强化学习入门:从零开始实现DDQN
在上一篇文章《深度强化学习入门:从零开始实现DQN》中,我们已经完整介绍了CartPole环境、DQN的理论背景以及实现流程。本篇文章将在此基础上,进一步介绍DQN的缺点,并通过双重深度Q网络(Double DQN, 简称DDQN) 的来解决这些问题,最终训练出一个更加稳定和可靠的CartPole智能体。
DQN的缺陷:过估计问题(Overestimation Bias)
在DQN中,目标值的计算公式为:
y=r+γmaxa′Qtarget(s′,a′;wT)y = r + \gamma \max_{a'} Q_{\text{target}}(s', a'; w_T) y=r+γa′maxQtarget(s′,a′;wT)
这里的max操作会直接选择使得Q值最大的动作,然后用目标网络计算其Q值。这带来一个问题:
- 神经网络预测的Q值本身存在估计误差。
- 由于
max操作总是会选择估计值最大的动作,因此会倾向于选择被高估的动作。 - 长期迭代后,这种系统性偏差会不断累积,导致Q值普遍被高估,训练不稳定。
DDQN的核心改进:解耦动作选择与评估
DDQN的提出正是为了解决过估计问题。其核心思想是:
- 动作选择(Action Selection)由主网络完成。
- 动作评估(Action Evaluation)由目标网络完成。
具体公式为:
y=r+γQtarget(s′,argmaxa′Qmain(s′,a′;w),wT)y = r + \gamma Q_{\text{target}}(s', \arg\max_{a'} Q_{\text{main}}(s', a'; w), w_T) y=r+γQtarget(s′,arga′maxQmain(s′,a′;w),wT)
相比DQN的公式,区别在于:
-
我们先用主网络找到下一个状态
s'下Q值最大的动作:a∗=argmaxa′Qmain(s′,a′;w)a^* = \arg\max_{a'} Q_{\text{main}}(s', a'; w) a∗=arga′maxQmain(s′,a′;w)
-
然后用目标网络来评估这个动作:
Qtarget(s′,a∗;wT)Q_{\text{target}}(s', a^*; w_T) Qtarget(s′,a∗;wT)
这样一来,“选动作”和“算值”分开进行,可以减轻过估计问题,从而让训练更稳定。
DDQN代码实现
在上一篇文章中,我们已经给出了DQN的代码结构。实现DDQN的改动非常小,主要在计算TD目标的部分。下面我们只展示和DQN不同的核心代码。
修改点:Algorithm类中的learn方法
