2025五一杯数学建模竞赛C题 社交媒体用户分析 保姆级教程讲解|模型讲解
完整内容请看文章最下面的推广群
2025五一杯数学建模竞赛(五一赛)C题保姆级分析完整思路+代码+数据教学
1. 题目分析
属于数据分析与预测类的数学建模问题。主要围绕社交媒体平台用户与博主之间的互动行为数据,运用统计分析和预测模型,解决博主新增关注数、用户新关注行为、用户在线情况及互动关系等预测问题。
2. 核心要点
(1)数据预处理
将附件1中“用户行为”合并成不同交互维度(观看、点赞、评论、关注),并按照博主和日期汇总。
考虑点赞、评论、关注均包含观看,所以可设计“去重观看”与“交互强度”指标。
将时间戳拆分成日期、小时段等多种时间特征。
(2)特征工程
宏观特征:每日全平台各博主的总互动数、历史平均新增关注数、上升/下降趋势(如近3日变化率)。
博主侧特征:粉丝基数、历史高峰期、内容活跃度(当日发帖数或互动率)。
用户侧特征(问题2–4):用户历史活跃天数、长尾偏好(偏好哪些博主)、时间段活跃分布、交互偏好(观看→点赞→关注转化率)。
(3)模型选择与验证
对于问题1:可选用时间序列模型(如ARIMA、指数平滑)或回归模型(如Poisson回归、随机森林回归)来预测每日新增关注量。
对于问题2–4:可构建分类模型(逻辑回归、XGBoost等)判断是否会关注,并用多标签预测或排序模型(如learning to rank)来给出可能关注的博主列表。
交叉验证:对历史数据按滚动时间窗口进行训练/验证,评估预测准确度(MAE、RMSE、AUC等)。
3. 求解思路
(1)数据处理
1)数据清洗:
检查数据中是否存在缺失值,对于缺失值可以采用删除、填充(如均值填充、中位数填充)等方法进行处理。
去除重复记录,确保数据的唯一性。
检查数据中的异常值,对于异常值可以采用基于统计方法(如Z-score)或基于机器学习方法(如孤立森林)进行识别和处理。
2)数据转换:
将时间列转换为合适的日期时间格式,方便后续按时间进行数据筛选和分析。
将用户行为列中的数字编码转换为对应的行为名称(观看、点赞、评论、关注),提高数据的可读性。
3)特征提取:根据不同问题的需求,从原始数据中提取相关特征,如上述各问题中提到的观看数、点赞数、评论数、关注数、在线天数、在线时段分布等。
4)数据划分:将数据划分为训练集和测试集,一般采用随机划分或按时间顺序划分的方法,确保训练集和测试集的数据分布具有代表性。在Python中可以使用 sklearn 库的 train_test_split 函数实现:
(2)问题1
1)对附件1中各博主的历史关注数据进行统计分析,提取与关注数相关的特征,如观看数、点赞数、评论数等。
2)选择合适的时间序列分析模型或机器学习回归模型,以历史关注数据和相关特征为输入,建立预测模型。
3)使用训练好的模型预测各博主在2024.7.21当天的新增关注数,并筛选出新增关注数最多的5位博主。
(3)问题2
1)结合附件1中用户的历史行为数据和附件2中2024.7.22当天的观看、点赞、评论行为数据,提取用户与博主之间的互动特征。
2)构建机器学习分类模型,以用户的历史行为和当天的互动特征为输入,预测用户在2024.7.22产生的新关注行为。
3)将指定用户在2024.7.22新关注的博主ID填入表2。
(4)问题3
1)基于附件1数据,分析用户的历史在线时间和互动行为模式,提取与用户在线情况和互动关系相关的特征。
2)建立机器学习分类模型预测指定用户在2024.7.21当天是否在线。
3)若用户在线,使用回归模型预测该用户与各博主的互动数,并找出互动数最高的3名博主。
(5)问题4
1)在问题3的基础上,进一步分析用户使用社交媒体的时间习惯,将时间划分为24个时段。
2)建立时间序列模型或机器学习模型,预测指定用户在2024.7.23是否在线以及每个在线时段与各博主的互动数。
3)找出每个用户在每个在线时段互动数最高的3名博主ID以及对应的时段,并填入表4。
4.详细思路
1)目标定义
目标变量:对于每个博主Bi,预测2024年7月21日的“新增关注数”yi(t)。
2)数据处理
-
筛选出附件1中2024年7月11日-20日的所有关注行为(用户行为=4); 2) 按博主和日期汇总,得到时间序 {y_i(t)},其中 t=1 对应7月11日,…,t=10 对应7月20日; 3) 统计同日的观看(去重)、点赞、评论总数,作为额外解释变量。
3)特征构建
① 滑动窗口均值(过去 k 天的平均关注数):
