ptmalloc(glibc-2.12.1)整体结构
目录
一 内存池
1. 什么是内存池
2. 如何设计一个内存池
3. 现如今的内存池
二 ptmalloc的结构组织
本章讲解的是 ptmalloc 版本为:glibc-2.12.1。
1. chunk
2. 整体结构
2. 分配区
1. 分配区
2. 主分配区
3. 非主分配区
三 申请/释放逻辑
1. 分配算法
2. 申请逻辑
3. 释放逻辑
本章针对 32位 的平台环境下讲解。
一 内存池
1. 什么是内存池
先说说生活上的例子:
比如在学校,每个月又或者每个星期或者每天家里人都会给生活费来维持在学校的生活开销。
那么一次要多少,隔多少天要一次?这些情况都会带来不一样的效果和影响。
比如一天要一次和一个星期要一次:
每天都要一点,每天都会给家里人通信,想必时间久了家里人都会觉得太麻烦了。
每隔星期要一点,一次要多点,这样就会家里人就不会觉得太麻烦了。
频繁要可能造成了问题:
- 家里人可能很忙,不能每天抽空按时给生活费。
- 一次要一点可能导致家里人有足够的钱,但没有大额的现金,比如红票票~~,虽然有足够的钱,但这些钱都是零零散散的1块或者1分,不能分配大额的现金。
这2个问题是最致命的:要钱的效率 + 有足够的钱但无法分配大额的现金。
所以上面所说的:
1. 向家里要一批钱,相当于把这些钱缓存起来,每天都可以用一点,不用要多少用多少,而是要多点,剩下的备着用。
2. 要多少次?一次要多少 ?多久要一次?不同的策略可能导致不同的结果和对应的影响,比如上面的例子。
所以什么是内存池呢?
程序预先向物理内存申请一批内存块,由程序自行进行管理,程序申请内存/释放内存都由这个内存池进行管理,无需向物理内存操作,大大提高了物理内存的闲置率,更高的进行他该做的事情。
不仅是内存池,还有线程池,进程池等。
这些都是程序预先向系统申请的资源,他们自行进行管理,用户直接用即可,无需自己写这些组件,提高了资源利用率,也提高了程序员的开发效率和开发成本。
2. 如何设计一个内存池
通过最开始生活中的例子类比一个内存池:
1. 每次向系统要多少?
2. 多久/什么时候向系统要一次?
3. 要到的内存如何进行管理?
4. 分配出去的内存还回来如何管理?
5. 什么时候把内存还给物理内存?
根据这些一个内存池其实要考虑的有很多但不包括这些。
比如:
- 单线程/多线程的情况下分配内存的速度
- 内存碎片大小的控制
- 是否兼容不同的平台
- 是否通用大部分的应用场景
- 极端场景产生的瓶颈如何优化
等等等等这些边边角角的都是一个内存池应该考虑的。
所以综上来说一个内存池必备的功能:
- 具有分配/释放内存的功能
- 单线程/多线程分配内存效率速度,也就是性能
- 内存分配/释放产生的内存碎片和如何优化
- 兼容不同的平台:如 Linux/Windows
3. 现如今的内存池
glibc ptmalloc 还是 Google tcmalloc 都是很成熟的内存池,各有优劣势,本章将介绍 ptmalloc 的实现和为什么在高并发的场景下效率低于 tcmalloc。
二 ptmalloc的结构组织
本章讲解的是 ptmalloc 版本为:glibc-2.12.1。
1. 内存块的管理结构
内存池向内存申请到的内存块,肯定不是直接用这个裸的内存块分配出去,下面来看看ptmalloc是如何描述一个用户所需要的内存块。
1. chunk
struct malloc_chunk {INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */struct malloc_chunk* fd; /* double links -- used only if free. */struct malloc_chunk* bk;/* Only used for large blocks: pointer to next larger size. */struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */struct malloc_chunk* bk_nextsize;
};可以看到管理内存块的结构为 malloc_chunk,这里称为 chunk。
前2个字段
prev_size:前一个相邻的 chunk 的大小
size:该 chunk 的大小,这里需要舍弃低 3 bit 位,该3个 bit 位,对应 A M P 标志位。
A:是主分配区还是非主分配区管理的。
M:是 brk 还是 mmap 分配的内存,是的,这里不仅仅是调用堆的系统调用还用了共享区的系统调用接口,一般申请的内存块太大则会用 mmap 进行分配。
P:上一个相邻的 chunk 是否空闲。
这里后面讲。
中间2个字段
fd:指向下一个相同的 chunk,这里不是相邻
bk:指向上一个相同的 chunk,这里不是相邻
后面2个字段
fd_nextsize:后一个比当前 chunk 大的 chunk,这里不是相邻
bk_nextsize:前一个比当前 chunk 小的 chunk,这里不是相邻
实际给用户分配的是 fd的地址,即第3个字段。
为什么?
在 chunk 空闲时,这些字段都有各自的作用,要维护不同chunk之间的链接关系。
但如果一个 chunk 被分配出去,第3个字段往后的几个字段,就没有意义了,那为什么前面2个字段要保留?
