Netty从0到1系列之I/O模型
文章目录
- 一、内核态和用户态
- 1.1 核心概念: 为什么需要两种状态?
- 1.2 用户态【User Mode】
- 1.3 内核态【Kernel Mode】
- 1.4 系统调用
- 1.4.1 调用过程
- 1.4.2 图解
- 1.5 总结
- 1.5.1 对比一下
- 1.5.2 优缺点
- 1.5.3 总结
- 二、缓冲区
- 2.1 为什么需要缓冲区?
- 2.2 缓冲区的定义与职责
- 2.2.1 应用程序缓冲区
- 2.2.2 内核缓冲区
- Kernel Buffer / Page Cache
- 2.2.3 从磁盘读取文件
- 2.2.4 向磁盘写入文件
- 2.2.5 核心对比
- 2.2.6 常见优化策略
- 2.2.7 常见误区澄清
- 2.2.8 总结
- 2.2.9 常见疑问解答
- 2.3 协同工作
- 2.4 异同点总结
- 2.5 fsync的作用
- 三、I/O模型
- 3.1 核心概念: 一次 I/O 操作的两个阶段
- 3.2 阻塞 I/O (Blocking I/O)
- 3.3 非阻塞 I/O (Non-blocking I/O)
- 3.4 I/O 多路复用 (I/O Multiplexing)
- 3.5 信号驱动 I/O (Signal-driven I/O)
- 3.6 异步 I/O (Asynchronous I/O, AIO)
- 3.7 异同点
一、内核态和用户态
1.1 核心概念: 为什么需要两种状态?
想象一个公司:
- 用户态 (User Mode):就像公司的普通员工。
- 他们能做很多事:写文档、做设计、开会讨论。
- 但他们权限有限:不能直接动用公司的核心资金,不能随意进入高管办公室。需要钱时,必须提交申请(系统调用),走标准化流程。
- 内核态 (Kernel Mode):就像公司的CEO和核心管理层。
- 拥有最高权限:可以访问公司所有资源,调度所有员工,动用所有资金。
- 负责公司的核心运作和安全管理。
设计这两种状态的根本目的是:安全性和稳定性。
如果任何一个普通程序(员工)都能直接操作硬件(如磁盘、网卡、内存管理单元),那么一个程序的崩溃或恶意操作(比如一个 bug 写的程序)就可能导致整个系统(公司)崩溃。通过权限隔离,即使某个应用程序出错,内核也能接管控制权,防止系统垮掉。
1.2 用户态【User Mode】
- 定义:普通应用程序运行的环境。
- 权限:权限非常受限。只能执行普通的 CPU 指令,只能访问分配给它的一段专属内存空间(用户空间)。如果试图访问其他内存或执行特权指令,硬件会直接拒绝并触发一个异常,最后由内核来处理这个“违规”程序(通常是被杀死)。
- 目标:为应用程序提供一个安全、隔离的沙箱环境。
1.3 内核态【Kernel Mode】
- 定义:操作系统内核运行的环境。
- 权限:拥有机器的最高权限(CPU 的 Ring 0 特权级)。可以执行任何 CPU 指令,可以访问任何内存地址,可以直接操作所有的硬件设备(如磁盘、显示器、网卡等)。
