第十章.XML
文章目录
- 1.XMl简介
- 2.解析XML技术
- 2.1DOM解析XML
- 2.2DOM4j
- 3.json
1.XMl简介
-
EXtensible Markup Language ,可扩充标记语言
-
特点:
- XML与操作系统,编程语言的开发平台无关
- 实现不同系统之间的数据交换
-
作用:
- 数据交互
- 配置应用程序和网站
-
XML标签
- xml文档由一系列标签元素组成
- <元素名 属性名 = “属性值”> 元素内容 </元素名>
- 属性值用双引号包裹
- 一个元素可以有多个属性
- 属性值不能直接包括<,",&(不建议:',>)
- 便签编写注意事项:
- 所有XML标签必须有结束标签
- 对大小写敏感
- 必须正确的嵌套
- 同级标签以缩进对齐
- 元素名称可以包含字母,数字或其他的字符
- 元素名称不能以数字或者标点符号开始
- 元素名称中不能含空格
-
eclipseXML配置

-
- file---->Source Folder---->创建文件(如config)---->新建file或者XML File
-
dtd 用来验证xml文件是否正确
-
xsd 格式验证
<?xml version="1.0" encoding="UTF-8"?>
<books><book id="1"><name>西游记</name><author>吴承恩</author><age>500</age></book><book id="2"><name>红楼梦</name><author>曹雪芹</author><age>200</age></book></books>- 转义字符
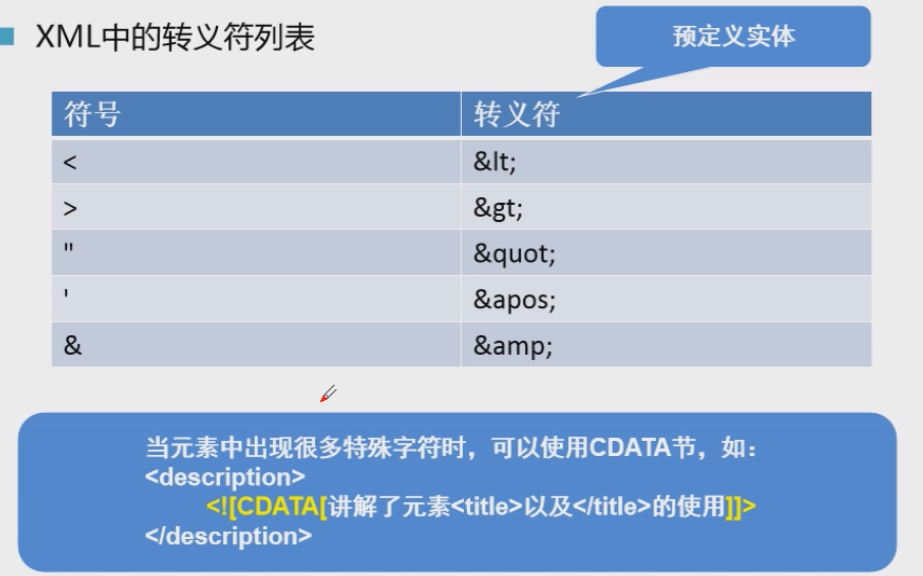
- //单个时用转义字符;多个的使用<![CDATA[ ]]
<?xml version="1.0" encoding="UTF-8"?>
<books><book id="1"><name>西游记</name><author>吴承恩<</author><age>500</age></book><book id="2"><name>红楼梦</name><author><![CDATA[<曹雪芹>]]></author><age>200</age></book></books>2.解析XML技术
- DOM
- 基于XMl文档树结构的解析
- 适用于多次访问的XML文档
- 特点:比较消耗资源
- SAX:
- 基于事件的解析
- 适用于大数据量的XML文档
- 特点:占用资源少,内存消耗小
- DOM4j:
- 非常优秀的java XML API
- 性能优异,功能强大
- 开放源代码
2.1DOM解析XML
- DOM介绍:
- 文档对象模型(Document Object Model)
- DOM把xml文档隐射成一个倒挂的树
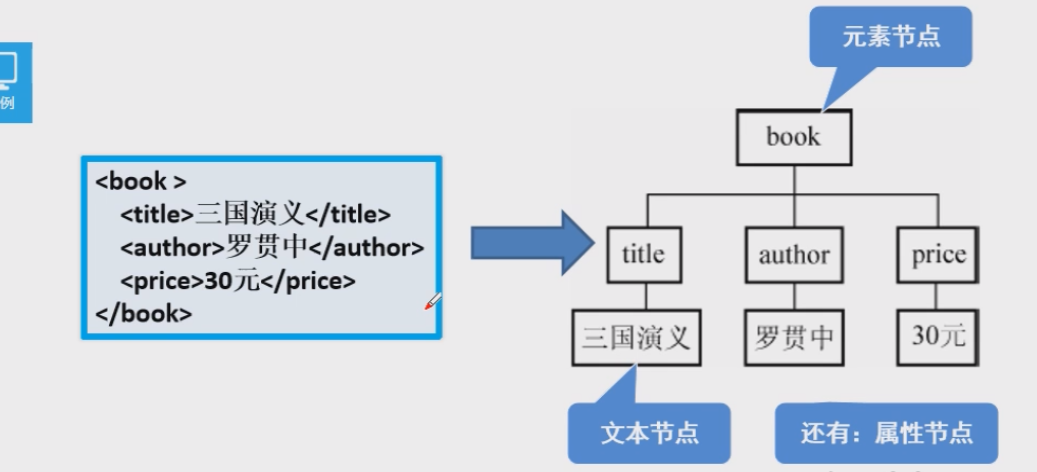

2.2DOM4j
- Document:定义XML文档
- Element:定义XML元素
- Text:定义XML文本节点
- Attribute:定义XML的属性
- 特点:
- 开源易用
- 应用于java开发平台
- 使用大量接口
- xml文件中就一个节点包含多个子节点及多个属性
- xml的使用1
-------------------XML文件------------------------------
<?xml version="1.0" encoding="UTF-8"?>
<books>
<!-- 下面是书本信息 --><book id="1"><name id="11">西游记</name><author id="22">吴承恩<</author><age>500</age></book><book id="2"><name id="111"> 红楼梦 </name><author><![CDATA[<曹雪芹>]]></author><age>200</age></book></books>
-------------------java文件------------------------------
package xml1;import java.io.File;import java.util.List;import org.dom4j.io.SAXReader;
import org.dom4j.DocumentException;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
public class Dom4jXml {public static void main(String[] args) throws Exception{//读文件对象SAXReader reader = new SAXReader();File file = new File("config/book.xml");//读取文件,获取文档对象Document document = reader.read(file);//获取根元素Element rootEl = document.getRootElement();//获取 根元素子元素集合List<Element> childEls = rootEl.elements();for(Element cel:childEls) {System.out.println("子元素名称:"+cel.getName());System.out.println("子元素内容:"+cel.getText());System.out.println("子元素的类型:"+cel.getNodeType()+"\t"+cel.getNodeTypeName());
// 子元素的子元素集合
