强化学习:山地车问题
山地车问题
问题定义
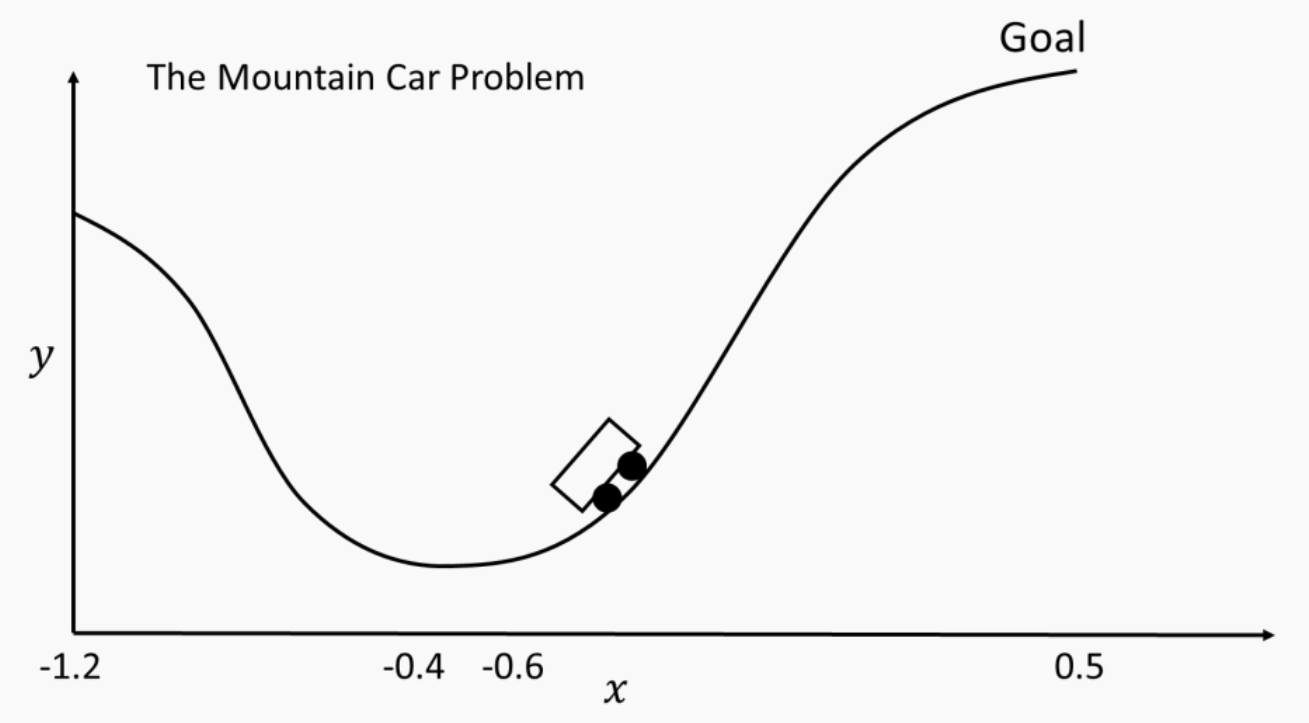
山地车问题(如下图)是强化学习中的经典问题,部分原因在于传统控制器难以解决它。
其具体描述是:一辆车被困在山谷中需要逃脱,但它的发动机动力不足以直接爬山,因此它必须来回滚动以积累动量,从而达到目标状态(目标状态为位置 x > 0.5 x > 0.5 x>0.5)。
现给出环境的关键细节:
- 初始状态:车的初始位置 x 0 x_0 x0在 − 0.4 -0.4 −0.4到 − 0.6 -0.6 −0.6之间随机初始化,位于山谷底部;初始速度 x ˙ 0 \dot{x}_0 x˙0 为0。
- 边界与速度限制:车不能超出边界(即不允许 x < − 1.2 x < -1.2 x<−1.2 ) ,速度限制在 − 0.07 < x ˙ t < 0.07 -0.07 < \dot{x}_t < 0.07 −0.07<x˙t<0.07 。
- 动作:有三个离散动作,即对车的力输入 u t u_t ut:-1、0、1 。
- 状态:有两个状态描述车,即采样时刻 t t t 的位置 x t x_t xt和速度 x ˙ t \dot{x}_t x˙t 。
- 高度函数:车的高度 y t = sin ( 3 x t ) y_t = \sin(3x_t) yt=sin(3xt) ,主要用于绘图。
- 动力学方程: x ¨ t = 0.001 u t − 0.0025 cos ( 3 x t ) \ddot{x}_t = 0.001u_t - 0.0025\cos(3x_t) x¨t=0.001ut−0.0025cos(3xt) 其中 x ¨ t \ddot{x}_t x¨t是汽车的加速度。
- 奖励机制:在强化学习问题中,我们按照萨顿(Sutton)和巴托(Barto)的定义来设置奖励,即规定山地车在朝向目标行进的每一步,或直至情节终止时,都给予离散奖励 -1 。也就是说,用一个较小的负奖励来激励智能体尽可能少地用步骤达到目标状态。
补充说明
在本任务中没有预定义的Matlab环境。
因此你需要自行构建(为这个山地车问题设计并实现一个环境),然后再训练一个强化学习智能体来解决它。
通常来说,当遇到新问题时,你需要为强化学习智能体设置并编写自己的自定义环境,以供其探索和体验。
这意味着你需要知道如何设置自定义环境,否则你将只能研究别人为你设置好的问题——这极具局限性!
