从代码学习深度学习 - 区域卷积神经网络(R-CNN)系列 PyTorch版
文章目录
- 前言
- R-CNN
- Fast R-CNN
- 兴趣区域汇聚层 (RoI Pooling)
- 代码示例:兴趣区域汇聚层 (RoI Pooling) 的计算方法
- Faster R-CNN
- Mask R-CNN
- 双线性插值 (Bilinear Interpolation) 与兴趣区域对齐 (RoI Align)
- 兴趣区域对齐层的输入输出
- 全卷积网络 (FCN) 的作用
- 掩码输出形状
- 总结
前言
欢迎来到“从代码学习深度学习”系列博客!在计算机视觉领域,目标检测是一个核心任务,它不仅要求我们识别图像中的物体,还需要定位它们的位置。区域卷积神经网络(Region-based Convolutional Neural Networks, R-CNN)及其后续改进版本(Fast R-CNN, Faster R-CNN, Mask R-CNN)是解决这一问题的里程碑式工作。它们逐步提高了目标检测的准确性和效率,并扩展到实例分割等更复杂的任务。
本篇博客将带你回顾 R-CNN 系列模型的发展历程,并通过 PyTorch 代码示例(重点在兴趣区域汇聚层)来理解其核心组件的工作原理。我们将从最初的 R-CNN 开始,逐步探索其改进版本,理解它们是如何解决前代模型的瓶颈,并引入新的创新思想的。
完整代码:下载链接
R-CNN
R-CNN (Regions with CNN features) 是将深度学习应用于目标检测领域的开创性工作之一。它的核心思想是利用卷积神经网络(CNN)提取区域特征,从而进行目标分类和定位。
R-CNN 的第一步是从整张图像中挑选出可能包含物体的小区域,称为“候选区域”或“提议区域”(region proposals)。这些区域是由 Selective Search 这类算法选出来的,不是通过滑动窗口或CNN直接得到的。数量大约为2000个。(注:锚框是Faster R-CNN等后续方法的技术,R-CNN并不使用锚框。)R-CNN通过先选出可能含目标的图像区域,对这些区域单独用CNN提取特征,再用这些特征去判断目标种类和更精准的位置。
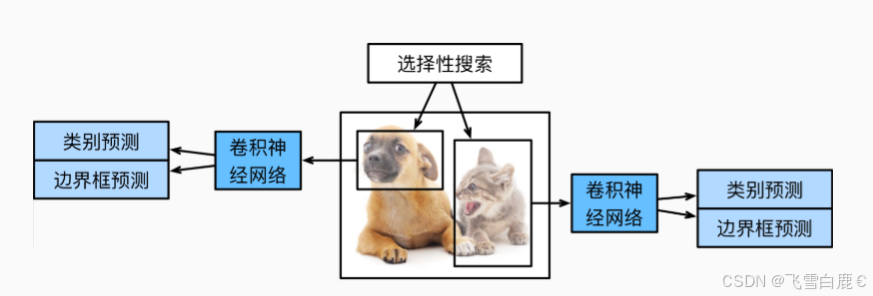
上图展示了R-CNN模型。具体来说,R-CNN包括以下四个步骤:
- 对输入图像使用_选择性搜索_(Selective Search)来选取多个高质量的提议区域。这些提议区域通常是在多个尺度下选取的,并具有不同的形状和大小。每个提议区域都将被标注类别和真实边界框。
- 选择一个预训练的卷积神经网络,并将其在输出层之前截断。将每个提议区域变形为网络需要的输入尺寸,并通过前向传播输出抽取的提议区域特征。
- 将每个提议区域的特征连同其标注的类别作为一个样本。训练多个支持向量机(SVM)对目标分类,其中每个支持向量机用来判断样本是否属于某一个类别。
- 将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性回归模型来预测真实边界框。
尽管R-CNN模型通过预训练的卷积神经网络有效地抽取了图像特征,但它的速度很慢。因为可能从一张图像中选出上千个提议区域,这需要上千次的卷积神经网络的前向传播来执行目标检测。这种庞大的计算量使得R-CNN在现实世界中难以被广泛应用。