- 目标:管理整个系统的硬件和软件资源,为应用程序提供安全、可靠的服务。
1.4 系统调用
普通员工(应用程序)不能自己动公司的钱(硬件资源),那他该怎么完成任务呢?他需要向管理层(内核)提交申请。
这个申请流程就是 系统调用 (System Call)。它是用户态程序主动进入内核态的唯一方式(除了异常和中断)。
1.4.1 调用过程
- 一个简单的示例: 程序向磁盘写入文件
- 你的程序(用户态)调用
write()函数。 write()函数封装了一个系统调用指令(如syscall)。- CPU 接收到这个指令后,会从用户态切换到内核态。
- 内核开始执行,它验证参数是否合法,然后代表你的程序,去操作硬盘驱动,将数据真正写入磁盘。
- 写入完成后,内核将结果返回给你的程序,并从内核态切换回用户态。
- 你的程序(用户态)继续执行。
1.4.2 图解
常见的系统调用:open, read, write, fork, execve, socket, send, recv 等。
1.5 总结
1.5.1 对比一下
| 特性 | 用户态 (User Mode) | 内核态 (Kernel Mode) |
|---|---|---|
| 权限级别 | 低(Ring 3) | 高(Ring 0) |
| 执行者 | 普通应用程序 | 操作系统内核 |
| 访问资源 | 受限的、隔离的用户空间内存 | 全部内存空间和硬件资源 |
| 稳定性影响 | 进程崩溃不影响系统和其他进程 | 内核崩溃会导致整个系统宕机 |
| 交互方式 | 通过系统调用/中断/异常请求内核服务 | 直接管理硬件,响应用户态请求 |
1.5.2 优缺点
优点
- 安全性:防止应用程序恶意或无意地破坏系统。
- 稳定性:将用户程序与核心系统隔离开,单个程序的错误不会导致系统崩溃。
- 抽象性:内核为上层应用提供了统一、简洁的硬件操作接口(系统调用),应用程序无需关心硬件细节。
缺点
- 性能开销:用户态和内核态之间的切换(上下文切换)是有成本的。需要保存和恢复大量的CPU状态、寄存器等。频繁的系统调用(如大量网络小数据包读写)会带来性能损失。
- 优化手段:这就是为什么需要像 I/O 多路复用(epoll)这样的技术,它通过一次系统调用获取多个就绪的IO事件,大大减少了切换次数。
1.5.3 总结
你可以把计算机系统看作一个工厂:
- 用户态是生产车间,工人们(应用程序)在里面完成各种任务。但他们不能随意离开车间,也不能直接操作电厂的总闸。
- 内核态是中央控制室,拥有最高权限,管理整个工厂的电力、物流和安全。
- 系统调用就是车间里的内线电话。工人需要操作大型设备时,必须打电话向控制室申请,由控制室的专家来安全地执行。
二、缓冲区
2.1 为什么需要缓冲区?
为了缓和速度矛盾,提高整体效率
想象一个物流系统:
- 生产者:一个高速运行的机器人(相当于 CPU)。
