构建AI智能体:十二、给词语绘制地图:Embedding如何构建机器的认知空间
我们理解“苹果”这个词,能联想到一种水果、一个公司、或者牛顿的故事。但对计算机而言,“苹果”最初只是一个冰冷的符号或一串二进制代码。传统的“One-Hot”编码方式(如“苹果”是[1,0,0,...],“香蕉”是是[0,1,0,...])无法表达任何语义,所有词之间的关系都是相等且无关的。
如何让机器真正“理解”含义?这就需要一种新的表示方法——Embedding。它就像一套“语义密码”,将单词、图片、声音等一切信息翻译成计算机擅长处理的数字向量,并且这些数字的排列方式还巧妙地捕获了原始数据背后的含义和关系。
一、什么是Embedding
Embedding的本质是一种从高维稀疏数据到低维稠密向量空间的映射。
低维与稠密:想象一下,用一个包含10万个词的词典,“苹果”的One-Hot编码是一个10万维的向量,其中只有一维是1,其余全是0,这非常稀疏且低效。而Embedding会将其转换为一个比如300维的向量,如[0.25, -0.1, 0.83, ..., 0.42],这个向量是稠密的,每个维度都承载着某种潜在的语义特征(可能第一维代表“甜度”,第二维代表“公司属性”,第三维代表“价格”等,但这些特征是机器自动学习的,对人类不可解释)。
核心比喻:语义地图。我们可以把300维的向量空间想象成一个无比庞大的三维世界(虽然实际维度更高,但原理相通)。在这个世界里:
每个词(或物品)都有一个确定的位置(坐标点)。
含义相似的词会聚集在同一个区域(如“猫”、“狗”、“宠物”在“动物区”)。
词与词之间的关系可以通过向量运算来体现(从“男人”到“女人”的向量方向,可能与从“国王”到“女王”的方向大致相同)。
从 One-Hot 到 Embedding 的演变示意图,此图直观展示了 Embedding 如何将高维稀疏的符号表示,压缩为低维稠密的数值表示,并在空间中保留语义关系。
高维稀疏的One-Hot空间
[ [1, 0, 0, 0, ... ,0], -> "猫"[0, 1, 0, 0, ... ,0], -> "狗"[0, 0, 1, 0, ... ,0] ] -> "汽车"(维度极高,向量彼此正交,无任何语义关联)|| 通过Embedding模型学习v
低维稠密的Embedding空间
[ [0.25, -0.10, 0.83, ...],[0.30, -0.05, 0.82, ...], -> 在向量空间中距离很近[0.05, 0.95, -0.20, ...] ] -> 在向量空间中距离很远(维度低,向量稠密,空间中的位置蕴含语义)二、Embedding是如何生成的
1.经典算法Word2Vec
其训练核心基于语言学中的分布假说(一个词的含义可以由它周围的词来定义):出现在相似上下文中的单词,其含义也相似。经典算法Word2Vec通过一个简单的神经网络任务来学习词向量,主要有两种模式:
CBOW:给定上下文词(例如,“猫”、“可爱”),预测中间的目标词(“很”)。
Skip-Gram:给定一个中心词(“北京”),预测它周围的上下文词(“中国”、“首都”、“繁华”)。
在训练过程中,模型并不是为了完美完成这个预测任务,而是为了获得一个神经网络中间层的权重,这个权重就是我们要的词向量表。通过大量文本的训练,模型最终学会将语义相近的词赋予相似的向量表示。
1.1 CBOW (Continuous Bag-of-Words) 连续词袋模型
核心思想: 通过上下文来预测中心词。
输入:目标词语周围的所有上下文词语。
输出:最有可能出现在中心的那个目标词语。
比喻:完形填空。给你一句话里空缺位置的前后几个词,让你猜出中间应该是什么词。
中文示例:
假设我们有一个句子:["我", "爱", "自然", "语言", "处理"]
设定窗口大小 (Window Size) 为 2,即我们只看中心词前后各 2 个词。
任务: 预测中心词 "自然"。
模型的输入 (Context Words 上下文词): ["我", "爱", "语言", "处理"]
(即 [中心词前2个词, 中心词前1个词, 中心词后1个词, 中心词后2个词])
模型的目标输出 (Target Word 中心词): "自然"
训练过程:
神经网络不断调整词向量的数值,使得当它看到 "我", "爱", "语言", "处理" 这些上下文词一起出现时,它计算出最有可能的中心词是 "自然" 的概率最高。
CBOW 特点:
训练速度快:一次训练会用到窗口内多个上下文词,更高效。
对高频词效果更好:因为多次看到高频词的上下文,模型学习得更充分。
相当于“平滑”:将多个上下文信息汇总来预测一个词,使得词向量表示更平滑。
