第1.2讲、从 RNN 到 LSTM 再到 Self-Attention:深度学习中序列建模的演进之路
处理序列数据(如文本、语音、时间序列)一直是深度学习的重要课题。在这个领域中,我们从 RNN(Recurrent Neural Network)出发,经历了 LSTM(Long Short-Term Memory)的改进,最终发展到了当今大放异彩的 Self-Attention(自注意力机制)。本文将带你理解它们的概念、工作原理、优缺点,并分析这一演进路径的必然性。
一、RNN:循环神经网络的起点
✅ 概念
RNN 是一种擅长处理序列数据的神经网络结构,其设计核心是:当前的输出不仅取决于当前的输入,还依赖于前一时刻的隐藏状态(记忆)。这让模型具备了“记忆能力”。

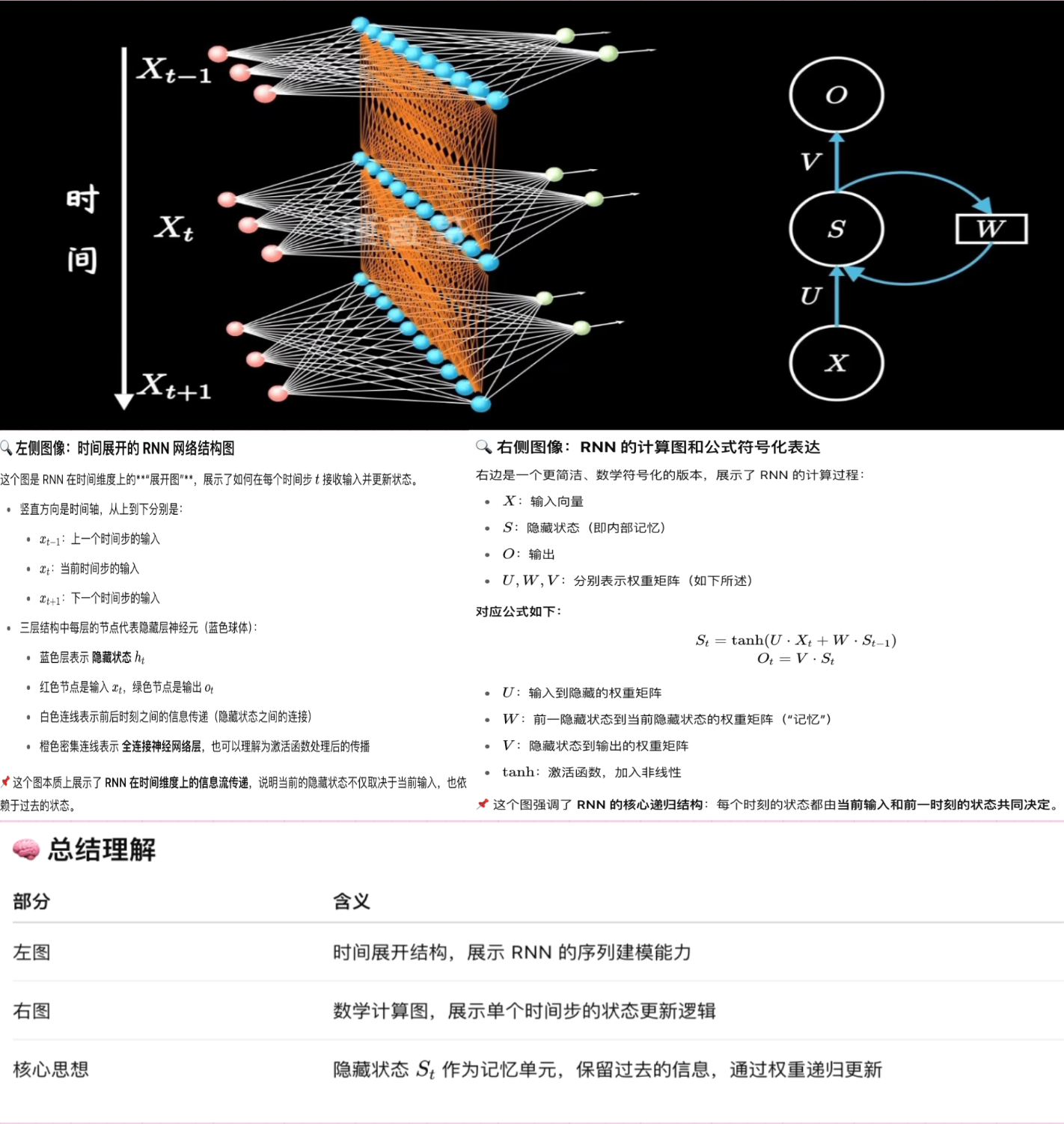
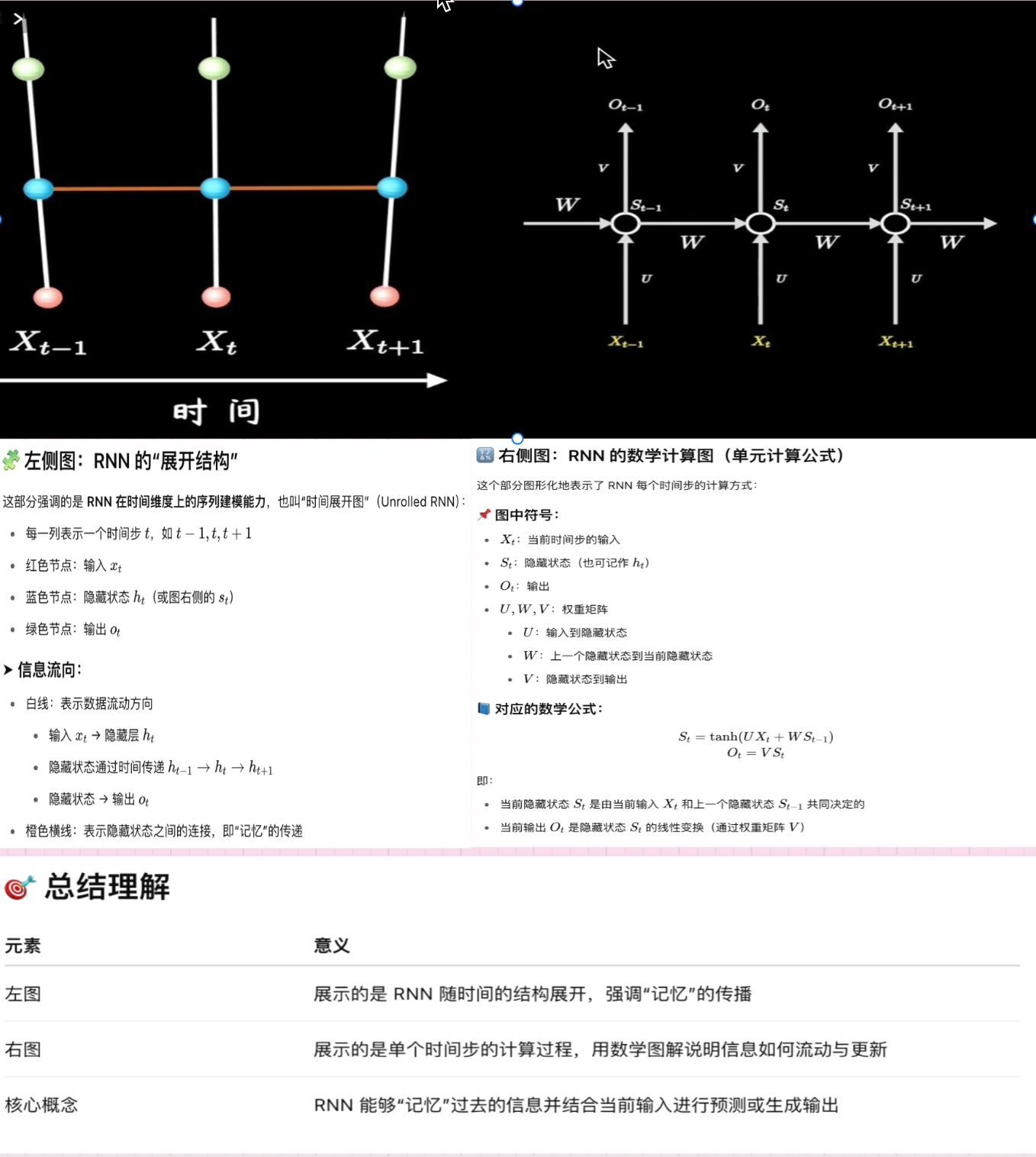
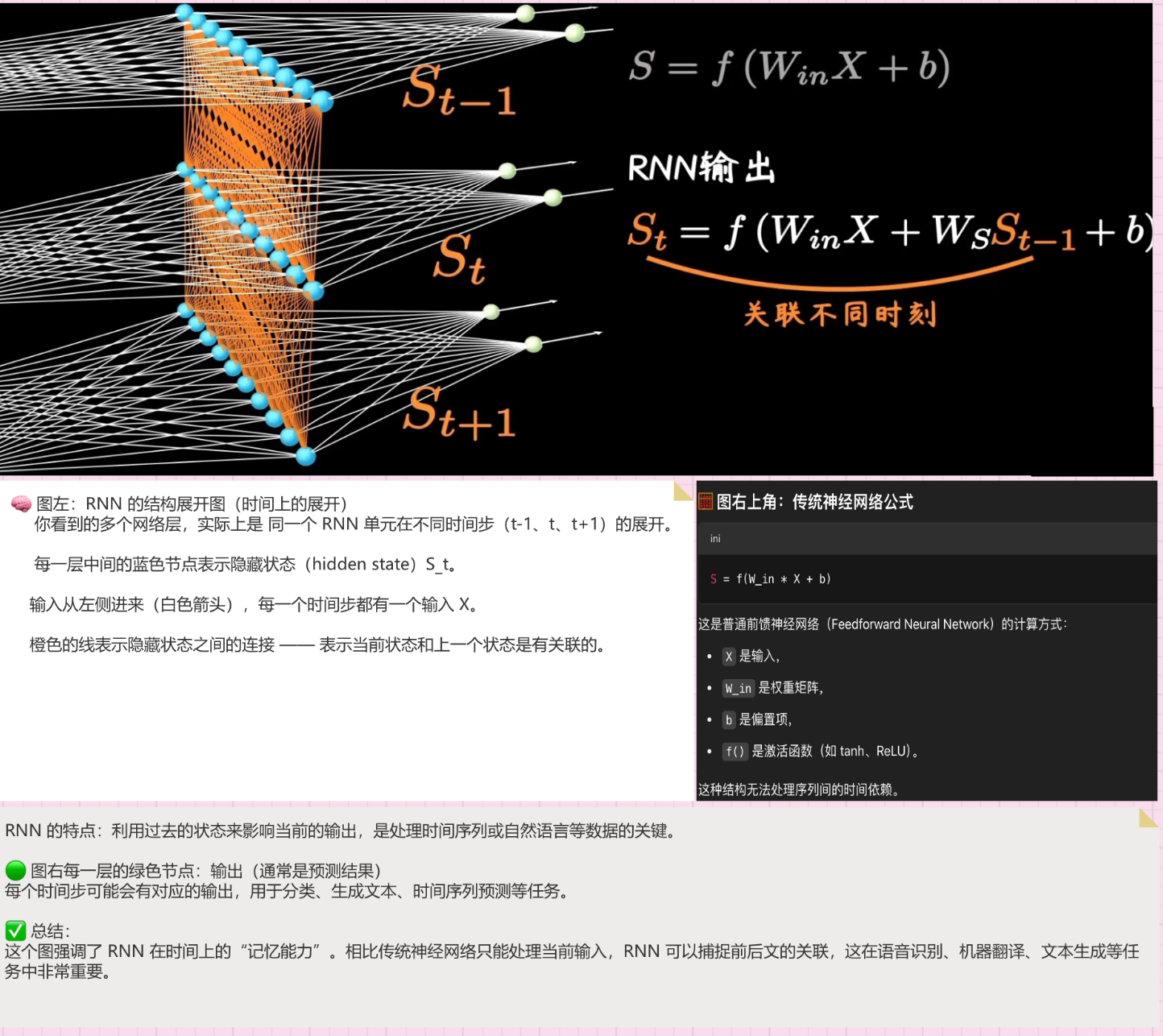
✅ 优点
- 简单,结构直观,易于实现。
- 能够处理变长输入的序列任务。
❌ 缺点
- 梯度消失/爆炸:长序列训练时,梯度可能变得非常小或非常大,导致学习失败。
- 长期依赖困难:模型很难保留远距离的信息,比如一个句首的名词对句尾动词的影响。
- 序列必须逐步处理,无法并行,导致训练速度慢。
✅ 应用场景
- 文本分类、语言模型、机器翻译、语音识别、对话系统、推荐系统等。
####案例代码:文本生成
import streamlit as st
import graphviz
import torch
import torch.nn as nn
import torch.optim as optim
from collections import Counter
import matplotlib.pyplot as plt
import re# ========== 文本清洗 ==========
# 清洗文本,只保留中文、标点和空格
# 输入:原始文本字符串
# 输出:清洗后的文本字符串
def clean_text(text):text = re.sub(r'[^\u4e00-\u9fa5。,!?\s]', '', text) # 保留中文、标点和空格text = re.sub(r'\s+', ' ', text)return text.strip()# ========== Tokenizer 和词表 ==========
# 分词函数,将文本按空格分割为词列表
def tokenize(text):return text.split()# 构建词表,统计词频,限制最大词表大小
def build_vocab(tokens, max_vocab_size=5000):counter = Counter(tokens)most_common = counter.most_common(max_vocab_size - 2)idx2word = ['<PAD>', '<UNK>'] + [word for word, _ in most_common]word2idx = {word: idx for idx, word in enumerate(idx2word)}return word2idx, idx2word# ========== 模型定义 ==========
# 定义词级RNN模型
class WordRNN(nn.Module):def __init__(self, vocab_size, embed_size=128, hidden_size=256):super().__init__()self.embed = nn.Embedding(vocab_size, embed_size) # 词嵌入层self.rnn = nn.RNN(embed_size, hidden_size, batch_first=True) # RNN层self.fc = nn.Linear(hidden_size, vocab_size) # 输出层def forward(self, x, h=None):x = self.embed(x)out, h = self.rnn(x, h)out = self.fc(out)return out, h# ========== 文本生成 ==========