- 消费者:一个送货员(相当于磁盘、网卡等硬件)。
- 货物:数据。
机器人每秒能生产 100 件货物,而送货员每秒只能送 10 件。如果让机器人每生产一件就交给送货员,那么机器人大部分时间都在等待送货员回来,效率极低。
解决方案:设立一个仓库(缓冲区)
- 机器人可以不停地把货物放进仓库。
- 送货员可以按自己的节奏从仓库取货送货。
- 双方都高效工作,无需相互等待。
这个“仓库”就是缓冲区。它在计算机世界里无处不在,用于
解决高速 CPU 与低速 I/O 设备之间的速度不匹配问题。
2.2 缓冲区的定义与职责
2.2.1 应用程序缓冲区
Application Buffer
- 位置:用户空间的内存。
- 所有者:由应用程序创建、管理和释放(例如,在 C 语言中
char buffer[1024];,在 Java 中byte[] buffer = new byte[1024];)。 - 目的:
- 存放应用程序需要处理的原始数据或待发送的数据。
- 为应用程序提供数据处理的临时场所,方便进行解析、组装、计算等操作。
- 特点:生命周期与应用程序进程相关,进程结束即消失。
2.2.2 内核缓冲区
Kernel Buffer / Page Cache
- 位置:内核空间的内存。
- 所有者:由 Linux 内核统一管理。
- 目的:
- 磁盘 I/O:缓存磁盘数据(读缓存与写缓存),减少直接访问慢速物理磁盘的次数,这是提升 I/O 性能的最重要手段。
- 网络 I/O:组装或拆分网络数据包,以满足协议要求(如 TCP MSS)。
- 特点:内核管理的缓存,对所有进程是共享的(但数据本身不是),遵循一定的策略(如 LRU)进行换入换出。
2.2.3 从磁盘读取文件
场景: 从磁盘上读取一个文件
char app_buffer[4096];
int fd = open("file.txt", O_RDONLY);
read(fd, app_buffer, sizeof(app_buffer)); // 数据从磁盘 → 内核缓冲区 → 应用缓冲区
🔍 详细步骤:
- 应用程序调用
read()。 - CPU 切换到内核态。
- 内核检查内核缓冲区是否已有所需数据(缓存命中?)。
- 若有 → 直接拷贝到 应用缓冲区。
- 若无 → 触发磁盘 I/O,将数据加载到 内核缓冲区,再拷贝到应用缓冲区。
- 系统调用返回,数据现在位于
app_buffer中,供程序使用。
2.2.4 向磁盘写入文件
char app_buffer[] = "Hello, World!";
int fd = open("output.txt", O_WRONLY);
write(fd, app_buffer, strlen(app_buffer));
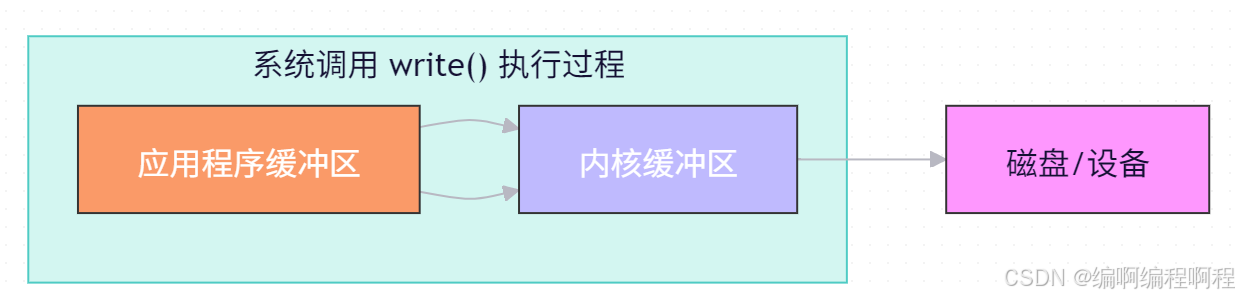
🔍 详细步骤:
- 调用
write(),数据从 应用缓冲区 拷贝到 内核缓冲区。 write()返回成功(不代表数据已落盘!)。- 内核在合适时机(如缓冲区满、定时刷新)将数据写入磁盘。
