【论文笔记】ViT-CoMer
【题目】:ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions
【引用格式】:Xia C, Wang X, Lv F, et al. Vit-comer: Vision transformer with convolutional multi-scale feature interaction for dense predictions[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2024: 5493-5502.
【网址】:https://openaccess.thecvf.com/content/CVPR2024/papers/Xia_ViT-CoMer_Vision_Transformer_with_Convolutional_Multi-scale_Feature_Interaction_for_Dense_CVPR_2024_paper.pdf
【开源代码】:https: //github.com/Traffic-X/ViT-CoMer
目录
一、瓶颈问题
二、本文贡献
三、解决方案
1. 总体架构
2. 多感受野特征金字塔
3. CNN与Transformer双向融合交互
四、实验结果
1. 目标检测和实例分割
1.1 实验设置
1.2 与不同骨干网络和框架的比较
1.3 不同预训练权重下的结果
1.4 与最先进方法的比较
2. 语义分割
2.1 实验设置
2.2 与不同骨干网络比较
2.3 与不同预训练权重的比较
2.4 与最先进方法比较
3. 消融实验
3.1 实验设置
3.2 组件消融实验
3.3 双向融合交互的数量
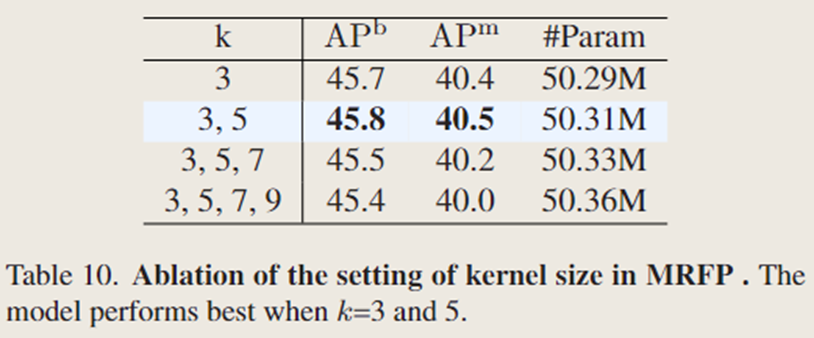
