RuoYi 中使用 PageUtils.startPage() 实现分页查询的完整解析
文章目录
- 一、PageHelper 简介与基本用法
- 使用方式如下:
- 二、Mapper 接口返回类型对分页的影响
- 1. 返回 `Page<T>` 类型(推荐)
- 2. 返回 `List<T>` 类型(不推荐)
- 三、解析RuoYi 是如何使用 PageUtils.startPage()
- 1、简要回答:
- 2、 详细解析
- 1. RuoYi 中典型的 Controller 分页代码结构如下:
- 2. PageHelper 是如何工作的?
- (1)PageHelper 使用 ThreadLocal 存储分页参数
- (2)执行 SQL 查询时拦截并生成分页语句
- (3)使用 PageInfo 获取 total
- 3、 所以你看到的流程是这样的:
- 4、 总结:为什么返回 List<T> 还能分页?
- 5、注意事项
- 6、推荐做法(适用于复杂业务)
- 7、结论一句话:
- 三、Service 层中的常见错误:new ArrayList<>() 导致分页信息丢失
- 1、错误写法示例:
- 2、正确做法:
- 四、XML 文件中是否需要特殊设置?
- 五、TableDataInfo 标准返回格式定义
- 六、最佳实践总结
- 七、结语
在基于 RuoYi 框架开发过程中,我们经常需要实现分页查询功能。RuoYi 默认集成的是 MyBatis 分页插件 PageHelper,它通过拦截 SQL 查询语句,自动添加分页逻辑并封装结果,从而简化分页操作。
然而,在实际开发中,如果不理解其内部机制或处理不当,很容易导致分页信息丢失,尤其是最核心的 total(总记录数)无法返回给前端。
本文将从原理出发,结合实际代码示例,深入分析 PageHelper 的工作方式,并指出一个常见的错误用法:Service 层中使用 new ArrayList<>() 造成分页信息丢失的问题。
一、PageHelper 简介与基本用法
PageHelper 是一个为 MyBatis 提供分页功能的第三方插件。它通过 ThreadLocal 存储当前线程的分页参数,并在执行下一条查询语句时动态生成带 LIMIT 的 SQL,同时生成统计总数的 SQL。
使用方式如下:
// Controller 中调用
PageUtils.startPage(); // 内部调用 PageHelper.startPage(pageNum, pageSize)
List<AccountInfo> list = accountInfoMapper.selectAccountInfoList(request);
return getDataTable(list);
其中:
startPage()方法会从请求参数中提取当前页码和每页大小;accountInfoMapper.selectAccountInfoList()执行数据库查询;getDataTable()将查询结果封装成TableDataInfo返回给前端。
二、Mapper 接口返回类型对分页的影响
这是关键所在。
1. 返回 Page<T> 类型(推荐)
@Mapper
public interface AccountInfoMapper {Page<AccountInfo> selectAccountInfoList(AccountInfoRequest request);
}
此时,查询结果是一个 Page<T> 类型对象,它是 ArrayList<T> 的子类,扩展了以下属性:
pageNum:当前页码;pageSize:每页大小;total:总记录数;pages:总页数;hasPreviousPage/hasNextPage:是否包含上一页/下一页。
因此,你可以直接获取到这些信息,用于构建标准分页响应。
2. 返回 List<T> 类型(不推荐)
@Mapper
public interface AccountInfoMapper {List<AccountInfo> selectAccountInfoList(AccountInfoRequest request);
}
虽然底层确实执行了分页查询,但返回值被强转为 List<T>,导致所有的分页元数据(如 total)都被丢弃。
即使你在 Service 层遍历后重新封装为新的 List<T>,也无法再恢复分页信息。
三、解析RuoYi 是如何使用 PageUtils.startPage()
但是纵观ruoyi框架,他在mapper层返回的就是list,代码如下:
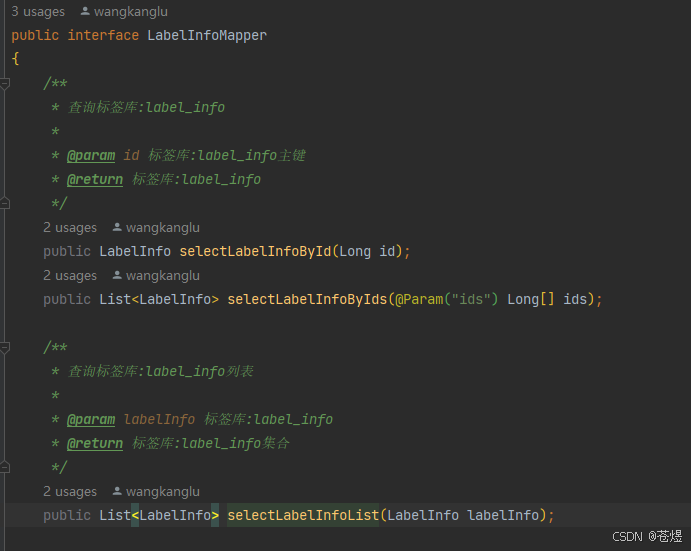
但是还是可以分页的,这是为啥
1、简要回答:
虽然 Mapper 返回的是
List<T>,但由于 PageHelper 的内部机制和 RuoYi 的封装设计,仍然可以获取到分页信息(如 total)。
但这并不是因为 List<T> 本身携带了分页信息,而是因为:
- PageHelper 在执行查询前设置了分页上下文;
- 查询后通过 ThreadLocal 缓存了分页结果;
- 最终通过
PageInfo或其他工具类从缓存中取出total。
2、 详细解析
1. RuoYi 中典型的 Controller 分页代码结构如下:
@GetMapping("/list")
public TableDataInfo list(ActiveDiscoveryRequest request) {startPage(); // 开启分页List<ActiveDiscovery> list = activeDiscoveryService.selectActiveDiscoveryList(request);return getDataTable(list);