1. prev 可以和前面相邻的 chunk 进行合并缓解内存碎片问题。
2. size 字段可以根据还回来的 chunk 计算大小放到对应的数据结构里,并设置后面的4个字段链接起来。
2. 整体结构
1. bins 数组
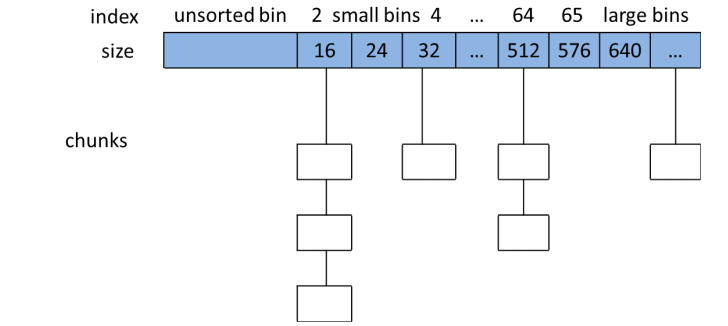
这里是逻辑结构,实际物理结构和这里不一样,后面会讲到。
上面说的是单个 chunk 的描述,实际是用 bins 数组来对这些chunk进行管理维护的。
可以看出来整体是用数组来维护这些大小不同的 chunk,数组大小为 126。
small bins:
1. 管理下标 2(从第三个下标开始) ~ 下标为63,一共 62 个下标。
2. 每个下标之间按 8 字节对齐,一共是 16字节 ~ 504字节,最少是从16 字节开始。
3. 该分区是由双向链表进行管理维护,每个下标对应的内存块大小固定不变,并由 fd,bk字段进行连接指向。
4. 从尾部获取,头部插入保证每个chunk都可能会被利用起来。
large bins:
1. 管理下标 63 ~ 126 个下标。
2. 每个下标管理一定的范围的内存块。
Bin 范围 递增步长 区间大小范围 区间间隔(字节差) 64~95 64B 512B ~ 4032B 64B(每个 bin 相差 64B) 96~111 512B 4032B ~ 22528B 512B(每个 bin 相差 512B) 112~119 4096B 22528B ~ 53248B 4096B(4KB)(每个 bin 相差 4KB) 120~123 32768B 53248B ~ 196608B 32768B(32KB)(每个 bin 相差 32KB) 124~125 262144B 196608B ~ 720896B 262144B(256KB)(每个 bin 相差 256KB) 126 无固定步长 ≥720896B 无固定间隔(仅单个 bin 存储超大 chunk) large bins 又被分配 6 个小子区间,每个区间管理一定范围的内存块,每个区之间相隔的字节大小也不相同,具体看上图。
3. 该结构采用:最小优先,最佳匹配策略,每个分区的不同的内存块大小严格按升序排列,并分配的时候优先分配最小的那个内存块缓解内存碎片。
unsorted bins:
1. 字面意思该分区管理的内存块分布是无序的,对应下标 1,0下标未被使用。
2. 所有归还的内存块大小超过 fast bins 管理的最大大小,将放到 unsorted bins 里面。
3. 该分区相当于一个缓存,如果后续分配查找该分区没找到,则把该分区的所有 chunk 放到对应的 small bins / large bins 里面。
补充上面的细节:
1. bins 数组对应的 3 个区间都是用双链表进行管理的。
2. chunk 的后2个字段 fd_nextsize,bk_nextsize只在 large bins 中有效,用来快速定位下一个大或者小的 chunk,因为每个下标管理不同范围的 chunk,相同的 chunk 会粘在一起,用来提高分配效率。
3. 所有归还的 chunk 会优先进入 unsorted bins 里,用来缓存给下一次申请寻找合适的分配出去,如果没有则放到 small / large bins 里面。
除了上面 bins 数组里的 3 个区的分区,还有一些其他的补充。
fast bins:
1. 管理小块对象,16 ~ 64字节大小内存块,主要对 small bins 的前 7个区进行缓存。
2. 所有归还的内存块在 fast bins 管理的范围内,都会优先进入该结构里。
top chunk:
1. 指向堆顶的指针,bins 并不是占据整个堆的大小,堆是从下往上扩展的,bins的结束地址 ~ top chunk 即堆顶指针也是空闲内存。
1. 当申请的内存块 bins数组 和 fast bins 都无法满足,就会像 top chunk 尝试分配,成功则切割分配出去,否则扩展 brk 堆顶指针,或者 mmap 一段内存分配出去。
2. 当归还的内存块和 top chunk 切割出去的内存相邻则合并。
mmaped chunk:
1. 上面的 top chunk 都无法满足所申请的内存大小且不伸缩堆顶指针,则会 mmap 一段内存区域给用户返回出去。
2. 当用户归还回来则直接调用 munmap 归还给操作系统。
Last Remainder:
1. 和 fast bins 一样也是缓存,当 unsorted bins 有足够大的 chunk 且 该 chunk 切割之后的大小足够一个 chunk,则会放到 Last Remainder 里。
2. 当 整个 bins 数组都不能申请到 chunk 时,则会像 Last Remainder 尝试进行分配。
2. 分配区
ptmalloc 为了满足多线程并发场景下,设计了主配区和非主分配区的概念。
1. 分配区