3.4 MRFP中不同卷积核大小
3.5 可扩展性
3.6 定性结果
一、瓶颈问题
- ViT 结构自身缺陷:ViT 存在 Patch 内信息交互不足以及缺乏分层特征的问题,导致其在捕捉图像多尺度信息、长距离依赖关系和语义表示能力上存在局限性,难以有效处理密集预测任务。
- 跨架构特征融合难题:CNN 和 Transformer 架构由于设计原理不同,在特征表示上存在显著差异(如高低频语义、全局 - 局部信息等方面的偏差),使得两者特征难以有效融合,无法充分发挥各自优势。
- 传统 Transformer 特征利用不充分:传统 Transformer 架构仅在单一尺度特征上使用自注意力机制,无法充分利用图像中丰富的多尺度信息,限制了模型在密集预测任务中的性能表现。
- 模型泛化与性能提升瓶颈:在密集预测任务(如目标检测、实例分割和语义分割)中,现有基于 ViT 的方法或特定视觉骨干网络,在模型性能、泛化能力以及对不同预训练策略的适应性方面存在提升瓶颈,难以在各类任务和数据集上取得更优表现 。
二、本文贡献
- 创新跨架构融合机制:提出新的融合策略,通过自注意力机制统一 CNN 与 Transformer 特征,增强特征对模态差异的不变性,并利用双向交互更新 ViT 和 CNN 分支特征,有效解决了不同架构特征融合的难题,提升了模型对多尺度、多层次信息的利用能力。
- 优化多尺度特征处理:改进传统 Transformer 单一尺度特征处理的局限,促使模型更好地捕捉图像多尺度信息,增强了模型在密集预测任务中的特征表达能力。
- 良好的可扩展性与适应性:方法可轻松集成到其他先进模型,在不同模型规模、算法框架和配置下均表现出色;对不同预训练权重具有良好适应性,能利用多样化的开源大规模预训练提升下游任务性能;应用于分层视觉 Transformer(如 Swin)时也能有效提升模型性能,证明了方法的可扩展性。
