强化学习之蒙特卡洛树搜索和噪声网络
1、蒙特卡洛树搜索(MCTS)
核心思想
蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)是一种用于决策和优化问题的启发式搜索算法,尤其适用于状态空间巨大且难以穷尽的复杂场景。它通过模拟随机策略探索决策路径,利用统计方法评估节点潜力,逐步构建和优化搜索树。
MCTS的核心在于平衡探索(Exploration)与利用(Exploitation),通过迭代执行四个步骤(选择、扩展、模拟、回溯、决策)来逐步逼近最优策略。其优势在于无需领域知识,能够处理高维连续状态空间,且在模拟次数足够时收敛到最优解。
算法步骤
1、选择(Select)
- 目的:从根节点开始,根据一定的策略选择一条路径,直到到达叶子节点,以便确定接下来要扩展和模拟的节点。
- 实现方式:通常使用基于 UCB(Upper Confidence Bound)的公式来平衡探索和利用。如公式
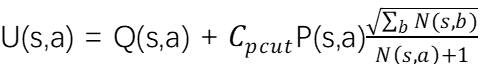
这个分数的意义为:加入父节点的状态为s,经过父节点的动作a,达到一个子节点,那么这个子节点的分数由这个子节点的价值函数Q(s,a)、这个子节点的先验概率P(s,a)、这个子节点被采样到的个数N(s,a)和父节点的所有采样个数的和的平方根共同决定,Cpcut是一个常数,控制了智能体的探索和利用之间的平衡。
一个节点的价值函数代表了这个节点未来有可能收到的奖励的值,在式中的第一项代表某个节点的价值,这个价值越大,表示探索这个节点与有可能获取大的奖励;第二项如果不考虑先验概率,那么这个值就和子节点被采样到的次数成反比,如果一个节点很少被采样到,那么第二项的访问次数的比值就会很大,从而就会增加U(s,a)的值,让这个节点更容易被采样到。因此,U(s,a)的第一项和第二项分别代表智能体利用和探索的部分,而Cpcut系数控制了这个两个部分之间的平衡,可以根据具体的问题来调节这个值,让蒙特卡洛搜索偏向于探索更好的节点或者探索尽可能多的节点。
2、扩展(Expand)
- 目的:在选择步骤到达的叶子节点上,生成一个或多个未被探索的子节点,以进一步扩展搜索树,增加对搜索空间的探索。
- 实现方式:如果叶子节点不是终端节点,并且存在未被探索过的子节点,则选择一个未探索的子节点进行扩展。具体选择方法可以是随机选择,或者根据一定的启发式规则选择。如果所有子节点都已被探索过,则可以选择一个随机子节点进行扩展,以避免搜索树过早地停止生长。
3、模拟(Simulation,也称为求值)
- 目的:从扩展后的节点开始,通过随机模拟游戏或其他方式,快速评估该节点的价值,得到一个奖励值,用于后续的回溯和节点评估。
- 实现方式:从当前节点的状态开始,按照一定的规则随机模拟游戏过程,直到达到游戏的结束状态(终端节点)。在模拟过程中,根据游戏的结果确定奖励值。例如,在博弈游戏中,胜利可能对应奖励值为 1,失败为 -1,平局为 0。模拟的过程通常是基于随机策略进行的,但也可以结合一些启发式规则或预先训练的模型来引导模拟,以提高模拟的效率和准确性。
4、回溯(Backup)
- 目的:将模拟得到的奖励值沿着选择和扩展的路径反向传播,更新路径上所有节点的统计信息,以便后续能够根据这些信息更好地选择节点和评估路径的价值。
- 实现方式:从模拟结束的节点开始,沿着搜索路径依次向上更新每个节点的统计信息。对于每个节点,其访问次数N加 1,总奖励值R加上模拟得到的奖励值。同时,根据这些统计信息可以计算出节点的平均奖励等其他相关指标,如Q(s,a)=R(s,a)/N(s,a),其中Q(s,a)是状态s下采取动作a的平均奖励,R(s,a)是状态s下采取动作a获得的总奖励,N(s,a)是状态s下采取动作a的次数。这些更新后的信息将用于下一次迭代中的选择步骤,以指导搜索朝着更有价值的方向进行。
5、决策(Play)
- 目的:在经过多次迭代的选择、扩展、模拟和回溯后,根据搜索树中存储的信息,从根节点的子节点中选择一个最优的动作作为当前的决策。
- 实现方式:通常选择根节点的具有最高平均奖励或其他评估指标最优的子节点所对应的动作作为决策结果。例如,可以选择平均奖励Q(s,a)最高的子节点,其对应的动作就是当前认为的最优动作。在一些情况下,也可能会考虑其他因素,如节点的访问次数等,以综合评估子节点的优劣。此外,为了增加决策的多样性和探索性,也可以采用一些随机选择的策略,例如按照一定的概率选择不是最优但具有一定潜力的子节点。
- 一般来说,访问次数越高,代表当前节点的价值越高,越应该被选择。根据这个原理可以估算出根节点所有子节点的概率Π(a|s),这个概率的计算公式为:
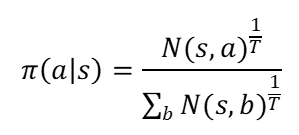
其中,T是温度系数,对应的访问次数越高,则代表节点的价值越高,越容易被选择。而温度系数越高,则意味着访问次数多的节点和访问次数少的节点的概率差距越大。当温度系数趋向于0的时候,访问次数最高的节点概率趋向于1,其它系欸但的概率趋向于0。
总结一下,蒙特卡洛搜索算法包含了一系列决策过程,每个决策过程都会包含多个“选择->扩展->求值->回溯”循环,并且在循环结束的时候计算选择对应的动作概率进行决策,随机采样让根节点向前移动。在决策到达终点,也就是得到对弈的结果之后,整条决策路径会被保存下来,同时,根据最后博弈的结果会给每个节点赋予一个具体的价值z,结合模型输出的概率p、价值v和蒙特卡洛书搜索算法得到的概率Π,以及模型的参数θ,可以得到最后的损失函数:
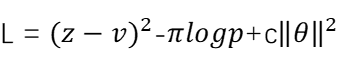
其中损失函数由三部分构成,第一部分是价值函数的MSE损失函数,目的是未来让模型对于局势的估计尽可能和最后的结果相符;第二部分是交叉熵损失函数,目的是为了模型对概率分布的估计尽可能和蒙特卡洛树搜索算法得到的概率Π相符;第三部分的目的是为了防止模型的过拟合,c是防止过拟合的常数。
特点
- 无需完整的领域知识:不需要对问题的整个搜索空间有先验的了解,只需要能够模拟从一个状态到另一个状态的转换以及判断终止状态和奖励。
- 适用于复杂的搜索空间:能够处理非常大甚至是无限的搜索空间,通过逐步构建搜索树来聚焦于有希望的区域。
- 在线学习:可以在不断接收新信息的过程中逐步改进策略,随着模拟次数的增加,对最优决策的估计会越来越准确。
实现代码
#! /usr/bin/env pythonimport math
import random
import numpy as np
from scipy.special import softmax
from collections import deque
import torch
import torch.nn as nn
