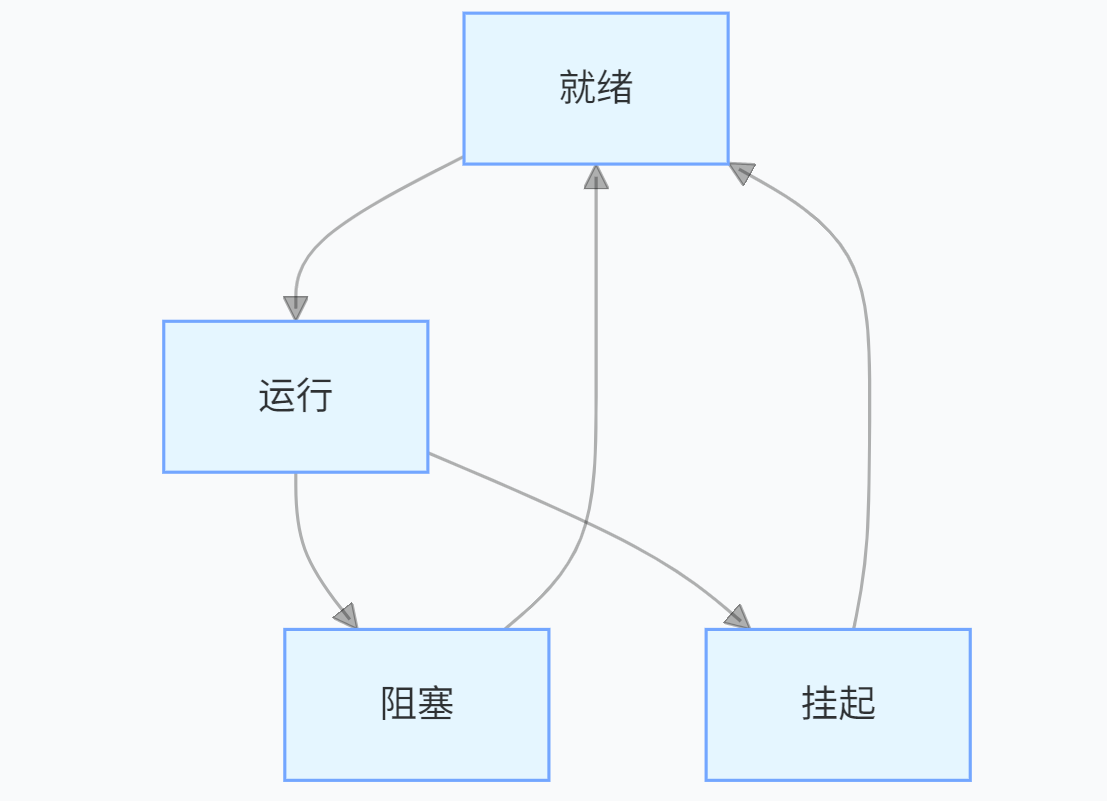
- 中断服务程序(ISR)中的任务唤醒:
// ISR中发送信号量 BaseType_t xHigherPriorityTaskWoken = pdFALSE; xSemaphoreGiveFromISR(mutex, &xHigherPriorityTaskWoken); portYIELD_FROM_ISR(xHigherPriorityTaskWoken);
5. DMA 工作原理与应用
题目
DMA 的主要作用是?
A. 提高 CPU 利用率
B. 增强数据安全性
C. 实现多任务调度
D. 优化内存管理
知识点详解
- 核心原理:
- 直接内存访问:外设通过 DMA 控制器直接与内存通信,无需 CPU 干预。
- 工作流程:
- CPU 配置 DMA 源地址、目标地址、传输长度。
- DMA 控制器发起总线请求,获取控制权后传输数据。
- 传输完成后触发中断通知 CPU。
- 典型场景:
- 高速数据采集:如 ADC 连续采样数据到内存。
- 外设通信:如 UART 接收数据到缓冲区。
答案与解析
- 正确答案:A
- 解析:DMA 减少 CPU 参与,提升其利用率。
易错点分析
- 误认为 DMA 能处理复杂逻辑:
- 错误:DMA 仅传输数据,无法处理数据加工。
- 正确:数据处理仍需 CPU 完成。
- 忽略 DMA 通道配置:
- 错误:未配置 DMA 通道参数(如突发传输模式)导致性能低下。
常见用法与拓展
- STM32 DMA 配置示例:
// 配置DMA1通道1传输USART1数据 DMA_InitTypeDef dma; dma.DMA_PeripheralBaseAddr = (uint32_t)&USART1->DR; dma.DMA_MemoryBaseAddr = (uint32_t)rx_buffer; dma.DMA_DIR = DMA_DIR_PeripheralToMemory; dma.DMA_BufferSize = 1024; DMA_Init(DMA1_Channel1, &dma); DMA_Cmd(DMA1_Channel1, ENABLE); - 循环 DMA 模式:
- 用于连续数据流(如音频采样),传输完成后自动重启。
- DMA 与中断结合:
// DMA传输完成中断处理 void DMA1_Channel1_IRQHandler() { if(DMA_GetITStatus(DMA1_IT_TC1)) { DMA_ClearITPendingBit(DMA1_IT_TC1); // 处理数据 } }
6. 电源管理与低功耗设计
题目
以下哪种技术可降低动态功耗?
A. 关闭未使用的外设时钟
B. 提高 CPU 工作电压
C. 使用低功耗模式
D. 增加外设数量
知识点详解
- 动态功耗:与电路开关活动相关,公式为
P = C × V² × f(C 为电容,V 为电压,f 为频率)。 - 降低方法:
- 时钟门控:关闭未使用模块的时钟。
- 动态电压频率调节(DVFS):根据负载调整电压和频率。
- 低功耗模式:
- Idle 模式:CPU 停止,外设运行。
- Sleep 模式:部分外设关闭。
- Deep Sleep 模式:几乎所有外设关闭。
- 静态功耗:漏电流导致的功耗,可通过电源门控(Power Gating)降低。
答案与解析
- 正确答案:A
- 解析:关闭时钟减少开关活动,降低动态功耗。
易错点分析
- 混淆动态与静态功耗:
- 错误:认为低功耗模式仅降低动态功耗。
- 正确:低功耗模式同时降低动态和静态功耗。
- 未优化电压频率:
- 错误:未使用 DVFS 导致高负载时功耗过高。
常见用法与拓展
- STM32 低功耗模式示例:
// 进入Sleep模式 __WFI(); // Wait For Interrupt // 进入Deep Sleep模式 PWR_EnterSTOPMode(PWR_Regulator_LowPower, PWR_STOPEntry_WFI); - 外设时钟管理:
// 关闭SPI1时钟(STM32) RCC_APB2PeriphClockCmd(RCC_APB2Periph_SPI1, DISABLE); - 功耗测量工具:
- 万用表:测量整机电流。
- 逻辑分析仪:分析外设活动与功耗关系。
7. JTAG 调试技术
题目
JTAG 的主要用途是?
A. 程序下载与调试
B. 网络通信
C. 图形渲染
D. 音频处理
知识点详解
- 核心功能:
- 边界扫描测试:检测 PCB 上芯片引脚连接是否正常。
- 在线编程(ISP):通过 JTAG 接口烧录固件到 Flash。
- 实时调试:单步执行、设置断点、查看寄存器。
- 接口信号:
信号 功能 TMS 测试模式选择 TCK 时钟信号 TDI 测试数据输入 TDO 测试数据输出 TRST# 复位信号(可选)
答案与解析
- 正确答案:A
- 解析:JTAG 主要用于程序下载与调试。
易错点分析
- 误认为仅用于测试:
- 错误:JTAG 不仅用于测试,还用于调试和编程。
- 正确:JTAG 是多功能接口。
- 忽略安全风险:
- 错误:未禁用 JTAG 接口导致固件被逆向。
- 正确:量产时应关闭 JTAG,仅保留 SWD(节省引脚)。
常见用法与拓展
- OpenOCD 配置示例:
# 连接JTAG适配器 interface ftdi ftdi_vid_pid 0x0403 0x6010 # 配置目标芯片 source [find target/stm32f1x.cfg] # 启动调试 init halt - JTAG 与 SWD 对比:
- JTAG:4-5 线,兼容性强。
- SWD:2 线,节省引脚,速度更快。
8. Makefile 基础
题目
以下 Makefile 语法正确的是?