三、解决方案
1. 总体架构
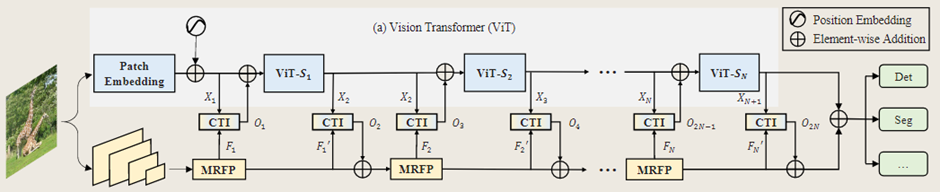
分支特征提取:
ViT-CoMer架构包含两个分支。对于ViT分支,将形状为(H×W×3)的输入图像送入补丁嵌入(patch embedding),得到分辨率为原始图像( 1 / 16 )的特征。对于另一分支,图像通过一组卷积操作,获得分辨率分别为( 1 / 8 )、( 1 / 16 ) 和( 1 / 32 )的特征金字塔C3、C4和C5,每个特征金字塔都包含D维特征图。
特征交互:
两个分支的特征都要经过N个阶段的特征交互。在每个阶段,特征金字塔首先通过 MRFP 模块进行增强,然后通过 CTI 模块与 ViT 的特征进行双向交互,以获得具有丰富语义信息的多尺度特征。CTI 在每个阶段的开始和结束时进行操作。经过N个阶段的特征交互后,将两个分支在每个尺度上的特征相加,用于密集预测任务。
2. 多感受野特征金字塔
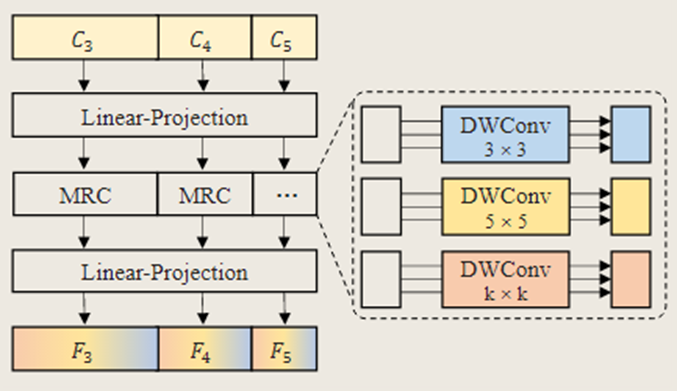
多感受野特征金字塔模块由一个特征金字塔和多感受野卷积层组成。【特征金字塔可以提供丰富的多尺度信息,适应图像中不同大小目标和结构的表征需求。而多感受野卷积层则通过不同的卷积核来扩大感受野,增强了卷积神经网络(CNN)特征的长距离建模能力】。
多感受野特征金字塔由两个线性投影层和一组具有多感受野的深度可分离卷积层组成。该模块的输入是一组多尺度特征{C3,C4,C5},文中将这些特征展平并连接成特征。C首先通过一个线性投影层来获得降维后的特征,然后在通道维度上把这些特征划分为M组;不同组的特征对应具有不同感受野的卷积层(例如卷积核大小k=3x3、5x5)。最后,经过处理的特征被连接起来,通过线性投影层进行升维。这个过程可表示为:
F = FC(DWConv(FC(C)))