import torch.nn.functional as Ffrom gym_gomoku.envs.gomoku import GomokuState, Board
from gym_gomoku.envs.util import gomoku_utilclass PolicyValueNet(nn.Module):def __init__(self, board_size):super().__init__()self.featnet = nn.Sequential(nn.Conv2d(4, 32, 3, 1, 1),nn.ReLU(),nn.Conv2d(32, 64, 3, 1, 1),nn.ReLU(),nn.Conv2d(64, 128, 3, 1, 1),nn.ReLU(),)self.pnet = nn.Sequential(nn.Conv2d(128, 4, 1),nn.ReLU(),nn.Flatten(),nn.Linear(4*board_size*board_size, board_size*board_size))self.vnet = nn.Sequential(nn.Conv2d(128, 2, 1),nn.ReLU(),nn.Flatten(),nn.Linear(2*board_size*board_size, 64),nn.ReLU(),nn.Linear(64, 1))def forward(self, x):feat = self.featnet(x)prob = self.pnet(feat).softmax(-1)val = self.vnet(feat).tanh()return prob, valdef evaluate(self, x):with torch.no_grad():prob, val = self(x)return prob.squeeze(), val.squeeze()class TreeNode(object):def __init__(self, parent, prior):self.parent = parentself.prior = priorself.Q = 0self.N = 0self.children = {}def score(self, c_puct): #公式计算,U(s,a)=Q(s,a)+c_puct*P(s,a)*sqrt(sum(N)/N+1)sqrt_sum = np.sqrt(np.sum([node.N for node in self.parent.children.values()]))return self.Q + c_puct*self.prior*sqrt_sum/(1 + self.N)def update(self, qval):self.Q = self.Q*self.N + qvalself.N += 1self.Q = self.Q/self.Ndef backup(self, qval):self.update(qval)if self.parent: self.parent.backup(-qval)def select(self, c_puct):return max(self.children.items(), key=lambda x: x[1].score(c_puct))def expand(self, actions, priors):for action, prior in zip(actions, priors):if action not in self.children:self.children[action] = TreeNode(self, prior)@propertydef is_root(self):return self.parent is None@propertydef is_leaf(self):return len(self.children) == 0class MCTSBot(object):def __init__(self, board_size, c_puct=5.0, nsearch=2000):self.board_size = board_sizeself.root = TreeNode(None, 1.0)self.c_puct = c_puctself.nsearch = nsearchdef get_feature(self, board, player):feat = board.encode()feat1 = (feat == 1).astype(np.float32)feat2 = (feat == 2).astype(np.float32)feat3 = np.zeros((self.board_size, self.board_size)).astype(np.float32)if board.last_action is not None:x, y = board.action_to_coord(board.last_action)feat3[x, y] = 1.0if player == 'white':feat4 = np.zeros((self.board_size, self.board_size)).astype(np.float32)return np.stack([feat1, feat2, feat3, feat4], axis=0)elif player == 'black':feat4 = np.ones((self.board_size, self.board_size)).astype(np.float32)return np.stack([feat1, feat2, feat3, feat4], axis=0)def mcts_search(self, state, pvnet):node = self.rootwhile not node.is_leaf:action, node = node.select(self.c_puct) #第一步,选择state = state.act(action)feature = self.get_feature(state.board, state.color)feature = torch.tensor(feature).unsqueeze(0)probs, val = pvnet.evaluate(feature) #求值actions = state.board.get_legal_action()probs = probs[actions]if state.board.is_terminal():_, win_color = \gomoku_util.check_five_in_row(state.board.board_state)if win_color == 'empty':val = 0.0elif win_color == state.color:val = 1.0else:val = -1.0else:node.expand(actions, probs) #第二步:扩展node.backup(-val) #第三步:回溯def alpha(self, state, pvnet, temperature=1e-3): #执行蒙特卡洛树搜索for _ in range(self.nsearch):self.mcts_search(state, pvnet)node_info = [(action, node.N) for action, node in self.root.children.items()]actions, nvisits = zip(*node_info)actions = np.array(actions)probs = np.log(np.array(nvisits)+1e-6)/temperatureprobs = softmax(probs)return actions, probsdef reset(self):self.root = TreeNode(None, 1.0)def step(self, action):self.root = self.root.children[action]self.root.parent= Noneclass MCTSRunner(object):def __init__(self, board_size, pvnet, eps = 0.25, alpha = 0.03, c_puct=5.0, nsearch=2000, selfplay=False):self.pvnet = pvnetself.mctsbot = MCTSBot(board_size, c_puct, nsearch)self.board_size = board_sizeself.selfplay = selfplayself.eps = epsself.alpha = alphadef reset(self):self.mctsbot.reset()def play(self, state, temperature=1e-3, return_data=False):#temperature控制动作选择随机性的参数probs = np.zeros(self.board_size*self.board_size)feat = self.mctsbot.get_feature(state.board, state.color)#执行蒙特卡洛搜索a, p = self.mctsbot.alpha(state, self.pvnet, temperature) #获得,行动,概率probs[a] = paction = -1if self.selfplay: #第四步:决策p = (1 - self.eps)*p + self.eps*np.random.dirichlet([self.alpha]*len(a))action = np.random.choice(a, p=p)self.mctsbot.step(action)else:action = np.random.choice(a, p=p)self.mctsbot.reset() if return_data:return action, feat, probselse:return actionclass MCTSTrainer(object):def __init__(self):self.board_size = 9self.buffer_size = 10000self.c_puct = 5.0self.nsearch = 1000self.temperature = 1e-3self.lr = 1e-3self.l2_reg = 1e-4self.niter = 5self.batch_size = 128self.ntrain = 1000self.buffer = deque(maxlen=self.buffer_size)self.pvnet = PolicyValueNet(self.board_size)self.optimizer = torch.optim.Adam(self.pvnet.parameters(), lr=self.lr, weight_decay=self.l2_reg)self.mcts_runner = MCTSRunner(self.board_size, self.pvnet, c_puct=self.c_puct, nsearch=self.nsearch, selfplay=True)def reset_state(self):self.state = GomokuState(Board(self.board_size), gomoku_util.BLACK) #初始化五子棋游戏对象def collect_data(self):self.reset_state()self.mcts_runner.reset()feats = [] #存储每个游戏状态的特征表示。probs = [] #存储每个动作的概率分布players = [] #存储每个状态下当前玩家的颜色values = [] #存储每个状态的价值(最终游戏结果)cnt = 0 #初始化一个计数器 cnt,用于跟踪当前游戏的步数while True:print(f"step {cnt+1}"); cnt += 1# print(self.state)action, feat, prob = self.mcts_runner.play(self.state, self.temperature, True) #获取当前状态下的动作、特征表示和概率分布feats.append(feat)probs.append(prob)players.append(self.state.color)self.state = self.state.act(action)if self.state.board.is_terminal():_, win_color = \gomoku_util.check_five_in_row(self.state.board.board_state)if win_color == 'empty':values = [0.0]*len(players)else:values = [1.0 if player == win_color else -1.0 for player in players]return zip(feats, probs, values)def data_augment(self, data):ret = []for feat, prob, value in data:for i in range(0, 4):feat = np.rot90(feat, i, (1, 2))ret.append((feat, prob, value))ret.append((feat[:,::-1,:], prob, value))ret.append((feat[:,:,::-1], prob, value))return retdef train_step(self):data = self.collect_data()data = self.data_augment(data)self.buffer.extend(data)for idx in range(self.niter):feats, probs, values = zip(*random.sample(self.buffer, self.batch_size))feats = torch.tensor(np.stack(feats, axis=0))probs = torch.tensor(np.stack(probs, axis=0))values = torch.tensor(np.stack(values, axis=0))p, v = self.pvnet(feats)loss = (v - values).pow(2).mean() - (probs*(p + 1e-6).log()).mean()self.optimizer.zero_grad()loss.backward()print(f"In iteration: {idx}, Loss function: {loss.item():12.6f}")self.optimizer.step()def train(self):for idx in range(self.ntrain):print(f"In training step {idx}")self.train_step()if __name__ == "__main__":trainer = MCTSTrainer()trainer.train()2、噪声网络(Noisy Network)
核心思想
噪声网络(Noisy Network)是强化学习中一种通过向神经网络参数注入噪声来提升探索效率与策略鲁棒性的方法,其核心在于将随机性从动作层面转移至参数层面,通过动态调整噪声分布实现更高效的探索与利用平衡。噪声的存在能够有效拟合强化学习算法中的噪声,同时也增加了模型对于价值函数估计的准确性。
为了让模型有拟合噪声的能力,噪声网络考虑的是显式地在网络前向传播的时候在模型的参数中加入一定的噪声,让带有噪声的模型去拟合带有噪声的分布,从而学习到正确的考虑噪声的参数。考虑一个简单的线性层,公式为y=Wx+b,其中x是输入的张量,W和b是线性层的参数,y是输出的张量。在一般的线性层中,W和b是确定的张量,没有包含任何随机性。为了加入随机性,可以考虑重参数化技巧,定义随机化的线性层参数W和b,公式如下:

实现代码
#! /usr/bin/env pythonimport torch
import torch.nn as nn
import torch.nn.functional as F
from torch.distributions import Categorical
import random
from math import sqrt
import numpy as np
import gym
from PIL import Image
from collections import dequeclass NoisyLinear(nn.Module):def __init__(self, in_features, out_features):super().__init__()self.in_features = in_featuresself.out_features = out_featuresself.mu_w = nn.Parameter(torch.zeros(in_features, out_features)) # 权重的均值self.sigma_w = nn.Parameter(torch.zeros(in_features, out_features)) # 权重的标准差self.mu_b = nn.Parameter(torch.zeros(out_features)) # 偏置的均值self.sigma_b = nn.Parameter(torch.zeros(out_features)) # 偏置的标准差self._init_params()def _init_params(self):val_w = 1.0 / sqrt(self.in_features)torch.nn.init.uniform_(self.mu_w, -val_w, val_w) # 均匀初始化权重均值torch.nn.init.constant_(self.sigma_w, 0.5 * val_w) # 标准差初始化为固定值val_b = 1.0 / sqrt(self.out_features)torch.nn.init.uniform_(self.mu_b, -val_b, val_b) # 均匀初始化偏置均值torch.nn.init.constant_(self.sigma_b, 0.5 * val_b) # 标准差初始化为固定值def reset_noise(self):eps1 = torch.randn(self.in_features)eps1 = eps1.sgn()*eps1.abs().sqrt()eps2 = torch.randn(self.out_features)eps2 = eps2.sgn()*eps2.abs().sqrt()self.e1 = (eps1.unsqueeze(1)*eps2.unsqueeze(0)).to(self.sigma_w.device)self.e2 = eps2.to(self.sigma_b.device)def forward(self, x):w = self.mu_w + self.sigma_w * self.e1 # 带噪声的权重b = self.mu_b + self.sigma_b * self.e2 # 带噪声的偏置return x @ w + b # 线性变换class Actor(nn.Module):def __init__(self, img_size, num_actions):super().