⚠️ 注意:若系统崩溃,未写入磁盘的数据会丢失。可使用 fsync() 强制落盘。
2.2.5 核心对比
| 特性 | 内核缓冲区 | 应用程序缓冲区 |
|---|---|---|
| 所属空间 | 内核空间(Kernel Space) | 用户空间(User Space) |
| 管理方 | 操作系统内核 | 应用程序开发者 |
| 访问权限 | 用户程序不能直接访问 | 应用程序可直接读写 |
| 主要目的 | 提升I/O效率、缓存、调度 | 减少系统调用、数据处理 |
| 生命周期 | 系统级,长期存在 | 由应用控制,函数/作用域决定 |
| 大小控制 | 由内核参数控制(如 vm.dirty_ratio) | 由程序员决定(如 malloc 大小) |
2.2.6 常见优化策略
✅ 合理设置缓冲区大小
- 太小 → 频繁系统调用 → 性能差。
- 太大 → 内存浪费,延迟增加。
- 推荐:使用
4096字节(一页大小)或64KB等常见块大小。
✅ 利用内核缓冲提高性能
- 连续读取时,内核会预读后续数据到缓冲区。
- 写操作可批量提交,减少磁盘寻道。
✅ 避免“双缓冲”冗余
- 某些高级I/O(如
mmap、splice、sendfile)可绕过内核缓冲或减少拷贝次数。 - 例如:
sendfile()实现零拷贝,直接在内核内部传输数据,不经过应用缓冲区。
2.2.7 常见误区澄清
| 误区 | 正确认知 |
|---|---|
write() 返回成功 = 数据已写入磁盘 | ❌ 实际只是写入了内核缓冲区 |
| 应用缓冲区越大越好 | ❌ 过大会浪费内存,影响其他进程 |
| 内核缓冲区可以被应用直接访问 | ❌ 用户态无法直接访问内核内存 |
| 关闭文件自动落盘 | ❌ 需显式调用 fsync() 才能确保 |
2.2.8 总结
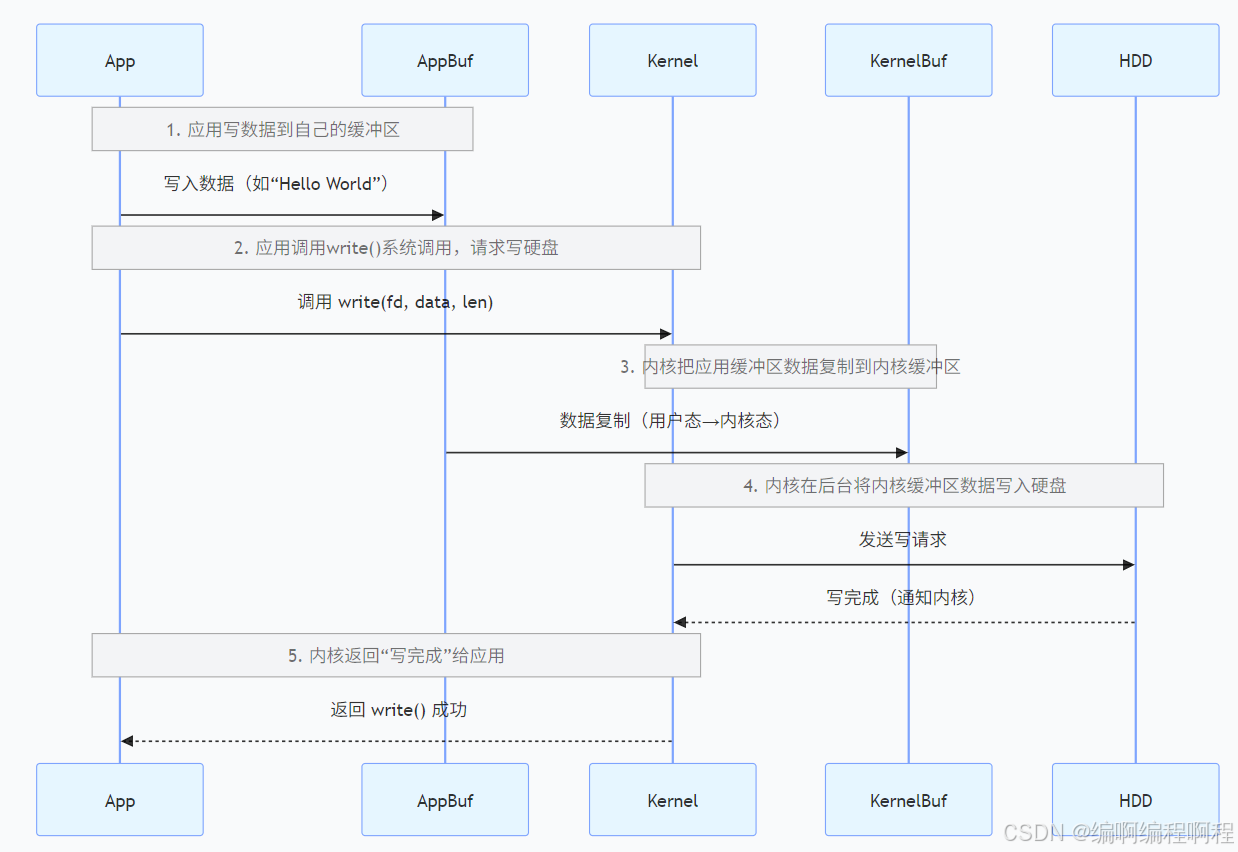
关键细节:
- 数据复制:步骤 3 是 “用户态内存→内核态内存” 的复制,这是有开销的(但相比直接等硬件,开销可忽略);
- 延迟写入:内核不会 “收到数据就立刻写硬盘”,而是会积累一定数据(或等待超时)再批量写,进一步减少硬盘 IO 次数(这就是 “写缓存” 的核心逻辑)。
2.2.9 常见疑问解答
- 为什么需要两层缓冲区?不能合并成一层吗?
不行。内核缓冲区是 “硬件保护与效率中枢”(必须由内核统一管理,防止应用乱操作硬件),应用缓冲区是 “应用灵活性中枢”(应用可自定义数据处理逻辑)。两层分工明确:内核管 “与硬件打交道”,应用管 “自己的数据逻辑”,缺一不可。 - 什么时候应用缓冲区可以省略?
当应用只需 “小批量、单次” 读写时(比如读 1 个字节),应用可以不分配缓冲区,直接通过系统调用让内核把数据 “临时复制到栈内存”。但高频读写场景下,省略应用缓冲区会导致频繁系统调用,效率极低。 - 内核缓冲区的数据会丢失吗?