- FC:线性投影
- DWConv:具有不同大小卷积核的深度可分离卷积
3. CNN与Transformer双向融合交互
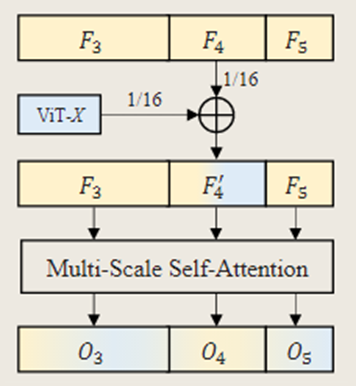
文中提出了一种名为CTI的跨架构特征融合方法,它在不改变 ViT 结构的情况下引入了 CNN 的多尺度特征。同时,通过双向交互,缓解了 ViT 中存在的 Patch 内信息交互不足和非分层特征的问题,同时进一步增强了 CNN 的长距离建模能力和语义表示能力。
文中为了融合ViT特征和通过MRFP模块获得的多尺度特征{F3,F4,F5}(可表示为
),文中直接将特征 X 和 F4 相加,得到集合 F’,表示为F' = {F3,F4',F5},其聚合了来自不同尺度的特征。之后,由于架构差异,它们在台表示上存在偏差(高低频语义以及全局 - 局部信息),文中增加自注意力机制来统一CNN和Transformer的特征【由于F’包含了不同尺寸的信息,通过自注意力机制可以有效解决传统Transformer在单一尺寸上使用自注意力机制的问题】,增强对模态差异的表示不变性,可描述为:
O=FFN(Attention(norm(F')))
- Norm(-):层归一化(LayerNorm)
- Attention():多尺度可变形注意力机制
- FFN():前馈神经网络
最后,通过双线性差值将O3和O5的特征图尺寸调整为与O4一致,并将X作为下一个ViT层的输入。
对于跨架构融合的特征,文中采用双向交互来更新ViT和CNN分支的特征。具体来说,在第i阶段开始时,将两个分支的特征进行融合,然后将融合后的特征注入到ViT分支中,可表示为:
:ViT分支更新后的特征
- α:一个初始化为零的可学习变量,能够在早期训练中最小化随机初始化的CNN架构对ViT的影响
在第 i 阶段结束时,重复该过程将特征注入到CNN分支,可表示为:
:卷积神经网络(CNN)分支更新后的特征
- i:根据ViT的深度来确定
跨架构的特征融合和双向交互使得能够利用多尺度和多层次的特征,提升了模型的表达能力和泛化能力。同时,所提出的组件能够轻松集成到其他先进的模型中,并在密集预测任务中表现得更好。
四、实验结果
1. 目标检测和实例分割
1.1 实验设置
文中利用MMDetection框架来实现文中方案,并在COCO数据集上进行目标检测和实例分割实验。目标检测和实例分割框架包括掩码区域卷积神经网络(Mask R-CNN)、级联掩码区域卷积神经网络(Cascade Mask R-CNN)、自适应训练样本选择算法(ATSS)和 Generalized Focal Loss(GFL)。参考金字塔Vision Transformer(PVT),文中按照 1 倍(12 个训练轮次)或 3 倍(36 个训练轮次)的训练计划进行实验。文中的总批量大小为 16,使用 AdamW 优化器,学习率为1 × 10⁻⁴ ,权重衰减为 0.05。
1.2 与不同骨干网络和框架的比较
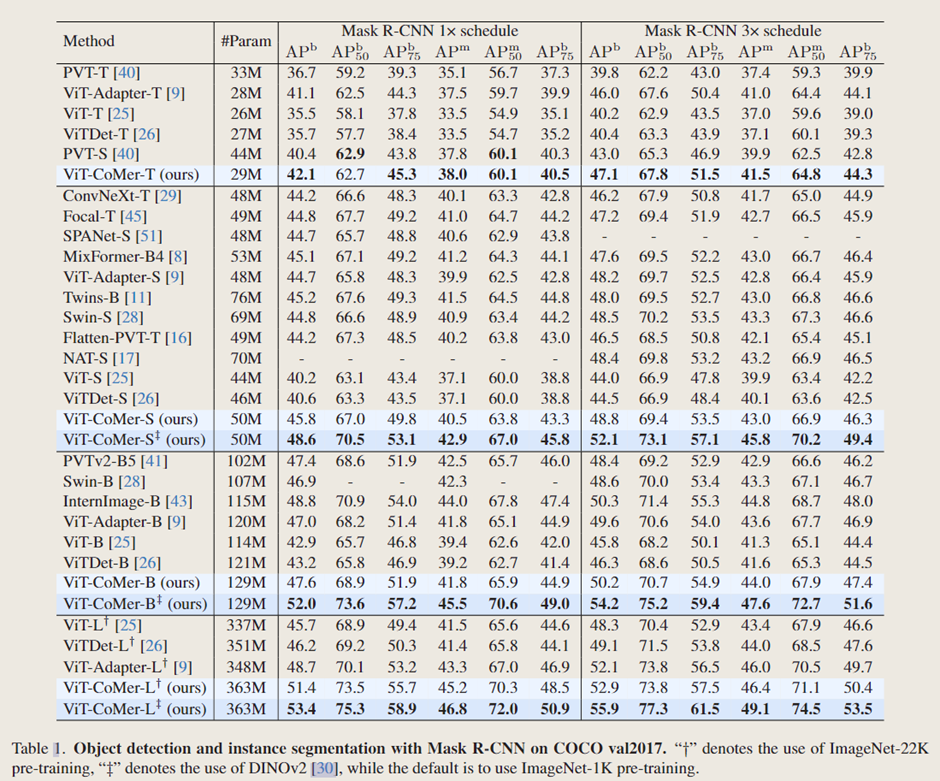
在模型规模相近的情况下,ViT-CoMer 在 COCO 目标检测和实例分割这两项典型的密集预测任务中,性能优于其他骨干网络。例如,在 1 倍(3 倍)训练计划下,ViT-CoMer-S 相比于普通 ViT-S,边界框平均精度均值(box mAP)显著提升了 + 5.6%(+4.8%),掩码平均精度均值(mask mAP)提升了 + 3.4%(+3.1%)。此外,ViT-CoMer-S 在仅使用 ViT-L 六分之一参数的情况下,检测结果优于 ViT-L。而且,文中的方法相较于特定视觉骨干网络以及适配骨干网络,如 InternImage 和 ViT-Adapter ,也展现出了显著的性能提升。
