深度学习总结(21)
超越基于常识的基准
除了不同的评估方法,你还应该了解的是利用基于常识的基准。训练深度学习模型,你听不到也看不到。你无法观察流形学习过程,它发生在数千维空间中,即使投影到三维空间中,你也无法解释它。唯一的反馈信号就是验证指标。在开始处理一个数据集之前,你总是应该选择一个简单的基准,并努力去超越它。如果跨过了这道门槛,你就知道你的方向对了—模型正在使用输入数据中的信息做出具有泛化能力的预测,你可以继续做下去。这个基准既可以是随机分类器的性能,也可以是你能想到的最简单的非机器学习方法的性能。
比如对于MNIST数字分类示例,一个简单的基准是验证精度大于0.1(随机分类器);对于IMDB示例,基准可以是验证精度大于0.5。对于路透社示例,由于类别不均衡,因此基准约为0.18~0.19。对于一个二分类问题,如果90%的样本属于类别A,10%的样本属于类别B,那么一个总是预测类别A的分类器就已经达到了0.9的验证精度,你需要做得比这更好。在面对一个全新的问题时,你需要设定一个可以参考的基于常识的基准,这很重要。如果无法超越简单的解决方案,那么你的模型毫无价值—也许你用错了模型,也许你的问题根本不能用机器学习方法来解决。这时应该重新思考解决问题的思路。
模型评估的注意事项
数据代表性(data representativeness)。训练集和测试集应该都能够代表当前数据。假设你要对数字图像进行分类,而初始样本是按类别排序的,如果你将前80%作为训练集,剩余20%作为测试集,那么会导致训练集中只包含类别0~7,而测试集中只包含类别8和9。这个错误看起来很可笑,但非常常见。因此,将数据划分为训练集和测试集之前,通常应该随机打乱数据。时间箭头(the arrow of time)。如果想根据过去预测未来(比如明日天气、股票走势等),那么在划分数据前不应该随机打乱数据,因为这么做会造成时间泄露(temporal leak):模型将在未来数据上得到有效训练。对于这种情况,应该始终确保测试集中所有数据的时间都晚于训练数据。
数据冗余(redundancy in your data)。如果某些数据点出现了两次(这对于现实世界的数据来说十分常见),那么打乱数据并划分成训练集和验证集,将导致训练集和验证集之间出现冗余。从效果上看,你将在部分训练数据上评估模型,这是极其糟糕的。一定要确保训练集和验证集之间没有交集。有了评估模型性能的可靠方法,你就可以监控机器学习的核心矛盾—优化与泛化之间的矛盾,以及欠拟合与过拟合之间的矛盾。
改进模型拟合
为了实现完美的拟合,你必须首先实现过拟合。由于事先并不知道界线在哪里,因此你必须穿过界线才能找到它。在开始处理一个问题时,你的初始目标是构建一个具有一定泛化能力并且能够过拟合的模型。得到这样一个模型之后,你的重点将是通过降低过拟合来提高泛化能力。在这一阶段,你会遇到以下3种常见问题。训练不开始:训练损失不随着时间的推移而减小。训练开始得很好,但模型没有真正泛化:模型无法超越基于常识的基准。训练损失和验证损失都随着时间的推移而减小,模型可以超越基准,但似乎无法过拟合,这表示模型仍然处于欠拟合状态。我们来看一下如何解决这些问题,从而抵达机器学习项目的第一个重要里程碑:得到一个具有一定泛化能力(可以超越简单的基准)并且能够过拟合的模型。
调节关键的梯度下降参数
有时训练不开始,或者过早停止。损失保持不变。这个问题总是可以解决的—请记住,对随机数据也可以拟合一个模型。即使你的问题毫无意义,也应该可以训练出一个模型,不过模型可能只是记住了训练数据。出现这种情况时,问题总是出在梯度下降过程的配置:优化器、模型权重初始值的分布、学习率或批量大小。所有这些参数都是相互依赖的,因此,保持其他参数不变,调节学习率和批量大小通常就足够了。我们来看一个具体的例子。
(train_images, train_labels), _ = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255model = keras.Sequential([layers.Dense(512, activation="relu"),layers.Dense(10, activation="softmax")
])
model.compile(optimizer=keras.optimizers.RMSprop(1.),loss="sparse_categorical_crossentropy",metrics=["accuracy"])
model.fit(train_images, train_labels,epochs=10,batch_size=128,validation_split=0.2)
这个模型的训练精度和验证精度很快就达到了30%~40%,但无法超出这个范围。下面我们试着把学习率降低到一个更合理的值1e-2。
代码清单 使用更合理的学习率训练同一个模型
model = keras.Sequential([layers.Dense(512, activation="relu"),layers.Dense(10, activation="softmax")
])
model.compile(optimizer=keras.optimizers.RMSprop(1e-2),loss="sparse_categorical_crossentropy",metrics=["accuracy"])
model.fit(train_images, train_labels,epochs=10,batch_size=128,validation_split=0.2)
现在模型可以正常训练了。如果你自己的模型出现类似的问题,那么可以尝试以下做法。降低或提高学习率。学习率过大,可能会导致权重更新大大超出正常拟合的范围,就像前面的例子一样。学习率过小,则可能导致训练过于缓慢,以至于几乎停止。增加批量大小。如果批量包含更多样本,那么梯度将包含更多信息且噪声更少(方差更小)。最终,你会找到一个能够开始训练的配置。
利用更好的架构预设
你有了一个能够拟合的模型,但由于某些原因,验证指标根本没有提高。这些指标一直与随机分类器相同,也就是说,模型虽然能够训练,但并没有泛化能力。这是怎么回事?这也许是你在机器学习中可能遇到的最糟糕的情况。这表示你的方法从根本上就是错误的,而且可能很难判断问题出在哪里。下面给出一些提示。
首先,你使用的输入数据可能没有包含足够的信息来预测目标。也就是说,这个问题是无法解决的。试图拟合一个标签被打乱的MNIST模型,它就属于这种情况:模型可以训练得很好,但验证精度停留在10%,因为这样的数据集显然是不可能泛化的。其次,你使用的模型类型可能不适合解决当前问题。你会在第10章看到,对于一个时间序列预测问题的示例,密集连接架构的性能无法超越简单的基准,而更加合适的循环架构则能够很好地泛化。模型能够对问题做出正确的假设,这是实现泛化的关键,你应该利用正确的架构预设。
提高模型容量
如果你成功得到了一个能够拟合的模型,验证指标正在下降,而且模型似乎具有一定的泛化能力,那么恭喜你:你就快要成功了。接下来,你需要让模型过拟合。考虑下面这个小模型,它是在MNIST上训练的一个简单的logistic回归模型。
model = keras.Sequential([layers.Dense(10, activation="softmax")])
model.compile(optimizer="rmsprop",loss="sparse_categorical_crossentropy",metrics=["accuracy"])
history_small_model = model.fit(train_images, train_labels,epochs=20,batch_size=128,validation_split=0.2)
import matplotlib.pyplot as plt
val_loss = history_small_model.history["val_loss"]
epochs = range(1, 21)
plt.plot(epochs, val_loss, "b--",label="Validation loss")
plt.title("Effect of insufficient model capacity on validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
模型得到的损失曲线。
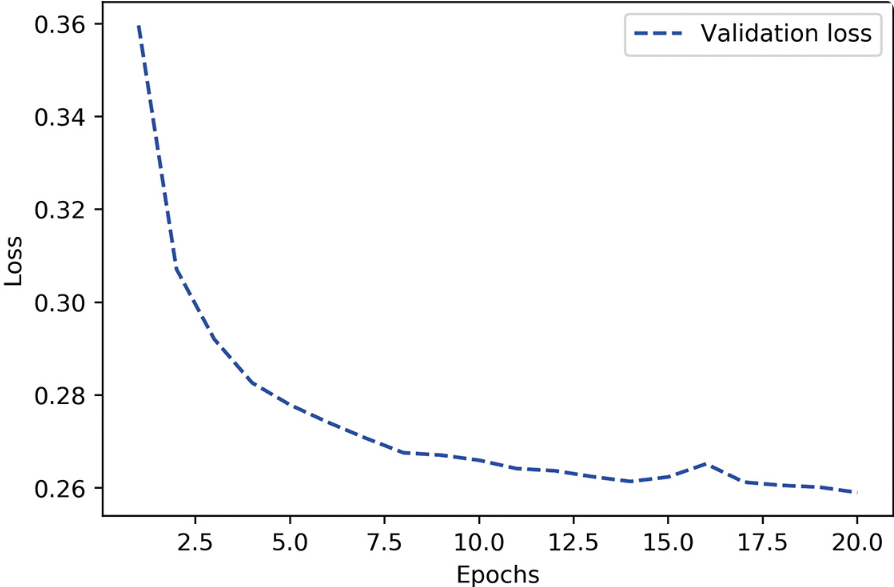
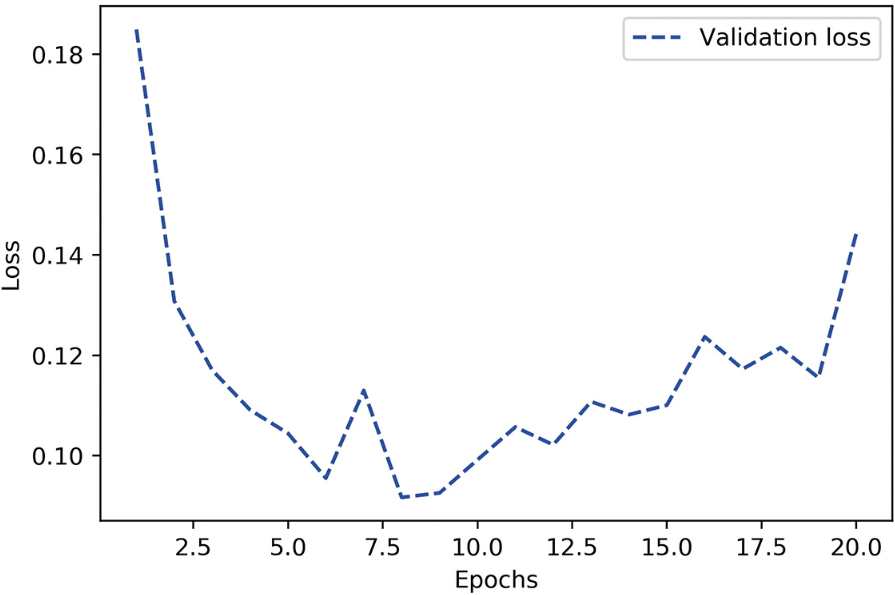
验证指标似乎保持不变,或者改进得非常缓慢,而不是达到峰值后扭转方向。验证损失达到了0.26,然后就保持不变。你可以拟合模型,但无法实现过拟合,即使在训练数据上多次迭代之后也无法实现。在你的职业生涯中,你可能会经常遇到类似的曲线。请记住,任何情况下应该都可以实现过拟合。与训练损失不下降的问题一样,这个问题也总是可以解决的。如果无法实现过拟合,可能是因为模型的表示能力(representational power)存在问题:你需要一个容量(capacity)更大的模型,也就是一个能够存储更多信息的模型。若要提高模型的表示能力,你可以添加更多的层、使用更大的层(拥有更多参数的层),或者使用更适合当前问题的层类型(也就是更好的架构预设)。我们尝试训练一个更大的模型,它有两个中间层,每层有96个单元。
model = keras.Sequential([layers.Dense(96, activation="relu"),layers.Dense(96, activation="relu"),layers.Dense(10, activation="softmax"),
])
model.compile(optimizer="rmsprop",loss="sparse_categorical_crossentropy",metrics=["accuracy"])
history_large_model = model.fit(train_images, train_labels,epochs=20,batch_size=128,validation_split=0.2)
现在验证曲线看起来正是它应有的样子:模型很快拟合,并在8轮之后开始过拟合