指定环境
在所有强化学习问题中,通常需要两个关键函数来指定环境:
- 初始化函数:此函数用于为训练情节初始化环境。
- 步动态函数 :该函数在环境动态模拟中执行一个时间步长 t t t ,具体过程如下:
- 动作执行:智能体从给定状态 S t S_t St 出发探索环境,采取给定动作 A t A_t At (函数输入),该动作作用于环境动态。
- 奖励与新观测获取:智能体因动作 A t A_t At 获得奖励 R t + 1 R_{t + 1} Rt+1 ,并得到新的观测值(此处观测值即更新后的状态 S t + 1 S_{t + 1} St+1 ,为函数输出)。
- 终止条件判断:步动态函数输出标志,用以指明是否达到情节的终止条件(若达到,学习情节将终止,新情节将使用初始化函数重新初始化 )。
- 信号输出:最后,步动态函数输出下一时间步模拟所需的记录信号。
% 初始化初始化函数
function [InitialObservation, LoggedSignals] = initialDynamics()% 从均匀分布初始化位置,范围在 -0.6 到 -0.4 之间x0 = -0.6 + (0.2 * rand()); % 这个范围是随机的% 初始化速度为零xdot0 = 0;% 定义观察值InitialObservation = [x0; xdot0];% 记录信号LoggedSignals = [x0; xdot0];
end% 步动态函数
function [NextObs, Reward, IsDone, LoggedSignals] = stepDynamics(Action, LoggedSignals)% 初始化终止条件标志IsDone = false;% 解包记录的信号xt = LoggedSignals(1); % 位置xdot = LoggedSignals(2); % 速度% 定义控制输入ut = Action;% 计算加速度xdotdot = 0.001 * ut - 0.0025 * cos(3 * xt);% 使用一阶数值积分更新动力学T = 1; % 时间步长xt_plus1 = xt + T * xdot;xdot_plus1 = xdot + T * xdotdot;% 饱和位置和速度以防止超出边界if xt_plus1 < -1.2xt_plus1 = -1.2;endif xdot_plus1 < -0.07xdot_plus1 = -0.07;endif xdot_plus1 > 0.07xdot_plus1 = 0.07;end% 如果达到终点位置,设置终止条件if xt_plus1 > 0.5IsDone = true;end% 定义下一步的观察值NextObs = [xt_plus1; xdot_plus1];% 记录信号LoggedSignals = [xt_plus1; xdot_plus1];% 定义奖励if IsDoneReward = 1; % 当达到终点时奖励为正elseReward = -1; % 当达到终点时奖励为正end
end
开始训练
1.环境与评判器的创建
% 山地车的强化学习% 清除工作区所有变量
clear all% 定义随机数种子以实现可重复的结果
rng(1,'twister');% 山地车环境定义% 观测信息
ObservationInfo = rlNumericSpec([2 1]);
ObservationInfo.Name = 'States';
ObservationInfo.Description = '位置和速度';% 动作信息
ActionInfo = rlFiniteSetSpec([-1 0 1]);
ActionInfo.Name = '动作';% 环境 - 此处使用上面那两个函数
env = rlFunctionEnv(ObservationInfo,ActionInfo,'stepDynamics','initialDynamics');% 获取观测和规格信息
stateInfo = getObservationInfo(env); % 获取状态信息
stateDimension = stateInfo.Dimension; % 获取连续状态的维度
actionInfo = getActionInfo(env); % 获取动作信息
numActions = length(actionInfo.Elements); % 离散动作的数量% 定义一个仅以状态作为输入的 Q 函数网络(在 Matlab 中称为评判器)% 创建一个浅层神经网络来近似 Q 值函数
net = [imageInputLayer(stateDimension,'Normalization','none','Name','States')fullyConnectedLayer(24)reluLayerfullyConnectedLayer(numActions)];% 使用该网络创建评判器
critic = rlQValueRepresentation(net,stateInfo,actionInfo,'Observation',{'States'});
代码功能简述
- 初始化工作:清除工作区变量,并设置随机数种子,保证实验结果的可重复性。
- 环境定义:
- 定义观测信息,明确观测是一个二维列向量,代表山地车的位置和速度。
- 定义动作信息,动作集合包含 -1、0、1 三个离散动作。
- 创建强化学习环境,使用上面咱们自定义的
stepDynamics和initialDynamics函数来模拟环境的动态变化和初始化。
- 信息获取:获取环境的观测信息和动作信息,包括状态维度和离散动作的数量。
- Q 函数网络构建:创建一个浅层神经网络,用于近似 Q 值函数。网络包含一个输入层、一个全连接层、一个 ReLU 激活函数层和一个输出层。
- 评判器创建:使用构建好的神经网络创建评判器(
critic),用于评估智能体在不同状态下采取不同动作的价值。
2.定义一个深度 Q 学习智能体来解决山地车问题
%% 定义智能体并进行训练
% 智能体选项设置
agentOpts = rlDQNAgentOptions(...'UseDoubleDQN',false, ... % 不使用双 DQN(Double DQN)算法'TargetUpdateMethod',"periodic", ... % 目标网络更新方法为“周期性”更新'TargetUpdateFrequency',4, ... % 每 4 步更新一次目标网络'ExperienceBufferLength',100000, ... % 经验回放缓冲区的长度为 100000'DiscountFactor',0.99, ... % 折扣因子为 0.99,用于计算未来奖励的现值'MiniBatchSize',256); % 每次从经验回放缓冲区中采样的小批量数据大小为 256% 定义智能体
agent = rlDQNAgent(critic,agentOpts); % 使用前面定义的评判器(critic)和设置好的智能体选项来创建深度 Q 学习智能体(rlDQNAgent)% 指定强化学习训练选项
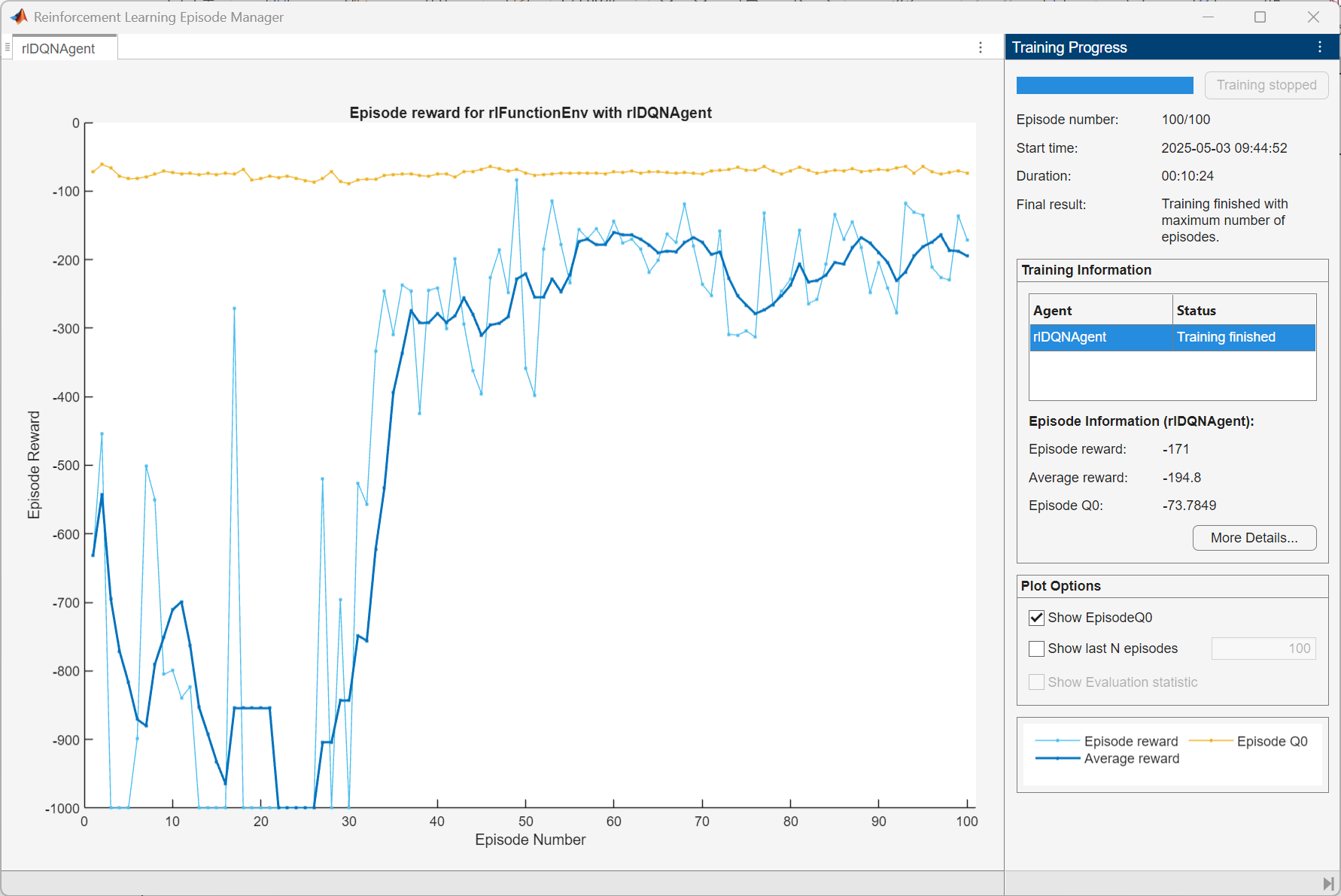
trainOpts = rlTrainingOptions(...'MaxEpisodes', 100, ... % 最大训练 episodes 数为 100'MaxStepsPerEpisode', 1000, ... % 每个 episode 中最大的步数为 1000'Verbose', false, ... % 训练过程中不输出详细信息'Plots','training-progress',... % 绘制训练进度图'StopTrainingCriteria','AverageReward'); % 停止训练的条件为达到平均奖励标准% 训练智能体
trainingStats = train(agent,env,trainOpts); % 使用定义好的智能体(agent)、环境(env)和训练选项(trainOpts)来进行训练,并将训练统计信息存储在 trainingStats 中
这段代码是设置和执行山地车问题的深度 Q 学习(Deep Q-Network, DQN)训练过程。
- 先是设置了深度Q学习智能体的各种选项,这些选项会影响智能体学习的方式和效率:
UseDoubleDQN:不使用双 DQN 算法,而是采用传统的 DQN 算法。TargetUpdateMethod: 此参数规定了目标网络的更新方式,设置为 “periodic”,也就是采用周期性更新的方式。TargetUpdateFrequency:这个参数明确了目标网络的更新频率,设置为 4,表示每 4 步更新一次目标网络。ExperienceBufferLength:该参数指的是经验回放缓冲区的长度。经验回放是 DQN 算法中的一个关键技巧,它能打破数据之间的相关性,提升训练的稳定性。设置为 100000,意味着经验回放缓冲区最多可以存储 100000 条经验数据。DiscountFactor:这是折扣因子,用于计算未来奖励的现值。它体现了智能体对未来奖励的重视程度,取值范围在 0 到 1 之间。设置为 0.99,表明智能体比较看重未来的奖励。MiniBatchSize:该参数代表每次从经验回放缓冲区中采样的小批量数据的大小。小批量数据用于训练神经网络。设置为 256,即每次从经验回放缓冲区中随机抽取 256 条经验数据来训练神经网络。
- 然后使用之前定义的评判器(critic)和设置好的选项来创建深度 Q 学习智能体。
- 接着指定了强化学习的训练选项,包括最大训练轮数(MaxEpisodes)、每轮的最大步数(MaxStepsPerEpisode)、是否输出详细训练信息(Verbose)、绘制训练进度图(Plots)以及停止训练的条件(StopTrainingCriteria)。
- 最后使用创建好的智能体、环境和训练选项进行训练,并将训练过程中的统计信息保存下来,以便后续分析训练结果。
模拟已训练的智能体
对已训练的智能体进行模拟,以检验其性能表现。
%% 模拟
simOptions = rlSimulationOptions('MaxSteps',1000); % 模拟选项,设置最大步数为 1000
experience = sim(env,agent,simOptions); % 对环境(env)和智能体(agent)进行模拟,使用上述模拟选项,并记录模拟过程中的经验
totalReward = sum(experience.Reward); % 从模拟经验中提取奖励,并计算总奖励% 绘制模拟结果