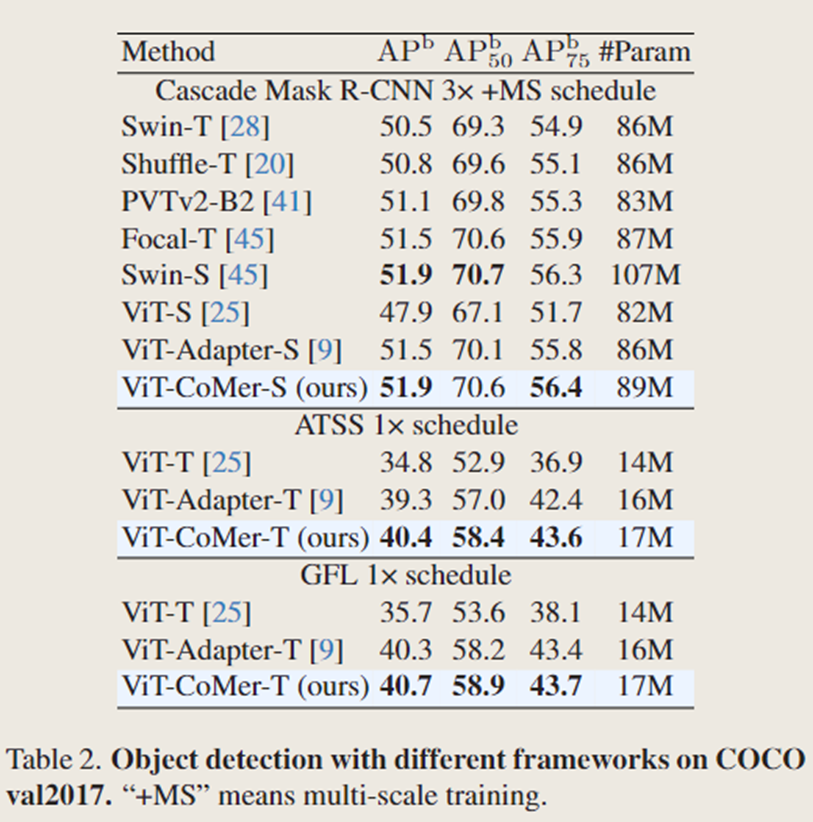
使用不同的检测框架对 ViT-CoMer 进行评估,在各种框架、模型规模和配置下,文中的方法始终优于其他骨干网络。
1.3 不同预训练权重下的结果
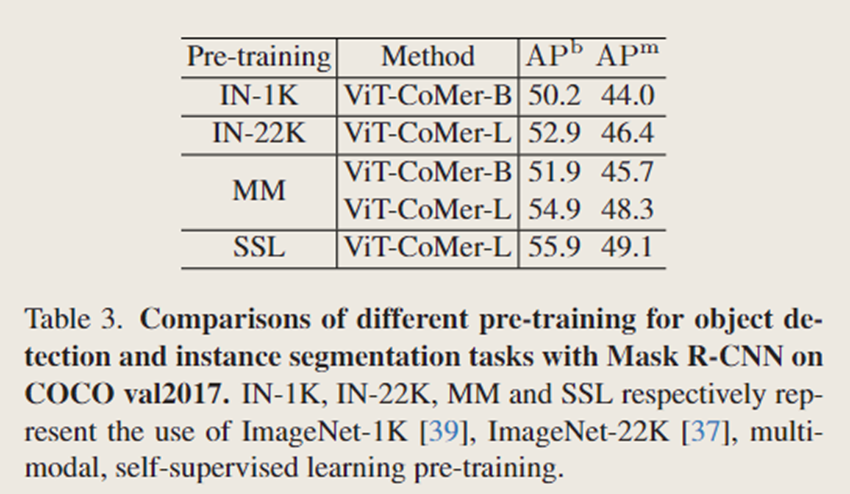
经过多模态预训练的 ViT-CoMer-B 与在 ImageNet-1K 上预训练的模型相比,在边界框平均精度(APb)上提升了(+1.7%),在掩码平均精度(APm)上提升了(+1.7%) 。此外,文中在 ViT-CoMer-L 上比较了更多的预训练方式,其中自监督预训练取得了显著的成果。与在 ImageNet-22K上预训练的模型相比,它在边界框平均精度(APb)上提升了(+3.0%),在掩码平均精度(APm)上提升了(+2.7%) 。
1.4 与最先进方法的比较
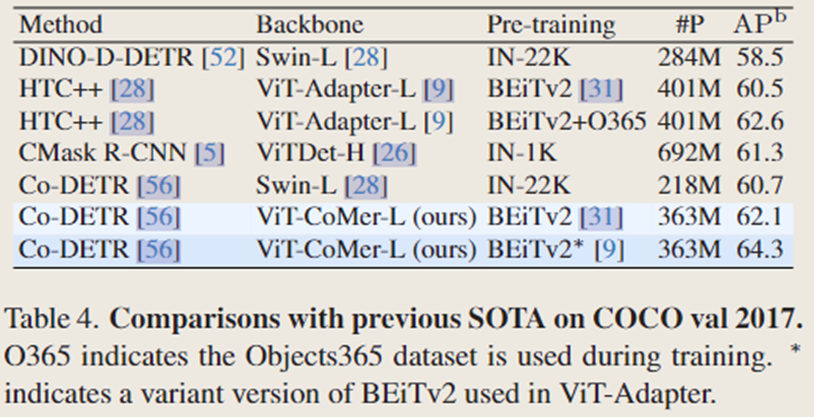
2. 语义分割
2.1 实验设置
语义分割实验基于使用了 MMSegmentation 的 ADE20K 数据集。文中选择 UperNet 作为基础框架。训练配置与 Swin 保持一致,包括进行 160,000 次迭代训练。批量大小设置为 16,使用 AdamW 优化器。学习率和权重衰减参数分别调整为(2 × 10⁻⁵) 和 0.05。
2.2 与不同骨干网络比较
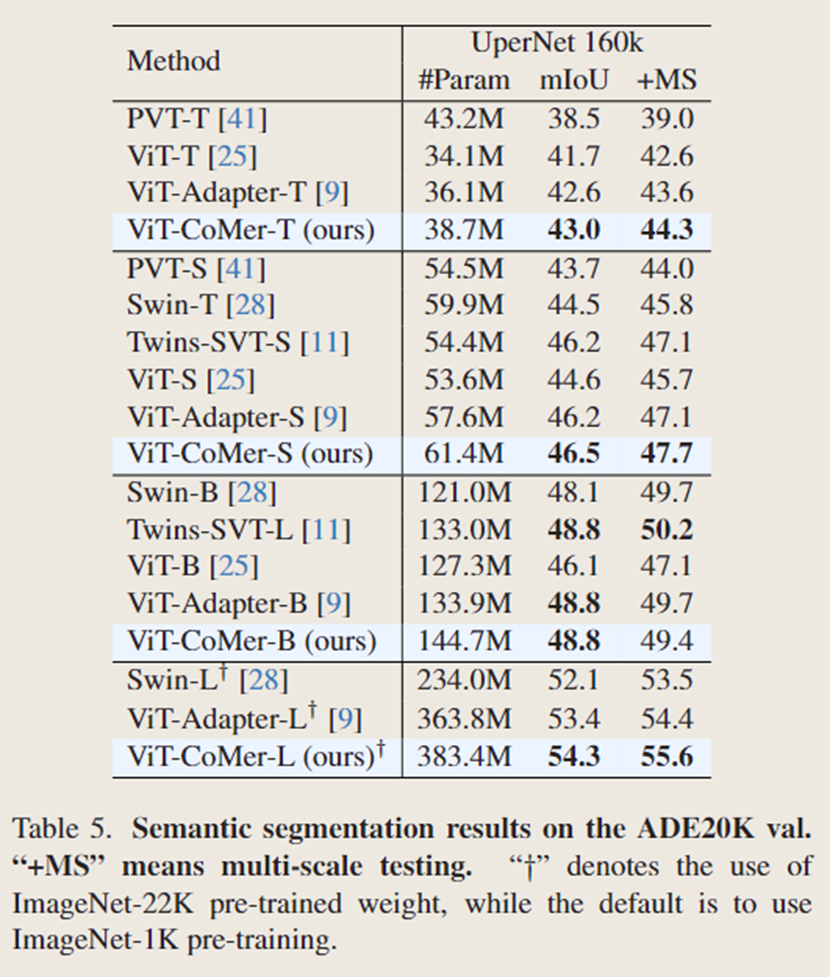
ViT-CoMer-S 在多尺度平均交并比(MS mIoU)上达到了 47.7%,超过了许多强大的同类方法,比如 Swin-T(高出 1.9%)和 ViTAdapter-S(高出 0.6%)。同样,ViT-CoMer-L 取得了具有竞争力的多尺度平均交并比(MS mIoU)成绩,达到了 55.6%,比 Swin-L 高出 2.1%,比 ViT-Adapter-L 高出 1.2%。
