如何5分钟快速搭建智能问答系统
目录
- 引言
- 一、智能问答系统的几种不同实现方式
- 1、问答对系统(FAQ-based Question Answering)
- 2、基于知识图谱的推理问答(Knowledge Graph-based Reasoning QA)
- 3、任务型问答(Task-oriented Dialogue Systems)
- 4、生成式闲聊问答(Generative Chat-based QA)
- 5、基于阅读理解的问答(MRC-QA)
- 6、基于表格的问答(TableQA)
- 7、混合式问答系统
- 8、检索增强生成(RAG)
- 二、初期:基于QA问答对的问答系统实现
- 三、中期:基于RAG的问答系统实现
- 四、后期:基于RAG(推理模型)的问答系统实现
引言
今天心血来潮突然想写这篇文章,纯想唠嗑,如有不适马上走开,不要回来。😁哈哈哈~
文章标题源于早在chatgpt诞生之前小马已经在实现智能问答系统的工作,那个时候还没有LLM,主要是借助Bert等这种NLP小模型来处理Embedding。于是使用向量数据库相似度匹配实现了一版问答系统《如何5分钟快速搭建智能问答系统》。后来当chatgpt一夜之间风靡全球,自然这种方法也显得落后不堪,这完全不是同一个等级的事务,于是最终必然走向了结合LLM的RAG智能问答系统之路,乃至今天的结合类似deepseek等推理模型的问答模型底座。今天我们就来简单聊聊这个“有趣”的演进故事。老规矩,小马力求通俗易懂,只讲干货。
阅读本文之前默认已经了解基本的AI技术栈概念知识。

一、智能问答系统的几种不同实现方式
智能问答系统(Intelligent Question Answering System)是一种能够自动理解用户问题并提供准确答案的AI系统。它在多个领域如客户服务、教育、医疗等有广泛应用,通过自然语言处理(NLP)技术实现高效交互。
我们知道根据不同的需求场景问答系统有很多种不同的实现方式,比如问答对系统、基于知识图谱的推理问答、任务型问答、生成式闲聊问答、基于阅读理解的问答、基于表格的问答、混合式问答系统、检索增强生成等核心技术实现方案。
1、问答对系统(FAQ-based Question Answering)
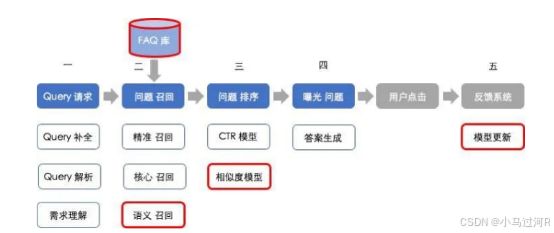
核心原理:该系统基于预定义的问答对数据库(FAQ库),通过关键词匹配或语义相似度算法检索最相关的答案。用户问题被映射到库中已有的问题-答案对,无需复杂推理。
- 技术实现:
- 使用检索模型(如BM25或TF-IDF)进行关键词匹配。