}
其中:
startPage():调用PageHelper.startPage(pageNum, pageSize);selectActiveDiscoveryList():Mapper 方法返回的是List<T>;getDataTable(list):构造并返回TableDataInfo。
2. PageHelper 是如何工作的?
(1)PageHelper 使用 ThreadLocal 存储分页参数
当你调用:
PageUtils.startPage();
它内部会调用:
PageHelper.startPage(pageNum, pageSize);
此时 PageHelper 将当前线程的分页参数保存到 ThreadLocal 中。
(2)执行 SQL 查询时拦截并生成分页语句
当执行下一条查询语句时,PageHelper 会:
- 自动将 SQL 改写为带
LIMIT的语句; - 同时生成一条统计总数的 SQL;
- 执行完成后将结果返回为
List<T>; - 但同时也会把分页信息(如 total)缓存在 ThreadLocal 中。
(3)使用 PageInfo 获取 total
RuoYi 中通常有一个 BaseController.getDataTable() 方法,类似如下:
protected TableDataInfo getDataTable(List<?> list) {TableDataInfo rspData = new TableDataInfo();rspData.setRows(list);rspData.setTotal(new PageInfo<>(list).getTotal());return rspData;
}
这里的关键是:
new PageInfo<>(list).getTotal()
这个 PageInfo 是通过反射访问 ThreadLocal 中缓存的分页信息来获取 total 的。
3、 所以你看到的流程是这样的:
startPage() → 设置 ThreadLocal 分页参数
↓
执行 Mapper 查询 → 返回 List<T>
↓
new PageInfo<>(list) → 通过 ThreadLocal 获取 total
↓
构造 TableDataInfo 并返回给前端
4、 总结:为什么返回 List 还能分页?
| 原因 | 说明 |
|---|---|
| PageHelper 的 ThreadLocal 缓存机制 | 即使返回的是 List,分页信息仍被缓存 |
| PageInfo 工具类自动读取缓存 | 能正确获取 total、pageNum、pageSize 等信息 |
| RuoYi 的封装设计 | 提供了统一的 getDataTable() 方法简化分页返回 |
5、注意事项
虽然这种方式在 RuoYi 中可以正常工作,但有以下几点需要注意:
| 问题 | 风险 |
|---|---|
| 多次查询干扰 | 如果一次请求中多次调用了分页查询,ThreadLocal 中的数据可能会被覆盖或混淆 |
| 异步线程丢失上下文 | 如果分页查询发生在子线程中,ThreadLocal 数据不会自动传递 |
| PageInfo 依赖反射 | 性能略低于直接使用 Page |
| 不适用于复杂场景 | 如需处理多个分页结果、自定义分页逻辑时,推荐使用 Page |
6、推荐做法(适用于复杂业务)
如果你需要更清晰、可控的分页逻辑,建议:
@Mapper
public interface ActiveDiscoveryMapper {Page<ActiveDiscovery> selectActiveDiscoveryList(ActiveDiscoveryRequest request);
}
然后在 Service 层:
Page<ActiveDiscovery> page = activeDiscoveryMapper.selectActiveDiscoveryList(request);
TableDataInfo dataTable = new TableDataInfo();
dataTable.setRows(page);
dataTable.setTotal(page.getTotal());
return dataTable;
这样可以避免对 ThreadLocal 和 PageInfo 的依赖,逻辑更清晰。
7、结论一句话:
虽然 Mapper 返回的是 List,但在 RuoYi 中借助 PageHelper 的 ThreadLocal 缓存 + PageInfo 工具类,仍然可以正确获取 total 字段并实现分页功能。
这是 RuoYi 框架的一个巧妙封装设计,但也存在一定局限性,适合简单场景。对于复杂业务,建议使用 Page<T> 显式保留分页信息。
三、Service 层中的常见错误:new ArrayList<>() 导致分页信息丢失
这是本篇文章的重点部分。
1、错误写法示例:
@Override
public List<AccountInfoRespone> selectAccountInfoList(AccountInfoRequest request) {List<AccountInfoRespone> respList = new ArrayList<>();List<AccountInfo> accountInfos = accountInfoMapper.selectAccountInfoList(request);for (AccountInfo info : accountInfos) {//这里对数据进行处理AccountInfoRespone vo = dataFormat(info);respList.add(vo);}return respList;
