深入浅出提示词工程(结合 DeepSeek)
提示词工程
Prompt 即提示、指令,所以提示工程也叫「指令工程」
用户输入的问题称为 Prompt,本文主要探讨 System Prompt(我将其翻译成「系统预设」)
使用 Prompt 的目的
直接提问
如「我该学 Vue 还是 React?」,能获得该问题的具体结果
固化到程序
通过设置 System Prompt,将大模型结合到程序中,成为系统功能的一部分
如「流量套餐客服系统」,能根据用户的问题有针对性的回答
Prompt 调优
找到好的 Prompt 是个持续迭代的过程,需要不断调优
训练数据已知
如果知道训练数据是怎样的,参考训练数据来构造 Prompt 是最好的选择
如 DeepSeek 的训练数据主要来自于中文互联网,它可能更擅长中文,那么就可以将提示词构造为中文
训练数据未知
如果不知道训练数据,可以:
向 AI 直接提问,看它是否会告诉你
如 ChatGPT 对 Markdown 格式友好,Claude 对 XML 友好
不断尝试不同的提示词
高质量 Prompt 核心要点:具体、丰富、少歧义
Prompt 经典构成
角色
给 AI 定义一个最匹配的任务角色,比如「你是一位软件工程师」
先定义角色,其实就是在开头把问题域收窄,减少二义性。有论文指出,在 Prompt 前加入角色定义,大模型的输出效果会更好
Lost in the Middle,大模型对 Prompt 开头、结尾的信息更敏感
指示
对任务进行具体描述
上下文
给出与任务相关的其他背景信息(尤其是在多轮交互中)
例子
必要时给出举例,学术中称为 one-shot learning, few-shot learning 或 incontext learning
能大幅度提升输出效果
输入
任务的输入信息,在提示词中明确的标识出输入
输出
输出的格式描述,以便后继模块自动解析模型的输出结果,如「以 Markdown 格式输出回答」
对话系统构建
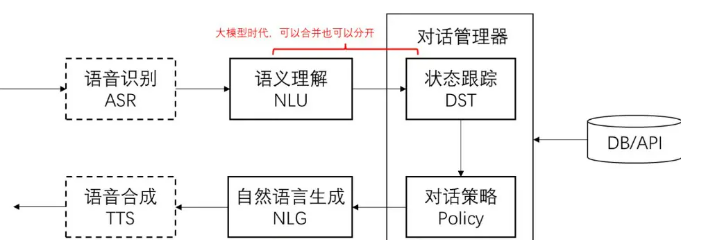
核心思路:
把输出的自然语言对话,转成结构化的表示
从结构化的表示,生成策略
把策略转成自然语言输出
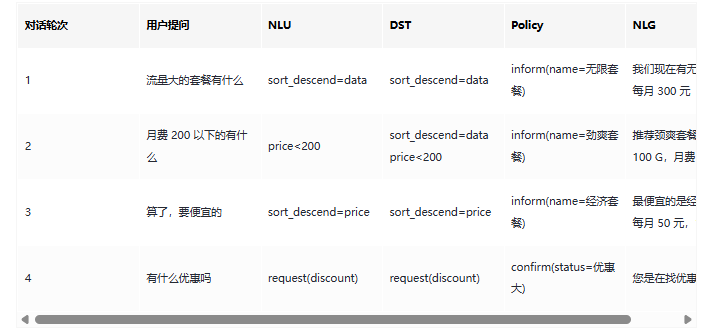
定义出的 Prompt:
你的任务是识别用户对手机流量套餐产品的选择条件。
每种流量套餐产品包含三个属性:名称(name),月费价格(price),月流量(data)
根据用户输入,识别用户在上述三种属性上的倾向。历史对话:
【此处将历史对话放入】以 JSON 格式输出
1. name 字段的取值为 string 类型,取值必须为以下之一:经济套餐、畅游套餐、无限套餐、校园套餐 或 null2. price 字段的取值为一个结构体或 null,包含两个字段:
(1)operator, string 类型,取值范围:'<='(小于等于),'>='(大于等于),'=='(等于)
(2)value,int 类型3. data 字段的取值为一个结构体或 null,包含两个字段:
(1)operator, string 类型,取值范围:'<='(小于等于),'>='(大于等于),'=='(等于)
(2)value, int 类型或 string 类型,string 类型只能是'无上限'4. 用户的意图可以包含 price 或 data 排序,以 sort 字段标识,取值为一个结构体:
(1)结构体中以"ordering"="descend"表示按降序排序,以"value"字段存储待排序的字段
(2)结构体中以"ordering"="ascend"表示按升序排序,以"value"字段存储待排序的字段只输出用户提及的字段,不要猜测任何用户未提及的字段,不输出为 null 的值一些例子:
便宜的套餐:{"sort":{"ordering"="ascend","value"="price"}}
有没有不限流量的:{"data":{"operator":"==","value":"无上限"}}
流量大的:{"sort":{"ordering"="descend","value"="data"}}
月费不超过200的:{"price":{"operator":"<=","value":200}}
就要月费180那个套餐:{"price":{"operator":"==","value":180}}用户输入:
办个 100G 以上的套餐执行的结果:
{"data": {"operator": ">=","value": 100}
}在这个 Prompt 中,将多轮对话(上下文)带入、规定了输出格式、给出了举例,这三种方式混合可以使输出效果达到最优
实现思路解析
上面的方式是用 Prompt 实现 DST,优点是节省了开发量,缺点是调优相对复杂
也可以用大模型 + 传统方法的形式进行开发,比如让大模型生成数据库查询语句,然后将该语句用传统方法进行数据库查询,再将查询结果替换掉大模型输出结果中的对应部分
优点是使得 DST 的可控性更高,缺点是开发量大
调优
加入指定回答模板,使回答更专业
非常抱歉,我们目前没有 200 元以内的套餐产品。不过,我们有一款经济套餐,每月只需支付 50 元,包含 10G 流量。这个套餐性价比很高,您可以考虑一下。如果您对其他套餐有任何需求或者疑问,我也可以为您提供更多选择。增加约束
回答亲切一些,不用说“抱歉”,直接给出回答。统一口径(用例子实现)
遇到类似问题,请参照以下回答:
问:流量包太贵了
答:亲,我们都是全省统一价哦
架构师思考
大模型应用架构师需要考虑哪些方面?
怎样能更准确?
让更多的环节可控
怎样能更省钱?
减少 Prompt 长度,减少 Tokens 的长度
怎样让系统简单好维护?
进阶技巧
思维链(Chain-of-Thought, CoT)
思维链是大模型自己涌现出来的一种神奇能力
它是被偶然发现的
有人在提问时以「Let’s think step by step」开头,发现 AI 会将问题分解成多步解决,使得输出的结果更加精确
原理:
让 AI 生成更多相关的内容,构成更丰富的「上文」,从而提升「下文」的正确率
对涉及计算和逻辑推理等复杂问题尤为有效
DeepSeek、GPT-o3 等均使用了思维链
自洽性(Self-Consistency)
一种有效对抗「幻觉」的手段,就像我们做数学题需要多次验算
核心:
同样的 Prompt 跑多次
通过投票选出最终结果
资料推荐
💡大模型中转API推荐
✨中转使用教程