- 结合语义模型(如Word2Vec或BERT)提升准确性。
- 示例:在政务场景中,系统通过FAQ知识库快速响应常见政策咨询。
- 应用场景:适用于高频、标准化问题,如企业客服热线或在线帮助中心。优点是实现简单、响应快,缺点是无法处理未预见的复杂问题。
2、基于知识图谱的推理问答(Knowledge Graph-based Reasoning QA)
核心原理:利用结构化知识图谱(KG)存储实体、属性和关系,通过图遍历或推理引擎回答涉及多步逻辑的问题。知识图谱使系统能“理解”语义关联,而非简单匹配。
- 技术实现:
- 知识图谱构建模块:从结构化或非结构化数据抽取实体和关系(如NER模型),存储在图数据库如Neo4j中。
- 问题解析模块:包括意图识别和实体识别(如使用BiLSTM-CRF模型),将用户问题转换为图谱查询(如Cypher语句)。
- 推理模块:基于规则或机器学习(如路径排序算法)进行推理,例如在医疗问答中诊断疾病关系。
- 示例:古诗词问答系统通过图谱查询诗人-作品关系,生成详细答案。
- 应用场景:适用于需要深度推理的领域,如教育、医疗或政务决策支持。优点是能处理复杂查询,缺点是需要高质量图谱构建和维护。
关于知识图谱的理解还可以参看这里《知识图谱初相识(概念理解篇)》。
3、任务型问答(Task-oriented Dialogue Systems)
核心原理:系统通过多轮对话引导用户完成特定任务(如订票或预约),涉及状态管理和API调用。核心是对话管理模块,跟踪上下文并执行动作。
- 技术实现:
- 使用管道架构:包括自然语言理解(NLU)、对话状态跟踪(DST)、对话策略(Policy)和自然语言生成(NLG)。
- 示例:在智慧政务中,任务流程式问答优化业务流程,如许可证申请。
- 应用场景:适用于目标导向的场景,如电商客服或智能助手。优点是高效完成任务,缺点是需要预定义任务框架,灵活性较低。
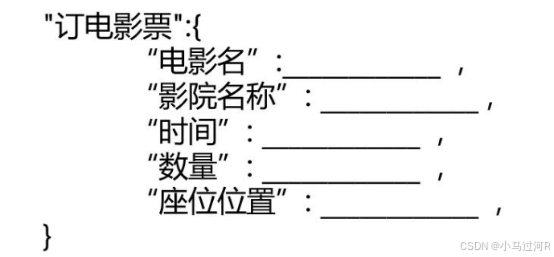
任务型问答一般有特定的业务场景,比如订电影票,列出所有订电影票需要的制定成一个模版,如机器人要在和客户的对话过程中把这些模版的信息都填充完毕,或者有可以根据用户地理位置等信息推断出模版需要添的,等填充完毕后就生成回答回复给用户。
4、生成式闲聊问答(Generative Chat-based QA)
- 核心原理:基于生成模型(如GPT系列)直接生成自然语言响应,支持开放域闲聊或创意回答。系统不依赖预定义知识库,而是通过大规模语料训练。
- 技术实现:
- 使用序列到序列(Seq2Seq)模型或Transformer架构。
- 结合强化学习优化对话流畅度。
- 示例:闲聊系统在社交应用中提供人性化交互,但需注意知识准确性。
- 应用场景:适用于娱乐、社交或简单咨询,如聊天机器人。优点是高度灵活,缺点是可能生成不准确信息,需结合检索机制提升可靠性。
- 技术实现:
5、基于阅读理解的问答(MRC-QA)
- 核心原理:直接从非结构化文本中抽取答案片段。系统接受用户问题和相关文档,通过深度阅读理解模型定位答案位置。
- 技术实现:
- 使用预训练语言模型(如BERT)构建抽取式问答系统。
- 在政务场景中直接搜索政策文档提取答案。
- 特点:无需结构化知识库,但依赖文档质量。适用于法律咨询、政策解读等场景。
- 技术实现:
6、基于表格的问答(TableQA)
- 核心原理:将自然语言问题转换为结构化表格查询(如SQL),返回精确数据结果。
- 技术实现:
- 语义解析:将问题转换为逻辑形式(如SELECT语句)
- 表格检索:在大型表格库中定位相关表格
- 如查询企业财务报表中的特定指标
- 特点:适用于金融报表、科研数据等表格密集型领域,精度高但需要表格标准化。
- 技术实现:
7、混合式问答系统
- 核心原理:融合多种技术,通过级联或集成方式提升覆盖率。
- 典型架构:
- 优势:在政务客服中显著提升问题解决率(实测可达92%+)。
8、检索增强生成(RAG)
- 核心原理:结合检索系统与大语言模型(LLM),先检索相关文档再生成答案。
- 技术流程:
- 问题向量化:$ \vec{q} = \text{BERT}(question) $
- 文档检索:$ \text{top-k} = \arg\max \text{sim}(\vec{q}, \vec{d}) $
- 提示工程:
基于{文档}回答{问题}
- 效果:减少大模型幻觉,提升事实准确性。
二、初期:基于QA问答对的问答系统实现
开篇引言中我们提到,早期还没有chatgpt等这种的大模型爆发,NLP模型似乎也是一直不温不火地存在,没有人相信LLM能爆发出如此惊人的能力,大力出奇迹。
当时我们也是快速锁定了一套基于QA相似度匹配的问答方案,最早就是源于这篇文章《快速搭建对话机器人,就用这一招!》,它甚至把原理总结得很好了。
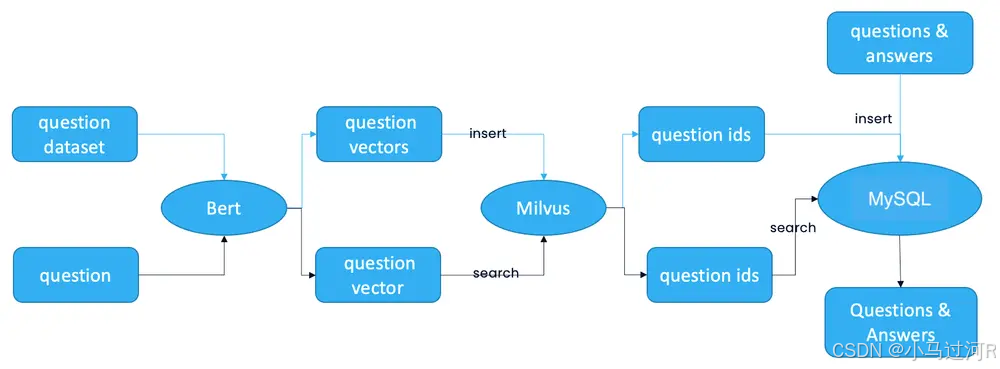
如上图,总体概括而言我们使用了Embedding模型对QA问答知识库语料进行Embedding之后持久化在向量数据库中(q,a),其中q的向量数据,a为原文。当用户提问q1进入系统,首先系统会对q1进行Embedding向量化qb1,然后qb1这个向量会进入向量数据库进行q的相似度计算,得出最相近的向量q2 list,于是通过q2 list召回,通过q2得到 之前持久化在向量数据库中的答案a2,返回用户。
