MySQL事务和索引原理
目录
1. MySQL事务原理
1.1. 事务的基本概念
1.2. 事务隔离的实现机制
1.3. 事务的启动方式
2. 索引的原理
2.1. 索引的作用
2.2. 索引常用模型及适用场景
2.3. InnoDB中的索引结构
2.4. 索引维护
2.5. 覆盖索引
2.6. 联合索引和最左缀原则
2.7. 索引下推
1. MySQL事务原理
1.1. 事务的基本概念
- 补充内容见SQL本栏以前的SQL章节
事务的基本概念:
什么是事务?
- 一组数据库操作,要么全部成功,要么全部失败,具有“原子性”。
- 典型应用场景:银行转账操作,必须保证“减钱”和“加钱”一起完成。
事务的支持
- MySQL 的事务支持是在 存储引擎层 实现的。
- InnoDB 支持事务,MyISAM 不支持(这是 InnoDB 取代 MyISAM 的主要原因之一)。
ACID 中的 “I” —— 隔离性(Isolation)
什么是隔离性:
多个事务并发执行时,各自的操作不应相互干扰。
常见并发问题:
| 问题类型 | 说明 |
| 脏读 | 读取了另一个事务尚未提交的数据 |
| 不可重复读 | 同一事务中多次读取结果不一致 |
| 幻读 | 同一事务中读取到“新增或删除”的记录 |
SQL 标准隔离级别(由低到高):
| 隔离级别 | 特点 | 是否存在脏读 | 不可重复读 | 幻读 |
| Read Uncommitted | 可读未提交数据 | ✅ 是 | ✅ 是 | ✅ 是 |
| Read Committed | 只读已提交数据 | ❌ 否 | ✅ 是 | ✅ 是 |
| Repeatable Read | 可重复读(MySQL 默认) | ❌ 否 | ❌ 否 | ✅ 是 |
| Serializable | 串行化(最安全) | ❌ 否 | ❌ 否 | ❌ 否 |
- MySQL 默认隔离级别是:Repeatable Read
- Oracle 默认隔离级别是:Read Committed
- 迁移时要注意设置一致:
transaction-isolation = READ-COMMITTED
1.2. 事务隔离的实现机制
MVCC(多版本并发控制):
- 每条记录在更新时会生成一条回滚记录。
- 所有版本记录可通过回滚日志回溯。
- 不同事务有不同的 read view(读取视图)。
示例:
值从 1 → 2 → 3 → 4,某个事务的 read view 可能还看到的是 1。
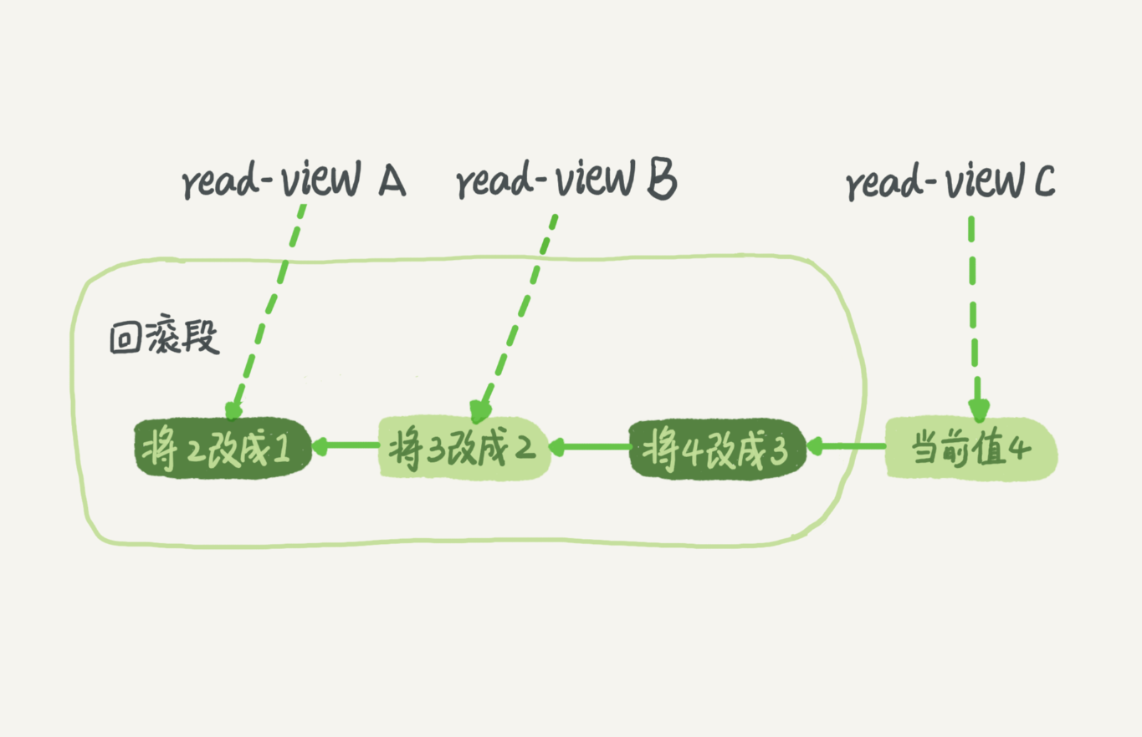
回滚日志的清理机制:
- 系统会判断是否仍有事务需要旧的版本。
- 当没有比当前回滚日志更早的事务存在时,可清理该日志。
避免使用长事务的原因
- 占用大量回滚日志(导致 ibdata 文件急剧膨胀)
- 锁资源占用,可能阻塞其他事务
- 历史版本维护成本高
MySQL 5.5 之前回滚日志无法自动回收,可能导致文件过大。
1.3. 事务的启动方式
- 自动模式:很多数据库系统(例如MySQL、PostgreSQL)默认处于自动事务模式。在这种模式下,每个SQL语句都被当作一个事务,并且会自动地启动、执行和提交。这种模式适合大多数的应用,因为它简单易用,但是可能会导致频繁的事务启动和提交,影响性能。
- 显式地启动事务:在显式事务模式下,你需要使用特定的SQL语句来启动事务,通常是BEGIN、START TRANSACTION等。在事务内,你可以执行多个SQL语句,并且通过COMMIT语句提交事务,或者使用ROLLBACK语句回滚事务。这种方式给予了你更多的控制权,可以在一个事务内执行多个操作,然后一次性地提交或回滚。
- 编程式启动事务:在应用程序中,特定的编程语言和数据库连接库(例如JDBC、Hibernate等)提供了编程式事务控制的能力。在这种方式下,你可以在代码中显式地启动、提交和回滚事务。这种方式通常用于需要更复杂事务逻辑的应用,例如需要多个数据库操作保持一致性的情况。
| 方式 | 描述 |
| 显式事务 |
/ → 或 |
| 隐式事务 |
:所有语句自动开启事务 |
| 推荐方式 | 使用显式事务 + |
警惕意外长事务:
- 有些客户端库默认执行
SET autocommit=0,若未手动提交,可能造成 隐式长事务。 - 推荐使用
COMMIT WORK AND CHAIN:执行提交后立即开启下一个事务。 - 可以在 information_schema 库的 innodb_trx 这个表中查询长事务,比如下面这个语句,用于查找持续时间超过 60s 的事务。
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>602. 索引的原理
2.1. 索引的作用
本质上,索引是“用于加速数据检索的数据结构”。
- 提升查询效率:加速 WHERE 条件、JOIN、ORDER BY、GROUP BY 等语句的执行。
- 加速排序和分组:利用索引中的有序特性,减少排序计算成本。
- 实现唯一性约束:例如主键索引保证数据唯一。
- 辅助查询优化器选择执行计划。
2.2. 索引常用模型及适用场景
| 模型 | 结构特点 | 优点 | 缺点 | 适用场景 |