# 根据起始词生成指定长度的文本
def generate_text(model, word2idx, idx2word, start_word, length=30):model.eval() # 设置为评估模式idx = torch.tensor([[word2idx.get(start_word, word2idx['<UNK>'])]])result = [start_word]hidden = Nonefor _ in range(length):out, hidden = model(idx, hidden)prob = torch.softmax(out[0, -1], dim=0) # 取最后一个时间步的输出并softmaxidx = torch.multinomial(prob, 1).unsqueeze(0) # 按概率采样下一个词word = idx2word[idx.item()]result.append(word)return ''.join(result)# ========== Streamlit UI ==========
# 设置Streamlit页面配置
st.set_page_config(page_title="词级中文文本生成器", layout="centered")
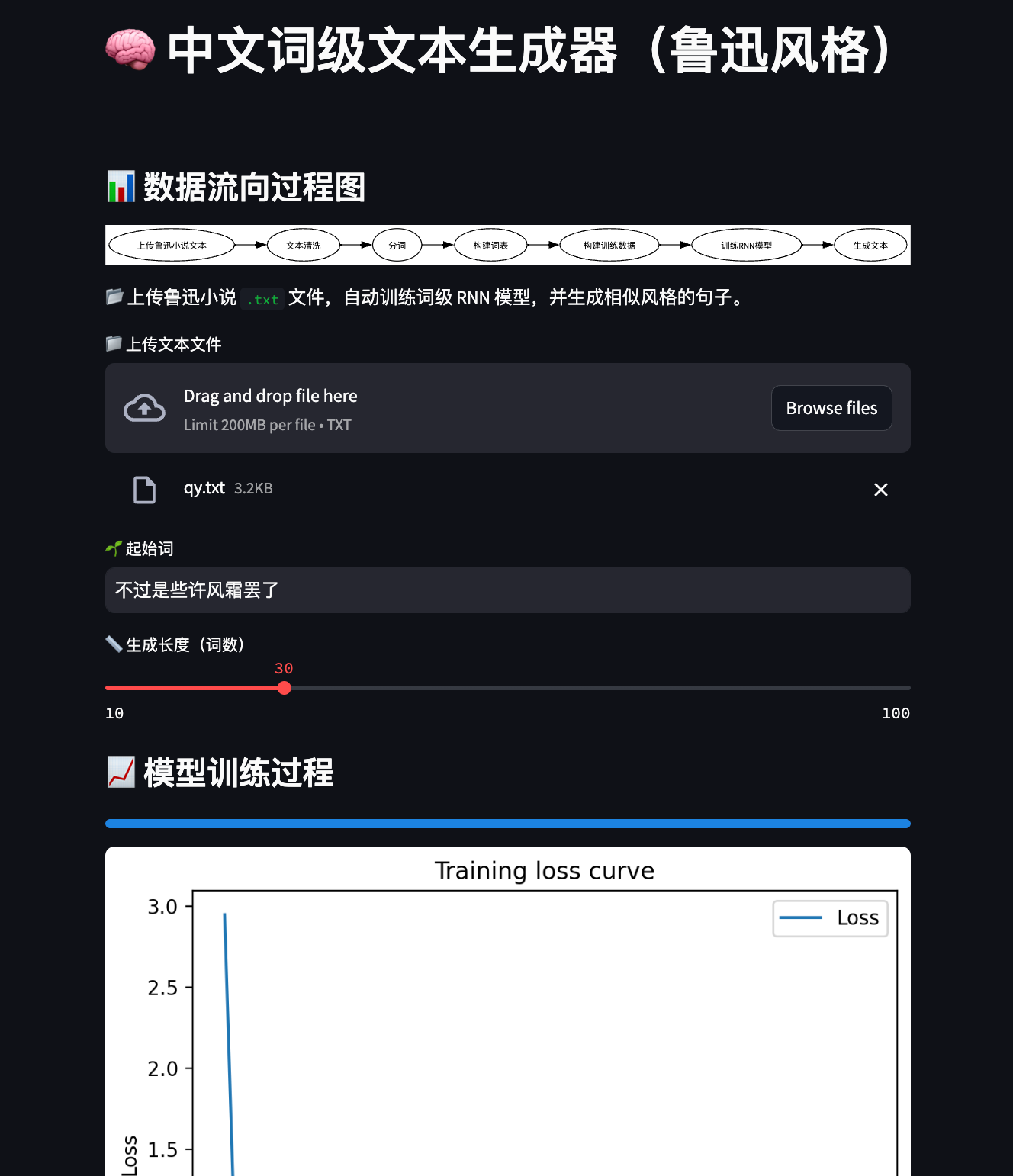
st.title("🧠 中文词级文本生成器(鲁迅风格)")
# ========== 数据流向过程图 ==========
st.subheader("📊 数据流向过程图")
flow_chart = graphviz.Digraph(format="png")
flow_chart.attr(rankdir="LR") # 从左到右flow_chart.node("A", "上传鲁迅小说文本")
flow_chart.node("B", "文本清洗")
flow_chart.node("C", "分词")
flow_chart.node("D", "构建词表")
flow_chart.node("E", "构建训练数据")
flow_chart.node("F", "训练RNN模型")
flow_chart.node("G", "生成文本")flow_chart.edges([("A", "B"),("B", "C"),("C", "D"),("D", "E"),("E", "F"),("F", "G"),
])
st.graphviz_chart(flow_chart)
st.markdown("📂 上传鲁迅小说 `.txt` 文件,自动训练词级 RNN 模型,并生成相似风格的句子。")# 文件上传控件
uploaded_file = st.file_uploader("📁 上传文本文件", type="txt")
# 起始词输入框
start_word = st.text_input("🌱 起始词", value="我")
# 生成长度滑块
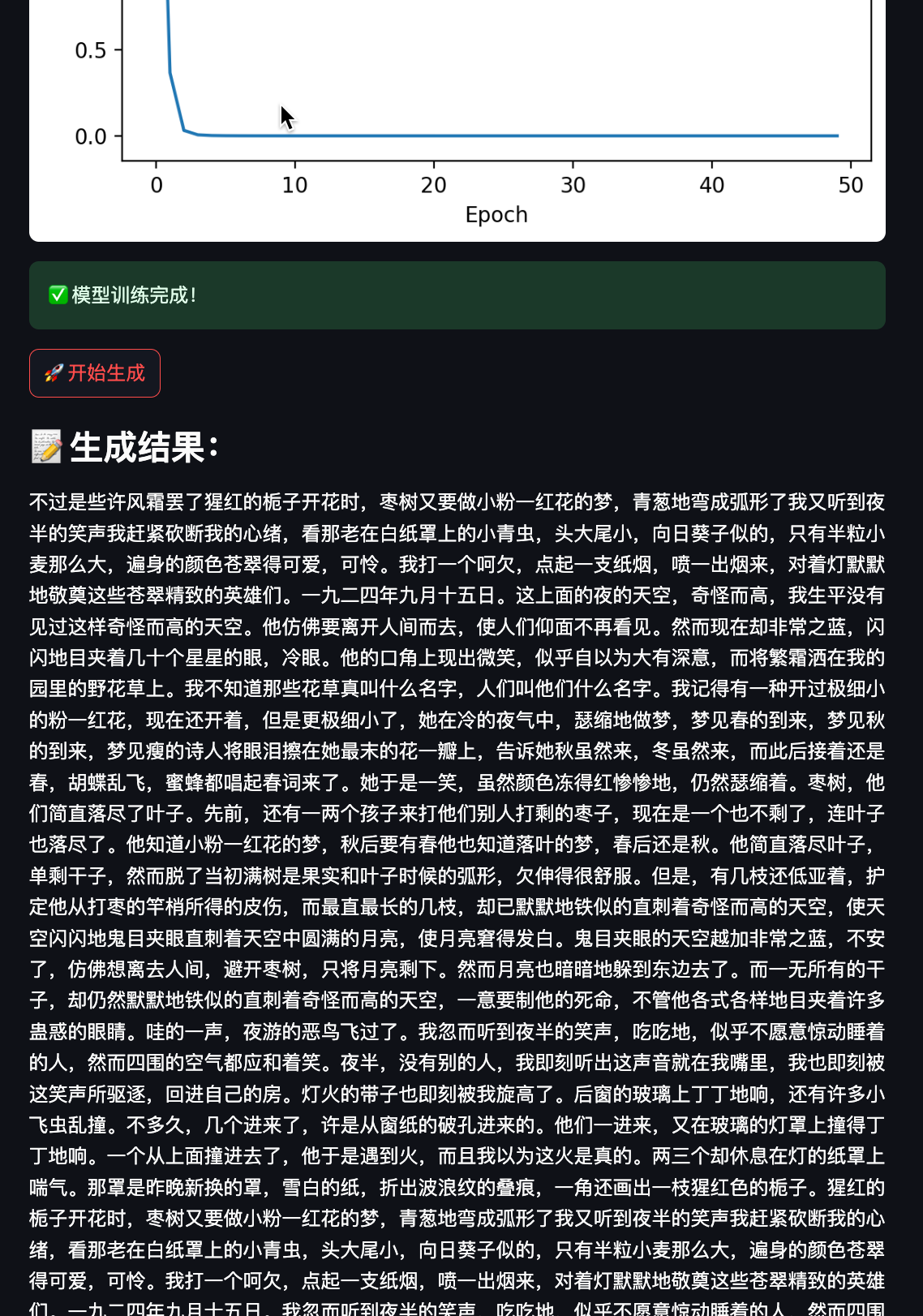
length = st.slider("📏 生成长度(词数)", 10, 100, 30)if uploaded_file:# 读取并清洗文本raw_text = uploaded_file.read().decode("utf-8")cleaned_text = clean_text(raw_text)tokens = tokenize(cleaned_text)# 限制最大词数,加速预览max_tokens = 1000tokens = tokens[:max_tokens]# 构建词表word2idx, idx2word = build_vocab(tokens)vocab_size = len(word2idx)# 构建训练数据(输入序列和目标序列)seq_input = [word2idx.get(w, word2idx['<UNK>']) for w in tokens[:-1]]seq_target = [word2idx.get(w, word2idx['<UNK>']) for w in tokens[1:]]input_tensor = torch.tensor(seq_input).unsqueeze(0)target_tensor = torch.tensor(seq_target).unsqueeze(0)# 初始化模型、损失函数和优化器model = WordRNN(vocab_size)loss_fn = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.01)# 展示训练过程st.subheader("📈 模型训练过程")loss_list = []progress_bar = st.progress(0)loss_chart = st.empty()num_epochs = 50 # 训练轮数for epoch in range(num_epochs):model.train()optimizer.zero_grad()output, _ = model(input_tensor)loss = loss_fn(output.view(-1, vocab_size), target_tensor.view(-1))loss.backward()optimizer.step()loss_list.append(loss.item())progress_bar.progress((epoch + 1) / num_epochs)# 每轮画一次loss曲线if epoch % 1 == 0:fig, ax = plt.subplots()ax.plot(loss_list, label='Loss')ax.set_xlabel("Epoch")ax.set_ylabel("Loss")ax.set_title("Training loss curve")ax.legend()loss_chart.pyplot(fig)st.success("✅ 模型训练完成!")# 生成文本按钮if st.button("🚀 开始生成"):result = generate_text(model, word2idx, idx2word, start_word, length)st.subheader("📝 生成结果:")st.write(result)
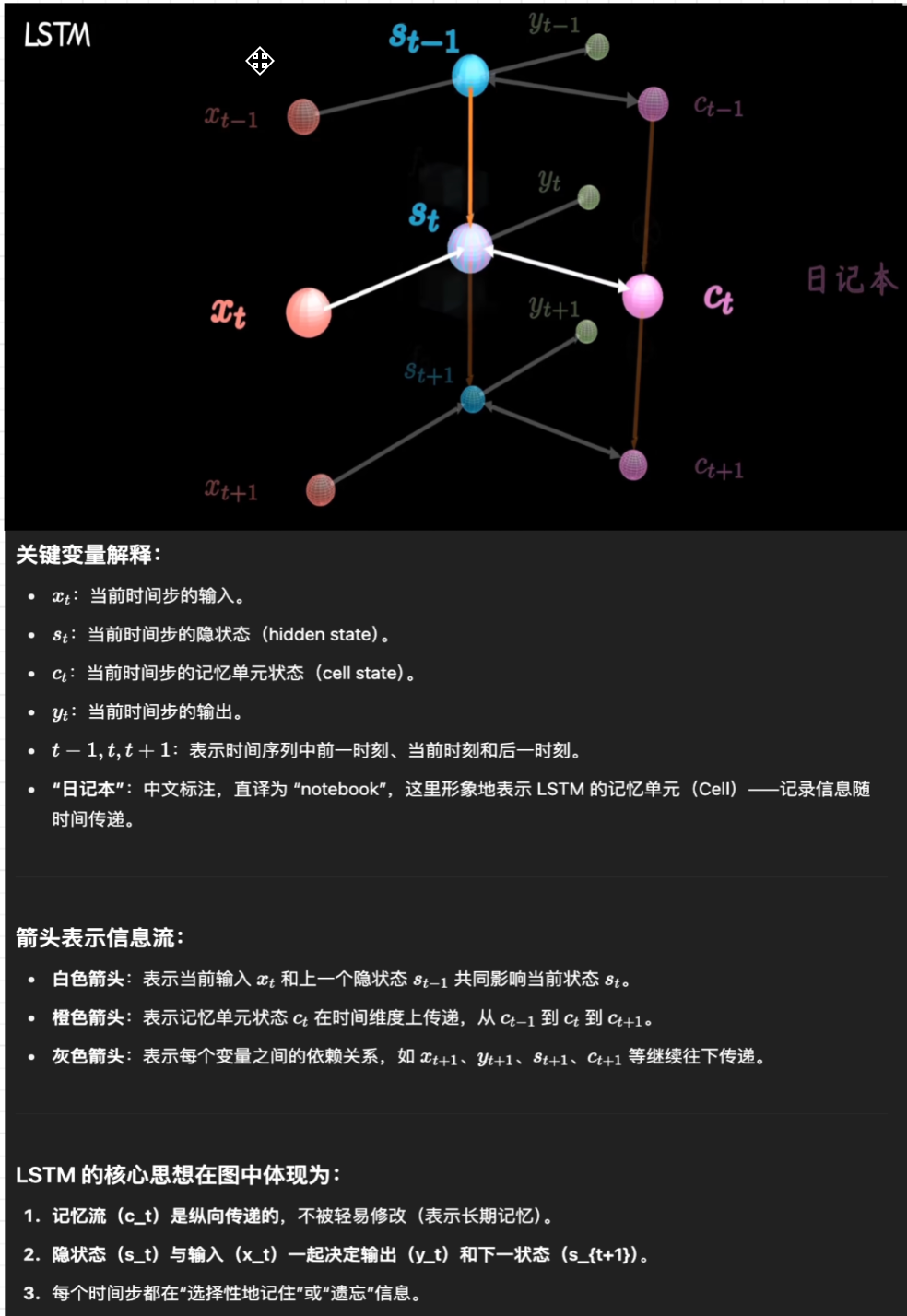
二、LSTM:为记忆加上“门”的改良版 RNN
✅ 概念
LSTM 是为了解决 RNN 长期依赖问题而提出的。它通过门控机制(门=控制信息流)来保留有用信息,遗忘无用信息,从而实现长期记忆的存储与更新。

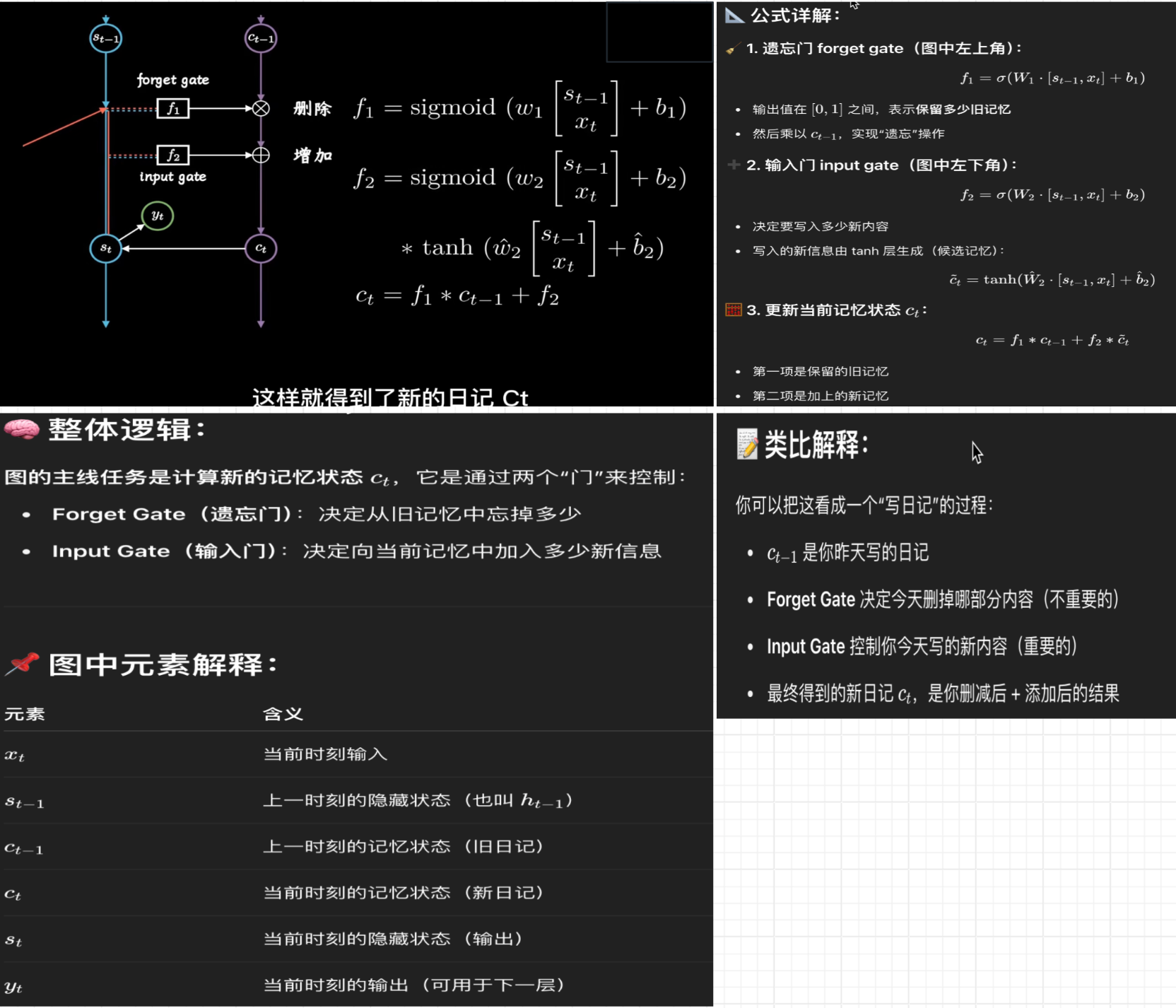
✅ 优点
- 解决了 RNN 的长期依赖问题。
- 更容易捕捉复杂的序列结构。
❌ 缺点
- 结构复杂,计算量大,训练较慢。
- 同样存在串行依赖问题:必须一个时刻一个时刻地处理,无法并行。
✅ 应用场景
- 文本分类、语言模型、机器翻译、语音识别、对话系统、推荐系统等。
####案例代码:文本生成
import streamlit as st
import graphviz
import torch
import torch.nn as nn
import torch.optim as optim
from collections import Counter
import matplotlib.pyplot as plt
import re
import os
import tempfile# ========== 文本清洗 ==========
# 清洗文本:保留中文、标点、空格
# 该函数用于清洗输入文本,只保留中文字符、常用标点和空格def clean_text(text):text = re.sub(r'[^00-\u9fa5。,!?\s]', '', text)text = re.sub(r'\s+', ' ', text)return text.strip()# ========== Tokenizer 和词表 ==========
# 分词
# 该函数将文本按空格分割为词def tokenize(text):return text.split()# 构建词表
# 统计词频,生成词到索引和索引到词的映射def build_vocab(tokens, max_vocab_size=5000):counter = Counter(tokens)most_common = counter.most_common(max_vocab_size - 