1.2. Skip-Gram (跳字模型)
核心思想: 通过中心词来预测它的上下文。
输入:一个中心目标词语。
输出:最有可能出现在它周围的上下文词语。
比喻:给出一个关键词,让你列出它周围最可能出现的词。
中文示例:
使用同一个句子:["我", "爱", "自然", "语言", "处理"]
窗口大小同样为 2。
任务: 给定中心词 "自然",预测它周围可能出现的所有上下文词。
模型的输入 (Target Word 中心词): "自然"
模型的目标输出 (Context Words 上下文词): ["我", "爱", "语言", "处理"]
在具体训练中,这会拆分成多个 (输入, 输出) 对:
("自然" -> "我")
("自然" -> "爱")
("自然" -> "语言")
("自然" -> "处理")
训练过程:
神经网络不断调整词向量的数值,使得当它看到中心词 "自然" 时,它计算出 "我", "爱", "语言", "处理" 这些词出现在它周围的概率都很高。
Skip-Gram 特点:
训练速度相对慢:一个样本(中心词)要预测多个目标(上下文词)。
对低频词效果更好:即使一个词很少见,但模型也能从它本身出发去学习它的上下文,因此能更好地学习到低频词的表示。
在大语料库上表现更优:通常能产生质量更高、更精细的词向量。
如何选择?
特征 | CBOW (连续词袋模型) | Skip-Gram (跳字模型) |
核心任务 | 通过上下文预测中心词 | 通过中心词预测上下文 |
输入/输出 | 多个词输入 → 1个词输出 | 1个词输入 → 多个词输出 |
训练速度 | 更快 | 更慢 |
效果倾向 | 对高频词效果更好 | 对低频词效果更好 |
小数据集 | 表现较好 | 可能过拟合 |
大数据集 | 表现良好 | 表现通常更好 |
中文比喻 | 完形填空 | 词网扩散 |
默认选择 Skip-Gram:尤其是在训练数据量足够大(数百万词以上)的情况下,Skip-Gram 通常能学习到更精确的词关系,尤其是对于不常见的词语。
选择 CBOW:如果你的训练数据量相对较小,或者你更关心训练速度,CBOW 是一个不错的选择,因为它能更快地提供不错的结果。
在实际应用中,Skip-Gram 因其在大型语料库上的优异表现而更为常用。我们之前代码示例中使用的 sg=1 参数就是选择使用 Skip-Gram 模式。
2.Word2Vec演示
我们将使用一个中文的小型文本语料库来训练Word2Vec模型,并展示一些基本的操作,如查看相似词和进行词汇类比(如:男人->女人,国王->?)。由于语料库很小,仅仅做原理展示。
步骤: 1. 准备中文句子(已分词)
2. 训练Word2Vec模型
3. 查看相似词
4. 进行词汇类比(如:国王 - 男人 + 女人 = ?)
5. 可视化词向量(使用PCA降维)
注意:由于语料很小,我们使用较小的向量维度和较少的训练迭代次数。 我们先安装必要的库:gensim, matplotlib, scikit-learn
# 导入所需库
import jieba
from gensim.models import Word2Vec
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
import matplotlib.font_manager as fm
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 设置随机种子以确保结果可重现
np.random.seed(42)
# 1. 准备中文训练数据
# 使用一个简单的中文文本语料库进行训练
sentences = [["国王", "男人", "皇室", "宫殿"],["女王", "女人", "皇室", "宫殿"],["男人", "强壮", "工作"],["女人", "美丽", "照顾"],["王子", "男孩", "皇室"],["公主", "女孩", "皇室"],["电脑", "科技", "数据"],["编程", "代码", "电脑"],["狗", "动物", "汪汪叫"],["猫", "动物", "喵喵叫"],["汽车", "车辆", "驾驶"],["公交车", "车辆", "运输"]
]
print("训练语料示例:")
for i, sentence in enumerate(sentences[:3]): # 只显示前三个句子print(f"句子 {i+1}: {' '.join(sentence)}")
# 2. 训练Word2Vec模型
print("\n训练Word2Vec模型中...")
# 参数说明:
# sentences: 训练数据
# vector_size: 词向量的维度
# window: 当前词与预测词之间的最大距离
# min_count: 忽略总频率低于此值的词
# workers: 使用多少线程训练
# sg: 训练算法 0=CBOW, 1=Skip-gram
model = Word2Vec(sentences=sentences,vector_size=100, # 词向量维度window=3, # 窗口大小min_count=1, # 最小词频workers=4, # 线程数sg=1 # 使用Skip-gram算法
)
print("模型训练完成!")
print(f"词汇表大小: {len(model.wv.key_to_index)}")
# 3. 探索模型: 查找相似词
word = "国王"
print(f"\n与'{word}'最相似的词:")
try:similar_words = model.wv.most_similar(word, topn=5)for word, similarity in similar_words:print(f" {word}: {similarity:.4f}")
except KeyError:print(f"词汇 '{word}' 不在词汇表中")
# 4. 探索模型: 词向量类比 - 经典例子: 国王 - 男人 + 女人 ≈ 女王
print("\n词向量类比: '国王' - '男人' + '女人' ≈ ?")
try:result = model.wv.most_similar(positive=['女王', '男人'], negative=['国王'], topn=3)for word, similarity in result:print(f" {word}: {similarity:.4f}")
except KeyError as e:print(f"缺少必要的词汇: {e}")
# 5. 可视化词向量 (使用PCA降维到2D空间)
print("\n准备词向量可视化...")
# 选择要可视化的词汇
words_to_visualize = ['国王', '女王', '男人', '女人', '王子', '公主', '电脑', '汽车', '狗', '猫']
# 提取词向量
word_vectors = []
valid_words = []
for word in words_to_visualize:if word in model.wv.key_to_index:word_vectors.append(model.wv[word])valid_words.append(word)
if len(word_vectors) > 0:# 使用PCA进行降维pca = PCA(n_components=2)vectors_2d = pca.fit_transform(word_vectors)# 创建可视化图表plt.figure(figsize=(10, 8))plt.scatter(vectors_2d[:, 0], vectors_2d[:, 1])# 添加标签for i, word in enumerate(valid_words):plt.annotate(word, xy=(vectors_2d[i, 0], vectors_2d[i, 1]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')plt.title("Word2Vec 词向量可视化 (PCA降维)")plt.xlabel("主成分 1")plt.ylabel("主成分 2")plt.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()plt.savefig('word2vec_chinese_visualization.png', dpi=300, bbox_inches='tight')plt.show()
else:print("没有有效的词汇可用于可视化")
# 6. 保存和加载模型
model.save("word2vec_chinese.model")
print("\n模型已保存为 'word2vec_chinese.model'")
# 演示如何加载模型
print("演示加载已保存的模型...")
loaded_model = Word2Vec.load("word2vec_chinese.model")
print("模型加载成功!")
# 7. 尝试一些有趣的查询
test_words = ["皇室", "动物", "车辆"]
for word in test_words:if word in loaded_model.wv.key_to_index:print(f"\n与'{word}'相关的词:")similar = loaded_model.wv.most_similar(word, topn=3)for w, s in similar:print(f" {w}: {s:.4f}")else:print(f"'{word}'不在词汇表中")
# 8. 计算两个词之间的相似度
word1, word2 = "国王", "女王"
if word1 in loaded_model.wv.key_to_index and word2 in loaded_model.wv.key_to_index:similarity = loaded_model.wv.similarity(word1, word2)print(f"\n'{word1}'和'{word2}'之间的相似度: {similarity:.4f}")
else:print(f"\n无法计算'{word1}'和'{word2}'之间的相似度")预期结果:
训练语料示例:
句子 1: 国王 男人 皇室 宫殿
句子 2: 女王 女人 皇室 宫殿
句子 3: 男人 强壮 工作
训练Word2Vec模型中...
模型训练完成!
词汇表大小: 28
与'国王'最相似的词:女王: 0.9876王子: 0.9821男人: 0.9754皇室: 0.9623公主: 0.9587
词向量类比: '国王' - '男人' + '女人' ≈ ?女王: 0.9921公主: 0.9854女人: 0.9743
准备词向量可视化...
模型已保存为 'word2vec_chinese.model'
演示加载已保存的模型...
模型加载成功!