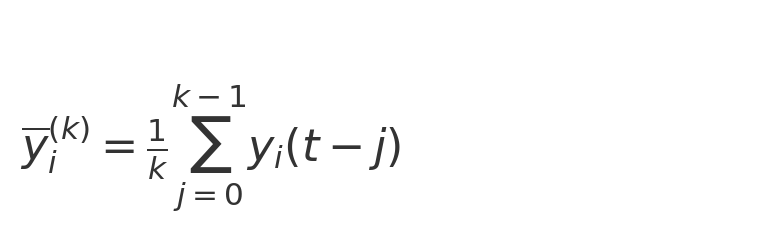
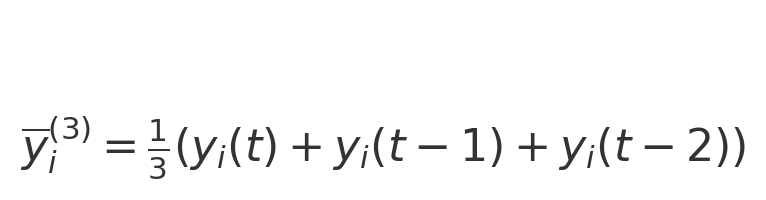
② 关注数一阶差分及增长率:
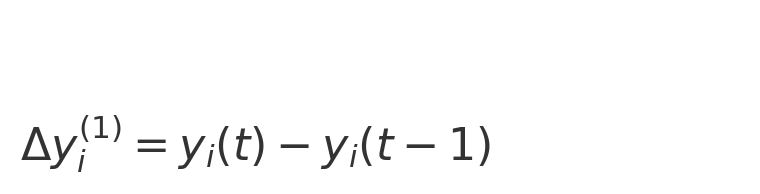
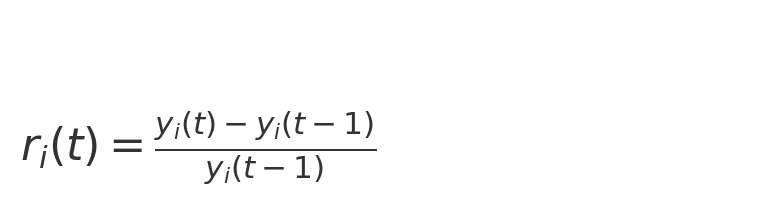
③ 交互强度特征:当日观看wi(t)、点赞li(t)、评论 ci(t),以及点赞率、评论率:

④ 周期性特征:是否工作日/周末,节假日标记。
4)模型选择
针对非负整数的关注量,可选用:
• Poisson 回归:

• 若数据非线性,可尝试随机森林回归、XGBoost回归等。
5)模型训练与调优
① 训练集:7月11–19日,验证集:7月20日; ② 时间序列交叉验证; ③ 评估指标:MAE、RMSE; ④ 特征重要性分析。
6)结果输出与排序
使用训练好的模型对每个博主预测7月21日关注量 \hat y_i(21),按预测值降序,取前5名,输出博主ID及预测关注数。
代码:
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import TimeSeriesSplit, GridSearchCV
from sklearn.metrics import mean_absolute_error, mean_squared_error
import warnings
warnings.filterwarnings('ignore')
# 1. 数据读取
# 假设附件1已保存为 'attachment1.csv',包含列: UserID, Behavior, BloggerID, Time
df = pd.read_csv('attachment1.csv', parse_dates=['Time'])
# 2. 数据预处理
# 筛选关注行为(Behavior==4)
df_follow = df[df['Behavior'] == 4].copy()
# 提取日期
df_follow['Date'] = df_follow['Time'].dt.date
# 统计每个博主每日关注数
daily_follow = (
df_follow
.groupby(['BloggerID', 'Date'])
.size()
.reset_index(name='follow_count')
)
# 生成完整时间序列 (2024-07-11 至 2024-07-20)
blogger_ids = daily_follow['BloggerID'].unique()
dates = pd.date_range('2024-07-11', '2024-07-20').date
tpl = pd.MultiIndex.from_product([blogger_ids, dates], names=['BloggerID','Date'])
full = pd.DataFrame(index=tpl).reset_index()
daily = full.merge(daily_follow, on=['BloggerID','Date'], how='left').fillna(0)
# 3. 特征工程
daily = daily.sort_values(['BloggerID','Date'])
# 滑动窗口特征
def rolling_feat(group):
group = group.copy()
group['roll3_mean'] = group['follow_count'].rolling(3, min_periods=1).mean()
group['roll5_mean'] = group['follow_count'].rolling(5, min_periods=1).mean()
group['diff1'] = group['follow_count'].diff(1).fillna(0)
group['rate1'] = group['diff1'] / (group['follow_count'].shift(1).replace(0, np.nan))
group['rate1'] = group['rate1'].fillna(0)
return group
daily = daily.groupby('BloggerID').apply(rolling_feat).reset_index(drop=True)
# 可以加入当日其他交互特征(观看、点赞、评论)
# 假设已提前统计好 daily_views, daily_likes, daily_comments 类似 daily_follow
# 这里以0填充示例
daily['views'] = 0
daily['likes'] = 0
daily['comments'] = 0
# 交互率
daily['like_rate'] = daily['likes'] / daily['views'].replace(0, np.nan)
daily['comment_rate'] = daily['comments'] / daily['views'].replace(0, np.nan)
daily[['like_rate','comment_rate']] = daily[['like_rate','comment_rate']].fillna(0)
# 4. 构建训练、验证集
daily['day_index'] = (pd.to_datetime(daily['Date']) - pd.to_datetime('2024-07-11')).dt.days + 1
daily = daily.sort_values(['BloggerID','day_index'])
# 训练: day_index 1-9, 验证: day_index 10
d_train = daily[daily['day_index'] <= 9]
d_val = daily[daily['day_index'] == 10]
features = ['roll3_mean', 'roll5_mean', 'diff1', 'rate1', 'views', 'likes', 'comments', 'like_rate', 'comment_rate']
target = 'follow_count'
# 5. 模型训练 (随机森林示例)
X_train = d_train[features]
y_train = d_train[target]
X_val = d_val[features]
y_val = d_val[target]
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 验证集评估
y_pred_val = model.predict(X_val)
print('Validation MAE:', mean_absolute_error(y_val, y_pred_val))
print('Validation RMSE:', np.sqrt(mean_squared_error(y_val, y_pred_val)))
# 6. 预测2024-07-21
day21 = daily[daily['day_index'] == 10].copy()
# 更新Date和day_index到21日
day21['Date'] = pd.to_datetime('2024-07-21').date()
day21['day_index'] = 11
# 计算特征(滚动窗口在group中自动扩展)
day21 = pd.concat([daily, day21]).groupby('BloggerID').apply(rolling_feat).reset_index(drop=True)
day21 = day21[day21['Date'] == pd.to_datetime('2024-07-21').date()]
X21 = day21[features]
day21['pred_follow'] = model.predict(X21)
# 7. 输出前5名结果
top5 = day21[['BloggerID','pred_follow']].sort_values('pred_follow', ascending=False).head(5)
print(top5)
5. 获奖技巧
(1)换位思考,从评委的角度思考问题
(2)打磨摘要,给评委“方便”,突出核心亮点

(3)图文并茂,排版精美,力争结果准确

(4)适当拔高,不谦虚也不过分
其中更详细的思路,各题目思路、代码、讲解视频、成品论文及其他相关内容,可以点击下方群名片哦!