#基于QA问答对的问答系统执行流程:
user -> q1-> model Embedding -> qb1 -> Vector DB match q->q2 list->top -> a2 ->user
Embedding模型文中的用是Bert,当然你也可以任意切换,比如M3e模型;向量数据库同理,文中是Milvus,你也可以任意切换,如Mysql家族的PostgreSQL等等。
对Embedding不熟悉的小伙伴,这里推荐一本书《深入浅出Embedding》,一本不错的NLP入门书, LLM 底层,Embedding model, 问答,分类,推荐系统实现…万物归宗都在Embedding。通俗地理解就是:主要是通过向量化来表达语义在空间上的差异,再利用正余弦会内积等算法计算向量在空间上的相近距离。这里需要注意的是不同的模型处理的向量化维度长度不一样,而且计算的准确度也是不一样。
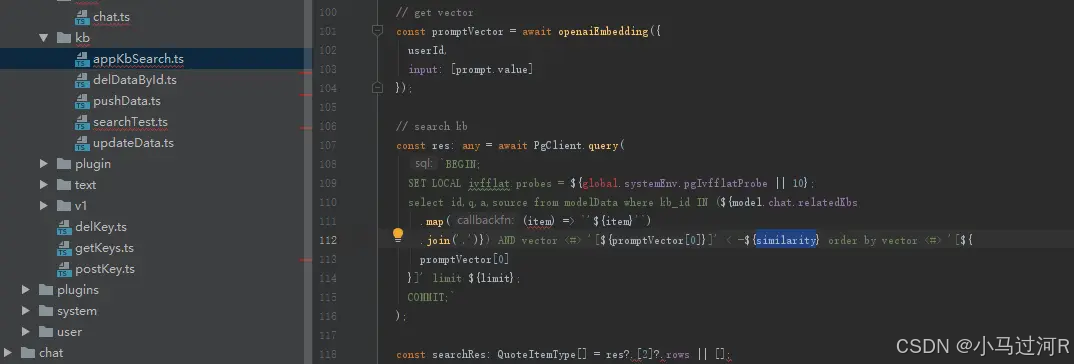
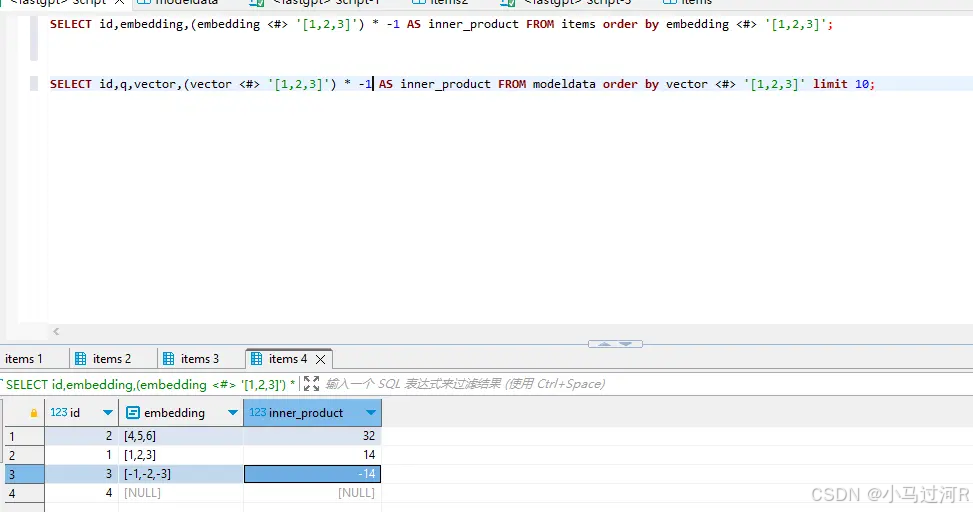
上面2张图是Postgres-Vector的相似度计算的代码块和IDE案例,具体的还可以参看Postgres-Vector官方文档。很多时候我们需要不断验证取寻找一个比较合适判断临界值similarity。
细心的同学很快就会发现,这种方案非常依赖于QA语料中Q语料的质量以及向量相似度匹配的精准度。在实际应用还是会遇到各种现实问题的,要追求准确率的话这两块的深耕是必不可少的。
三、中期:基于RAG的问答系统实现
这块其实就很有趣了,我们先来看一段RAG的描述。
RAG(Retrieval-Augmented
Generation,检索增强生成)是一种结合信息检索与大语言模型生成能力的技术范式,旨在解决传统生成模型(如GPT系列)在处理知识密集型任务时出现的“幻觉”(即生成错误或无关信息)和知识滞后问题。
其核心思想是:在生成答案前,先从外部知识库中检索相关上下文,然后基于这些信息生成更准确、可靠的回答。这种方法模拟了人类专家“查阅资料后再回答问题”的行为,显著提升了模型的准确性和可信度。
我们咋一看这是在解决大模型的幻觉问题吧?是的,但是同时不也是问答系统的解决方案呢?要么怎么说人类这么聪明呢。
于是基于RAG的问答系统实现就来了。
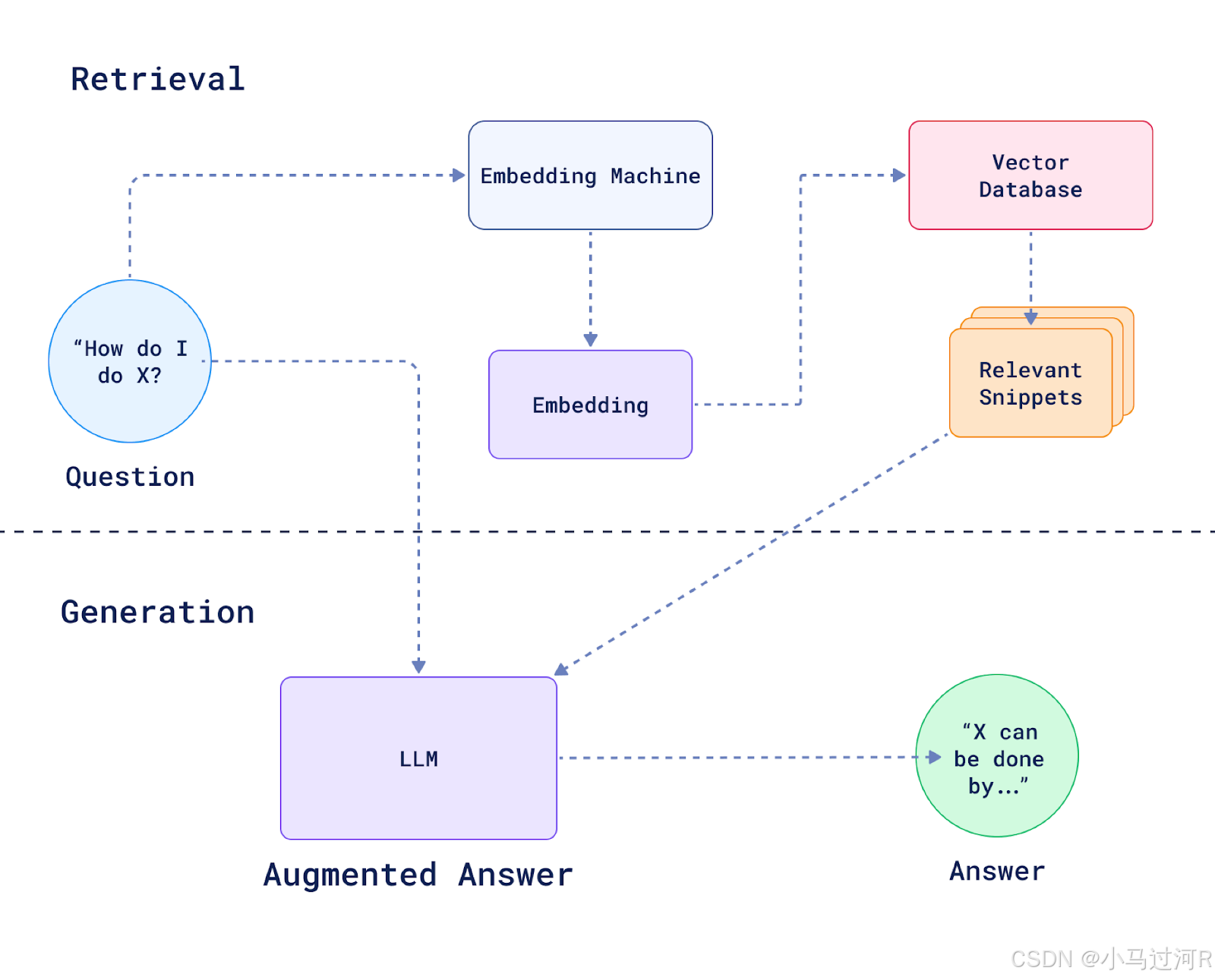