会。如果内核缓冲区的数据还没写入硬盘(比如刚复制完应用数据,还没触发批量写),此时系统突然断电或内核崩溃,缓冲区数据会丢失。因此,关键数据需要调用fsync()系统调用,强制内核把缓冲区数据刷到硬盘。
2.3 协同工作
假设一个程序要执行 write(fd, data, size)。
流程图:
详细操作步骤
- 准备数据:应用程序将需要写入的数据准备好,放在自己的应用缓冲区中。
- 发起系统调用:应用程序调用
write系统调用,请求内核将数据写入文件。 - 上下文切换:CPU 从用户态切换到内核态。
- 数据拷贝:内核将数据从应用程序缓冲区(用户空间)拷贝到内核缓冲区(内核空间)中。这一步是必须的,因为内核不能直接信任和访问用户空间的数据。
- 立即返回:一旦数据进入内核缓冲区,
write系统调用就成功返回了!请注意,此时数据并没有真正落到磁盘上。 - 异步写入:内核会在后台(异步地)选择合适的时机(例如:缓冲区满了、间隔时间到了、应用程序调用
sync/fsync),将内核缓冲区中的数据真正写入磁盘。
这个过程被称为“延迟写”(Write-Back Cache),它极大地提高了性能。
- 优点:应用程序无需等待慢速的磁盘操作,可以继续执行后续代码,吞吐量得到提升。
- 风险:如果系统在数据写入磁盘前意外崩溃,数据可能会丢失。
2.4 异同点总结
| 特性 | 应用程序缓冲区 (Application Buffer) | 内核缓冲区 (Kernel Buffer / Page Cache) |
|---|---|---|
| 所在空间 | 用户空间 | 内核空间 |
| 创建管理者 | 应用程序 | Linux 内核 |
| 目的 | 暂存程序自身待处理/已处理的数据 | 缓存磁盘数据,优化IO性能;处理网络协议 |
| 生命周期 | 随进程存在而存在 | 随内核存在而存在,与具体进程无关 |
| 数据交换 | 与内核缓冲区通过系统调用拷贝数据 | 与硬件设备直接交互;与应用程序缓冲区拷贝数据 |
2.5 fsync的作用
理解了内核缓冲区,你就明白了为什么像数据库、日志系统这类对数据安全要求极高的程序,在重要操作后要调用 fsync(fd)。
write()返回成功只意味着数据安全地放在了内核缓冲区,并不保证已在磁盘上持久化。fsync()的作用是强制内核将指定文件的所有内核缓冲区数据立即、同步地刷到磁盘上。调用会一直阻塞,直到磁盘写入完成。这是一个保证数据落盘的安全操作,但性能开销很大。
一个生动的比喻:快递寄件
- 应用程序缓冲区:你家书房里的打包桌。你在上面把要寄的物品(数据)整理好,放进纸箱。
write()系统调用:你打电话叫快递小哥上门。- 内核缓冲区:快递公司的本地中转仓库。
- 数据拷贝:小哥上门,把包裹从你的书房(用户空间)搬到了他的货车(上下文切换),然后运回中转仓库(内核空间)。对你来说,包裹已经“寄出”了(
write返回)。 - 异步写入磁盘:快递公司的物流网络开始工作,包裹可能经过多个中转站,最终由大卡车送上千公里外的目的地(写入磁盘)。
fsync():你选择了加价的次日达航空件,并要求签收后必须回传单据。你必须确认包裹真的空运送达了才放心(数据安全落盘)。
三、I/O模型
3.1 核心概念: 一次 I/O 操作的两个阶段
在深入模型之前,必须明白一次 I/O 操作(比如 read)其实分为两个关键阶段:
- 等待数据就绪:数据从网络或磁盘到达内核缓冲区,等待被读取。
- 拷贝数据:将数据从内核缓冲区拷贝到我们应用程序的缓冲区。
所有的 I/O 模型差异,本质上都是在这两个阶段上的等待方式不同。
餐厅比喻
想象一个餐厅:
- 你(应用程序):想吃东西的顾客。
- 服务员(内核):为你提供服务的人。
- 厨房(数据源):准备食物的地方。
你的“点餐”动作就是一次 read 操作。
3.2 阻塞 I/O (Blocking I/O)
最传统、最简单的模型。
- 过程:你点完餐后,就一直坐在座位上盯着服务员,什么事也不干,直到服务员把菜端上来。在这期间,你完全被“阻塞”了。
- 对应:应用程序调用
read,线程会被挂起,直到内核将数据准备好并拷贝到用户空间,read调用才返回。
伪代码
// 1. 创建 socket(相当于“找餐厅”)
int sock = socket(AF_INET, SOCK_STREAM, 0);
// 2. 绑定端口(相当于“占座位”)
bind(sock, ...);
// 3. 监听连接(相当于“等服务员来点餐”,阻塞!)