Fast R-CNN
针对 R-CNN 的速度瓶颈,Fast R-CNN 提出了关键改进。R-CNN的主要性能瓶颈在于,对每个提议区域,卷积神经网络的前向传播是独立的,而没有共享计算。由于这些区域通常有重叠,独立的特征抽取会导致重复的计算。Fast R-CNN 对R-CNN的主要改进之一,是仅在整张图象上执行卷积神经网络的前向传播。
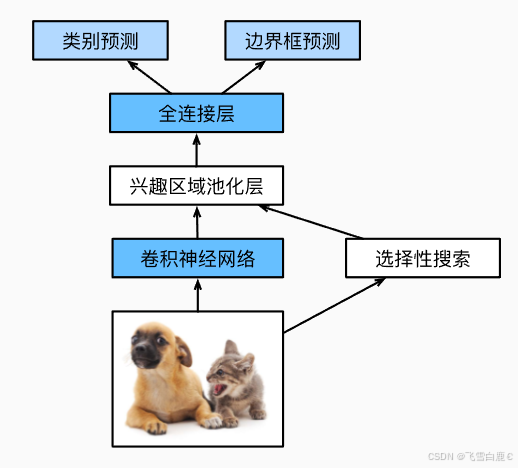
上图中描述了Fast R-CNN模型。它的主要计算如下:
- 与R-CNN相比,Fast R-CNN用来提取特征的卷积神经网络的输入是整个图像,而不是各个提议区域。此外,这个网络通常会参与训练。设输入为一张图像,将卷积神经网络的输出的形状记为1×c×h1×w1。
- 假设选择性搜索生成了n个提议区域。这些形状各异的提议区域在卷积神经网络的输出上分别标出了形状各异的兴趣区域。然后,这些感兴趣的区域需要进一步抽取出形状相同的特征(比如指定高度h2和宽度w2),以便于连结后输出。为了实现这一目标,Fast R-CNN引入了_兴趣区域汇聚层_(RoI pooling):将卷积神经网络的输出和提议区域作为输入,输出连结后的各个提议区域抽取的特征,形状为n×c×h2×w2。
- 通过全连接层将输出形状变换为n×d,其中超参数d取决于模型设计。
- 预测n个提议区域中每个区域的类别和边界框。更具体地说,在预测类别和边界框时,将全连接层的输出分别转换为形状为n×q(q是类别的数量)的输出和形状为n×4的输出。其中预测类别时使用softmax回归。
兴趣区域汇聚层 (RoI Pooling)
在汇聚层中,我们通过设置汇聚窗口、填充和步幅的大小来间接控制输出形状。而兴趣区域汇聚层对每个区域的输出形状是可以直接指定的。
例如,指定每个区域输出的高和宽分别为h2和w2。对于任何形状为h×w的兴趣区域窗口,该窗口将被划分为h2×w2子窗口网格,其中每个子窗口的大小约为(h/h2)×(w/w2)。在实践中,任何子窗口的高度和宽度都应向上取整,其中的最大元素作为该子窗口的输出。因此,兴趣区域汇聚层可从形状各异的兴趣区域中均抽取出形状相同的特征。
代码示例:兴趣区域汇聚层 (RoI Pooling) 的计算方法
下面我们通过一段 PyTorch 代码来演示兴趣区域汇聚层 (RoI Pooling) 的计算方法。
# 演示兴趣区域汇聚层(ROI Pooling)的计算方法
import torch # 导入PyTorch库
import torchvision # 导入PyTorch视觉库# 创建一个4×4的特征图张量作为CNN抽取的特征
# torch.arange(16.) 创建一个包含0到15的一维浮点数张量,维度为[16]
# reshape(1, 1, 4, 4) 将张量重塑为4维张量,维度为[1, 1, 4, 4]
# 第一个维度: 批次大小(batch size) = 1
# 第二个维度: 通道数(channels) = 1
# 第三个维度: 高度(height) = 4
# 第四个维度: 宽度(width) = 4
X = torch.arange(16.).reshape(1, 1, 4, 4)
X[: