基于Llama的RAG 3种模型配置方法
目录
方法一:使用Llama-index为智谱构建的专门的包
安装六个包
环境变量读取APIkey
配置对话模型
测试对话模型
流式输出
出现的原因
解决方案
配置嵌入模型
测试嵌入模型
方法二:借助OpenAI的库接入智谱
重写类
重写OpenAI类
用NewOpenAI这个类来配置llm
测试对话模型
修改源码
修改对话模型源码
修改嵌入模型源码
方法三:自定义模型接口
确认电脑IP
在本地启动Ollama服务
参考文章
RAG(检索增强生成)是结合检索与生成式 AI 的技术框架。核心逻辑是先从外部知识库精准检索相关信息,再将其作为上下文输入大模型生成回答。技术上依赖检索引擎(如向量数据库、BM25)、大语言模型(如 GPT、LLaMA)及数据预处理技术。通过检索增强,解决大模型知识滞后、幻觉问题,提升回答准确性。应用广泛,涵盖智能客服、医疗问答、法律检索、教育辅导等场景,能基于特定领域知识提供精准、可控的生成内容。
wow-RAG 是 Datawhale 推出的 RAG 技术实践项目,网址:datawhalechina/wow-rag: A simple and trans-platform rag framework and tutorial https://github.com/datawhalechina/wow-rag
方法一:使用Llama-index为智谱构建的专门的包
安装六个包
%pip install llama-index-core
%pip install llama-index-embeddings-zhipuai
%pip install llama-index-llms-zhipuai
%pip install llama-index-readers-file
%pip install llama-index-vector-stores-faiss
%pip install llamaindex-py-client安装的库分别支持:从文件中读取知识内容;使用嵌入模型为文本生成向量;将向量存入 FAISS 数据库进行高效检索;在用户提问时,召回最相关的文本块;使用大语言模型(如 GLM)根据上下文生成高质量回答。
环境变量读取APIkey
import os
from dotenv import load_dotenv# 加载环境变量
load_dotenv()
# 从环境变量中读取api_key
api_key = os.getenv('ZHIPU_API_KEY')
base_url = "https://open.bigmodel.cn/api/paas/v4/"
chat_model = "glm-4-flash"
emb_model = "embedding-2"配置对话模型
from llama_index.llms.zhipuai import ZhipuAI
llm = ZhipuAI(api_key = api_key,model = chat_model,
)测试对话模型
# 测试对话模型
response = llm.complete("你是哪位?你是干什么的?")
print(response)调用了 llm 对象的 complete 方法,向大语言模型发送一条提示词。complete 是 LlamaIndex 中用于触发文本生成的标准方法。模型接收到请求后会返回生成的回复内容,并将其赋值给变量 response。