listen(sock, 5);
// 4. 接受连接(等待客户端连接,阻塞!直到有客户端连入)
int client_fd = accept(sock, ...);
// 5. 读取客户端数据(等待数据就绪 + 拷贝数据,阻塞!)
char buf[1024];
ssize_t n = read(client_fd, buf, sizeof(buf));
// 6. 处理数据(直到 read 返回才执行,相当于“开始吃饭”)
process_data(buf, n);
- 优点:编程非常简单,符合直觉。
- 缺点:一个线程只能处理一个连接(一个顾客需要一个服务员)。要处理多个连接就需要开多个线程,系统资源消耗巨大,上下文切换开销大。
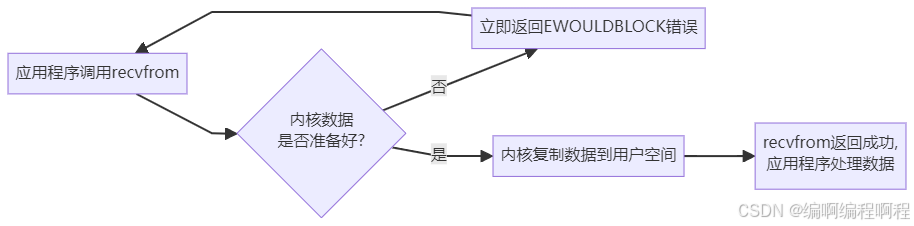
3.3 非阻塞 I/O (Non-blocking I/O)
“轮询”模型,忙等待。
- 过程:你点完餐后,不原地傻等。你每隔几分钟就问一次服务员:“好了没?”(轮询)。在问的间隙,你可以玩手机、聊天(线程可以处理其他任务),但你需要不断地主动去问。
- 对应:应用程序调用
read,如果内核数据没准备好,会立即返回一个错误(如 EWOULDBLOCK)。应用程序需要不断地循环调用read来询问数据是否就绪。
示例代码【伪代码】
int sock = socket(AF_INET, SOCK_STREAM, 0);
// 关键:将 socket 设置为非阻塞模式
fcntl(sock, F_SETFL, O_NONBLOCK); bind(sock, ...);
listen(sock, 5);// 轮询等待客户端连接(非阻塞,没连接就返回错误)
int client_fd;
while (1) {client_fd = accept(sock, ...);if (client_fd == -1) {if (errno == EWOULDBLOCK) {// 没有客户端连接,做点其他事(如打印日志)printf("暂无连接,稍等...\n");sleep(1); // 避免轮询太频繁,占用 CPUcontinue;}// 其他错误,退出break;}// 有连接了,读取数据(拷贝阶段仍阻塞)char buf[1024];ssize_t n = read(client_fd, buf, sizeof(buf));process_data(buf, n);break;
}
- 优点:可以在一个线程里通过轮询尝试处理多个连接。
- 缺点:轮询会消耗大量的 CPU 资源,因为绝大多数次的询问都是徒劳的(数据没准备好)。效率很低,通常不推荐
3.4 I/O 多路复用 (I/O Multiplexing)
“代理”模型,事件驱动,Linux 高并发网络编程的基石。
- 过程:餐厅专门设立一个接待员。你点完餐后,把手机号留给接待员,然后你就可以放心地去干自己的事(玩手机、聊天)。接待员会盯着所有顾客的餐。谁的餐好了,接待员就主动打电话通知谁:“您的餐好了,来取一下吧。”
- 这个“接待员”就是
select,poll,epoll这些系统调用。
- 这个“接待员”就是
- 对应:应用程序将多个文件描述符(socket)告诉
select/epoll,然后阻塞在select/epoll调用上。当其中任何一个描述符的数据就绪时,select/epoll返回,应用程序再调用read进行数据拷贝(这个拷贝过程是阻塞的)。
epoll伪代码
// 1. 创建 epoll 实例(相当于“雇秘书”)
int epfd = epoll_create1(0);
// 2. 创建 socket 并设为非阻塞
int sock = socket(AF_INET, SOCK_STREAM, 0);
fcntl(sock, F_SETFL, O_NONBLOCK);
bind(sock, ...);
listen(sock, 5);// 3. 告诉 epoll 要监控 sock 的“连接事件”(相当于“让秘书盯这家餐厅”)
struct epoll_event ev;
ev.events = EPOLLIN; // 关注“可读事件”(有连接/有数据)
ev.data.fd = sock;
epoll_ctl(epfd, EPOLL_CTL_ADD, sock, &ev);struct epoll_event events[10]; // 存储就绪事件
