数据预处理
回顾Pandas 处理丢失数据
检测缺失值
isnull(): 判断数据框中的每个单元格是否为空(NaN 或 None),返回布尔值 DataFrame
import pandas as pd
missing_values = ["n/a", "na", "--"]
df = pd.read_csv('property-data.csv', na_values = missing_values)
print(df['NUM_BEDROOMS'])
print(df['NUM_BEDROOMS'].isnull())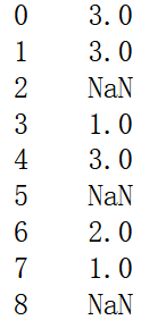

删除缺失值
dropna(): 删除包含空字段的行(默认)或列。
参数:axis(0=行/1=列), how(‘any’/‘all’), thresh(非缺失值最小数量), subset(检查列), inplace(是否原地修改)。
import pandas as pd
missing_values = ["n/a", "na", "--"]
df = pd.read_csv('property-data.csv', na_values = missing_values)
new_df = df.dropna()
print(new_df)
填充缺失值
fillna(): 用指定的值(常数、均值、中位数等)替换空字段。
import pandas as pd
missing_values = ["n/a", "na", "--"]
df = pd.read_csv('property-data.csv', na_values = missing_values)
df.fillna(666, inplace = True)
print(df)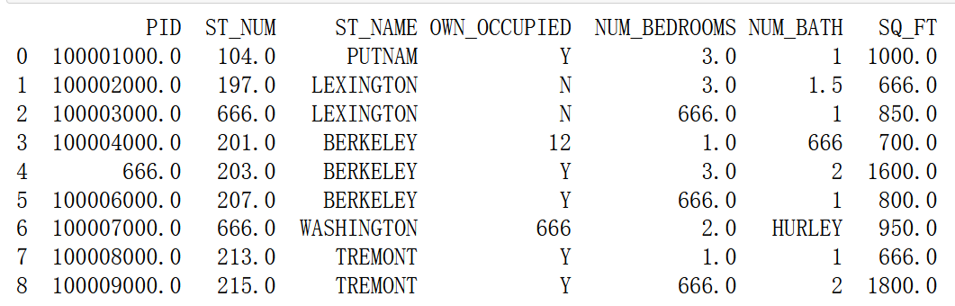
mean(): 计算列的均值,用于填充该列的空单元格。
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].mean()
print(x)
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
#191.42857142857142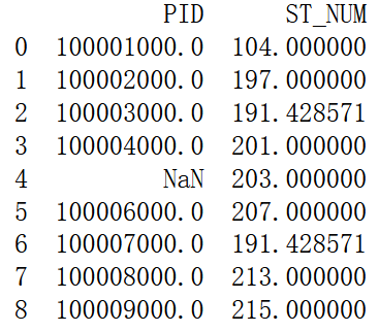
median(): 计算列的中位数,用于填充该列的空单元格。
sklearn处理缺失值
sklearn.impute.SimpleImputer处理缺失值
提供更灵活的缺失值填补策略:
使用均值 (strategy='mean') 填补。
from sklearn.impute import SimpleImputer
# 默认使用均值填补
imp_mean = SimpleImputer(missing_values=np.nan, strategy="mean")
imp_mean = imp_mean.fit_transform(age.reshape(-1,1))
imp_mean[:10]
使用中位数 (strategy='median') 填补。
# 使用中位数填补
imp_median = SimpleImputer(missing_values=np.nan, strategy="median")
imp_median = imp_median.fit_transform(age.reshape(-1,1))
imp_median[:10]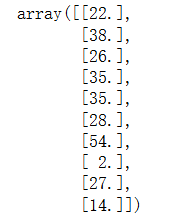
使用常数 (strategy='constant', fill_value=xxx) 填补。
# 使用常数(0)填补
imp_0 = SimpleImputer(strategy="constant", fill_value=0)
imp_0 = imp_0.fit_transform(age.reshape(-1,1))
imp_0[:10]
使用众数 (strategy='most_frequent') 填补。
# 使用众数填补Embarked
Embarked = data.loc[:,"Embarked"].values.reshape(-1,1)
imp_mode = SimpleImputer(strategy = "most_frequent")
data.loc[:,"Embarked"] = imp_mode.fit_transform(Embarked)
data.head()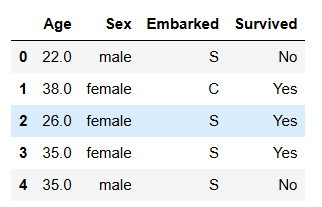
数据标准化 (无量纲化)
标准化定义:将特征数据的分布调整成标准正态分布,也叫高斯分布,也就是使得数据的均值为 0,方差为 1。
原因:如果有些特征的方差过大,则会主导目标函数从而使参数估计器无法正确地去学习其他特征。
目的: 将不同规格或分布的数据转换到统一规格或特定分布,消除量纲影响,便于比较和模型计算。
类型:
中心化: 数据平移 (如:减去均值)。
缩放: 数据范围调整 (如:除以固定值、取对数)。
方法:
最大最小值标准化 (归一化):preprocessing.MinMaxScaler(): 将数据缩放到 [0, 1] 或指定区间。
# 数据归一化
from sklearn.preprocessing import MinMaxScalerdata = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
# 创建实例
scaler = MinMaxScaler()
# fit 生成min和max
scaler = scaler.fit(data)
# 导出结果
result = scaler.transform(data)
# # 参数feature_range实现将数据归一化到指定范围
# data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
# scaler = MinMaxScaler(feature_range=[5,10])
# result = scaler.fit_transform(data)
from sklearn.preprocessing import MinMaxScalerdata = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler(feature_range=(5,10)) # 查看数据归一化结果
result = scaler.fit_transform(data)
print("归一化结果:")
print(result)#归一化结果:
#[[ 5. 5. ]
# [ 6.25 6.25]
# [ 7.5 7.5 ]
# [10. 10. ]]
# 数据标准化
Z 值标准化 (标准差标准化):preprocessing.StandardScaler(): 将数据转换为均值为 0、标准差为 1 的分布。
# 数据标准化
from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
# 创建实例
scaler = StandardScaler()
# 生成均值和方差
scaler.fit(data)
# 均值
scaler.mean_
#array([-0.125, 9. ])
# 导出结果
x_std = scaler.transform(data)
# 导出的结果的均值,用mean()查看均值
x_std.mean()
#0.0
# 导出结果的方差
x_std.std()
#1.0
特征编码
特征类型:
名义变量: 类别间无顺序、独立 (如:性别-男/女)。
有序变量: 类别间有顺序、不可计算 (如:学历-小学/初中/高中)。
有距变量: 数值间有联系、可计算 (如:分数)。
编码技术:
独热编码 (One-Hot Encoding): OneHotEncoder。为名义变量的每个类别创建独立的二进制特征 (0/1)。
序号编码 (Ordinal Encoding): 将有序变量的类别映射为有序整数 (如:小学->0, 初中->1, 高中->2)。
目标标签编码 (Target Encoding / Label Encoding): 根据目标变量对类别进行编码(文档未详细说明,通常指将类别标签转换为数值)。
数据二值化
将数值数据根据设定的阈值转换为两类 (0 或 1)。例如,大于阈值的为 1,否则为 0
import pandas as pd
from sklearn.preprocessing import Binarizer# 假设data是一个DataFrame
data = pd.DataFrame({'Age': [22, 38, 26, 35, 35],'Sex': ['male', 'female', 'female', 'female', 'male'],'Embarked': ['S', 'C', 'S', 'S', 'S'],'Survived': ['No', 'Yes', 'Yes', 'Yes', 'No']
})# 复制data到data_2
data_2 = data.copy()# 将年龄列转换为二维数组
X = data_2.iloc[:, 0].values.reshape(-1, 1)# 创建Binarizer对象并进行二值化处理
transformer = Binarizer(threshold=30).fit_transform(X)# 将处理后的数据赋值回data_2的相应列
data_2.iloc[:, 0] = transformer# 查看处理后的数据
print(data_2.head())