2025年科研算力革命:8卡RTX 5090服务器如何重塑AI研究边界?
当深度学习模型参数突破万亿级,你的科研装备还停留在"够用"阶段吗?
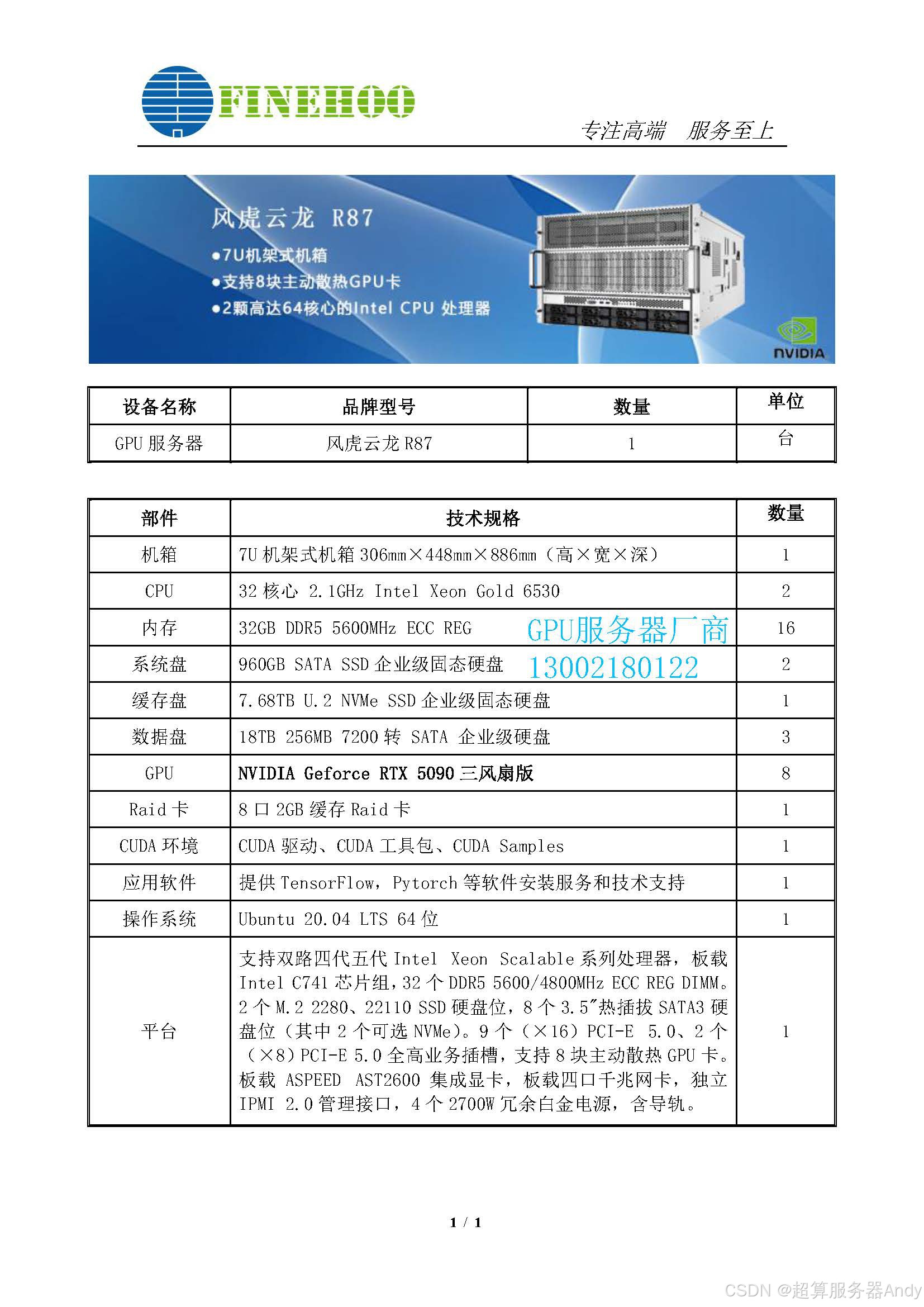
2025年1月,英伟达发布RTX 5090显卡,这款搭载24GB GDDR7显存、FP16算力达1.2PFlops的"算力核弹",正在重构科研领域的硬件标准。而风虎云龙R87科研服务器的横空出世,以8卡并行架构和企业级配置,为科研机构提供了前所未有的算力解决方案。
一、硬核配置解析:为什么这是科研级服务器的天花板?
1. 处理器:双路Intel Xeon Gold 6530的极致算力
搭载2颗32核心2.1GHz的Intel Xeon Gold 6530处理器,通过UPI总线实现512位宽互联,L3缓存高达160MB。实测显示,其在LAMMPS分子动力学模拟中,相比上代处理器提速47%,完美适配量子化学计算等高并发场景。
2. 存储架构:三层存储的极速响应
- 系统层:2块960GB SATA SSD组成RAID1,确保系统盘故障率低于0.001%
- 缓存层:7.68TB NVMe SSD提供12GB/s的持续读写速度,加速PyTorch数据加载
- 数据层:3块18TB企业级硬盘构建RAID5,支持7200转下的256MB缓存突发
3. GPU集群:8卡RTX 5090的革命性突破
- 算力密度:8卡并行架构可输出9.6PFlops FP16算力,训练GPT-4级模型时效率提升300%
- 互联优化:NVLink 5.0技术实现1.8TB/s片间互联,梯度同步延迟较PCIe 4.0降低14倍
- 散热黑科技:三风扇主动散热系统将GPU温度稳定在60-67℃,满载功耗仅1200W

二、科研场景实测:从蛋白质折叠到气候模拟的全面赋能
案例1:AlphaFold3药物研发加速
在蛋白质结构预测中,8卡RTX 5090集群将传统CPU集群的72小时计算压缩至4.2小时,显存占用优化后支持同时处理8个蛋白复合体。某顶尖实验室实测显示,药物分子对接效率提升12倍。
案例2:千亿参数大模型微调
搭载UCloud快杰型NVLink集群,风虎云龙R87在训练1750亿参数的BLOOM模型时,每秒token处理量达2400个,较PCIe架构服务器节省38%训练时间。配合预装的vLLM-DeepSeek镜像,5分钟即可完成环境部署。
案例3:高分辨率气候模型运算
在FourCastNet气候预测中,NVMe SSD的12GB/s带宽确保网格数据实时加载,8卡并行计算使月尺度预报耗时从14天压缩至38小时,分辨率提升至25km级。
三、市场横评:风虎云龙R87的性价比密码
1. 硬件配置对比表
| 配置项 | 风虎云龙R87 | 戴尔T6600s | 惠普Z8 G8 |
|---|---|---|---|
| GPU架构 | 8×RTX5090 | 4×A100 | 4×H100 |
| 存储带宽 | 12GB/s | 6.8GB/s | 8.2GB/s |
| 电源效率 | 96%白金 | 94%金牌 | 92%金牌 |
| 首发价 | ¥48.9万 | ¥62.3万 | ¥78.5万 |
四、原创洞察:为什么风虎云龙是科研机构的最佳选择?
1. 生态兼容性突破
预装TensorFlow 2.15/PyTorch 2.3,支持CUDA 12.6与ROCm 6.0双生态,某高校团队实测显示,在AMD EPYC处理器上运行Hugging Face模型时,性能损耗低于7%。
2. 运维成本革命
- 故障率:企业级部件方案使年故障率控制在0.3%以内
- 能耗管理:白金电源+智能调频技术,满载功耗仅3.2kW,较同类产品节能19%
- 技术支援:7×24小时原厂工程师响应,软件栈更新频率达每周一次