A. target: dependency; command
B. target: dependency\n\tcommand
C. target: dependency \
D. target: dependency \n\tcommand
知识点详解
- 基本结构:
target: dependency1 dependency2 command1 command2 - 变量与函数:
$(VAR):引用变量。$@:当前目标。$<:第一个依赖。$(wildcard *.c):获取所有.c文件。
- 条件编译:
ifeq ($(DEBUG), 1) CFLAGS += -g endif
答案与解析
- 正确答案:D
- 解析:依赖后换行,命令需以 Tab 缩进。
易错点分析
- 命令未用 Tab 缩进:
- 错误:使用空格导致语法错误。
- 正确:必须使用 Tab。
- 多行依赖未正确换行:
- 错误:未用反斜杠
\换行。 - 正确:依赖多行时需用
\连接。
- 错误:未用反斜杠
常见用法与拓展
- 简单 Makefile 示例:
CC = gcc CFLAGS = -Wall -O2 SRC = main.c utils.c OBJ = $(SRC:.c=.o) target: $(OBJ) $(CC) $(CFLAGS) -o target $(OBJ) clean: rm -f target $(OBJ) - 自动生成依赖:
include $(wildcard *.d) %.d: %.c $(CC) -MM $< > $@
9. 嵌入式 C 与标准 C 的区别
题目
以下哪项是嵌入式 C 特有的语法?
A. 结构体
B. 联合体
C. 位域
D. 枚举
知识点详解
| 特性 | 嵌入式 C | 标准 C |
|---|---|---|
| 寄存器操作 | 支持指针强制类型转换 | 无相关特性 |
| 位域 | 用于硬件寄存器位控制 | 标准 C 支持,但应用较少 |
| 内存对齐 | 严格控制(如__packed) | 依赖编译器默认设置 |
| 中断服务程序 | 特定关键字(如__irq) | 无相关特性 |
- 位域示例:
struct GPIO { uint32_t pin0 : 1; // 1位 uint32_t pin1 : 1; uint32_t reserved : 30; };
答案与解析
- 正确答案:C
- 解析:位域是嵌入式 C 常用的硬件寄存器控制方法。
易错点分析
- 误认为联合体是嵌入式特有:
- 错误:联合体是标准 C 特性。
- 正确:联合体在嵌入式中常用于数据解析。
- 忽略寄存器操作的安全性:
- 错误:直接操作指针可能导致硬件故障。
- 正确:应通过宏定义或封装函数操作寄存器。
常见用法与拓展
- 寄存器映射示例:
#define RCC_BASE 0x40021000 typedef struct { volatile uint32_t CR; volatile uint32_t CFGR; // ...其他寄存器 } RCC_TypeDef; #define RCC ((RCC_TypeDef *)RCC_BASE) // 使用示例 RCC->CR |= RCC_CR_HSEON; // 使能外部高速时钟 - 中断服务程序声明:
// GCC编译器 void __attribute__((interrupt("IRQ"))) USART1_IRQHandler() { // 中断处理代码 }
总结
通过以上补充的嵌入式常见面试题,新手可全面覆盖以下核心领域:
- 内存管理:结构体对齐、
volatile关键字。 - 通信协议:UART、SPI、I2C 的原理与应用。
- 实时操作系统:任务调度、优先级反转。
- 硬件加速:DMA 的工作原理与配置。
- 低功耗设计:电源管理、睡眠模式。
- 开发工具:JTAG 调试、Makefile 编写。
- 编程语言:嵌入式 C 的特有语法与优化。
建议结合实际项目练习,例如:
- 使用
volatile实现中断标志位。 - 编写 I2C 驱动程序与传感器通信。
- 配置 DMA 实现高速数据传输。
- 通过 JTAG 调试工具定位代码问题。
通过理论与实践结合,可快速提升嵌入式面试竞争力。
通过以上题目与知识点的学习,新手可系统掌握嵌入式基础概念。实际学习中,要多结合代码示例与硬件场景深入理解,关注易错点,逐步积累知识,为嵌入式面试与开发夯实基础。