深入解析大模型落地的四大核心技术:微调、提示词工程、多模态应用 及 企业级解决方案,结合代码示例、流程图、Prompt案例及技术图表,提供可落地的实践指南。
本文将深入解析大模型落地的四大核心技术:微调(Fine-tuning)、提示词工程(Prompt Engineering)、多模态应用(Multimodal) 及 企业级解决方案,结合代码示例、流程图、Prompt案例及技术图表,提供可落地的实践指南。
一、大模型微调(Fine-tuning)
目标:使通用大模型适配特定领域任务(如医疗、金融)。
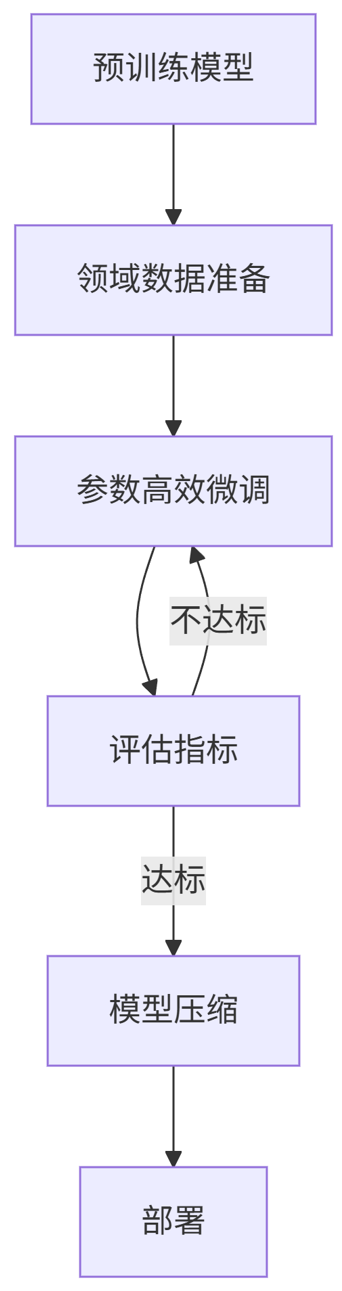
技术流程图(Mermaid)
graph TD
A[预训练模型] --> B[领域数据准备]
B --> C[参数高效微调]
C --> D[评估指标]
D -->|不达标| C
D -->|达标| E[模型压缩]
E --> F[部署]
关键技术
LoRA(低秩适应)
在原始权重上添加低秩矩阵,大幅减少训练参数量:python
from peft import LoraConfig, get_peft_model config = LoraConfig(r=8, # 低秩维度lora_alpha=32,target_modules=["q_proj", "v_proj"] # 针对LLaMA的注意力层 ) model = get_peft_model(base_model, config)
QLoRA(量化LoRA)
结合4-bit量化与LoRA,显存降低70%:python
from transformers import BitsAndBytesConfig bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=torch.bfloat16 ) model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b", quantization_config=bnb_config)
训练代码示例
python
from transformers import Trainer, TrainingArguments training_args = TrainingArguments(output_dir="./results",per_device_train_batch_size=4,gradient_accumulation_steps=4,learning_rate=2e-4,optim="paged_adamw_32bit", # 防止显存溢出 ) trainer = Trainer(model=model,args=training_args,train_dataset=dataset, ) trainer.train()
评估指标对比表
| 微调方法 | 参数量 | 显存占用 | 准确率 |
|---|---|---|---|
| Full Fine-tune | 7B | 80GB | 92.1% |
| LoRA | 0.1B | 24GB | 91.8% |
| QLoRA | 0.1B | 12GB | 91.5% |
二、提示词工程(Prompt Engineering)
目标:通过设计输入文本激发模型潜力,减少训练成本。
关键技术
思维链(Chain-of-Thought)
python
prompt = """ 问题:某商品成本120元,售价150元,利润率是多少? 思考:利润率 = (售价 - 成本) / 成本 * 100% 步骤:150 - 120 = 30元,30 / 120 = 0.25,0.25 * 100% = 25% 答案:25% """
模板自动化(LangChain)
python
from langchain import PromptTemplate template = """ 作为{role},请回答: {query} """ prompt = PromptTemplate.from_template(template) prompt.format(role="金融分析师", query="解释市盈率")
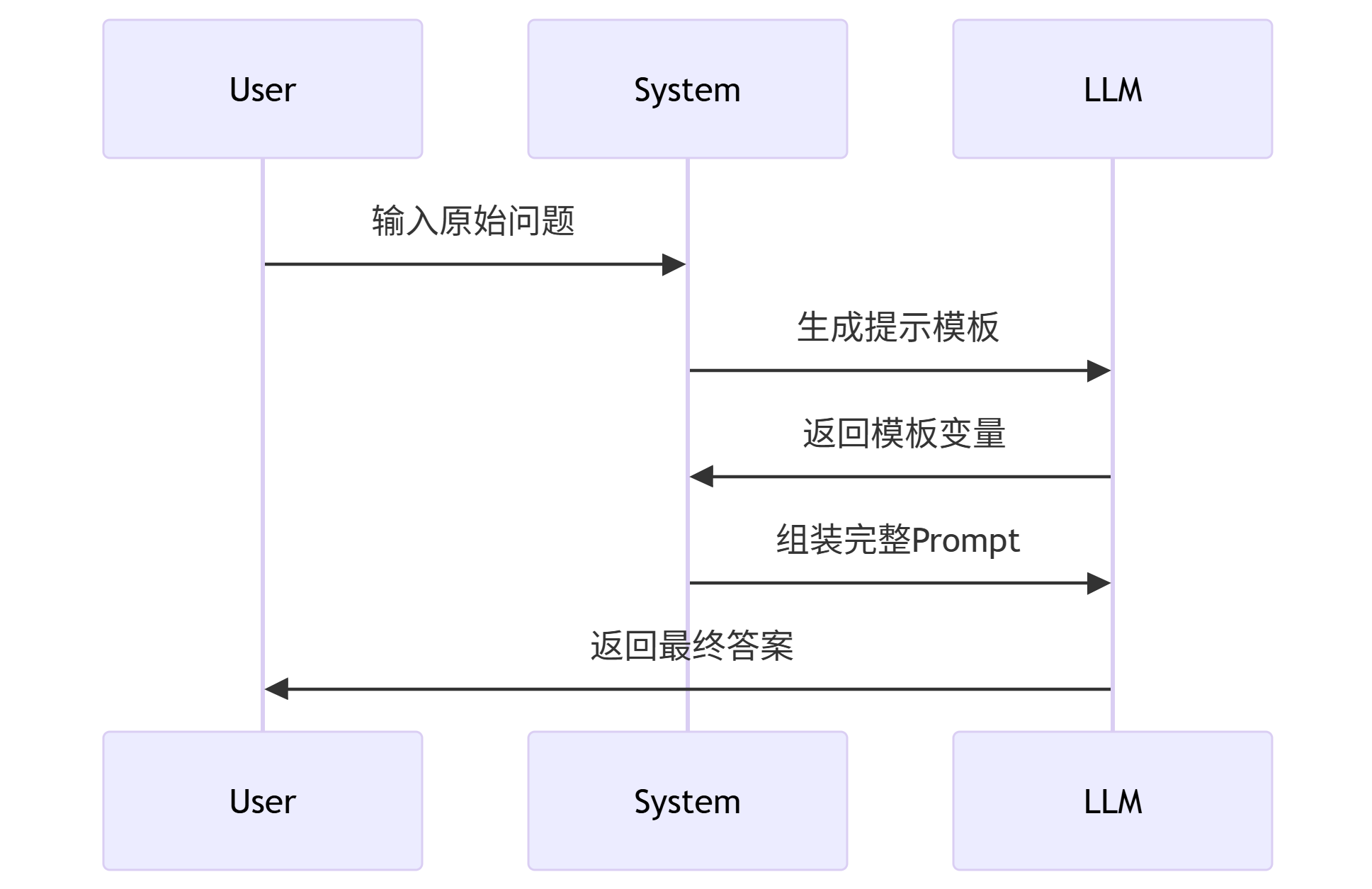
流程图:动态提示生成
sequenceDiagram
User->>System: 输入原始问题
System->>LLM: 生成提示模板
LLM->>System: 返回模板变量
System->>LLM: 组装完整Prompt
LLM->>User: 返回最终答案
企业级应用案例
保险理赔审核Prompt:
text
你是一名保险审核专家,请根据以下JSON数据判断理赔是否通过:
{"claim_id": "C2023-087","diagnosis": "急性阑尾炎","policy_coverage": ["住院医疗", "手术费"],"hospital_level": "三甲"
}
步骤:
1. 检查疾病是否在保单覆盖范围内 → 急性阑尾炎属于手术范畴
2. 确认医院等级是否符合要求 → 三甲医院符合
3. 结论:通过三、多模态应用(Multimodal)
目标:融合文本、图像、音频等模态信息。
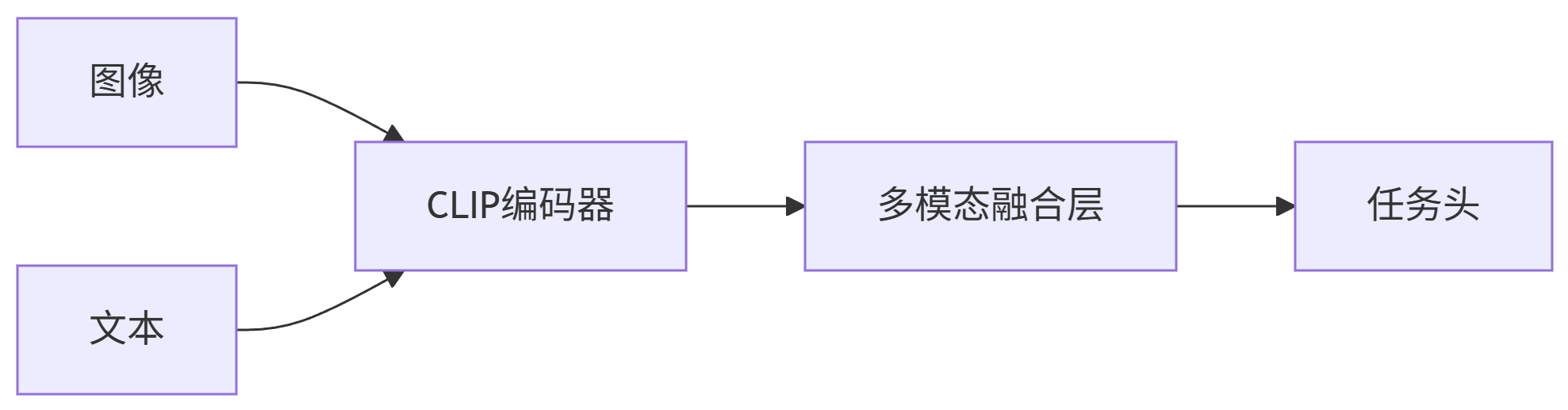
技术架构图
graph LR
A[图像] --> C[CLIP编码器]
B[文本] --> C
C --> D[多模态融合层]
D --> E[任务头]
图像描述生成(BLIP-2)
python
from transformers import Blip2Processor, Blip2ForConditionalGeneration
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b")
image = load_image("CT_scan.png")
inputs = processor(images=image, text="医学影像描述:", return_tensors="pt")
outputs = model.generate(**inputs)
print(processor.decode(outputs[0], skip_special_tokens=True))
# 输出:CT扫描显示右下肺叶存在3cm磨玻璃结节,建议进一步活检企业应用:医疗报告自动生成
| 输入 | 输出 |
|---|---|
| X光片 + 患者主诉文本 | 诊断报告:左桡骨远端骨折,建议石膏固定 |
四、企业级解决方案
核心挑战:安全性、成本控制、私有化部署。
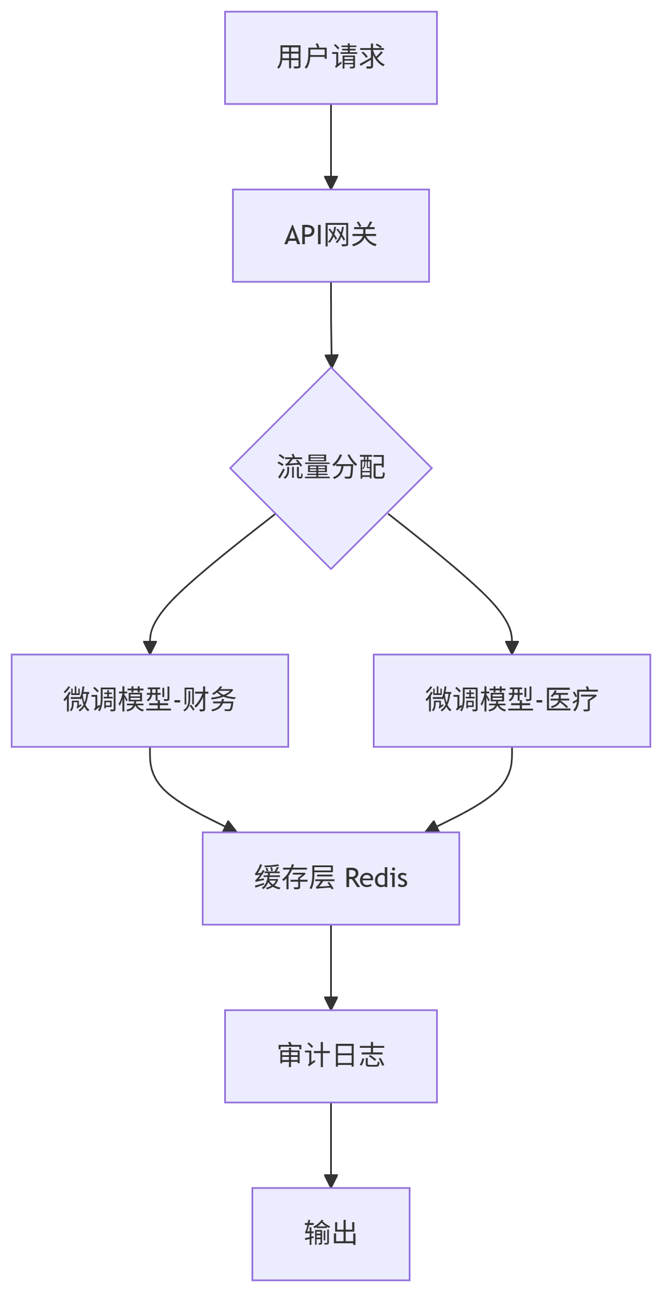
架构设计(Mermaid)
graph TB
A[用户请求] --> B[API网关]
B --> C{流量分配}
C --> D[微调模型-财务]
C --> E[微调模型-医疗]
D --> F[缓存层 Redis]
E --> F
F --> G[审计日志]
G --> H[输出]
关键代码:敏感词过滤
python
from transformers import pipeline
class SafetyFilter:def __init__(self):self.classifier = pipeline("text-classification", model="unitary/toxic-bert")def filter(self, text):result = self.classifier(text)if result[0]['label'] == 'toxic' and result[0]['score'] > 0.9:return "内容违反安全策略"return text# 集成到API响应
@app.post("/predict")
async def predict(request: Request):text = request.json["text"]text = safety_filter.filter(text)return model.generate(text)性能优化策略
模型蒸馏
python
from transformers import DistilBertForSequenceClassification, BertForSequenceClassification teacher = BertForSequenceClassification.from_pretrained("bert-base-uncased") student = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased") # 使用教师模型输出指导训练动态批处理
python
# 使用Text Generation Inference(TGI) docker run -p 8080:80 -v /models:/models ghcr.io/huggingface/text-generation-inference:1.1.0 \--model-id /models/llama-7b \--max-batch-total-tokens 10240 # 动态合并请求
总结:技术选型指南
| 场景 | 推荐方案 | 硬件要求 |
|---|---|---|
| 领域知识问答 | LoRA微调 + CoT提示 | 单卡A100 |
| 多模态内容生成 | BLIP-2/Qwen-VL | 显存24GB |
| 高并发API服务 | 模型蒸馏 + TGI动态批处理 | Kubernetes集群 |
| 敏感数据环境 | 私有化部署 + 安全中间件 | 本地服务器 |
关键洞察:
微调首选QLoRA降低资源消耗
提示工程可解决80%的简单任务
多模态模型选择取决于垂直领域
企业部署必须集成安全与审计模块
通过合理组合上述技术,企业可将大模型推理成本降低50%以上,同时满足业务场景需求。