我们来看这个参考架构图,其实核心就是在上一个相似度匹配的方案上再接了一层大模型来总结语料后组织输出最终答案,这样显得更智能,确实有点私人定制的体验,有那么点AI的样子了。
# 我们prompt类似如下PROMPT_TEMPLATE = """已知信息:{context} 根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “暂时无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。 问题是:{question}"""
想快速实现的小伙伴可以搜关键字“RAG框架”相信今天肯定是已经琳琅满目了,比如fastgpt、langchain等,甚至目前主流的Agent框架支持RAG都变成了基本能力之一。(很多人把RAG和Agent混为一谈其实不恰当的,对Agent概念还比较模糊的同学可以看这里《一文搞懂什么是AI Agent》)。
# 基于RAG的问答系统执行流程:
user -> q1-> model Embedding -> qb1 -> Vector DB match q->q2 list->top -> a2 list-> prompt Engineering -> LLM -> user
如果已经忍不住要动手的小伙伴,我也给你整好了几个,怕你5分钟超时,拿走安装就搭建好了。
| 项目 | 相关描述 | 地址 |
|---|---|---|
| fastgpt | 项目技术栈:NextJs + TS + ChakraUI + MongoDB + PostgreSQL (PG Vector 插件)/Milvus | https://github.com/labring/FastGPT |
| langchain | Build context-aware, reasoning applications with LangChain’s flexible abstractions and AI-first toolkits | https://github.com/langchain-ai |
| LangChain-Chatchat | 原Langchain-ChatGLM | https://github.com/chatchat-space/Langchain-Chatchat |
细心的同学又会发现了,这种方案只不过是在QA问答对的方案后面多加了一步大模型总结输出而已,那些缺陷不还是一样存在。确实是的,RAG方案的问答系统不仅依赖于语料召回的情况还依赖于大模型对召回语料的总结能力,这两个相辅相成才能达到一个比较好的评估效果。
