运行Spark程序(二)RDD基本概念和创建
RDD基本概念
Resilient Distributed Dataset 叫做弹性分布式数据集,是Spark中最基本的数据抽象,是分布式计算的实现载体,代表一个不可变,可分区,里面的元素并行计算的集合。
不可变的:immutable。类比理解scala中的不可变集合或者是使用val修饰的变量。
可分区的:集合的数据课划分成为很多部分,每部分称为分区:Partition
并行计算:集合中的数据可以被并行的计算处理,每个分区数据被一个Task任务处理。
RDD的创建
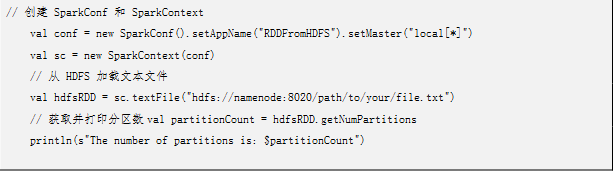
spark的计算功能是通过RDD来实现的,那么如何去创建RDD呢?有两种创建方式。
1.从集合内存中创建
可以通过将本地集合(如数组、列表等)传递给 SparkContext 的 parallelize 方法来创建 RDD。

2.从外部存储中创建。例如,读入外部的文件。