| 哈希表 | 键值对映射(无序) | 查询速度极快,O(1) | 无序,不支持范围查询或排序 | 等值查询,如 |
| 有序数组 | 连续内存中有序排列 | 二分查找快,适合范围查询 | 插入成本高(需整体移动) | 静态数据、范围查找 |
| 搜索树 (如红黑树) | 动态平衡树结构 | 插入/删除/查找复杂度 O(logN) | 难以快速进行磁盘页访问优化 | 通用结构,适合内存存储 |
| B+树 | 多叉平衡树,数据存在叶子节点 | 磁盘友好,支持范围查询 | 内存占用比哈希略高 | 数据库和文件系统中广泛使用 |
- 查询频繁、数据量大 → ✅ B+树最适合。
- 只做等值查询、数据可全部放内存 → ✅ 哈希表优先。
- 插入频繁 → ❌ 避免用有序数组。
- 数据静态、查找密集 → ✅ 有序数组也可考虑。
2.3. InnoDB中的索引结构
为什么用 B+ 树:
- 磁盘访问效率高:每个节点存储多个键值对,I/O 次数少。
- 范围查询友好:叶子节点通过指针串联,支持快速范围扫描。
- 高度低:一般 2~3 层就能存储百万级数据。
B+ 树结构特点:
- 所有值存储在叶子节点,非叶节点只做索引。
- 叶子节点间通过链表连接,支持顺序访问。
- 高度平衡,插入删除操作后自动维护平衡。
InnoDB 的索引类型:
| 索引类型 | 存储内容说明 | 特点 |
| 主键索引(聚簇索引) | 叶子节点存储整行数据 | 索引就是数据,按主键有序 |
| 辅助索引(二级索引) | 叶子节点存储主键值(不是整行) | 需回表查询实际数据 |
- 回表查询:通过辅助索引定位主键,再通过主键索引获取整行数据。
示例:
假设,我们有一个主键列为 ID 的表,表中有字段 k,并且在 k 上有索引。
这个表的建表语句是:
mysql> create table T(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;表中 R1~R5 的 (ID,k) 值分别为 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6),两棵树的示例示意图如下。
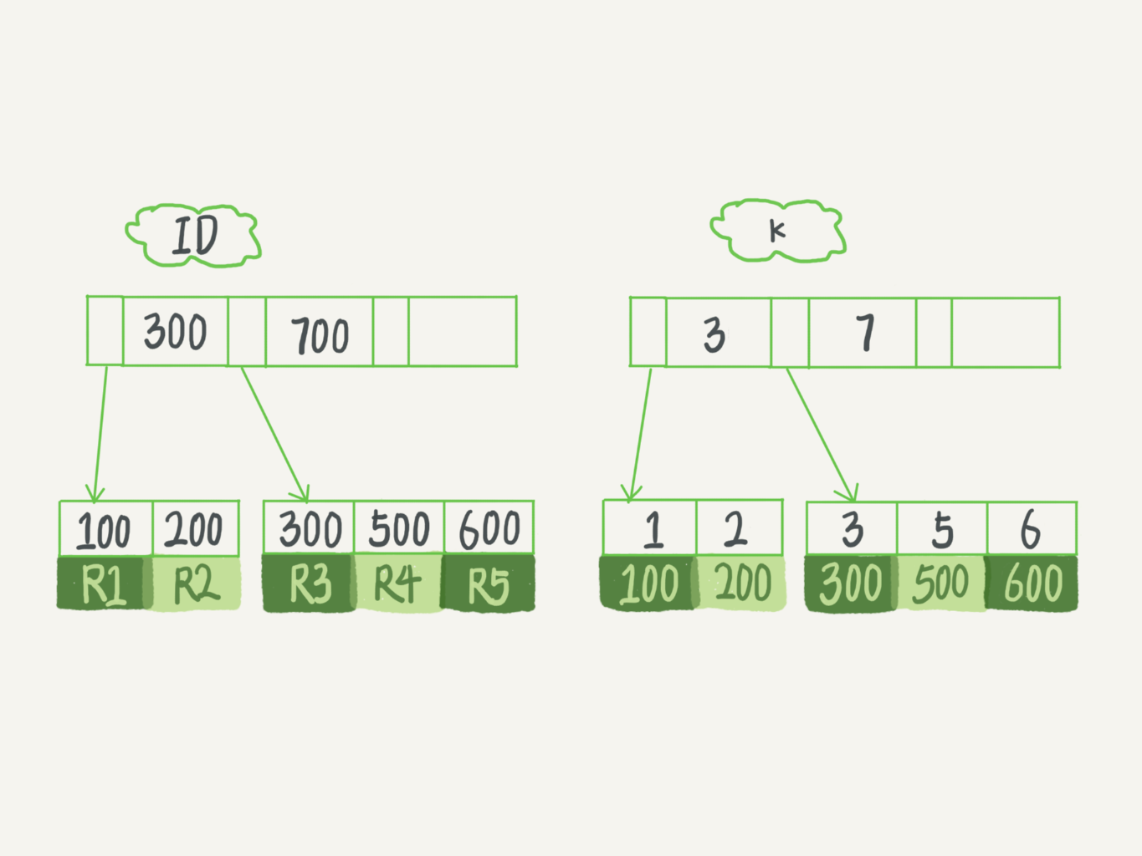
从图中不难看出,根据叶子节点的内容,索引类型分为主键索引和非主键索引。
- 主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
- 非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
基于主键索引和普通索引的查询有什么区别?
- 如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
2.4. 索引维护
索引维护的概念:
索引维护是指在数据库执行 INSERT、DELETE、UPDATE 等写操作时,自动同步更新对应的索引结构,以保持数据和索引的一致性。
索引维护的基本过程:
| 操作类型 | 索引维护动作 | 说明 |
| 插入 | 在对应的索引结构中插入新记录的位置 | B+ 树节点可能需要分裂或调整 |
| 删除 | 从索引中删除指定记录的键值 | 涉及节点合并或重平衡 |
| 更新 | 若更新字段被索引,等同于删除+插入 | 比仅更新值成本更高 |
- 注意:更新非索引字段不会触发索引更新,但更新索引字段会引发一次**“删除旧记录 + 插入新记录”**的完整流程。
索引维护对性能的影响:
| 操作 | 对性能的影响 |
| 插入大量数据 | 索引频繁重构,耗时明显 |
| 批量更新索引列 | 成本高,建议避免大批量更新索引字段 |
| 删除操作 | 需判断是否触发合并,影响写入性能 |
| 太多冗余索引 | 每次写操作都需同步更新所有相关索引 |
优化建议:
- 控制索引数量,仅对常用查询字段建立索引;
- 批量插入或导入数据前,可暂时移除索引,导入后重建;
- 避免频繁修改被索引字段,降低维护成本。
主键的选择:
主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
从性能和存储空间方面考量,自增主键往往是更合理的选择。
有没有什么场景适合用业务字段直接做主键的呢?还是有的。比如,有些业务的场景需求是这样的:
- 只有一个索引;
- 该索引必须是唯一索引。
这就是典型的 KV 场景。
由于没有其他索引,所以也就不用考虑其他索引的叶子节点大小的问题。
这时候我们就要优先考虑上面提到的“尽量使用主键查询”原则,直接将这个索引设置为主键,可以避免每次查询需要搜索两棵树。
2.5. 覆盖索引
回表的概念:
回表(回表查询)是数据库查询优化器在执行查询时的一种策略。当查询的条件无法通过索引直接获取数据时,查询优化器会选择通过索引获取到的主键值,然后再根据这些主键值去主键索引中查找对应的数据,这个过程就叫做回表。
覆盖索引的定义:
如果查询所需要的字段都能在一个索引中直接获取,就不需要回表,这种索引称为 覆盖索引。
优点:
- 避免回表,减少树的访问次数。
- 提升查询性能,尤其在 高频请求 中表现明显。
示例:
SELECT ID FROM T WHERE k BETWEEN 3 AND 5;- 由于
ID存储在索引k(k)中,不需要回表,形成覆盖索引。 - 引擎层实际读取的是三条索引记录(R3~R5),但 Server 层认为扫描了 2 行(符合条件的2行)。
2.6. 联合索引和最左缀原则
联合索引概念:
联合索引是指在一个索引中包含多个列的索引。
联合索引的优势:
- 支持多列联合查询加速:对于同时包含多个字段的查询,联合索引可以一次性命中多个字段,提高检索效率。
- 支持最左前缀原则(见下),具备较强的索引复用能力。
- 可用于覆盖索引,避免回表,提高性能。
最左前缀原则:
查询语句中用到的字段必须从联合索引的最左边开始,连续匹配,才能使用索引。
例如,索引为 (a, b, c):
| 查询条件 | 能否使用索引? | 原因 |
| WHERE a = 1 | ✅ 是 | 匹配最左前缀 a |
| WHERE a = 1 AND b = 2 | ✅ 是 | 匹配 a, b |
| WHERE b = 2 AND a = 1 | ✅ 是 | 虽然顺序不同,但条件包含 a, b |
| WHERE b = 2 | ❌ 否 | 不满足最左字段 a,无法使用索引 |
| WHERE a = 1 AND c = 3 | ✅ 部分 | 匹配了 a,但跳过了 b,c 无法参与索引 |
| WHERE a LIKE '张%' | ✅ 是 | 字符串最左前缀匹配也可以用索引 |
字段顺序设计原则:
1. 最常出现在查询条件中的字段放在前面(提高索引利用率)。
2. 区分度高的字段放前面(能快速缩小范围)。
3. 尽量减少冗余索引:
- 如果有
(a, b)联合索引,通常不需要再建 (a)。 - 但如果经常单独用 b 查询,还需考虑是否加上
(b)索引。
4. 考虑是否用于覆盖索引(被查询的字段尽量全部包含在索引中)。
2.7. 索引下推
索引下推的定义:
索引遍历过程中,直接在索引内部判断条件是否满足,提前过滤掉无效记录,减少回表次数。
示例:
联合索引 (name, age),查询:
sql复制编辑
SELECT * FROM tuser WHERE name LIKE '张%' AND age=10 AND ismale=1;- 无索引下推:name 匹配后全部回表判断 age。
- 有索引下推:在索引中先判断 age,再决定是否回表。
- 回表次数显著减少,查询效率显著提升。