LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
一、引言
在自然语言处理领域,大规模预训练语言模型(LLMs)展现出强大的语言理解和生成能力。然而,将这些模型适配到多个下游任务时,传统微调方法面临诸多挑战。LoRA(Low-Rank Adaptation of Large Language Models)作为一种创新的微调技术,旨在解决这些问题,为大语言模型的高效应用提供新的思路和方法。
二、背景与问题
许多自然语言处理应用需要将大规模预训练语言模型适配到不同的下游任务。传统的微调方法需要更新模型的所有参数,这对于像 GPT-3(175B)这样的大参数模型来说,训练参数规模极其庞大,不仅增加了训练成本,还可能导致过拟合等问题。此外,模型适配过程中的计算资源需求和时间成本也成为实际应用中的阻碍。
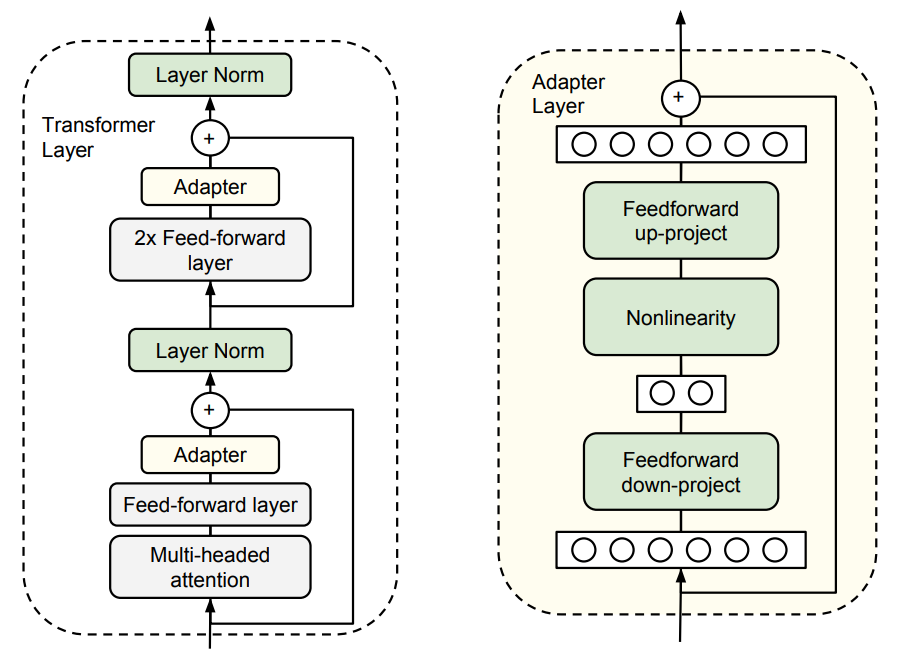
三、现有方法局限
3.1 Adapter Layers
Adapter Layers 方法通过在模型中插入额外的适配器层来减少参数更新量。然而,这种方法会引入推理延迟。以 GPT2 medium 在单 GPU 推理为例,