通用RAG:通过路由模块对多源异构知识库检索生成问答思路
如何在多个语料库(多源异构知识库,如:文本、图片、视频)中检索和整合来自不同模态和粒度的知识?UniversalRAG:一种新的RAG框架,用于从多个模态和粒度的语料库中检索和整合知识。下面来看看思路,供参考。
方法
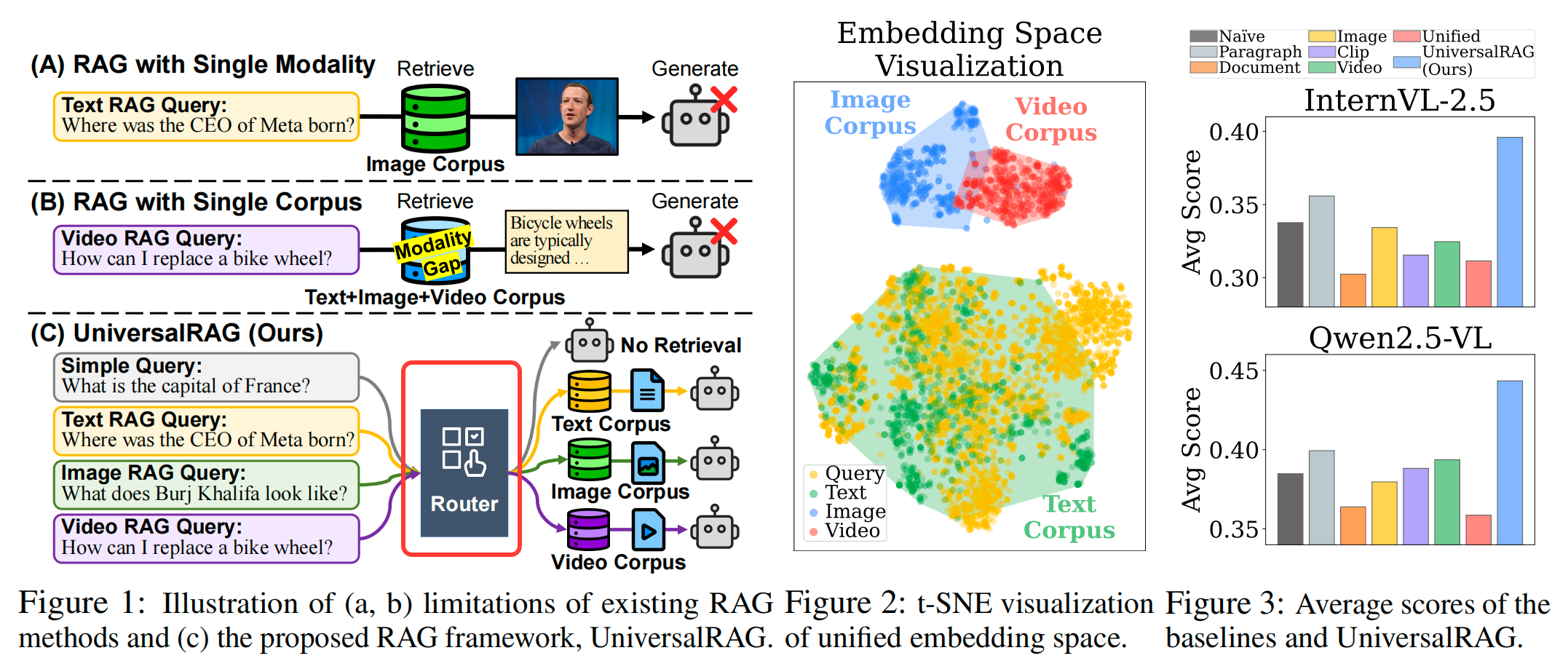
从上图可以看到,UniversalRAG的核心思想是通过动态识别和路由查询到最合适的模态和粒度知识源来进行检索。
-
模态感知检索(Modality-Aware Retrieval):
-
多模态语料库:UniversalRAG维护三个独立的嵌入空间,分别对应文本、图像和视频模态。每个模态的语料库被组织成不同的子语料库,如:文本语料库分为段落级和文档级,视频语料库分为完整视频和视频片段。
-
路由模块(Router):引入一个路由模块,Router,动态选择每个查询的最合适模态。给定一个查询q,Router预测查询相关的模态r,并从相应的模态特定语料库中选择相关项c。
-
-
粒度感知检索(Granularity-Aware Retrieval):
-
多粒度支持:为了灵活适应不同查询的信息需求,UniversalRAG在每个模态内进一步划分为多个粒度级别。例如,文本语料库分为段落级和文档级,视频语料库分为视频片段和完整视频。
-
路由决策:路由决策r分为六类:无检索(None)、段落(Paragraph)、文档(Document)、图像(Image)、片段(Clip)、视频(Video)。检索过程根据路由决策r进行,具体公式如下:

-
路由模块设计:
一、无训练的路由
无训练的路由利用预训练的LLM的内在知识和推理能力来分类查询。步骤如下:
- 提示设计:给定一个查询q,LLM会被提供一个详细的指令描述路由任务,并附带几个上下文示例。
- 预测路由类型:LLM根据提示和示例预测查询最合适的检索类型,从六个预定义的选项中选择。
小结:这种方法的优势在于不需要额外的训练数据,利用了LLM的强大泛化能力。然而,其性能可能受限于LLM的预训练知识和推理能力。
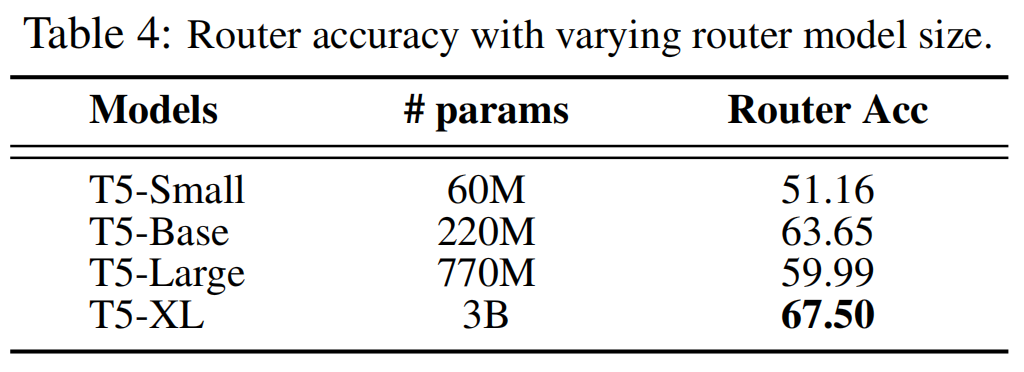
二、训练路由
为了提高路由的准确性,UniversalRAG还探索了训练路由模块的方法。训练路由模块面临的主要挑战是缺乏查询标签对(ground-truth query-label pairs)来进行最优语料库选择的监督。为此,文章采用了一种间接的方法来构建训练数据集:
- 利用基准测试的归纳偏差:假设每个基准测试主要与特定的模态和检索粒度相关联。例如,文本问答基准测试中的查询可能主要需要段落级别的信息,而多跳问答基准测试可能需要文档级别的信息。
- 标签分配:
-
对于文本问答基准测试,查询被标记为’None’(如果查询可以仅通过模型的参数知识回答)、‘Paragraph’(单跳RAG基准测试)或’Document’(多跳RAG基准测试)。
-
对于图像基准测试,查询被标记为’Image’。
-
对于视频问答基准测试,查询被标记为’Clip’(如果查询关注视频中的局部事件或特定时刻)或’Video’(如果查询需要理解整个视频的故事情节或更广泛的上下文)。
-
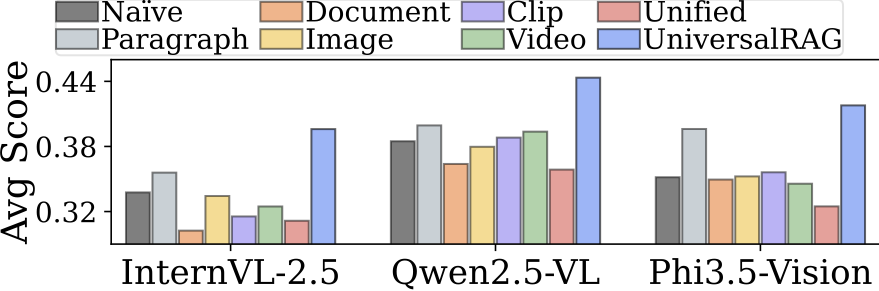
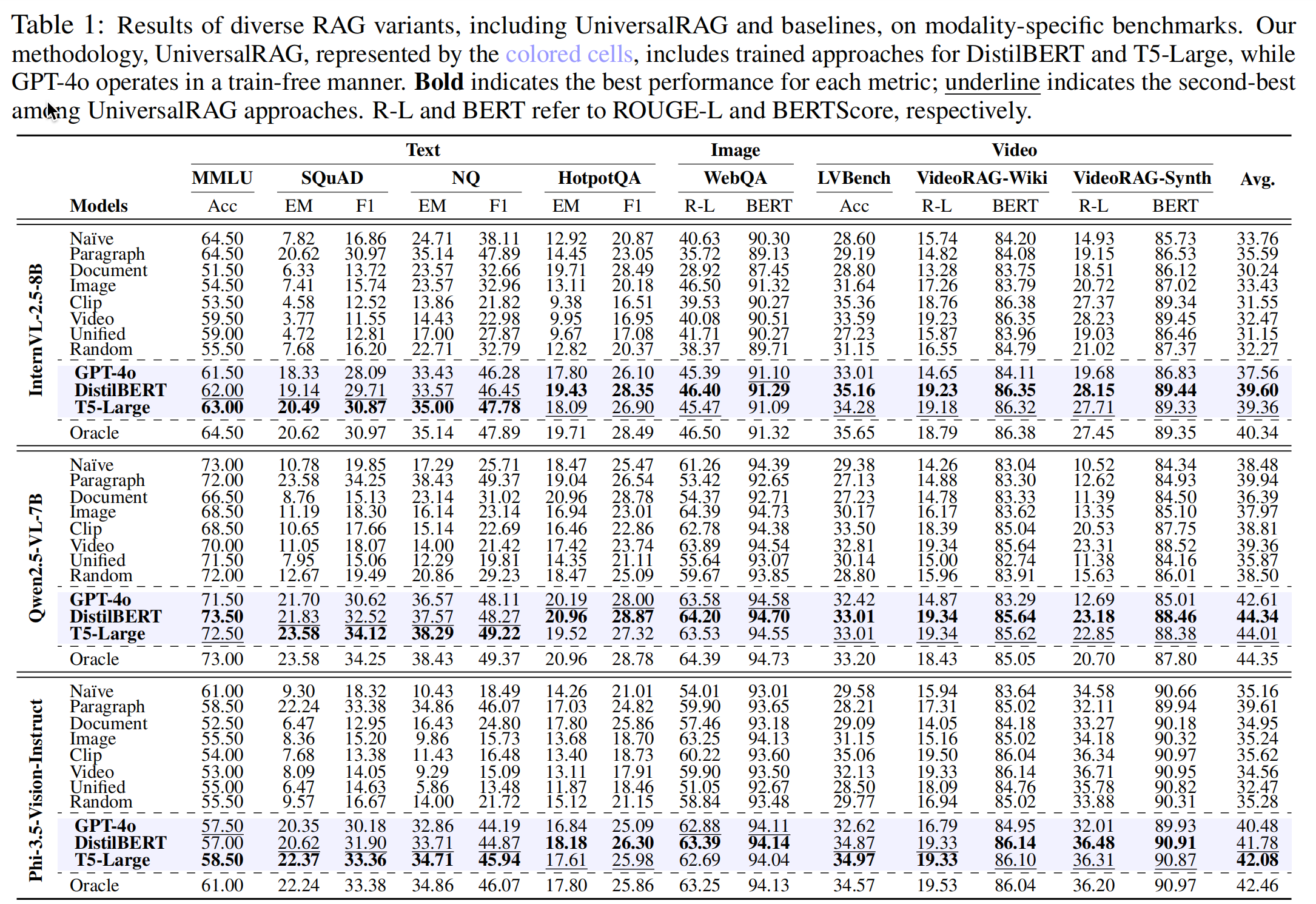
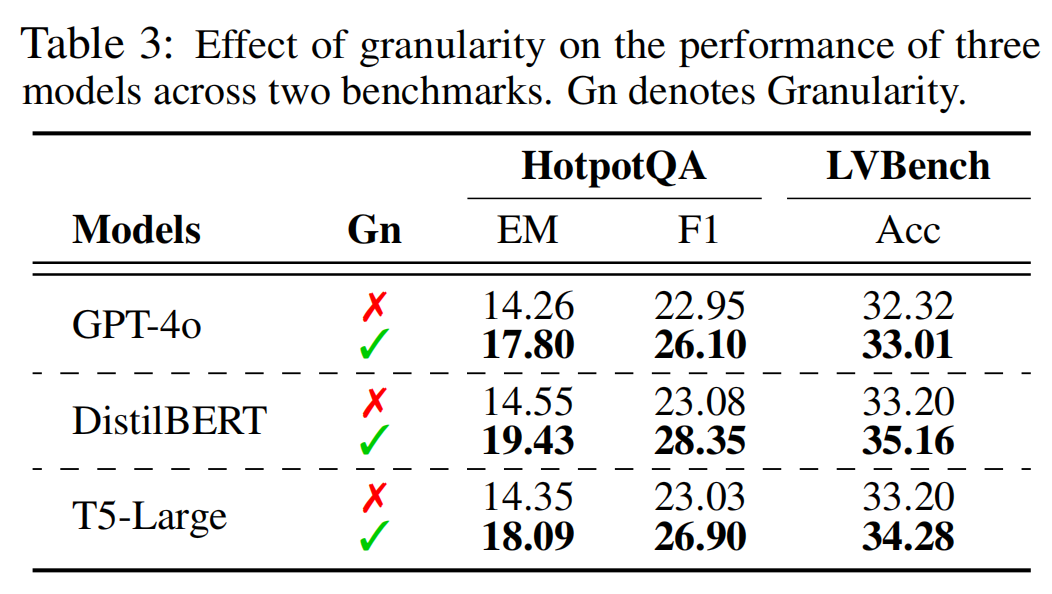
性能效果

参考:UniversalRAG: Retrieval-Augmented Generation over Multiple Corpora with Diverse Modalities and Granularities,https://arxiv.org/pdf/2504.20734