在多线程的场景下,如果一个分配区被锁住了,另一个线程就会申请一个新的分配区,并加上全局锁,申请出来的分配区和已有的分配区进行双向链表连接起来,分配区只会增不会减。
2. 主分配区
ptmalloc 最开始默认只有一个分配区,该分配区为主分配区且只有一个主分配区。
1. 主分配区可以向堆/共享区申请内存。
2. 当归还内存时,如果是堆申请的则归还到 bins 数组里,否则调用 munmap 直接归还到物理内存。
3. 当线程进入该分配区则会进行加锁,不管是申请内存还是是否内存。
3. 非主分配区
1. 非主分配区只能向共享区申请内存。
2. 当归还内存时,直接调用 mummap 换到物理内存。
3. 当线程进入该分配区则会进行加锁,不管是申请内存还是是否内存。
4. 非主分配区可以有很多个,主分配区只有一个,锁竞争严重,就会申请更多的非主分配区,非主分配区只增不减。
三 申请/释放逻辑
这里只是粗粒度的把申请/释放的流程走一遍。
1. 分配算法
<= 64 字节的内存:优先向 fast bins 寻找。
65 ~ 512 字节的内存:优先向 unsorted bins 和 small bins 寻找。
>= 512 字节的内存:优先向 unsorted bins 和 small bins 和 large bins 寻找。
>= mmap 阈值:直接调用 mmap 进行分配内存。
2. 申请逻辑
1. 首先获取分配区的锁,如果被锁住则去申请下一个分配区,直到申请到,否则重新分配主分配区并加上大锁,锁住所有的分配区。新分配的主分配区则会 mmap 一段内存空间映射到共享区,并设置 top chunk ,即该 mmap 出来的顶部地址。
2. 讲用户需要的内存大小转行/对齐到对应的 chunk 大小。
3. 如果对齐后的 chunk 在 fast bins 数组里,则从 fast bins 数组里分配一个合适的 chunk 出去,如果没有则取 small bins 里寻找,如果有则分配出去,否则说明需要的内存大小 > 512 字节或者 small bins 没有小块内存块了。
4. small bins 都无法申请到内存块,则会把 fast bins 里的内存块尝试合并,并放入 unsorted bins 里,再去 unsorted bins 里找,如果 unsorted bins 里只有一个 chunk 且 该 chunk 是上次分配的和该 chunk 在 small bins 范围内,则会将该 chunk 进行切割并放到 Last Remainder 里,否则放入到 small bins 或者 large bins。
5. 到这里需要的内存大小 small bins/unsorted bins/fast bins 都无法满足,则会去 large bins 尝试分配,如果有则返回,否则说明整个 bins 数组都无法满足需要的内存,下一步则会判断该分配区是主还是非主分配区。
6. 如果是主分配区且申请的内存大小 <= mmap阈值,则伸展 top chunk 堆顶指针,否则调用 mmap 一段独立的内存区域分配出去。
7. 如果是非主分配区申请的内存大小 <= mapp阈值,则伸展 top chunk 堆顶指针,这里是模拟主分配区的行为,伸展在非主分配区是 mmap 一段内存区域并和之前的区域连接起来,否则大于 mmap 阈值则直接 mmap 一块独立的内存区域,不和之前任何 mmap 出来的内存块进行关联,并返回给用户。
3. 释放逻辑
1. 先申请分配区的锁,如果被锁住则或者下一个分配区的锁。
2. 如果指针为空则什么也不干直接返回,否则判断该 chunk 是否是 mmap 出来的大块内存,如果是则直接调用 munmap 归还给系统,如果该 chunk 大小大于 mmap 分配阈值,并启用 mmap
分配阈值的动态调整机制,则让 mmap 的分配阈值等于当前 chunk 的大小,并让 mmap 的收缩阈值等于分配阈值的 2 倍。
3. 到这步说明 chunk 不是 mmap 出来的大块内存,先判断是否和 top chunk 相邻如果是直接合并然后返回,否则如果在 fast bins 的范围内,则挂到里面并不修改他的使用状态,防止被合并以便下次更快的分配出去,如果不在 fast bins 范围内则判断前一个 chunk 是否空闲,是就合并,这里合并之后也会尝试和 top chunk 进行合并,如果不能合并则把合并之后的 chunk 放到 unsorted bins 里,如果该 chunk 大于 64kb,则会将 fast bins 里的所有 chunk 进行合并,并放到 unsorted bins 里,并且如果 top chunk 的大小大于 mmap 的收缩阈值,则会收缩 top chunk 的大小,即收缩堆顶指针,但最开始分配的内存不会收缩,如果是非主分配区的 sub heap,也会进行收缩他的 top chunk 指针,如果 top chunk 是整个 sub heap 则会直接调用 munmap还给系统。