def learn(self, experiences):"""更新主网络"""# 将经验样本转化为tensor类型states, actions, next_states, rewards, dones = Processor.convert_tensors(experiences)# 根据主网络得到预测Q值current_q_values = self.model(states).gather(dim=1, index=actions.unsqueeze(-1))# ==============================DQN 更新target_q_values============================# 根据target_network得到目标Q值# with torch.no_grad():# values = self.target_model(next_states).max(1)[0].detach()# target_q_values = rewards + (1-dones) * (Config.GAMMA * values)# =============================DDQN 更新target_q_values=============================# 根据target_network得到目标Q值with torch.no_grad():next_actions = self.model(next_states).argmax(1)values = self.target_model(next_states).gather(dim=1, index=next_actions.unsqueeze(-1)).squeeze(dim=1)target_q_values = rewards + (1 - dones) * Config.GAMMA * values# 计算lossloss = F.mse_loss(current_q_values, target_q_values.unsqueeze(1))# 反向传播loss.backward()# 梯度更新self.optimizer.step()# 梯度清0self.optimizer.zero_grad()# 向监视器添加梯度信息self.monitor.add_loss_info(loss.detach().item())self.train_count += 1# 更新target_networkif self.train_count % Config.TARGET_UPDATE_INTERVAL == 0:self.update_target_network()
其他部分保持不变
- 模型结构(Model类):仍然是多层感知机(MLP),输入状态输出动作的Q值。
- 经验回放、训练流程(train_workflow):和DQN一样。
- 配置文件与环境管理:也完全一致。
完整代码
结果
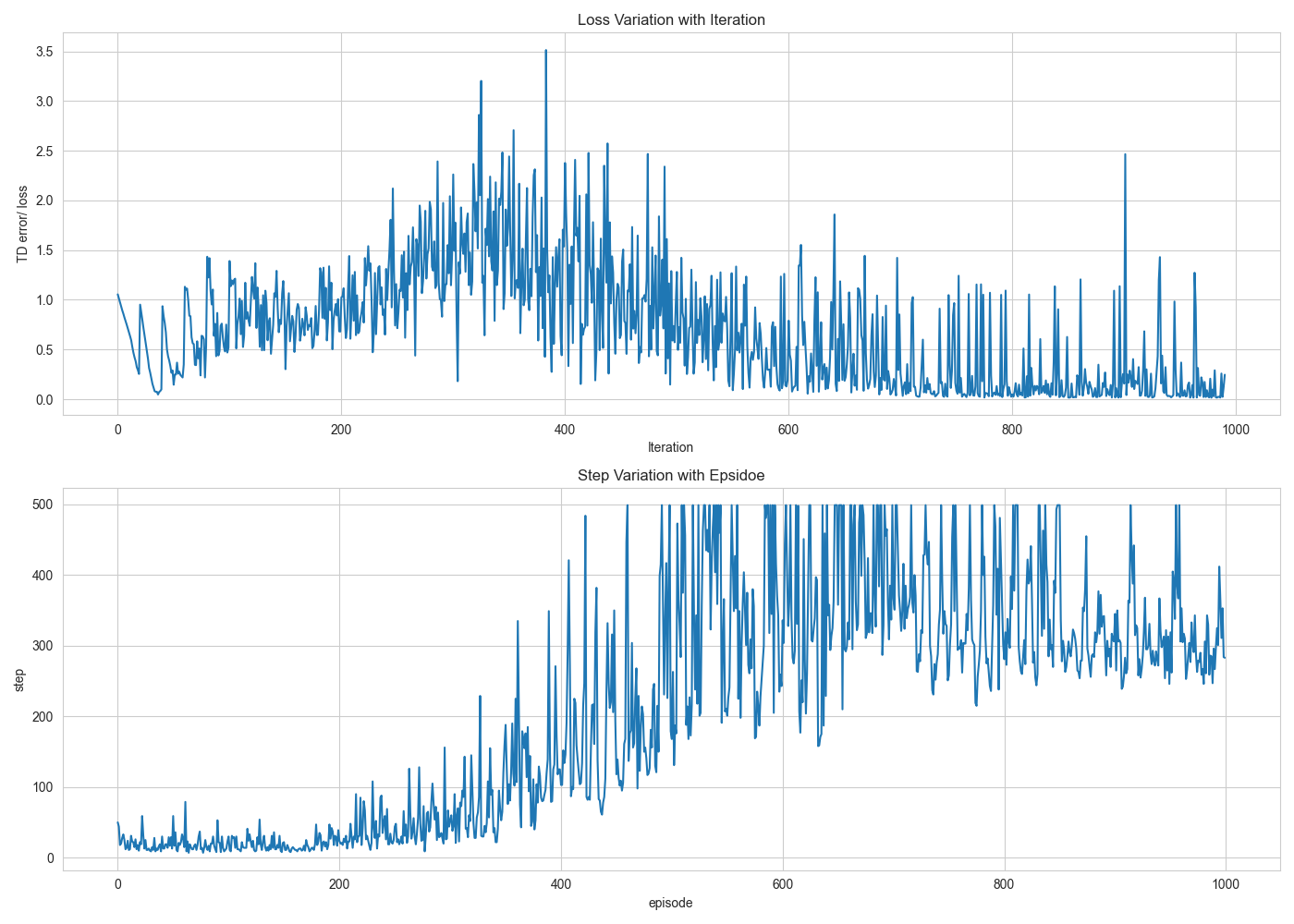
训练一千次回合,Loss以及回答长度随训练次数的变化趋势如下图所示:
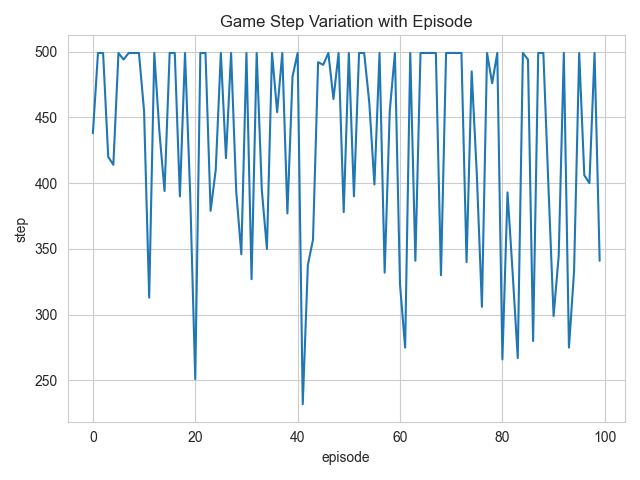
用训练好的智能体测试一百次,100次episode的回合长度如下图所示: