pod声明周期
Pod 对象自从其创建开始至其终止退出的时间范围称为其生命周期。在这段时间中,Pod 会处于多种不同的状态,并执行一些操作;其中,创建主容器(main container)为必须的操作,其他可选的操作还包括进行初始化容器(init container)、容器启动后钩子(post start hook)、容器的存活性探测(liveness probe)、就绪型探测(readiness probe)以及容器终止前钩子(pre stop hook)等,这些操作是否执行则取决于 Pod 的定义。
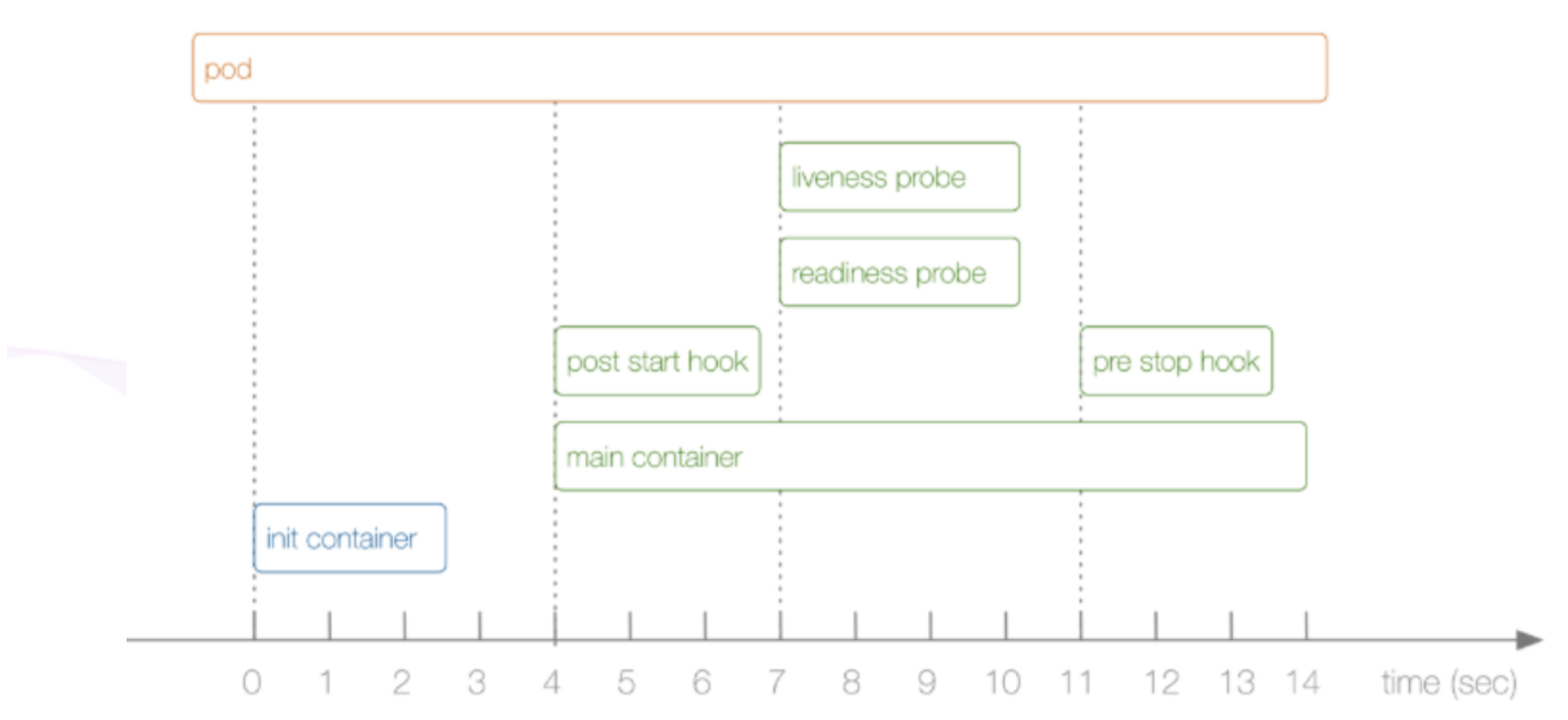
初始化容器
运行主容器和启动后钩子函数
启动探针(只检测一次)
存活探针和就绪探针(周期性检测)
终止前钩子函数
一、Pod phase
无论是用户手动创建,还是通过 Deployment 等控制器创建,Pod 对象总是应该处于其生命进程中以下几个相位(phase)之一
- pending:API Server 创建了 Pod 资源对象并已存入 etcd 中,但是它尚未被调度完成,或者仍处于从仓库下载镜像的过程中。
- Running:Pod 已经被调度至某节点,并且所有容器都已经被 kubelet 创建完成。
- Succeeded:Pod 中的所有容器都已经成功终止并且不会被重启。
- Failed:所有容器都已经终止,但至少有一个容器终止失败,即容器返回了非 0 值的退出状态或已经被系统终止。
- Unkown:API Server 无法正常获取到 Pod 对象的状态信息,通常是由于其无法与所在工作节点的 kubelet 通信所致。
故障排查速查表
| 现象 | 优先检查点 | 关键命令 |
|---|---|---|
| Pod卡在Pending | 节点资源/污点检查 | kubectl describe node |
| CrashLoopBackOff | 容器启动日志 | kubectl logs --previous |
| 服务间歇性不可用 | Readiness探针配置 | kubectl get endpoints |
| 终止耗时过长 | PreStop钩子执行情况 | kubectl get events -w |
| 存储卷挂载失败 | PVC绑定状态 | kubectl get pvc -o wide |
二、pod创建流程

- 当执行apply命令时会加载证书文件($HOME/.kube/config)连接Api-server(假设是rc资源创建Pod副本数量为5);
- Api-server对客户端请求进行验证,权限校验及资源清单配置文件解析;
- 若权限校验没问题,就会将请求记录写入到etcd数据库中进行存储;
- Control Manager组件查询api-server当前集群是否有任务需要维护(发现有一个rc资源有需要创建5个副本数,目前为0,于是会watch事件,监督其副本数量升为5个);
- scheduler查询api-server是否有Pod需要处于调度状态,api-server返回需要调度的列表,及集群的状态信息供给scheduler调度;
- scheduler调度完成后将结果返回给api-sever,api-sever将结果存储到etcd中;
- kubelet将Pod状态及worker节点资源状态周期性上报给api-server;
- api-server会验证kubelet的证书文件,验证通过后将数据写入到etcd中,与此同时,会将etcd中调度到该节点的Pod任务下发给kubelet;
- kubelet开始创建Pod,并周期性上报该Pod状态及节点状态给api-server;
三、声明周期钩子
钩子函数能够感知自身生命周期中的事件,并在相应的时刻到来时运行用户指定的程序代码
k8s 在主容器的启动之后和停止之前提供了两个钩子函数
- postStart:容器创建之后立刻执行,用于资源部署、环境准备等。
- preStop:在容器被终止前执行,用于优雅关闭应用程序、通知其他系统等
钩子函数定义方式
钩子的回调函数支持两种方式定义动作,下面以 postStart 为例讲解,preStop 定义方式与其一致:
exec模式
在容器中执行指定的命令。如果命令退出时返回码为0,判定为执行成功。
lifecycle:postStart:exec:command:- cat- /var/lib/redis.conf
HTTP GET模式
对容器中的指定端点执行HTTP GET请求,如果响应的状态码大于等于200且小于400,判定为执行成功。
httpGet模式支持以下配置参数:
- Host:HTTP请求主机地址,不设置时默认为Pod的IP地址。
- Path:HTTP请求路径,默认值是/。
- Port:HTTP请求端口号。
- Scheme:协议类型,支持HTTP和HTTPS协议,默认是HTTP。
- HttpHeaders:自定义HTTP请求头。
示例:访问 http://192.168.2.150:80/users
lifecycle:postStart:httpGet:path: /usersport: 80host: 192.168.2.150scheme: HTTP # 或者HTTPS
四、容器探测
Kubernetes 存在 3 种类型的探针,当探针检测失败时容器会被重启,如果容器在多次 (次数通过配置参数决定) 重启后仍然无法通过探针检测,容器状态将会被设置为 CrashLoopBackOff, 这意味着容器处于崩溃循环状态,无法成功启动和运行
启动探针
Startup Probe (启动探针) 用于检测容器是否已经完成所有初始化操作。
对于starup探针是一次性检测,容器启动时进行检测,检测成功后,才会调用其他探针,且此探针不在生效。
如果提供了启动探针,则所有其他探针都会被禁用,直到此探针成功为止。
如果启动探测失败,kubelet将杀死容器,而容器依其重启策略进行重启。
如果容器没有提供启动探测,则默认状态为 Success。
存活探针
【pod是否准备就绪】