流式输出
response = llm.stream_complete("你是谁?")
for chunk in response:print('\n')print(chunk, end="",flush=True)与普通的 complete 方法不同,stream_complete 会以流式(streaming)方式获取模型的生成结果,这意味着模型在生成回答的过程中会逐步返回中间结果(即每个文本块 chunk),而不是等到全部内容生成完毕才一次性返回。
使用 for 循环遍历 response 中的每一个 chunk,即模型生成的一小段文本。每次接收到新的文本块时,先打印一个换行符 \n,以便每个新接收的文本块单独显示一行;然后使用 print(chunk, end="", flush=True) 将当前文本块输出到控制台,end="" 表示不自动换行,使得多个 chunk 可以连贯地拼接成完整句子,flush=True 则确保内容立即刷新显示在终端上,不会因为缓冲区未满而延迟输出。
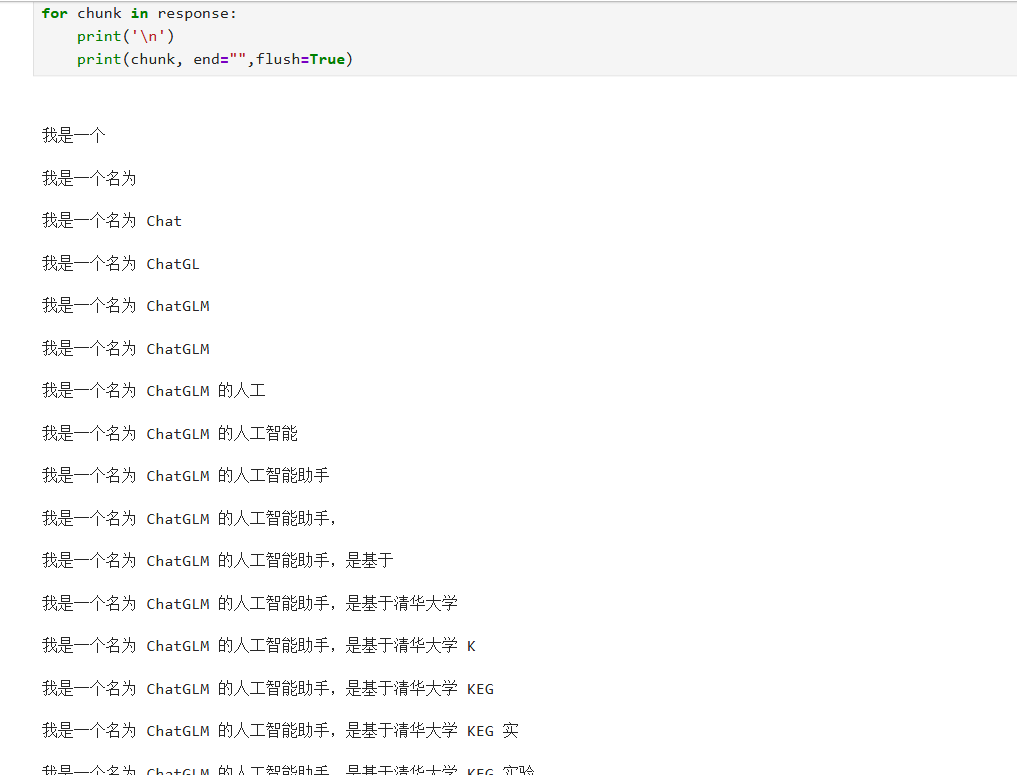
我想体验真正的流式输出,所以我删除第一个print:
response = llm.stream_complete("你是谁?")
for chunk in response:print(chunk, end="", flush=True)输出为:

问题出在 print('\n') 这一行。它在每次接收到一个 chunk 之前都会打印一个换行符,这就导致了每个 chunk 都被强制显示在新的一行,结果看起来就像是一次性输出了好多行,而不是我期望的“逐字打印”的流式效果。
这说明模型在生成回答时并不是一次性完整输出,而是逐块(chunk by chunk)生成文本片段,并且每个新 chunk 是对前一个内容的扩展和覆盖,而不是追加新的句子。这种行为通常出现在一些语言模型的流式接口中,尤其是在封装层没有正确处理增量更新逻辑的情况下。
出现的原因
(1)模型返回的是增量文本(delta),而非完整上下文:
每个 chunk 并不是新增的一段内容,而可能是当前模型认为完整的最新版本;
(2)封装层未做去重或上下文拼接处理:
在代码中只是简单地打印了每一个 chunk,而没有判断它是“新增内容”还是“整体替换”,所以你会看到每一段都是前面内容的重复叠加,看起来像是“越说越多”,但其实只是模型不断修正自己的输出;
(3)输出粒度过细:
有些模型会将每个词甚至字作为一个 chunk 发送回来,导致你在终端上看到一连串看似冗余的输出,这种设计是为了模拟“打字效果”,但如果前端没有做合并优化,就会出现看到的现象。
解决方案
运行以下代码就能解决问题:
response = llm.stream_complete("你是谁?")
current_output = ""for chunk in response:current_text = chunk.text # 获取当前完整生成的文本new_part = current_text[len(current_output):] # 只取新增部分if new_part:print(new_part, end="", flush=True)current_output = current_text # 更新已输出内容错误示例:
response = llm.stream_complete("你是谁?")
current_output = ""
for chunk in response:new_part = chunk[len(current_output):] # 只取出新增部分if new_part:print(new_part, end="", flush=True)current_output = chunk会报错:TypeError Traceback (most recent call last) Cell In[10], line 4 2 current_output = "" 3 for chunk in response: ----> 4 new_part = chunk[len(current_output):] # 只取出新增部分 5 if new_part: 6 print(new_part, end="", flush=True) TypeError: 'CompletionResponse' object is not subscriptable
TypeError: 'CompletionResponse' object is not subscriptable
说明你在尝试对一个 CompletionResponse 类型的对象使用索引操作(即 chunk[len(current_output):] 中的 [] 操作),但该对象并不支持这种类似字符串或列表的切片行为。应该先提取出 chunk 对象中的实际文本字段(通常是 .text 或 .delta.content,具体取决于模型封装方式),然后再进行比较和输出控制。
配置嵌入模型
# 配置嵌入模型
from llama_index.embeddings.zhipuai import ZhipuAIEmbedding
embedding = ZhipuAIEmbedding(api_key = api_key,model = emb_model,
)测试嵌入模型
# 测试嵌入模型
emb = embedding.get_text_embedding("你好呀呀")
len(emb), type(emb)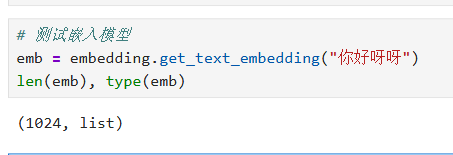
配置成功
方法二:借助OpenAI的库接入智谱
核心目的是绕过 LlamaIndex 对模型上下文长度的硬编码限制检查,从而实现使用非官方支持的 OpenAI 兼容接口(如 Zhipu AI、Moonshot、阿里云百炼等)的大语言模型。
重写类
重写OpenAI类
from llama_index.llms.openai import OpenAI
from llama_index.core.base.llms.types import LLMMetadata,MessageRole
class NewOpenAI(OpenAI):def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)@propertydef metadata(self) -> LLMMetadata:# 创建一个新的LLMMetadata实例,只修改context_windowreturn LLMMetadata(context_window=8192,num_output=self.max_tokens or -1,is_chat_model=True,is_function_calling_model=True,model_name=self.model,system_role=MessageRole.USER,)class NewOpenAI(OpenAI):def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)构造函数只是简单地调用了父类的初始化方法,不做任何修改,保持原有行为一致。
@propertydef metadata(self) -> LLMMetadata:return LLMMetadata(context_window=8192,num_output=self.max_tokens or -1,is_chat_model=True,is_function_calling_model=True,model_name=self.model,system_role=MessageRole.USER,)metadata 是一个只读属性,LlamaIndex 在运行时会用它来判断当前模型的能力,比如:
- 支持多长的上下文输入?
- 最多能输出多少个 token?
- 是否是 chat 模型?
- 是否支持 function calling?
默认情况下,LlamaIndex 的 OpenAI 类会根据 model 名称查找对应的上下文窗口长度(context_window),如果找不到就会报错。而通过重写这个属性,直接指定了一个固定的 context_window=8192,跳过了模型名称匹配的过程,从而绕开了限制。
用NewOpenAI这个类来配置llm
llm = NewOpenAI(temperature=0.95,api_key=api_key,model=chat_model,api_base=base_url
)temperature=0.95:控制生成文本的随机性,数值越高越发散,越低越保守。
api_key=api_key:访问 API 所需的身份认证密钥,从环境变量中获取。我们的存放在.env里面。
model=chat_model:指定使用的模型名称,例如 "glm-4-flash"。
api_base=base_url:指定要调用的第三方 API 地址,这里是智谱AI的 base URL。
测试对话模型
response = llm.complete("你是谁?")
print(response)同样也可以用流式输出,步骤同上
修改源码
修改对话模型源码
找到这个文件:Lib\site-packages\llama_index\llms\openai\utils.py
在大约第30行,有一个GPT4_MODELS: Dict[str, int]
在这里面列举了很多模型的名称,把智谱的glm-4-flash加进入,变成这样:
"gpt-4": 8192,
"gpt-4-32k": 32768,
改成:
"gpt-4": 8192,
"glm-4-flash": 8192,
"gpt-4-32k": 32768,
修改嵌入模型源码
改源码:
Lib\site-packages\llama_index\embeddings\openai\base.py
一共改四个地方
class OpenAIEmbeddingModelType(str, Enum):
最下面增加
EMBED_2 = "embedding-2"
class OpenAIEmbeddingModeModel(str, Enum):
最下面增加
EMBED_2 = "embedding-2"
_QUERY_MODE_MODEL_DICT = {
最下面增加
(OAEM.TEXT_SEARCH_MODE, "embedding-2"): OAEMM.EMBED_2,
_TEXT_MODE_MODEL_DICT = {
最下面增加
(OAEM.TEXT_SEARCH_MODE, "embedding-2"): OAEMM.EMBED_2,
改了上面这四个地方,再调用OpenAIEmbedding这个类,就可以正常使用了
如果怕麻烦,也可以用教程里附的base.py 直接替换。
如果不小心导入过llama_index,改完源码不要忘了重启jupyter内核。
方法三:自定义模型接口
Ollama里的qwen2系列非常棒,有很多尺寸规模的模型,最小的模型只有 0.5b,然后还有1.5b、7b、32b等等,可以适应各种设备。访问 https://ollama.com。 下载Windows版本。直接安装。 安装完成后,打开命令行窗口,输入 ollama,如果出现 Usage: Available Commands: 之类的信息,说明安装成功。我们用qwen2:7b这个模型就行,整个还不到4G。 运行 ollama run qwen2:7b如果出现了success,就说明安装成功。 然后会出现一个>>>符号,这就是对话窗口。可以直接输入问题。想要退出交互页面,直接输入 /bye 就行。斜杠是需要的。否则不是退出交互页面,而是对大模型说话,它会继续跟你聊。浏览器中输入 127.0.0.1:11434,如果出现 Ollama is running说明端口运行正常。
ollama的安装以及模型导入可以参考以下博客:
Ollama 自定义导入模型_外部下载的gguf大模型文件怎么安装到ollama里面-CSDN博客文章浏览阅读290次,点赞7次,收藏4次。nvidia-smi我的笔记本 可怜兮兮的GPU。_外部下载的gguf大模型文件怎么安装到ollama里面https://blog.csdn.net/m0_69704099/article/details/148778969?fromshare=blogdetail&sharetype=blogdetail&sharerId=148778969&sharerefer=PC&sharesource=m0_69704099&sharefrom=from_linkOllama API-CSDN博客文章浏览阅读368次,点赞4次,收藏9次。datawhale.com 动手学Ollama。
https://blog.csdn.net/m0_69704099/article/details/148812245?fromshare=blogdetail&sharetype=blogdetail&sharerId=148812245&sharerefer=PC&sharesource=m0_69704099&sharefrom=from_linkOllama 在LangChain中的应用 Python环境-CSDN博客文章浏览阅读882次,点赞16次,收藏16次。你是一位经验丰富的电商文案撰写专家。你的任务是根据给定的产品信息创作吸引人的商品描述。请确保你的描述简洁、有力,并且突出产品的核心优势。""")请为以下产品创作一段吸引人的商品描述:产品类型: {product_type}核心特性: {key_feature}目标受众: {target_audience}价格区间: {price_range}品牌定位: {brand_positioning}请提供以下三种不同风格的描述,每种大约50字:1. 理性分析型2. 情感诉求型。
https://blog.csdn.net/m0_69704099/article/details/148855725?fromshare=blogdetail&sharetype=blogdetail&sharerId=148855725&sharerefer=PC&sharesource=m0_69704099&sharefrom=from_link
确认电脑IP
Windows: 打开命令提示符(cmd),输入 ipconfig 命令,找到你的网络适配器对应的IPv4地址。
macOS/Linux: 打开终端,输入 ifconfig 或 ip addr show 命令,查找你的网络接口对应的IPv4地址。
# 我们先用requets库来测试一下大模型
import json
import requests
# 190.168.000.12就是部署了大模型的电脑的IP,
# 请根据实际情况进行替换
BASE_URL = "http://190.168.000.12:11434/api/chat"将请求代码中的 BASE_URL 修改为指向你当前电脑的IP地址
在本地启动Ollama服务
CMD:
set OLLAMA_HOST=0.0.0.0:11434
ollama run qwen2:7b
如果使用的是 PowerShell,设置 OLLAMA_HOST 环境变量(PowerShell):
$env:OLLAMA_HOST = "0.0.0.0:11434"
ollama run qwen2:7b上述命令只是临时设置环境变量,只对当前终端窗口有效。关闭窗口后失效。
如果想永久设置,可以使用系统环境变量配置:
(1)搜索“编辑系统环境变量”
(2)点击“环境变量”
(3)在“用户变量”或“系统变量”中添加:
变量名:OLLAMA_HOST
变量值:0.0.0.0:11434
payload = {"model": "qwen2:7b","messages": [{"role": "user","content": "请写一篇100字左右的文章,论述法学专业的就业前景。"}]
}
response = requests.post(BASE_URL, json=payload)
print(response.text)
payload = {"model": "qwen2:7b","messages": [{"role": "user","content": "请写一篇100字左右的文章,论述法学专业的就业前景。"}],"stream": True