2.3 与不同预训练权重的比较
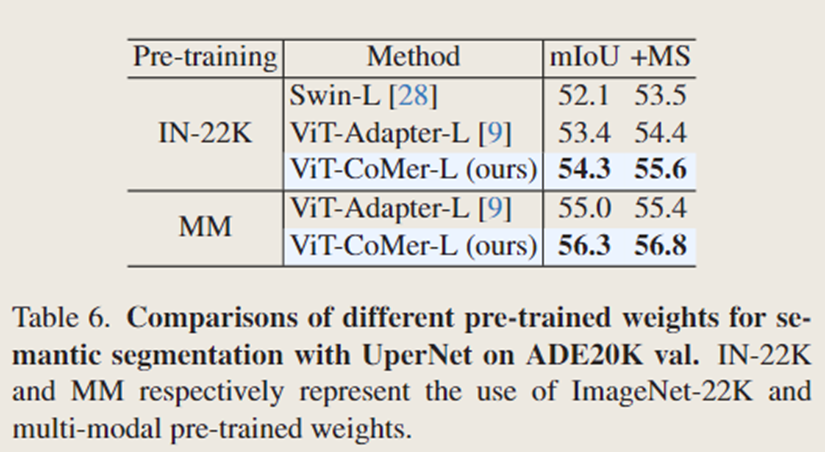
当使用 ImageNet-22K 预训练权重时,文中的 ViT-CoMer-L 在多尺度平均交并比(MS mIoU)上达到 55.6%,比 ViT-Adapter-L 的平均交并比(mIoU)高出 1.2%。然后,文中使用多模态预训练来初始化 ViT-CoMer-L,这使文中的模型在平均交并比(mIoU)上显著提升了 2.0%,比 ViT-Adapter-L 高出 1.4%。
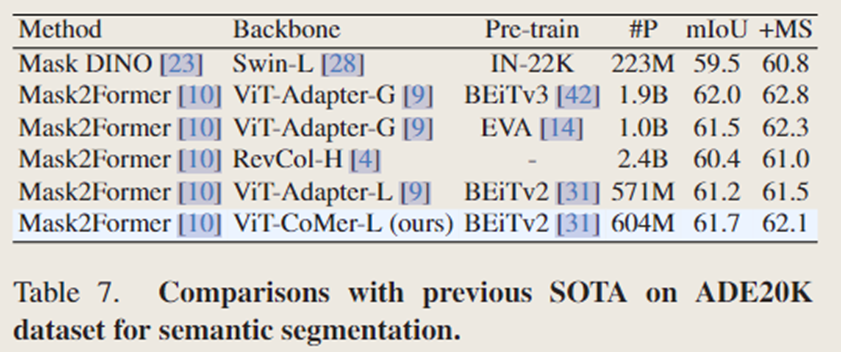
2.4 与最先进方法比较
3. 消融实验
3.1 实验设置
文中对 ViT-CoMer-S 进行消融实验,使用掩码区域卷积神经网络(Mask R-CNN)(1 倍训练计划)来执行目标检测和实例分割任务。在训练过程中使用的总批量大小为 16,所采用的优化器是 AdamW,学习率和权重衰减参数分别设置为1 × 10⁻⁴ 和 0.05。
3.2 组件消融实验
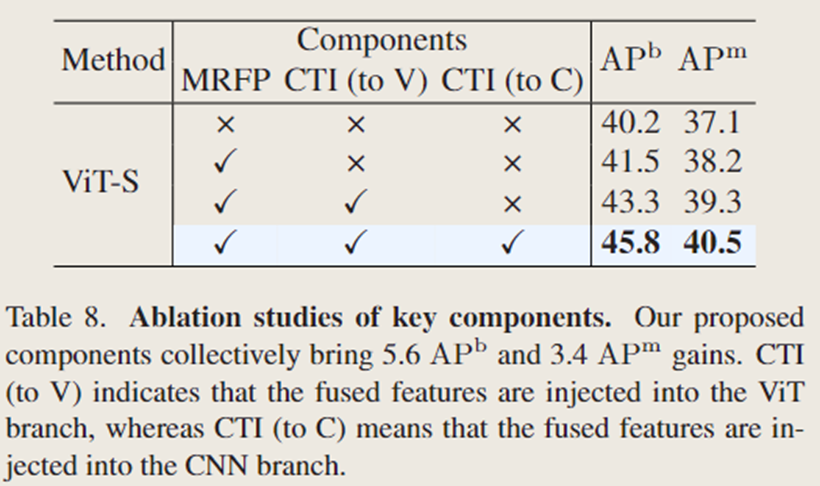
当使用多感受野特征金字塔(MRFP)向普通 ViT 提供卷积神经网络(CNN)的多尺度和多感受野特征时(特征直接相加),边界框平均精度(APb)提高了(1.3%),掩码平均精度(APm)提高了(1.1%)。此外,用本文提出的卷积神经网络 - Transformer 双向融合交互模块(CTI)替换 “直接相加” 操作。当仅使用 CTI(作用于 ViT 分支,即 CTI (to V))时,模型的边界框平均精度(APb)提高了(1.8%),掩码平均精度(APm)提高了(1.1%);当同时使用 CTI(作用于 ViT 分支)和 CTI(作用于 CNN 分支,即 CTI (to C))时,性能进一步显著提升,边界框平均精度(APb)提高了(2.5%),掩码平均精度(APm)提高了(1.2%) 。总体而言,与普通 ViT 相比,文中的 ViT-CoMer 在边界框平均精度(APb)上显著提高了(5.6%),在掩码平均精度(APm)上提高了(3.4%)。
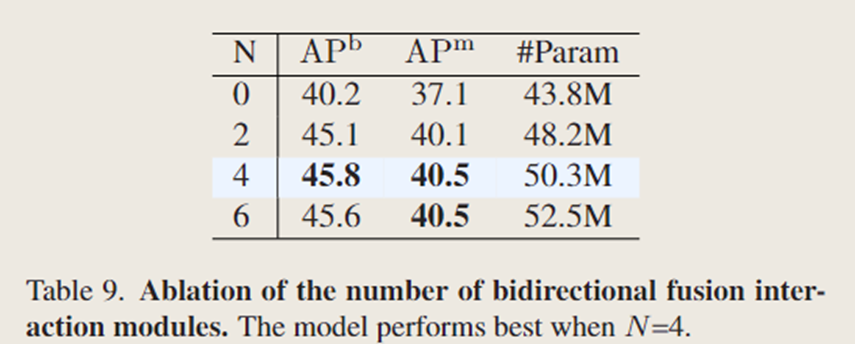
3.3 双向融合交互的数量
3.4 MRFP中不同卷积核大小
3.5 可扩展性
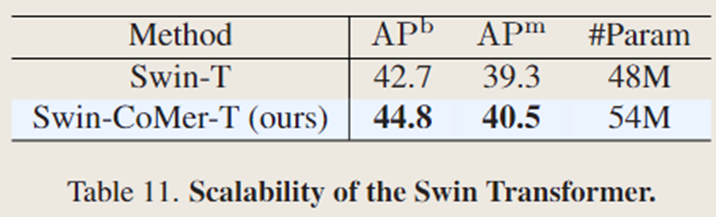
文中的方法也可以应用于诸如 Swin 之类的分层视觉 Transformer。文中的方法使 Swin-T 的边界框平均精度(box AP)提升了(+2.1%),掩码平均精度(mask AP)提升了(+1.2%)。由于 Swin 架构已经引入了归纳偏置,与普通的 ViT 相比,性能提升幅度略低。
3.6 定性结果

根据 iFormer,普通的视觉 Transformer(ViT)由于自注意力操作,倾向于捕获图像中的全局和低频特征,而卷积神经网络(CNN)由于卷积操作,倾向于捕获图像中的局部和高频特征。然而,在密集预测任务中,图像中会出现不同大小和密度的各种物体,这要求模型具备同时提取和捕获局部与全局、高频与低频特征的能力。文中通过可视化不同层(下采样率为 1/4、1/8、1/16 和 1/32)的特征图,对普通 ViT 和文中提出的 ViT-CoMer 在实例分割和目标检测任务中的差异进行了定性评估。如图可以看出,与普通 ViT 相比,文中的 ViT-CoMer 生成了更细粒度的多尺度特征,从而增强了模型的目标定位能力。