while (1) {// 4. 等待 epoll 通知(阻塞,直到有事件就绪)int nfds = epoll_wait(epfd, events, 10, -1);// 5. 遍历所有就绪的事件for (int i = 0; i < nfds; i++) {if (events[i].data.fd == sock) {// 有新客户端连接,接受连接int client_fd = accept(sock, ...);// 告诉 epoll 监控新客户端的“数据事件”ev.data.fd = client_fd;epoll_ctl(epfd, EPOLL_CTL_ADD, client_fd, &ev);} else {// 客户端有数据,读取并处理(拷贝阶段阻塞)int client_fd = events[i].data.fd;char buf[1024];ssize_t n = read(client_fd, buf, sizeof(buf));process_data(buf, n);// 移除已处理的 fdepoll_ctl(epfd, EPOLL_CTL_DEL, client_fd, NULL);close(client_fd);}}
}
- 优点:一个线程可以高效地管理成千上万个网络连接。大大减少了系统资源开销。这是 Nginx、Redis 等高性能服务器使用的模型。
- 缺点:编程模型比阻塞 I/O 复杂。对于连接数较少且都非常活跃的场景,性能可能反而不如多线程阻塞 I/O。
[!note]
selectvspollvsepoll:
select/poll:接待员需要拿着一份长长的名单(fd 集合),一个个打电话问厨房:“A的餐好了吗?B的餐好了吗?…”。效率随连接数线性下降。epoll:厨房有个状态屏,哪个餐好了会自动亮灯。接待员只需要看亮灯的那个就行。效率极高,与连接数无关。
3.5 信号驱动 I/O (Signal-driven I/O)
“收快递”模型。
- 过程:你点完外卖后,只需告诉快递员“到了给我打电话”,然后你就可以做自己的事。当外卖真的到了,快递员打电话(发送信号) 通知你,你再去门口取。
- 对应:应用程序开启套接字的信号驱动功能,并提供一个信号处理函数(回调函数)。内核在数据就绪时,会发送一个
SIGIO信号给应用程序。应用程序在信号处理函数中调用read进行数据拷贝。
信号驱动伪代码
// 信号处理函数:收到 SIGIO 信号后执行(数据就绪)
void sigio_handler(int signo) {char buf[1024];// 数据就绪,发起 read 请求(拷贝阶段阻塞)ssize_t n = read(client_fd, buf, sizeof(buf));process_data(buf, n);
}int main() {int sock = socket(AF_INET, SOCK_STREAM, 0);bind(sock, ...);listen(sock, 5);// 1. 注册信号处理函数(告诉内核“数据就绪发 SIGIO”)struct sigaction sa;sa.sa_handler = sigio_handler;sigemptyset(&sa.sa_mask);sa.sa_flags = 0;sigaction(SIGIO, &sa, NULL);// 2. 告诉内核“这个进程要处理 sock 的 SIGIO 信号”fcntl(sock, F_SETOWN, getpid());// 3. 开启 sock 的“信号驱动模式”int flags = fcntl(sock, F_GETFL);fcntl(sock, F_SETFL, flags | O_ASYNC);// 4. 进程可自由做其他事(如循环打印日志),不阻塞while (1) {printf("进程在做其他事...\n");sleep(2);}return 0;
}
- 优点:在等待数据期间,应用程序完全不被阻塞。
- 缺点:信号本身不可靠,编程复杂。在大量 IO 操作时,信号队列可能会溢出。实际应用中较少见。
3.6 异步 I/O (Asynchronous I/O, AIO)
“终极懒人”模型,最理想的方式。
- 过程:你去一家全自动餐厅,用平板点餐。点完后什么都不用管。餐厅会自动把做好的菜直接端到你的桌子上。整个过程中,你一次都没有呼叫过服务员。
- 对应:应用程序调用