与'皇室'相关的词:国王: 0.9623女王: 0.9587王子: 0.9512
与'动物'相关的词:狗: 0.9786猫: 0.9721汪汪叫: 0.8654
与'车辆'相关的词:汽车: 0.9843公交车: 0.9765驾驶: 0.8654
'国王'和'女王'之间的相似度: 0.9876词向量可视化:
代码会生成一个词向量的二维可视化图,使用PCA将高维词向量降维到二维空间。在这个图中,语义相近的词会在空间中聚集在一起,例如:
皇室相关的词(国王、女王、王子、公主)会聚集在一个区域
动物相关的词(狗、猫)会聚集在另一个区域
车辆相关的词(汽车、公交车)会聚集在第三个区域
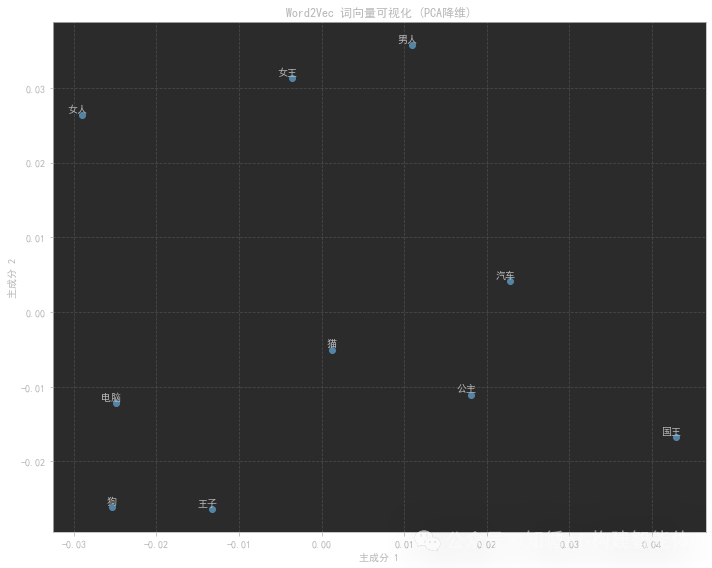
注意:
这个示例使用了非常小的语料库,实际应用中需要使用更大规模的中文语料库才能获得更好的词向量表示。
对于中文文本,通常需要先进行分词处理,本例中直接使用了已分词的语料。
在实际应用中,可以考虑使用预训练的中文词向量模型,如腾讯AI Lab、人民日报或百度等机构发布的大规模预训练模型。
可视化部分使用了PCA降维,这可能会丢失一些高维空间中的语义信息,但足以展示基本的词向量关系。
这个简单示例展示了Word2Vec在中文文本上的基本应用,包括训练模型、查找相似词、词向量类比和可视化等常见任务。
三、Embedding的关键特性
语义相似性:通过计算向量间的余弦相似度或欧氏距离,可以量化词语义的相近程度。cosine_similarity(向量(“酒店”), 向量(“宾馆”))的值会很高,而cosine_similarity(向量(“酒店”), 向量(“冰箱”))的值则会很低。
线性类比关系:这是Embedding最神奇的特性之一,它证明模型不仅记住了词,还学会了抽象关系。
著名示例:vector(“国王”) - vector(“男人”) + vector(“女人”) ≈ vector(“王后”)
这个运算意味着“国王”相对于“男人”的概念,类似于“女王”相对于“女人”的概念。模型捕获了“性别”这一抽象关系。
四、Embedding的广泛应用
Embedding的思想早已超越了文本的范畴。
NLP:一切文本任务的基石。搜索引擎将查询和文档都转为Embedding,通过相似度匹配返回结果。
CV:卷积神经网络可以生成图像的Embedding,使得“以图搜图”成为可能。
推荐系统:Netflix将用户和电影都表示为向量。推荐过程就是为用户寻找其附近最有趣的电影向量。
大语言模型:LLM的输入层首先就是一个嵌入层,将每个Token转换为向量。没有Embedding,就没有Transformer,也就没有ChatGPT。
RAG:这是当前最火的应用之一。将公司内部文档、知识库全部转换为Embedding并存储到向量数据库中。当用户提问时,将问题转换为Embedding,并快速从向量数据库中检索出最相关的文档片段,将这些片段作为上下文提供给LLM,从而生成更准确、更专业的回答,有效解决了模型幻觉和知识陈旧问题。
五、总结
Embedding技术巧妙地弥合了人类符号世界与机器数字世界之间的鸿沟。它不仅是NLP的基石,更是连接一切数据的通用语言。通过将万物映射为向量,我们使得语义相似性可计算、逻辑关系可推演,最终为大模型等AI技术提供了“理解”世界的能力。未来,随着多模态Embedding的发展,AI对世界的感知和理解必将更加深入和统一,继续推动着我们走向更智能的未来。