2)idx2word = ['<PAD>', '<UNK>'] + [word for word, _ in most_common]word2idx = {word: idx for idx, word in enumerate(idx2word)}return word2idx, idx2word# ========== 模型定义 ==========
# 构建词级模型,支持 RNN / LSTM / GRU
# WordRNN 类用于定义词级循环神经网络模型
class WordRNN(nn.Module):def __init__(self, vocab_size, embed_size=128, hidden_size=256, rnn_type='RNN'):super().__init__()self.embed = nn.Embedding(vocab_size, embed_size) # 词嵌入层if rnn_type == 'LSTM':self.rnn = nn.LSTM(embed_size, hidden_size, batch_first=True) # LSTMelif rnn_type == 'GRU':self.rnn = nn.GRU(embed_size, hidden_size, batch_first=True) # GRUelse:self.rnn = nn.RNN(embed_size, hidden_size, batch_first=True) # RNNself.rnn_type = rnn_typeself.fc = nn.Linear(hidden_size, vocab_size) # 输出层def forward(self, x, h=None):x = self.embed(x)out, h = self.rnn(x, h)out = self.fc(out)return out, h# ========== 文本生成 ==========
# 用训练好的模型生成文本
# 该函数根据起始词和长度,利用模型生成文本def generate_text(model, word2idx, idx2word, start_word, length=30, temperature=1.0):model.eval()idx = torch.tensor([[word2idx.get(start_word, word2idx['<UNK>'])]])result = [start_word]hidden = Nonefor _ in range(length):out, hidden = model(idx, hidden)logits = out[0, -1] / temperatureprob = torch.softmax(logits, dim=0)idx = torch.multinomial(prob, 1).unsqueeze(0)word = idx2word[idx.item()]result.append(word)return ''.join(result)# ========== Streamlit UI ==========
# Streamlit 页面设置和流程图展示
st.set_page_config(page_title="词级中文文本生成器", layout="centered")
st.title("\U0001F9E0 中文词级文本生成器(鲁迅风格)")st.subheader("\U0001F4CA 数据流向过程图")
flow_chart = graphviz.Digraph(format="png")
flow_chart.attr(rankdir="LR")
flow_chart.node("A", "上传鲁迅小说文本")
flow_chart.node("B", "文本清洗")
flow_chart.node("C", "分词")
flow_chart.node("D", "构建词表")
flow_chart.node("E", "构建训练数据")
flow_chart.node("F", "训练***模型")
flow_chart.node("G", "生成文本")
flow_chart.edges([("A", "B"), ("B", "C"), ("C", "D"), ("D", "E"), ("E", "F"), ("F", "G")])
