AdaBoost算法详解:原理、实现与应用指南
AdaBoost算法详解:原理、实现与应用指南
1. 引言
在机器学习领域,AdaBoost(Adaptive Boosting) 是最早提出的集成学习(Ensemble Learning)**算法之一,由Yoav Freund和Robert Schapire于1995年提出。它通过组合多个弱分类器(Weak Classifiers)(如决策树桩)来构建一个强分类器(Strong Classifier),在分类任务中表现优异。
本文将深入讲解:
- AdaBoost 的核心思想
- 算法数学推导
- Python 代码实现
- 实际应用案例
- 调参技巧与优化方法
2. AdaBoost 简介
AdaBoost 是一种迭代式增强算法,其核心思想是:
- 训练多个弱分类器(如决策树桩),每个分类器只比随机猜测略好。
- 调整样本权重,使前一个分类器分错的样本在下一轮获得更高权重。
- 组合所有弱分类器的预测结果,通过加权投票得到最终预测。
优点:
✔ 高精度,尤其适用于二分类问题
✔ 自动处理特征选择,对噪声数据鲁棒
✔ 可与多种基学习器结合(如决策树、SVM)
缺点:
✖ 对异常值敏感
✖ 训练时间随迭代次数增加
3. AdaBoost 核心原理
3.1 算法流程
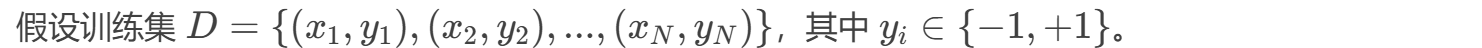
步骤:
-
初始化样本权重:
![[
w_i = \frac{1}{N}, \quad i = 1, 2, ..., N
]](https://i-blog.csdnimg.cn/direct/f5beb4de6acd4f64bb710c2700198088.png)
-
迭代训练 ( T ) 个弱分类器:
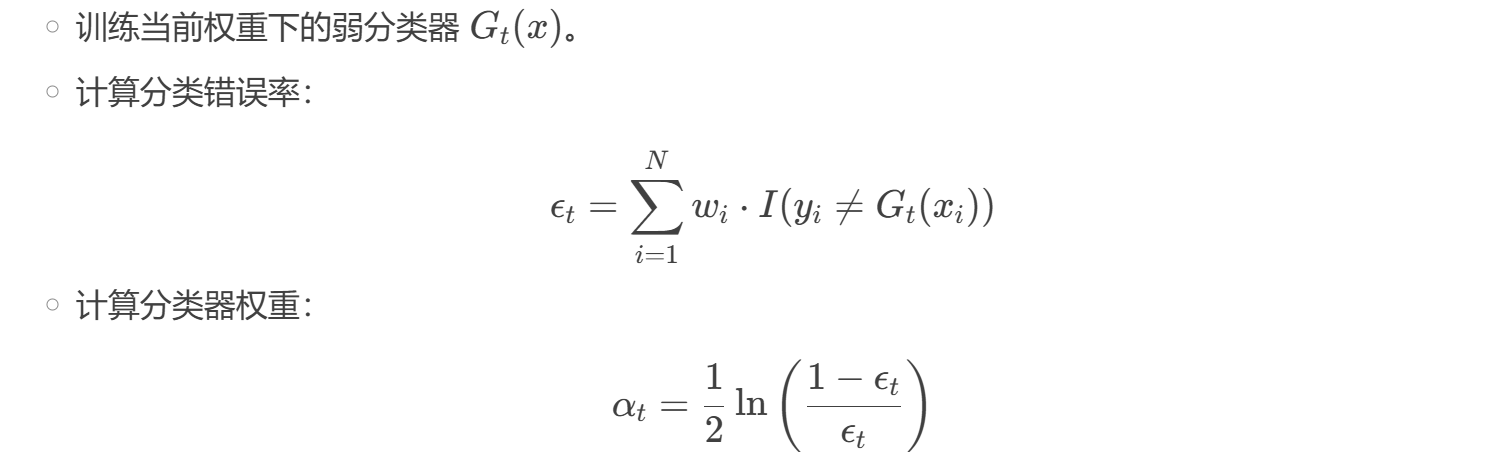
- 更新样本权重(增加错分样本权重):
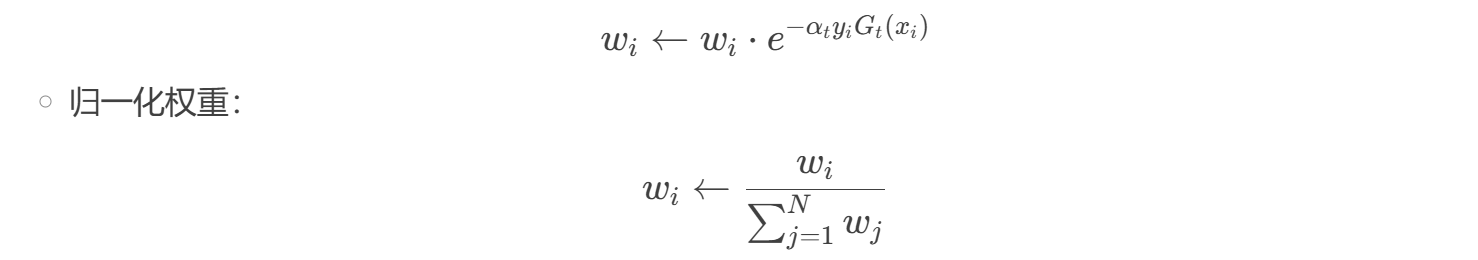
- 更新样本权重(增加错分样本权重):
-
最终强分类器:
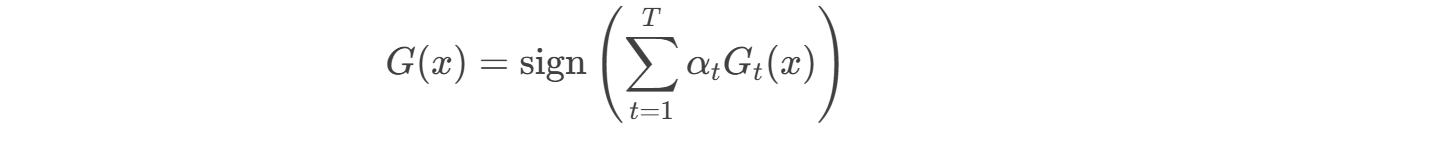
3.2 关键点
- 样本权重调整:让后续分类器更关注难分类的样本。
- 分类器权重 (\alpha_t):错误率 (\epsilon_t) 越小,(\alpha_t) 越大(贡献更高)。
- 指数损失函数:优化目标是最小化:
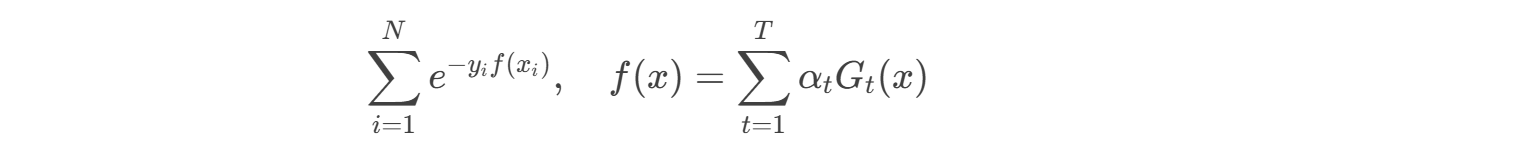
4. AdaBoost 实战(Python 示例)
4.1 安装依赖
pip install scikit-learn matplotlib numpy
4.2 代码实现(以垃圾邮件分类为例)
import numpy as np
import pandas as pd
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report# 加载数据
data = pd.read_csv('spambase.csv')
X = data.iloc[:, :-1]
y = data.iloc[:, -1]# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 使用决策树桩(max_depth=1)作为弱分类器
base_model = DecisionTreeClassifier(max_depth=1)# 训练 AdaBoost
model = AdaBoostClassifier(base_estimator=base_model,n_estimators=50, # 迭代次数learning_rate=1.0, # 学习率(调整 alpha_t 的影响)random_state=42
)
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
输出示例:
Accuracy: 0.945precision recall f1-score support0 0.95 0.94 0.94 5381 0.94 0.95 0.94 542accuracy 0.94 1080macro avg 0.94 0.94 0.94 1080
weighted avg 0.94 0.94 0.94 1080
4.3 可视化训练过程
import matplotlib.pyplot as plt# 绘制分类器权重
plt.bar(range(len(model.estimator_weights_)), model.estimator_weights_)
plt.xlabel('Weak Classifier Index')
plt.ylabel('Alpha (Classifier Weight)')
plt.title('AdaBoost Classifier Weights')
plt.show()
5. AdaBoost 调参指南
| 参数 | 作用 | 推荐范围 |
|---|---|---|
n_estimators | 弱分类器数量 | 50~200 |
learning_rate | 学习率(调整分类器权重) | 0.5~1.0 |
base_estimator | 弱分类器类型 | DecisionTree(max_depth=1) |
algorithm | 实现方式(SAMME 或 SAMME.R) | SAMME.R(更稳定) |
调参技巧:
- 增加
n_estimators可以提高精度,但可能过拟合。 - 降低
learning_rate可以增强泛化能力,但需要更多迭代。 - 更换
base_estimator(如 SVM、逻辑回归)可能提升性能。
6. AdaBoost vs. 其他Boosting算法
| 算法 | 特点 | 适用场景 |
|---|---|---|
| AdaBoost | 自适应调整样本权重 | 二分类、简单特征 |
| Gradient Boosting (GBM) | 优化梯度下降 | 回归、分类 |
| XGBoost | 二阶梯度优化、正则化 | 大规模数据 |
| LightGBM | 直方图优化、高效 | 高维数据 |
7. 总结
- AdaBoost 通过组合多个弱分类器,构建高精度模型。
- 核心是样本权重调整,让后续分类器更关注难样本。
- 适用于二分类问题,如垃圾邮件检测、人脸识别。
- 调参关键:
n_estimators、learning_rate、base_estimator。