}
response = requests.post(BASE_URL, json=payload, stream=True) # 在这里设置stream=True告诉requests不要立即下载响应内容
# 检查响应状态码
if response.status_code == 200: # 使用iter_content()迭代响应体 for chunk in response.iter_content(chunk_size=1024): # 你可以设置chunk_size为你想要的大小 if chunk: # 在这里处理chunk(例如,打印、写入文件等) rtn = json.loads(chunk.decode('utf-8')) # 假设响应是文本,并且使用UTF-8编码 print(rtn["message"]["content"], end="")
else: print(f"Error: {response.status_code}") # 不要忘记关闭响应
response.close()
如果遇到报错,可以在CMD里输入:
curl http://localhost:11434/api/chat -X POST -H "Content-Type: application/json" -d "{\"model\": \"qwen2:7b\", \"messages\": [{\"role\": \"user\", \"content\": \"你好\"}]}"如果输出为:
{"model":"qwen2:7b","created_at":"2025-07-16T04:50:25.9652222Z","message":{"role":"assistant","content":"你好"},"done":false} {"model":"qwen2:7b","created_at":"2025-07-16T04:50:26.6918219Z","message":{"role":"assistant","content":"!"},"done":false} {"model":"qwen2:7b","created_at":"2025-07-16T04:50:27.3889671Z","message":{"role":"assistant","content":"很高兴"},"done":false} {"model":"qwen2:7b","created_at":"2025-07-16T04:50:28.0123335Z","message":{"role":"assistant","content":"能"},"done":false} {"model":"qwen2:7b","created_at":"2025-07-16T04:50:28.6996211Z","message":{"role":"assistant","content":"为你"},"done":false} {"model":"qwen2:7b","created_at":"2025-07-16T04:50:29.2292556Z","message":{"role":"assistant","content":"服务"},"done":false} {"model":"qwen2:7b","created_at":"2025-07-16T04:50:29.7292238Z","message":{"role":"assistant","content":"。"},"done":false} {"model":"qwen2:7b","created_at":"2025-07-16T04:50:30.2031634Z","message":{"role":"assistant","content":"有什么"},"done":false} {"model":"qwen2:7b","created_at":"2025-07-16T04:50:30.6622801Z","message":{"role":"assistant","content":"我能"},"done":false} {"model":"qwen2:7b","created_at":"2025-07-16T04:50:31.0990926Z","message":{"role":"assistant","content":"帮助"},"done":false} {"model":"qwen2:7b","created_at":"2025-07-16T04:50:31.5958556Z","message":{"role":"assistant","content":"你的"},"done":false} {"model":"qwen2:7b","created_at":"2025-07-16T04:50:32.0505737Z","message":{"role":"assistant","content":"吗"},"done":false} {"model":"qwen2:7b","created_at":"2025-07-16T04:50:32.5099374Z","message":{"role":"assistant","content":"?"},"done":false} {"model":"qwen2:7b","created_at":"2025-07-16T04:50:32.9703164Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":40135156500,"load_duration":19543345200,"prompt_eval_count":20,"prompt_eval_duration":13423753200,"eval_count":14,"eval_duration":7025921300}
则证明:Ollama 正常监听 localhost;qwen2:7b 模型加载成功;推理过程正常进行
如果代码块半天没有反应,这是因为让模型写一篇 1000 字左右的文章,需要大量的推理 token(可能超过 1500 token),而本地大模型(特别是 CPU 上运行的)速度较慢,导致:
- 推理时间长(几十秒到几分钟)
- 没有流式输出,所以
response.text会等到整个响应完成才返回 - 给人一种“卡住”或“转圈”的错觉
另外,如果刚才输入CMD的代码是:
ollama run qwen2:7b这会进入交互聊天模式(出现 >>> 提示符),它会占用模型资源并可能导致 API 响应变慢或延迟。
建议改用:
set OLLAMA_HOST=0.0.0.0:11434
ollama serve这样 Ollama 就只会专注于处理 API 请求,不会卡在命令行输入界面。
参考文章
https://github.com/datawhalechina/wow-rag![]() https://github.com/datawhalechina/wow-rag
https://github.com/datawhalechina/wow-rag