figure; % 创建一个新的图形窗口% 绘制训练奖励
subplot(2,1,1); % 创建一个 2 行 1 列的子图,当前操作在第 1 个子图plot(trainingStats.EpisodeIndex,trainingStats.EpisodeReward); % 绘制训练集数(EpisodeIndex)与每集奖励(EpisodeReward)的关系曲线
hold on; % 保持当前图形,以便后续图形能在同一图中绘制
plot(trainingStats.EpisodeIndex,trainingStats.AverageReward); % 绘制训练集数(EpisodeIndex)与平均奖励(AverageReward)的关系曲线
title('Training Rewards'); % 设置子图标题为“训练奖励”
xlabel('Episode'); % 设置 x 轴标签为“集数(Episode)”
ylabel('Reward'); % 设置 y 轴标签为“奖励”
legend('Episode Reward','Average Reward','Location','SouthEast'); % 添加图例,说明曲线代表的内容,并设置图例位置为东南方向
nt = length(experience.Reward.Time); % 获取模拟过程中奖励时间序列的长度
States = experience.Observation.States.Data; % 获取模拟过程中观测到的状态数据
xvals = [-1.2:0.1:0.6]; % 生成 x 轴数据点,范围从 -1.2 到 0.6,步长为 0.1
yvals = sin(3*xvals); % 根据 x 轴数据点计算对应的 y 轴数据点(这里是正弦函数计算)
cumReward = cumsum(experience.Reward.Data); % 计算模拟过程中奖励的累积和
以下是将注释改成中文后的代码:
%% 模拟
simOptions = rlSimulationOptions('MaxSteps',1000); % 模拟选项,设置最大步数为 1000
experience = sim(env,agent,simOptions); % 对环境(env)和智能体(agent)进行模拟,使用上述模拟选项,并记录模拟过程中的经验
totalReward = sum(experience.Reward); % 从模拟经验中提取奖励,并计算总奖励% 绘制模拟结果
figure; % 创建一个新的图形窗口% 绘制训练奖励
subplot(2,1,1); % 创建一个 2 行 1 列的子图,当前操作在第 1 个子图plot(trainingStats.EpisodeIndex,trainingStats.EpisodeReward); % 绘制训练集数(EpisodeIndex)与每集奖励(EpisodeReward)的关系曲线
hold on; % 保持当前图形,以便后续图形能在同一图中绘制
plot(trainingStats.EpisodeIndex,trainingStats.AverageReward); % 绘制训练集数(EpisodeIndex)与平均奖励(AverageReward)的关系曲线
title('Training Rewards'); % 设置子图标题为“训练奖励”
xlabel('Episode'); % 设置 x 轴标签为“集数(Episode)”