__init__()# 输入图像的形状(c, h, w)self.img_size = img_sizeself.num_actions = num_actions# 对于Atari环境,输入为(4, 84, 84)self.featnet = nn.Sequential(nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=4, stride=2),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1),nn.ReLU(),nn.Flatten(),)gain = nn.init.calculate_gain('relu')self.pnet1 = nn.Sequential(nn.Linear(self._feat_size(), 512),nn.ReLU(),)self._init(self.featnet, gain)self._init(self.pnet1, gain)# 策略网络,计算每个动作的概率gain = 1.0self.pnet2 = NoisyLinear(512, self.num_actions)self._init(self.pnet2, gain)def _feat_size(self):with torch.no_grad():x = torch.randn(1, *self.img_size)x = self.featnet(x).view(1, -1)return x.size(1)def _init(self, mod, gain):for m in mod.modules():if isinstance(m, (nn.Linear, nn.Conv2d)):nn.init.orthogonal_(m.weight, gain=gain)nn.init.zeros_(m.bias)def reset_noise(self):for m in self.modules():if isinstance(m, NoisyLinear):m.reset_noise()def forward(self, x):feat = self.featnet(x)feat = self.pnet1(feat)return self.pnet2(feat)def act(self, x):with torch.no_grad():logits = self(x)m = Categorical(logits=logits).sample().squeeze()return m.cpu().item()class Critic(nn.Module):def __init__(self, img_size):super().__init__()# 输入图像的形状(c, h, w)self.img_size = img_size# 对于Atari环境,输入为(4, 84, 84)self.featnet = nn.Sequential(nn.Conv2d(img_size[0], 32, kernel_size=8, stride=4),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=4, stride=2),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1),nn.ReLU(),nn.Flatten())gain = nn.init.calculate_gain('relu') self.vnet1 = nn.Sequential(nn.Linear(self._feat_size(), 512),nn.ReLU())self._init(self.featnet, gain)self._init(self.vnet1, gain)# 价值网络,根据特征输出每个动作的价值gain = 1.0self.vnet2 = NoisyLinear(512, 1)self._init(self.vnet2, gain)def _feat_size(self):with torch.no_grad():x = torch.randn(1, *self.img_size)x = self.featnet(x).view(1, -1)return x.size(1)def _init(self, mod, gain):for m in mod.modules():if isinstance(m, (nn.Linear, nn.Conv2d)):nn.init.orthogonal_(m.weight, gain=gain)nn.init.zeros_(m.bias)def reset_noise(self):for m in self.modules():if isinstance(m, NoisyLinear):m.reset_noise()def forward(self, x):feat = self.featnet(x)feat = self.vnet1(feat)return self.vnet2(feat).squeeze(-1)def val(self, x):with torch.no_grad():val = self(x).squeeze()return val.cpu().item()class ActionBuffer(object):def __init__(self, buffer_size):super().__init__()self.buffer = deque(maxlen=buffer_size)def reset(self):self.buffer.clear()def push(self, state, action, value, reward, done):self.buffer.append((state, action, value, reward, done))def sample(self, next_value):state, action, value, reward, done = \zip(*self.buffer)value = np.array(value + (next_value, ))done = np.array(done).astype(np.float32)reward = np.array(reward).astype(np.float32)delta = reward + GAMMA*(1-done)*value[1:] - value[:-1]rtn = np.zeros_like(delta).astype(np.float32)adv = np.zeros_like(delta).astype(np.float32)reward_t = next_valuedelta_t = 0.0for i in reversed(range(len(reward))):reward_t = reward[i] + GAMMA*(1.0 - done[i])*reward_tdelta_t = delta[i] + (GAMMA*LAMBDA)*(1.0 - done[i])*delta_trtn[i] = reward_tadv[i] = delta_treturn np.stack(state, 0), np.stack(action, 0), rtn, advdef __len__(self):return len(self.buffer)class EnvWrapper(object):def __init__(self, env, num_frames):super().__init__()self.env_ = envself.num_frames = num_framesself.frame = deque(maxlen=num_frames)def _preprocess(self, img):# 预处理数据img = Image.fromarray(img)img = img.convert("L")img = img.crop((0, 30, 160, 200))img = img.resize((84, 84))img = np.array(img)/256.0return img - np.mean(img)def reset(self):obs = self.env_.reset()if isinstance(obs, tuple):obs = obs[0]for _ in range(self.num_frames):self.frame.append(self._preprocess(obs))return np.stack(self.frame, 0)def step(self, action):obs, reward, done, _, _ = self.env_.step(action)self.frame.append(self._preprocess(obs))return np.stack(self.frame, 0), np.sign(reward), done, {}@propertydef env(self):return self.env_def train(buffer, next_value, pnet, vnet, optimizer, use_gae=False):state, action, rtn, adv = buffer.sample(next_value)state = torch.tensor(state, dtype=torch.float32)action = torch.tensor(action, dtype=torch.long)rtn = torch.tensor(rtn, dtype=torch.float32)adv = torch.tensor(adv, dtype=torch.float32)logits = pnet(state)values = vnet(state)if not use_gae:adv = (rtn - values).detach()dist = Categorical(logits=logits)lossp = -(adv*dist.log_prob(action)).mean() - REG*dist.entropy().mean()lossv = 0.5*F.mse_loss(rtn, values)optimizer.zero_grad()lossp.backward()lossv.backward()torch.nn.utils.clip_grad_norm_(pnet.parameters(), 0.5) # 梯度裁剪:限制梯度范数不超过 0.5torch.nn.utils.clip_grad_norm_(vnet.parameters(), 0.5)optimizer.step()return lossp.item()GAMMA = 0.99
LAMBDA = 0.95
NFRAMES = 4
BATCH_SIZE = 8
NSTEPS = 1000000
REG = 0.01
env = gym.make('PongDeterministic-v4', render_mode='human')
env = EnvWrapper(env, NFRAMES)state = env.reset()
buffer = ActionBuffer(BATCH_SIZE)
pnet = Actor((4, 84, 84), env.env.action_space.n)
vnet = Critic((4, 84, 84))
# pnet.cuda()
# vnet.cuda()
optimizer = torch.optim.Adam([{'params': pnet.parameters(), 'lr': 3e-4},{'params': vnet.parameters(), 'lr': 3e-4},
])all_rewards = []
all_losses = []
all_values = []
episode_reward = 0
loss = 0.0pnet.reset_noise()
vnet.reset_noise()for nstep in range(NSTEPS):state_t = torch.tensor(state, dtype=torch.float32).unsqueeze(0)action = pnet.act(state_t)value = vnet.val(state_t)next_state, reward, done, _ = env.step(action)buffer.push(state, action, value, reward, done)state = next_stateepisode_reward += rewardif done:state = env.reset()all_rewards.append(episode_reward)state_t = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0)all_values.append(vnet.val(state_t))episode_reward = 0if done or len(buffer) == BATCH_SIZE:with torch.no_grad():state_t = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0)next_value = vnet.val(state_t)loss = train(buffer, next_value, pnet, vnet, optimizer)pnet.reset_noise()vnet.reset_noise()buffer.reset()