}
在这个例子中:
accountInfos是由 Mapper 返回的List<T>;- 虽然底层确实是分页查询的结果,但由于没有保留原始的
Page<T>对象; - 最终返回的是一个新的
ArrayList<>(),分页信息完全丢失; - 前端无法知道总共有多少条记录,也就无法正常显示分页控件。
2、正确做法:
应在 Service 层中保持 Page<T> 类型,并在此基础上进行 VO 转换。
@Override
public TableDataInfo selectAccountInfoList(AccountInfoRequest request) {Page<AccountInfo> accountInfoPage = accountInfoMapper.selectAccountInfoList(request);List<AccountInfoRespone> respList = new ArrayList<>();for (AccountInfo info : accountInfoPage) {AccountInfoRespone vo = dataFormat(info);respList.add(vo);}TableDataInfo dataTable = new TableDataInfo();dataTable.setRows(respList);dataTable.setTotal(accountInfoPage.getTotal());return dataTable;
}
或者使用ruoyi的框架原理,使用new PageInfo
@Override
public TableDataInfo selectAccountInfoList(AccountInfoRequest request) {Page<AccountInfo> accountInfoPage = accountInfoMapper.selectAccountInfoList(request);long total = new PageInfo(accountInfoPage).getTotal();List<AccountInfoRespone> respList = new ArrayList<>();for (AccountInfo info : accountInfoPage) {AccountInfoRespone vo = dataFormat(info);respList.add(vo);}TableDataInfo rspData = new TableDataInfo();rspData.setCode(HttpStatus.SUCCESS);rspData.setRows(respList );rspData.setMsg("查询成功");rspData.setTotal(total);return dataTable;
}
这样可以确保:
- 数据转换完成;
- 分页信息(如
total)未丢失; - 返回给前端的结构是完整的。
四、XML 文件中是否需要特殊设置?
不需要!
即使你的 XML 文件中 SQL 写法如下:
<select id="selectAccountInfoList" parameterType="com.example.dto.AccountInfoRequest" resultType="com.example.entity.AccountInfo">SELECT * FROM account_info<where><if test="delFlag != null"> AND del_flag = #{delFlag} </if></where>
</select>
只要接口方法返回的是 Page<T> 类型,PageHelper 会在运行时自动拦截该 SQL,生成两条语句:
- 统计总数:
SELECT COUNT(*) FROM account_info WHERE ... - 分页查询:
SELECT * FROM account_info WHERE ... LIMIT pageNum, pageSize
因此,SQL 无需任何修改,只需关注业务逻辑即可。
五、TableDataInfo 标准返回格式定义
public class TableDataInfo {private long total; // 总记录数private List<?> rows; // 当前页数据// getter/setter
}
前端可以通过这个结构准确获取当前页的数据列表以及总记录数,从而正确渲染分页组件。
六、最佳实践总结
| 项目 | 推荐做法 |
|---|---|
| Mapper 接口返回类型 | ✅ Page<T> |
| XML SQL 写法 | ❌ 不需要特殊修改 |
| Service 层处理 | ✅ 使用 Page<T> 进行 VO 转换并封装 TableDataInfo |
| Controller 层 | ✅ 只负责调用和返回 |
| VO 转换方式 | ✅ 使用 MapStruct 替代 BeanUtils.copyProperties |
| 分页工具类 | ✅ 抽取通用分页转换工具类 |
七、结语
PageHelper 是一个强大且易用的分页插件,但在使用过程中必须注意:
- 不要随意丢弃
Page<T>对象; - 避免在 Service 层中使用
new ArrayList<>()包装分页结果; - 确保最终返回的
TableDataInfo包含total字段;
只有这样才能保证前后端协同工作的准确性,避免出现“前端分页失效”、“total 为 0”等常见问题。
如果你正在使用 RuoYi 开发后台管理系统,请务必重视分页逻辑的设计与实现,确保每一次查询都能正确携带分页信息。