ylabel('Reward'); % 设置 y 轴标签为“奖励”
legend('Episode Reward','Average Reward','Location','SouthEast'); % 添加图例,说明曲线代表的内容,并设置图例位置为东南方向
nt = length(experience.Reward.Time); % 获取模拟过程中奖励时间序列的长度
States = experience.Observation.States.Data; % 获取模拟过程中观测到的状态数据
xvals = [-1.2:0.1:0.6]; % 生成 x 轴数据点,范围从 -1.2 到 0.6,步长为 0.1
yvals = sin(3*xvals); % 根据 x 轴数据点计算对应的 y 轴数据点(这里是正弦函数计算)
cumReward = cumsum(experience.Reward.Data); % 计算模拟过程中奖励的累积和
这段代码对已训练智能体的模拟以及结果的可视化操作:
- 模拟设置与执行:使用
rlSimulationOptions函数设置模拟的最大步数为 1000,然后调用sim函数对之前定义的环境env和已训练的智能体agent进行模拟,并记录模拟过程中的经验。 - 计算总奖励:从模拟经验中提取奖励数据,并计算出总奖励。
- 绘制训练奖励图:创建一个新的图形窗口,在其中添加一个 2 行 1 列子图中的第 1 个子图。分别绘制训练集数与每集奖励、训练集数与平均奖励的关系曲线,并添加标题、坐标轴标签和图例,以直观展示训练过程中的奖励变化情况。
- 数据处理:获取模拟过程中奖励时间序列的长度,提取观测到的状态数据,生成一组 x 轴数据点并计算对应的 y 轴数据点(基于正弦函数),最后计算模拟过程中奖励的累积和,为后续可能的进一步可视化或分析做准备。
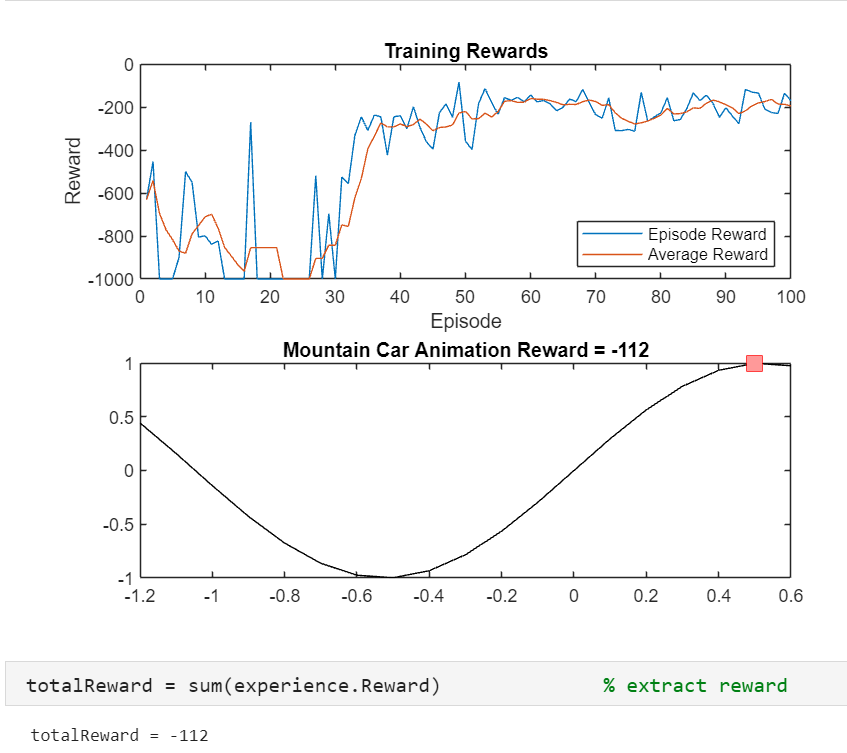
哎,那上图中第二行的图片是干什么的呢?
自然是显示小车位置的了,代码如下所示:
(这段代码展示了山地车的模拟情况,不过需要将下面的代码复制粘贴到命令窗口中执行,不然容易只绘制模拟完成时的图。)
%% 模拟
% 为了使结果可复现,固定随机数生成器的种子
rng(1,'twister');% 绘制动画
for i = 1:ntsubplot(2,1,2); % 创建一个 2 行 1 列的子图,当前操作在第 2 个子图cla; % 清除当前子图中的绘图内容plot(xvals,yvals,'k'); % 绘制黑色的山地曲线(根据之前定义的 xvals 和 yvals)hold on; % 保持当前图形,以便后续图形能在同一图中绘制x = States(1,1,i); % 获取山地车在第 i 步时的水平位置(从状态数据中提取)y = sin(3*x); % 根据水平位置计算山地车在第 i 步时的高度plot(x,y,'sq','MarkerSize',10,'MarkerEdgeColor','red','MarkerFaceColor',[1 .6 .6]); % 绘制一个红色边框、内部颜色为淡红色的正方形标记来表示山地车的位置title(['Mountain Car Animation Reward = ' num2str(cumReward(i))]); % 设置子图的标题,显示“山地车动画 奖励 = 当前累积奖励值”pause(0.01); % 暂停 0.01 秒,以便能观察到动画效果
end
这段代码比较简单,看注释就能明白。
改用Python实现
下次再补充。