st.graphviz_chart(flow_chart)
st.markdown("\U0001F4C2 上传鲁迅小说 `.txt` 文件,自动训练词级 *** 模型,并生成相似风格的句子。")# 多文件上传
# 支持上传多个文本文件
uploaded_files = st.file_uploader("\U0001F4C1 上传文本文件(可多选)", type="txt", accept_multiple_files=True)# 生成文本的起始词和长度
start_word = st.text_input("\U0001F331 起始词", value="我")
length = st.slider("\U0001F4CF 生成长度(词数)", 10, 100, 30)# ========== 超参数设置 ==========
# 侧边栏设置模型超参数
st.sidebar.header("\U0001F527 模型设置")
rnn_type = st.sidebar.selectbox("选择模型类型", ["RNN", "LSTM", "GRU"], index=0)
embed_size = st.sidebar.slider("词嵌入维度", 64, 512, 128, step=32)
hidden_size = st.sidebar.slider("隐藏层大小", 64, 512, 256, step=32)
num_epochs = st.sidebar.slider("训练轮数", 10, 200, 50, step=10)
learning_rate = st.sidebar.select_slider("学习率", options=[0.001, 0.005, 0.01, 0.02, 0.05], value=0.01)# 保存路径根据模型类型区分
model_save_path = f"luxun_{rnn_type.lower()}_model.pt"if uploaded_files:# 拼接多个文本文件raw_text = ''.join([file.read().decode("utf-8") for file in uploaded_files])cleaned_text = clean_text(raw_text) # 文本清洗tokens = tokenize(cleaned_text) # 分词tokens = tokens[:1000] # 限制长度,防止内存溢出word2idx, idx2word = build_vocab(tokens) # 构建词表vocab_size = len(word2idx)# 构建训练输入输出序列seq_input = [word2idx.get(w, word2idx['<UNK>']) for w in tokens[:-1]]seq_target = [word2idx.get(w, word2idx['<UNK>']) for w in tokens[1:]]input_tensor = torch.tensor(seq_input).unsqueeze(0)target_tensor = torch.tensor(seq_target).unsqueeze(0)# 初始化模型model = WordRNN(vocab_size, embed_size, hidden_size, rnn_type)optimizer = optim.Adam(model.parameters(), lr=learning_rate)loss_fn = nn.CrossEntropyLoss()# 加载已有模型(断点训练),需判断结构是否匹配if os.path.exists(model_save_path):try:model.load_state_dict(torch.load(model_save_path))st.info("已加载已保存的模型参数,继续训练...")except RuntimeError as e:st.warning(f"⚠️ 模型结构变更,未加载已有模型参数。