// cel.elements();//获取指定元素Element nameEl = cel.element("name");//知道属性名称System.out.println(nameEl.attributeCount());//Cannot invoke "org.dom4j.Element.attributeCount()" because "nameEl" is null
// at XMLStudy/xml1.Dom4jXml.main(Dom4jXml.java:34) 出错原因:book.xml没有属性标识,删掉没有name属性的System.out.println("\n\n"+nameEl.getText()+"~");System.out.println(nameEl.getTextTrim()+"~\n\n");//元素是获取内容//属性是获取值 }
// 获取根元素的属性集合List<Attribute> atts = rootEl.attributes();//不知道属性名for(Attribute att:atts) {System.out.println("属性名称:"+att.getName());System.out.println("属性值:"+att.getValue());System.out.println("属性类型:"+att.getNodeType()+"\t"+att.getNodeTypeName());}}
}- xml的使用2
-------------------My.xml文件------------------------------
<?xml version="1.0" encoding="UTF-8"?>
<books>
<!-- 下面是书本信息 --><book id="1" ><name id="11" >哈哈</name><author id="12">无聊的人</author><address id="13"><sf id="111">湖南</sf><ds id="112">岳阳</ds><qx id="113">湘阴</qx></address></book><book id="22" ><name >嘿嘿</name><author>欠揍的人</author><address><sf>湖南</sf><ds>岳阳</ds><qx>湘阴</qx></address></book></books>-------------------MyDom4j.java文件------------------------------
package xml1;import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
import java.util.List;import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.dom4j.Attribute;public class MyDom4j {private Document document;//dom4j解析出来的文档对象/**** 1.读取文件* @Date 2025年4月28日15:18:31* @param path*/public void read(String path) {SAXReader reader = new SAXReader();File srcFile = new File(path);try {document= reader.read(srcFile);} catch (DocumentException e) {e.printStackTrace();}}/**** 2.解析文档内容* @Date 2025年4月28日15:19:50* @param el*/public void jiexi(Element el) {//节点里有子节点集合//先获取属性System.out.println("属性:");List<Attribute> attrs = el.attributes();for(int i=0;i<attrs.size();i++) {Attribute att = attrs.get(i);System.out.println("属性名:"+att.getName());System.out.println("属性值:"+att.getValue());}System.out.println("标签:");//再获取标签List<Element> els = el.elements();for(int i=0;i<els.size();i++) {Element cElement = els.get(i);System.out.println("标签名:"+cElement.getName());System.out.println("标签值:"+cElement.getTextTrim());jiexi(cElement);//继续往下解析,是否还有子节点,或子属性}}//修改name标签//在内存中奖属性值变换一下public void updateNameEl(Element el) {List<Element> els = el.elements();for(int i = 0; i< els.size();i++) {Element cel = els.get(i);if (cel.getName().equals("name")) {cel.setText(("A"+Math.random()).substring(0,7));}updateNameEl(cel);}}//根据属性id进行删除public void delElement(Element el) {List<Element> els = el.elements();for(int i = 0 ; i< els.size();i++) {Element cel = els.get(i);//获取ID属性Attribute idAttr = cel.attribute("id");if(idAttr != null && idAttr.getValue().equals("11")) {el.remove(cel);}else {delElement(cel);}}}//元素添加public void addElement(Element el) {//Element newEl = el.addElement("mybook");newEl.setText("我是新的标签");el.addAttribute("myshow","100");}
// //输出为文件
// public void writer() {
// Writer writer = null;
// XMLWriter xw = null;
// try {
// writer = new FileWriter("new-my.xml");
// OutputFormat of=OutputFormat.createPrettyPrint();
// of.setEncoding("gbk");//编码设置
// xw = new XMLWriter(writer, of);
// } catch (IOException e) {
// e.printStackTrace();
// }//过于复杂,进行修改
// finally {
// if (xw !=null) {
// try {
// xw.close();
// } catch (IOException e) {
// // TODO Auto-generated catch block
// e.printStackTrace();
// }
// }
// if (writer !=null) {
// try {
// writer.close();
// } catch (IOException e) {
// // TODO Auto-generated catch block
// e.printStackTrace();
// }
// }
// }//输出为文件public void writer() {try(Writer writer = new FileWriter("new-my.xml")) {OutputFormat of=OutputFormat.createPrettyPrint();of.setEncoding("gbk");//编码设置XMLWriter xw=null;try {xw = new XMLWriter(writer, of);xw.write(document);xw.flush();} catch (Exception e) {e.printStackTrace();}finally{if(xw !=null) {xw.close();}}} catch (IOException e) {e.printStackTrace();}}public static void main(String[] args) {MyDom4j myDom4j = new MyDom4j();myDom4j.read("config/My.xml");Element rootEl =myDom4j.document.getRootElement(); //自己调用自己,递归算法[循环]
// myDom4j.jiexi(rootEl);
// myDom4j.updateNameEl(rootEl);
// myDom4j.writer();
// myDom4j.delElement(rootEl);
// myDom4j.writer();myDom4j.addElement(rootEl);myDom4j.writer();File outputFile = new File("config/new-my.xml");System.out.println("文件将输出到:" + outputFile.getAbsolutePath());File configDir = new File("config");System.out.println("目录可写: " + configDir.canWrite());}
}-------------------new-my.xml文件------------------------------
<?xml version="1.0" encoding="utf-8"?><books myshow="100"> <!-- 下面是书本信息 --> <book id="1"> <name id="11">哈哈</name> <author id="12">无聊的人</author> <address id="13"> <sf id="111">湖南</sf> <ds id="112">岳阳</ds> <qx id="113">湘阴</qx> </address> </book> <book id="22"> <name>嘿嘿</name> <author>欠揍的人</author> <address> <sf>湖南</sf> <ds>岳阳</ds> <qx>湘阴</qx> </address> </book> <mybook>我是新的标签</mybook>
</books>3.json
- 组成:{}/[]
- {} 对象
- {“name”:“哈哈” , “age”:“1”}
- [] 数组
- [“郑州” , “安阳”]
- 数组对象:
- [ {“name”:“哈哈” , “age”:“1”} ]
- 对象中有数组
-
- {“name”:“哈哈” , “age”:“1” , “address”: [“郑州” , “安阳”] }
-
- {} 对象
- java里书写时必须带双引号
- 校验:可以网上搜索在线校验工具
https://www.bejson.com/