因此,我们需要根据实际场景对召回这块逻辑进行不断升级,比如之前是只支持QA对匹配的,现在如何支持各种不同类型语料,比如长文本,图片等等,召回方式又是什么呢?增加ES检索,OCR识别还是如何呢?这些都是需要重点考虑的,语料的召回往往决定了最终模型是否能精准答对问题。这种的原理也很好理解,如果把模型回答比作是一次开卷考试,那么你给它的资料越精准,它就能答得越精准。
其次,我们还需关心大模型的总结能力,如果有需要特定的能力,比如回答风格要求精炼,那最适合做一下特定任务微调了。对微调比较模糊的同学也可以参考这里《模型微调(Fine-tuning)实践》。
当然,除了以上这些我们还可能遇到各种需要优化和处理的场景,比如开启流模式提升体验的同时会出现什么问题,本地部署的模型API能否多进程,模型答非所问怎么办,模型性能太差是量化还是蒸馏还是如何压缩,模型的上下文窗口最大token不够用了怎么办,如何做每次优化后效果的问答系统模型评估,如果模型要支持多轮问答该怎么实现,指代消解的能力需要怎么微调,一个模型能否支撑多个特定任务的微调效果等等问题。这一系列的问题都将接踵而至,精雕细琢才能出好玉。这里小马就不一一展开说了,后续有机会可以一起展开探讨。
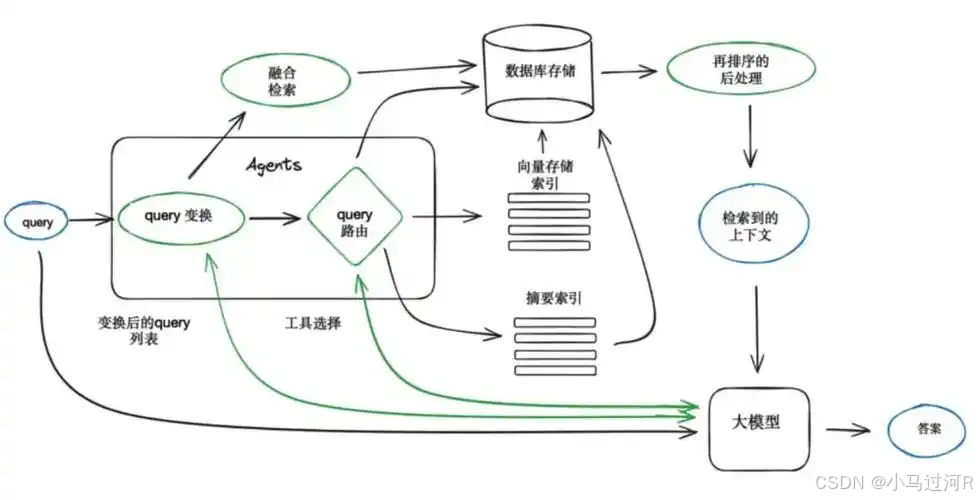
有的小伙伴也要问了,既然都用了LLM了为什么不直接用语料训练LLM呢?下面这张图也许可以解答你的疑惑。(也是Agent诞生的价值)

四、后期:基于RAG(推理模型)的问答系统实现
看标题就知道了,我们把RAG中的LLM换成具备推理能力的模型,这也是今天春节deepseek轰动全球的节点。所谓的推理模型,就是在训练时强制模型进行思考来让它具备推理能力,原理不是本文的重点就不赘述,感兴趣的同学可以参看这里《DeepSeek R1核心原理GRPO算法详解》。
# 基于RAG(推理模型)的问答系统执行流程:
user -> q1-> model Embedding -> qb1 -> Vector DB match q->q2 list->top -> a2 list-> prompt Engineering -> Reasoning LLM -> user
然而当我们的问答基座接入了推理模型之后,确实可以看到模型对于召回的语料的思考更加深入了。但也免不了带来一些新的损失,比如精炼度、速度等等,各位根据业务场景按需服用即可,切不可盲目用药。
推理模型用于问答场景确实大材小用了点,那可以做问答Agent的决策模型是不是更合适呢?有兴趣的小伙伴部署一下Agent看看哈。
好了,今天就唠到这了,感谢听我唠完的小伙伴也作为抛砖引玉能对大家能有所帮助那更好了。有什么疑问欢迎交流。
- 彩蛋的位置~