\n{str(e).splitlines()[0]}")st.subheader("\U0001F4C8 模型训练过程")loss_list = []progress_bar = st.progress(0)loss_chart = st.empty()# 训练主循环for epoch in range(num_epochs):model.train()optimizer.zero_grad()output, _ = model(input_tensor)loss = loss_fn(output.view(-1, vocab_size), target_tensor.view(-1))loss.backward()optimizer.step()loss_list.append(loss.item())progress_bar.progress((epoch + 1) / num_epochs)# 实时绘制损失曲线fig, ax = plt.subplots()ax.plot(loss_list, label='Loss')ax.set_xlabel("Epoch")ax.set_ylabel("Loss")ax.set_title("Training loss curve")ax.legend()loss_chart.pyplot(fig)# 保存模型参数torch.save(model.state_dict(), model_save_path)st.success("✅ 模型训练完成,已保存到本地!")# 生成文本并提供下载if st.button("\U0001F680 开始生成"):result = generate_text(model, word2idx, idx2word, start_word, length)st.subheader("\U0001F4DD 生成结果:")st.write(result)# 保存生成结果为临时文件供下载with tempfile.NamedTemporaryFile(delete=False, suffix=".txt", mode="w", encoding="utf-8") as tmpfile:tmpfile.write(result)tmpfile_path = tmpfile.namewith open(tmpfile_path, "rb") as f:st.download_button("⬇️ 下载生成文本", f, file_name="generated_text.txt", mime="text/plain")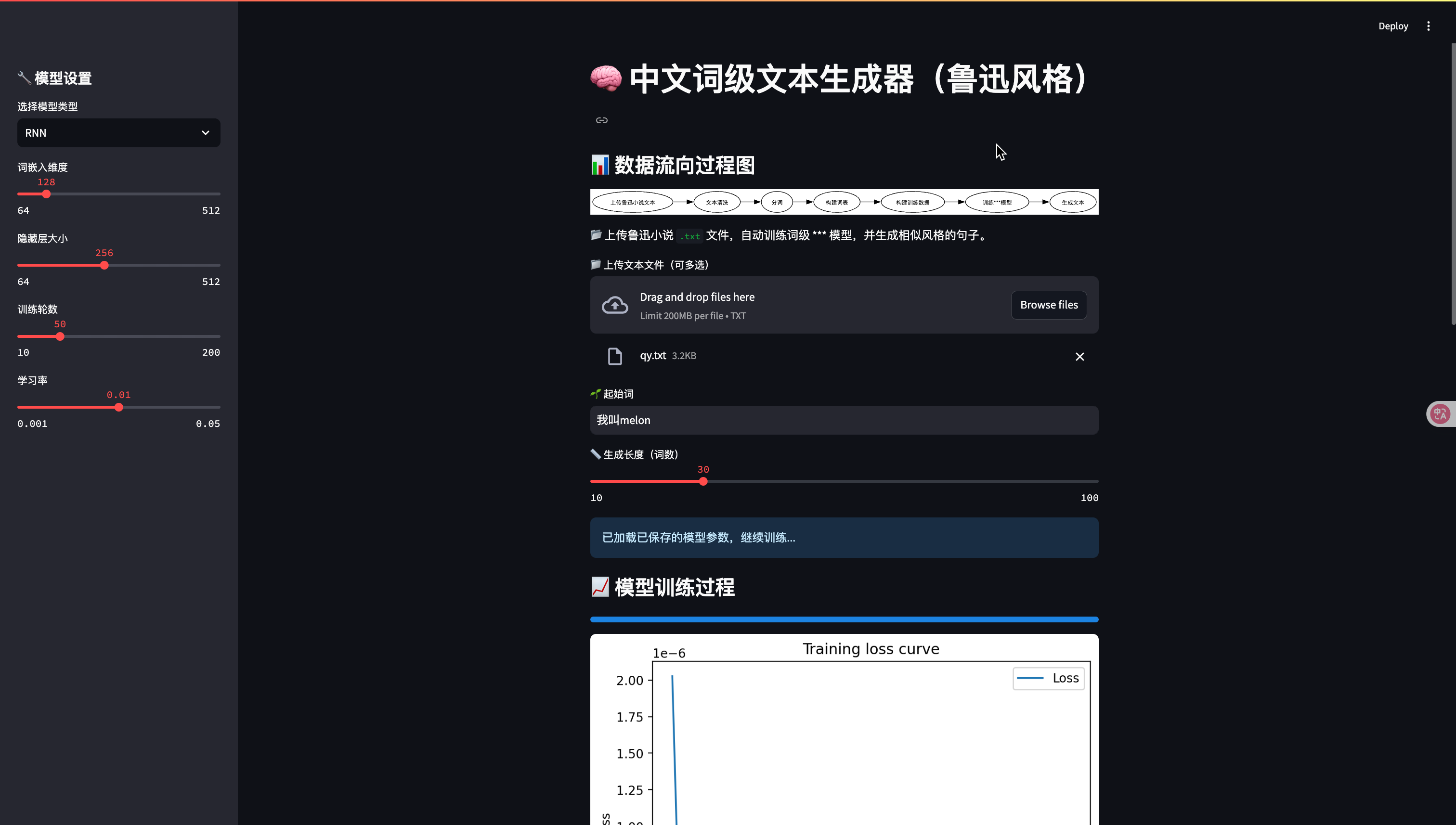
三、Self-Attention:打破顺序限制的序列建模方式
✅ 概念
在一个序列中,每个词作为 Query 同时也是 Key 和 Value。
用于捕捉句子内部不同位置之间的关系。
举个例子:对于句子 “The cat sat on the mat”,每个词都可以看到整个句子,包括它自己。
Self-Attention 是一种机制,它允许模型在处理每个词或时间步时关注序列中的其他所有位置。它完全摒弃了“隐藏状态”的串行传递方式,而是通过注意力权重计算全局信息。
它是 Transformer 模型的核心模块,也是当前 NLP(如 GPT、BERT)主流架构的基础。

✅ 优点
- 全局感知能力强,可以建模任意位置间的依赖关系。
- 支持并行计算,极大提升训练效率。
- 在大型语料预训练(如 GPT/BERT)中表现出色。
❌ 缺点
- 对长序列的计算复杂度高( O ( n 2 ) O(n^2) O(n2)),会占用大量内存。
- 缺乏天然的位置信息(需手动加 positional encoding)。
####案例代码
import streamlit as st
import torch
import torch.nn as nn
import torch.nn.functional as F
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
from transformers import BertTokenizer, BertModel# ----------------------------
# Self-Attention Layer
# ----------------------------
class SelfAttention(nn.Module):def __init__(self, embed_dim):super(SelfAttention, self).__init__()self.query = nn.Linear(embed_dim, embed_dim)self.key = nn.Linear(embed_dim, embed_dim)self.value = nn.Linear(embed_dim, embed_dim)self.scale = torch.sqrt(torch.tensor(embed_dim, dtype=torch.float32))def forward(self, x):Q = self.query(x)K = self.key(x)V = self.value(x)attn_scores = torch.bmm(Q, K.transpose(1, 2)) / self.scaleattn_weights = F.softmax(attn_scores, dim=-1)out = torch.bmm(attn_weights, V)return out, attn_weights, Q, K, V# ----------------------------
# Streamlit UI
# ----------------------------
st.set_page_config(page_title="Self-Attention 可视化")
st.title("🧠 Self-Attention 中文可视化 Demo")# 用户输入句子
sentence = st.text_input("✏️ 输入一个句子(支持中英文混合):", "A cat relishes fish.")# 加载中文/英文 BERT 模型
#Google 发布的中文版本的 BERT(Bidirectional Encoder Representations from Transformers)模型,
#它是一个预训练的通用语言理解模型
#BERT模型作用:
# 1. 生成上下文相关的中文词向量(Embedding:与传统词向量(如 Word2Vec)不同,BERT 根据上下文动态生成向量# 2、作为下游任务的通用编码器:你可以把 bert-base-chinese 当成一个“理解中文句子”的模块;#3、适配中文文本结构 与英文不同,中文没有空格分词。bert-base-chinese:使用字级别(Character-level)分词(WordPiece)# 专门为中文来设计的
# model_code='bert-base-chinese'
# 混合语言来设计
# model_code='bert-base-multilingual-cased'
# 专门为英文设计
#model_code = 'bert-base-uncased'
@st.cache_resource
def load_model():model_code = 'bert-base-uncased'tokenizer = BertTokenizer.from_pretrained(model_code)model = BertModel.from_pretrained(model_code)return tokenizer, modeltokenizer, bert = load_model()# 编码输入
inputs = tokenizer(sentence, return_tensors="pt")
with torch.no_grad():outputs = bert(**inputs)embeddings = outputs.last_hidden_state # (1, seq_len, hidden_dim)# 去掉 batch 维度
x = embeddings# 实例化 Self-Attention
embed_dim = x.shape[-1]
attn_layer = SelfAttention(embed_dim)
output, weights, Q, K, V = attn_layer(x)# 可视化
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])
weights_matrix = weights[0].detach().numpy()st.subheader("🎯 自注意力权重矩阵")
fig, ax = plt.subplots(figsize=(10, 6))
sns.heatmap(weights_matrix, xticklabels=tokens, yticklabels=tokens, cmap="YlOrBr", annot=True, fmt=".2f", ax=ax)
ax.set_xlabel("Key(followed)")
ax.set_ylabel("Query(viewed)")
st.pyplot(fig)st.subheader("🎯 自注意力权重矩阵表格(部分示意)")
# 取前 N 个 token 可读性更好(可调)
N = min(10, len(tokens))
partial_weights = weights_matrix[:N, :N]
partial_tokens = tokens[:N]# 构建 DataFrame
df_weights = pd.DataFrame(partial_weights, index=partial_tokens, columns=partial_tokens)
df_weights.index.name = "Query\\Key"st.dataframe(df_weights.style.format(precision=2))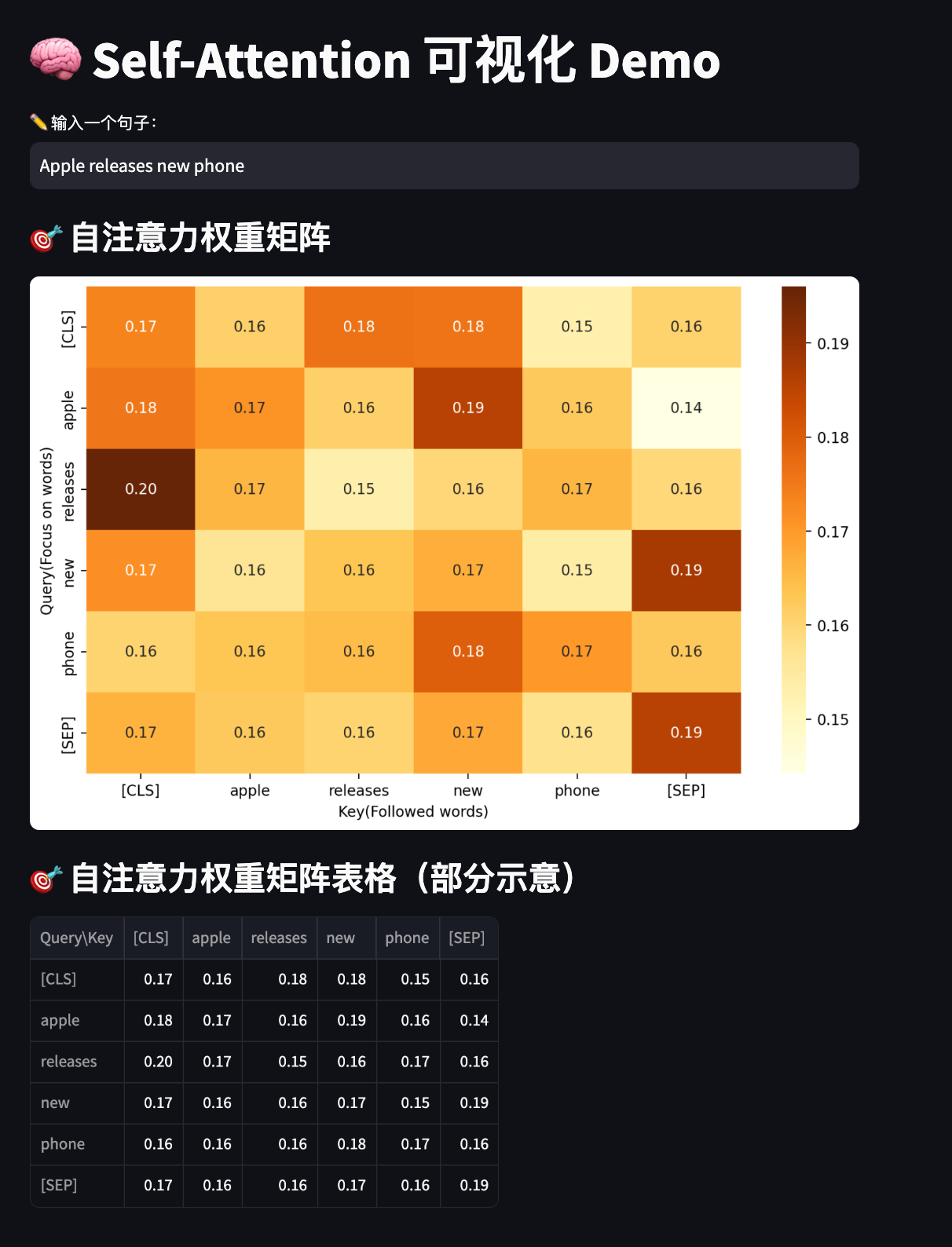
#####在 BERT 模型中,[CLS] 和 [SEP] 是两个特殊的标记(token),用于帮助模型理解输入结构和任务目标:
🟩 [CLS]:分类标记(Classification)
-
含义:Classification 的缩写。
-
位置:始终出现在输入的最开头。
-
作用:
- 它的输出向量(embedding)被用作整个句子的“全局语义表示”。
- 主要用于句子分类任务,如情感分析、句子对关系判断(如是否是问答对)等。
- 在 BERT 输出的张量中,可以通过
outputs.last_hidden_state[:, 0, :]取出[CLS]的向量。
🟨 [SEP]:分隔标记(Separator)
-
含义:Separator 的缩写。
-
作用:
- 在句子之间起“分隔”作用。
- 用于区分 两个句子的边界,如句子对输入(句子1 +
[SEP]+ 句子2)。
-
位置:
- 如果是单句:
[CLS]+ 句子 +[SEP] - 如果是句子对:
[CLS]+ 句子A +[SEP]+ 句子B +[SEP]
- 如果是单句:
🧠 总结对比
| Token | 全称 | 用于 | 在 input_ids 中的位置 |
|---|---|---|---|
[CLS] | Classification | 句子整体的语义表示 | 最前面 |
[SEP] | Separator | 句子/段落分隔 | 单句结尾 / 句子对之间与结尾 |
四、演进趋势的背后动因
| 阶段 | 代表模型 | 优点 | 遇到的瓶颈 |
|---|---|---|---|
| RNN | Elman RNN | 序列建模 | 记忆能力弱,难学长期依赖 |
| LSTM | LSTM / GRU | 引入门机制,缓解梯度问题 | 仍然串行,训练效率低 |
| Self-Attention | Transformer | 并行计算,全局感知,预训练强 | 对长文本成本高 |
演进趋势源于两个根本问题:
- 模型对长期依赖的建模能力不足 → LSTM 出现。
- 模型训练效率受串行计算限制 → Self-Attention 出现。
随着算力和数据的增长,Self-Attention 在规模化预训练中大显身手,最终逐步取代 RNN/LSTM 成为主流。
五、总结:从线性记忆到全局关注的进化
| 模型 | 记忆方式 | 并行能力 | 长距离建模能力 | 主流应用 |
|---|---|---|---|---|
| RNN | 隐藏状态 | ✘ | 弱 | 简单序列建模 |
| LSTM | 门控记忆 | ✘ | 较强 | 机器翻译、语音识别 |
| Self-Attention | 全局注意力 | ✔ | 强 | GPT/BERT 等大型语言模型 |
从 RNN 到 LSTM,再到 Self-Attention,是深度学习对信息依赖建模能力不断提升、计算效率不断优化的必然路径。掌握这一演进过程,不仅有助于理解 NLP 模型的本质,也为未来模型设计提供了重要启发。