aio_read,并告诉内核缓冲区地址和大小。调用立即返回。内核会自己完成“等待数据”和“拷贝数据”两个阶段。全部完成后,内核通过信号或回调函数通知应用程序“整个操作已完成,数据已经在你的缓冲区里了”。
flowchart LRA[应用程序调用aio_read] --> B[立即返回, 线程继续执行]B --> C[内核等待数据]C -- 数据报准备好 --> D[内核复制数据到用户空间]D -- 复制完成 --> E[内核通知应用程序<br>(如信号或回调)]E --> F[应用程序直接处理数据]
异步伪代码
#include <aio.h>
#include <signal.h>// 异步 IO 完成后的回调函数(内核自动调用)
void aio_completion_handler(sigval_t sigval) {// 获取 aio 控制块struct aiocb *cb = (struct aiocb *)sigval.sival_ptr;// 检查是否完成if (aio_error(cb) == 0) {ssize_t n = aio_return(cb);// 直接处理数据(拷贝已完成)process_data(cb->aio_buf, n);}// 释放资源free(cb->aio_buf);free(cb);
}int main() {int sock = socket(AF_INET, SOCK_STREAM, 0);bind(sock, ...);listen(sock, 5);int client_fd = accept(sock, ...);// 1. 初始化 aio 控制块(描述 IO 任务)struct aiocb *cb = malloc(sizeof(struct aiocb));cb->aio_buf = malloc(1024); // 用户缓冲区cb->aio_fildes = client_fd; // 要操作的 fdcb->aio_nbytes = 1024; // 读取字节数cb->aio_offset = 0; // 文件偏移(网络 IO 忽略)// 2. 设置完成通知方式:调用回调函数cb->aio_sigevent.sigev_notify = SIGEV_THREAD;cb->aio_sigevent.sigev_notify_function = aio_completion_handler;cb->aio_sigevent.sigev_value.sival_ptr = cb; // 传递 cb 给回调// 3. 发起异步 read 请求(全程非阻塞,立即返回)aio_read(cb);// 4. 进程自由做其他事(如循环打印)while (1) {printf("进程在做其他事...\n");sleep(2);}return 0;
}
- 优点:应用程序在整个过程中完全不被阻塞,只需接收最终结果。是真正的异步。
- 缺点:Linux 原生 AIO 实现不完善(主要对磁盘 IO 支持好,网络 IO 支持差),编程复杂。Windows 的 IOCP 是真正的异步 IO 模型。
3.7 异同点
| 模型 | 第一阶段:等待数据 (等待就绪) | 第二阶段:拷贝数据 | 核心优点 | 核心缺点 |
|---|---|---|---|---|
| 阻塞 I/O | 应用程序阻塞 | 应用程序阻塞 | 编程简单 | 资源利用率低,1:1 模型 |
| 非阻塞 I/O | 应用程序轮询 | 应用程序阻塞 | 可单线程处理多连接 | CPU 空转浪费严重 |
| I/O 多路复用 | 内核阻塞(select/epoll) | 应用程序阻塞 | 高并发核心,1:N 模型 | 编程复杂,拷贝阶段仍阻塞 |
| 信号驱动 I/O | 应用程序不阻塞 | 应用程序阻塞 | 等待阶段不阻塞 | 信号不可靠,编程复杂 |
| 异步 I/O | 应用程序不阻塞 | 应用程序不阻塞 | 真正的异步,性能潜力最高 | Linux 实现不完善,编程最复杂 |
最重要的区别:
- 与 I/O 多路复用的区别:I/O 多路复用是 “告诉我们哪个 I/O 准备好了”(然后需要我们自己动手去读),而异步 I/O 是 “帮我做完 I/O 并通知我结果”。
- 与信号驱动 I/O 的区别:信号驱动 I/O 是内核在第一阶段完成后通知我们,第二阶段仍需我们同步完成(我们自己去
read)。而异步 I/O 是内核在两个阶段都完成后才通知我们。