Liveness Probe (存活探针) 用于检测容器内部应用是否在运行,可以为单个 Pod 中的所有容器单独设置,存活探针会监控容器的健康状态,如果容器发生故障或崩溃,存活探针会判断容器不再存活,容器会被重启或替换。
一旦启动探针成功返回一次,存活探针就开始接管对容器对监控。
健康状态检查,周期性检查服务是否存活,==检查结果失败,将"重启"容器(==删除源容器并重新创建新容器)。
如果容器没有提供健康状态检查,则默认状态为Success。
就绪探针
【pod服务是否能被外部访问】
Readiness Probe (就绪探针) 用于检测容器是否已经准备好接收流量,应用启动需要一系列初始化操作,就绪探针可以确保容器就绪前不会接收任何流量。 如果就绪检测失败,Pod 就不会再收到任何流量。
可用性检查,周期性检查服务是否可用,从而判断容器是否就绪。
若检测Pod服务不可用,则会将Pod从svc的ep列表中移除。
若检测Pod服务可用,则会将Pod重新添加到svc的ep列表中。
如果容器没有提供可用性检查,则默认状态为Success。
探针检测Pod服务方式
主要参数
initialDelaySeconds
表示容器启动后,等待多少时间之后再启动各类探针periodSeconds
表示探针执行检测的间隔时间timeoutSeconds
表示探针执行检测的超时后的等待时间successThreshold
表示探针执行检测失败之后,如果容器状态想再次被标记为健康,至少需要经过多少次连续成功检测failureThreshold
表示探针执行检测时,连续失败多少次,容器状态就会被确认不健康
HTTP GET
针对容器指定 URL 执行 HTTP 请求,如果响应码 Status Code 是 2xx 或者 3xx, 将应用标记为正常运行。否则将应用标记为不健康。
apiVersion: v1
kind: Pod
metadata:name: http-get-probe-example
spec:containers:- name: nginximage: nginx:latestports:- containerPort: 80livenessProbe:httpGet:path: /healthz # 健康检查路径port: 80 # 容器端口scheme: HTTP # 可选 HTTP/HTTPSinitialDelaySeconds: 5 # 容器启动后 5s 开始探测periodSeconds: 10 # 每 10s 探测一次timeoutSeconds: 2 # 超时时间 2sfailureThreshold: 3 # 连续失败 3 次后重启容器readinessProbe:httpGet:path: /port: 80initialDelaySeconds: 2periodSeconds: 5
TCP
针对容器指定端口号发起 TCP 连接,如果连接成功,将应用标记为正常运行。否则将应用标记为不健康。
该方法主要针对 HTTP 探针或命令探针无法运行的情况,例如 gRPC 或 FTP 等协议。
apiVersion: v1
kind: Pod
metadata:name: tcp-probe-example
spec:containers:- name: redisimage: redis:latestports:- containerPort: 6379livenessProbe:tcpSocket:port: 6379 # 检测 Redis 默认端口initialDelaySeconds: 15periodSeconds: 20readinessProbe:tcpSocket:port: 6379initialDelaySeconds: 5periodSeconds: 10
Exec
在容器内执行任意命令 (例如文件检查、网络检查),并检查命令的退出状态码,如果状态码为 0,将应用标记为正常运行。否则将应用标记为不健康。
适用场景:
- 检查文件是否存在(如
test -f /tmp/healthy)。 - 运行脚本检测服务状态(如
curl localhost:8080)。 - 数据库健康检查(如
mysqladmin ping)。
apiVersion: v1
kind: Pod
metadata:name: exec-probe-example
spec:containers:- name: myappimage: busybox:latestcommand: ["/bin/sh", "-c", "touch /tmp/healthy && sleep 3600"]livenessProbe:exec:command:- cat- /tmp/healthy # 如果文件存在,返回 0(健康)initialDelaySeconds: 5periodSeconds: 5readinessProbe:exec:command:- sh- -c- "nc -z localhost 8080 || exit 1" # 检查本地 8080 端口是否可连接initialDelaySeconds: 2periodSeconds: 3
最佳实践
启动探针
如果应用的启动时间过长,应该设置一个启动探针,并且==将 initialDelaySeconds 参数的值设置为大于应用的启动时间,==应用启动时, 不应该因为数据库等依赖项尚未就绪而崩溃,例如应该在连接失败后继续尝试重新连接,直到连接成功或者重试次数超出最大限制。
initialDelaySeconds 参数的取值可以参考监控中的应用启动时间 P99 分位值。
启动探针常用业务场景:
- 数据库连接池初始化完成
- 缓存连接池初始化完成
- 热点数据缓存在本地初始化完成
还有一种做法是,直接将 initialDelaySeconds 参数值设置为大于应用启动的估计时长,不使用启动探针。
存活探针
如果应用在发生鼓掌时无法自动结束退出 (例如遇到了死锁),应该设置一个存活探针,并指定 restartPolicy 为 “Always” 或 “OnFailure”, 这样该应用会被重启。
就绪探针
如果需要应用在完成初始化工作之后才能开始接收流量,应该设置一个就绪探针,这样可以避免流量进入到错误到 Pod 中。
就绪探针可能与存活探针相同,但是 就绪探针表示 Pod 在初始化阶段不接收任何流量,并且只有就绪探针返回成功后再开始接收流量, 虽然使用启动探针也可以完成同样的功能,但是就绪探针可以区分应用位于 “正在启动中” 和 “已经完成启动,正在当前状态是正常|失败” 两个不同的阶段中的哪一个。
小结
就绪探针和存活探针可以同时用于同一 Pod,这样可以确保流量无法到达未准备好的 Pod,并且在探针检测失败时重启。
五、容器的重启策略
容器程序发生崩溃或容器申请超过限制的资源等原因都可能会导致 Pod 对象的终止,此时是否应该重建该 Pod 对象则取决于其重启策略(restartPolicy)属性的定义。
-
Always:但凡 Pod 对象终止就将其重启,此为默认设定。
-
OnFailure:仅在 Pod 对象出现错误时方才能将其重启。
-
Nerver:从不重启
restartPolicy 适用于 Pod 对象中的所有容器,而且它仅用于控制在同一节点上重新启动 Pod 对象的相关容器。
首次需要重启的容器,将在其需要时立即进行重启,随后再次需要重启的操作由 kubelet 延迟一段时间后进行,且反复的重启操作的延迟时长依次为 10秒、20秒、40秒、80秒、160秒 和 300秒,300秒是最大延迟时长。
Pod 一旦绑定到一个节点,Pod对象将永远不会被重新绑定到另一个点,它要么被重启,要么终止,直到节点发生故障或被删除。
六、pod终止流程
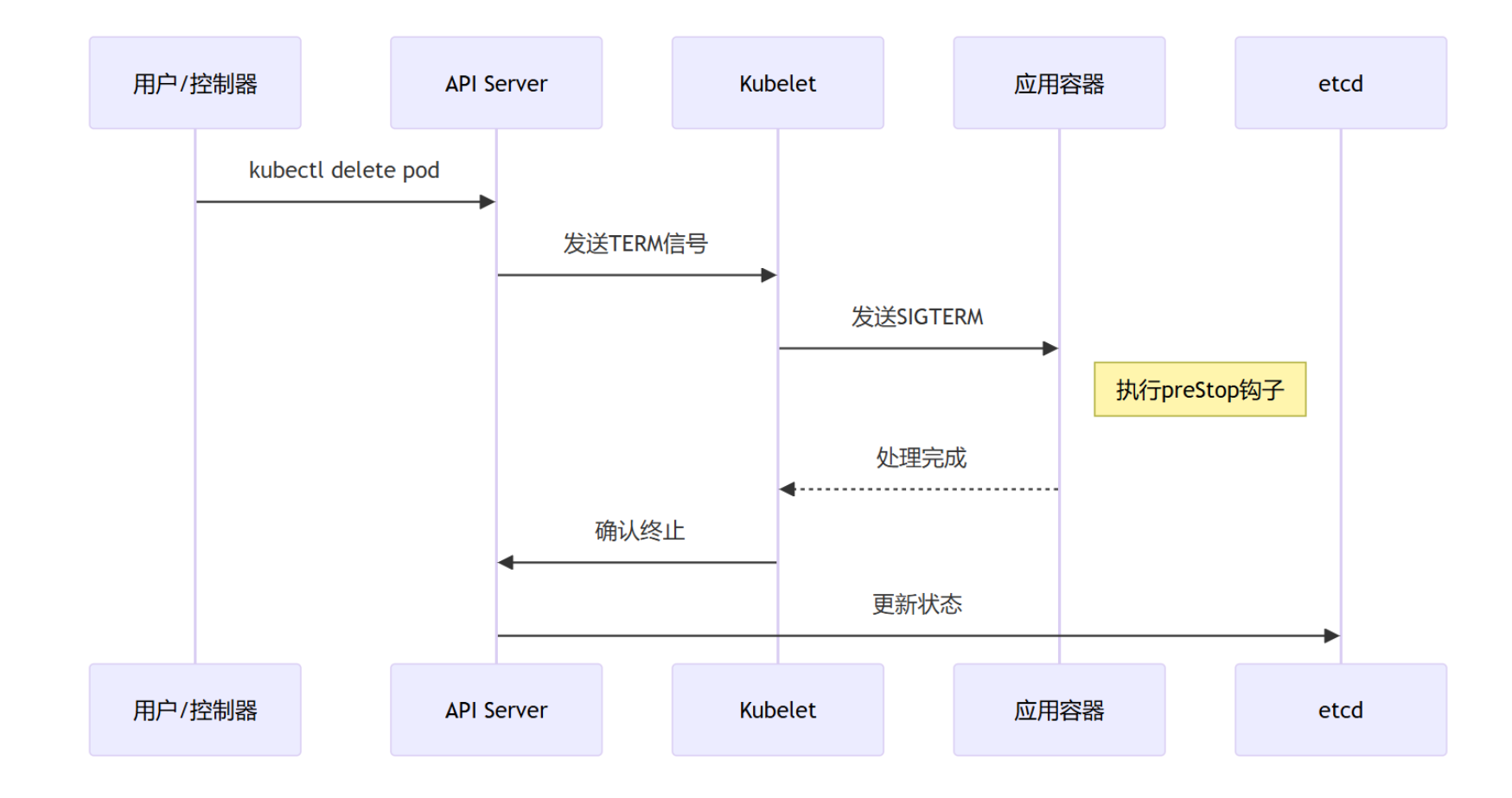
- 用户发出删除 pod 命令:kubectl delete pods ,kubectl delete -f yaml
- Pod 对象随着时间的推移更新,在宽限期(默认情况下30秒),pod 被视为“dead”状态
- pod 标记为“Terminating”状态
- 第三步同时运行,监控到 pod 对象为“Terminating”状态的同时启动 pod 关闭过程
- 第三步同时进行,endpoints 控制器监控到 pod 对象关闭,将pod与service匹配的 endpoints 列表中删除
- 如果 pod 中定义了 preStop 钩子处理程序,则 pod 被标记为“Terminating”状态时以同步的方式启动执行;若宽限期结束后,
- preStop 仍未执行结束,第二步会重新执行并额外获得一个2秒的小宽限期
- Pod 内对象的容器收到 TERM 信号
- 宽限期结束之后,若存在任何一个运行的进程,pod 会收到 SIGKILL 信号
- Kubelet 请求 API Server 将此 Pod 资源宽限期设置为0从而完成删除操作
七、优雅终止
Pod 优雅关闭就是在容器被停止时,确保容器内的进程有足够的时间完成当前的任务,并且做必要的清理工作。这样可以避免因强制停止容器而导致的数据丢失、资源泄漏等问题。
具体来说,Kubernetes 会发送一个 SIGTERM 信号给容器,让容器进行自定义的清理工作。如果容器在指定时间内没有正常退出,Kubernetes 会发出 SIGKILL 强制终止容器。
优雅关闭的步骤:
- 收到 SIGTERM 信号:容器收到停止信号,应该开始优雅关闭。
- 等待 terminationGracePeriodSeconds 时间:容器会有一段时间来进行清理工作,这个时间段可以自定义。
- 执行 preStop 钩子:如果配置了 preStop 钩子,它会在 SIGTERM 信号发送后立刻执行。
- 完成清理并退出:容器完成清理工作后退出。
- 超时后发送 SIGKILL:如果容器在规定时间内没有正常退出,Kubernetes 会强制终止它。
如何配置 Pod 的优雅关闭?
关键点:
terminationGracePeriodSeconds:控制容器关闭时的最大等待时间。
preStop钩子:容器关闭前执行的命令,帮助我们在容器退出前完成清理工作。
1.配置 terminationGracePeriodSeconds
控制容器关闭时的最大等待时间。
这是控制 Pod 在关闭时等待的时间。默认情况下是 30 秒,即容器会在收到 SIGTERM 信号后有 30 秒的时间来优雅退出。你可以通过 terminationGracePeriodSeconds 来修改这个时间。
示例:设置优雅关闭时间为 60 秒
apiVersion: v1
kind: Pod
metadata:name: mypod
spec:terminationGracePeriodSeconds: 60 # 设置优雅关闭时间为 60 秒containers:- name: my-containerimage: my-image
- 使用
preStop钩子
preStop 钩子是一个非常有用的特性,它允许你在容器关闭前执行自定义的脚本或命令,帮助你完成一些清理工作。比如,可以在容器关闭前断开数据库连接、保存临时文件等。
示例:配置 preStop 钩子
apiVersion: v1
kind: Pod
metadata:name: mypod
spec:terminationGracePeriodSeconds: 60containers:- name: my-containerimage: my-imagelifecycle:preStop:exec:command: ["/bin/sh", "-c", "echo 'Stopping container...'; sleep 10"]
自定义的脚本或命令,帮助你完成一些清理工作。比如,可以在容器关闭前断开数据库连接、保存临时文件等。
示例:配置 preStop 钩子
apiVersion: v1
kind: Pod
metadata:name: mypod
spec:terminationGracePeriodSeconds: 60containers:- name: my-containerimage: my-imagelifecycle:preStop:exec:command: ["/bin/sh", "-c", "echo 'Stopping container...'; sleep 10"]