【论文阅读笔记】Context-Aware Hierarchical Merging for Long Document Summarization
2025ACL
keywords 长文本摘要 / LLM / 幻觉
传统长文本摘要方法 暴力切块,相邻合并,递归生成,直到长度符合要求。
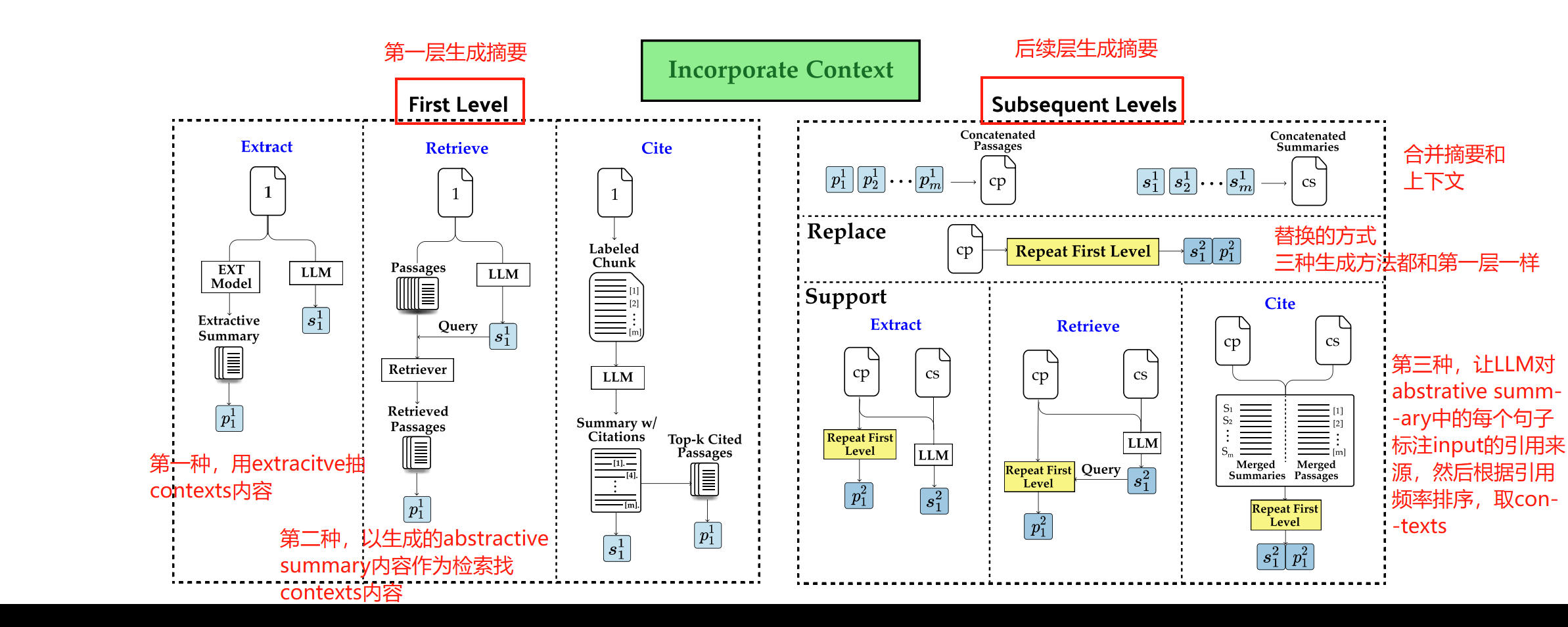
本文方法 合并的时候不直接用相邻内容,而是挑相关的context。具体有三种方法,第一种直接挑关键句子做生成,第二种使用摘要检索输入中的相关内容,第三种以输入内容作参考引用做生成。
关于IC模块的理解:
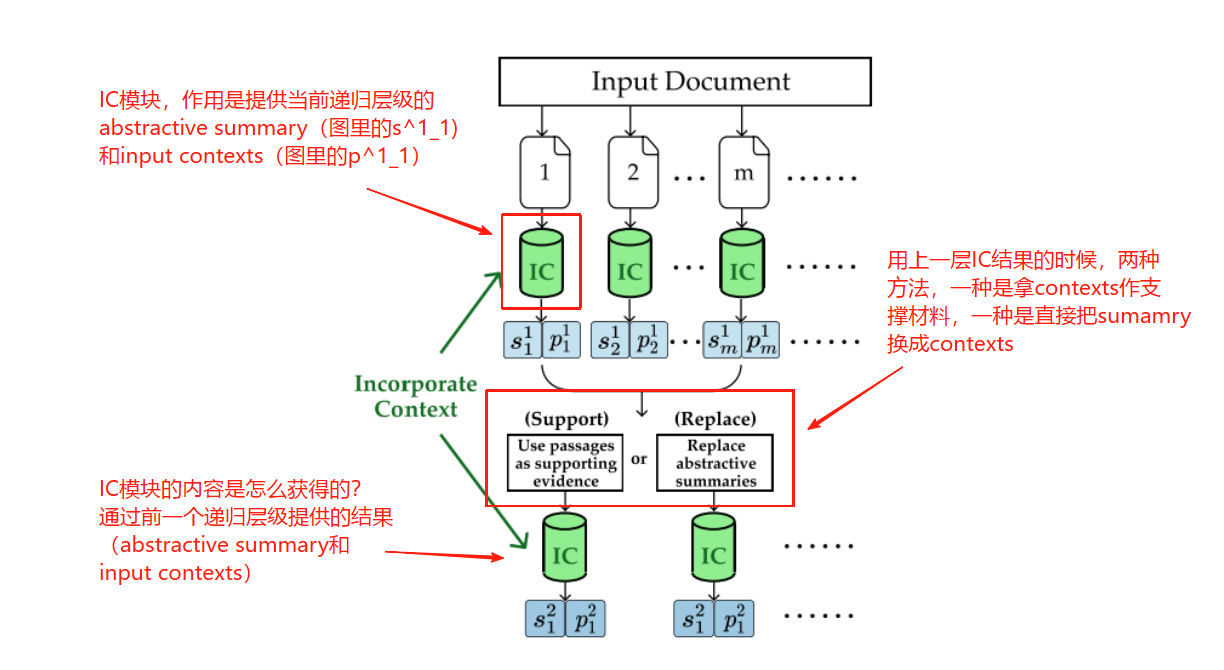
关于加入IC模块后的具体使用方式:
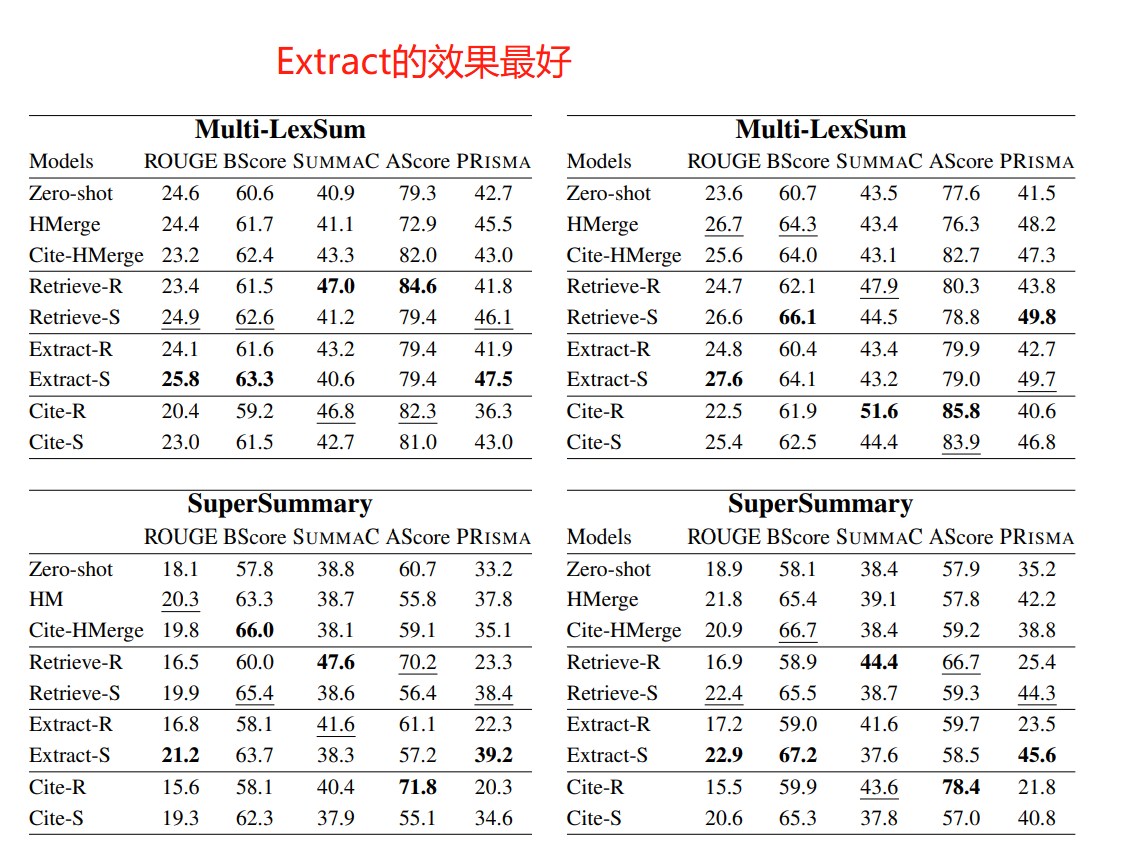
实验
数据集:Multi-LexSum(法律)、SuperSummary(小说)
模型:Llama3、MemSum(Extract方法抽contexts的时候)
可改进的方向
1. 人工评估,没什么说的。
2. 在Support方法中,输入上下文被用作支持证据,导致在合并阶段输入到LLM的文本长度增加,相比replace方法,运行效率低。可以探索更高效地将上下文信息整合到摘要过程中的方法。例如,可以选择性地包含上下文,基于位置信息或对文档结构的了解,而不是简单地将所有上下文信息都纳入。
3. 虽然实验结果表明加入上下文可以提高摘要的准确性,但目前尚不清楚上下文是如何在中间摘要和最终结果中发挥作用的。未来的研究可以进一步分析上下文如何改善中间摘要的质量,以及如何更有效地利用上下文信息。例如,可以通过实验来评估不同上下文选择方法对摘要质量的影响,或者开发一种机制来预测哪些段落对摘要任务最有帮助。
比较能做的:改进上下文选择方法(比如结合一下或者用别的)、优化上下文长度(动态调整之类的)、垂直领域(加知识库、外部数据库)