深度学习论文idea:多模态检索
🧀关注各大顶会的同学们都知道,今年多模态相关的主题可谓是火爆非常,有许多突破性成果被提出,比如最新的多模态检索增强框架MORE,生成性能猛超GPT-4!
🧀再比如多模态检索模型MARVEL,在所有基准上实现SOTA!可见相比传统单一模态检索,这种多模态检索更具优势,不仅能提供更全面、更准确的检索结果,也能帮助我们提升工作效率。
🧀目前多模态检索逐渐成为了研究焦点,因为它的全面性、准确性和灵活性在多个领域(比如图像检索、医疗诊断等)都很有用武之地,是个拥有广泛应用前景的热门方向。
🧀因此对论文er来说,这也是个很好的发文选择。为了帮助各位快速了解这个方向的最新动态,我整理好了10篇多模态检索今年最新的论文给各位作参考,代码基本都有。
我整理了一些时间序列【论文+代码】合集,需要的同学公人人人号【AI科研算法paper】发555自取
论文1
标题:
Wiki-LLaVA:HierarchicalRetrieval-Augmented Generation for Multimodal LLMs
Wiki-LLaVA:多模态LLMs的分层检索增强生成
方法:
-
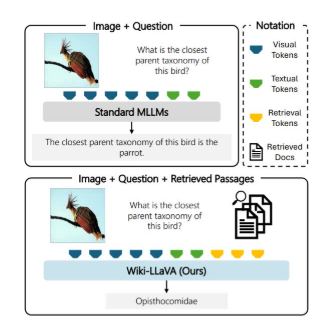
分层检索增强生成:提出了一种分层检索增强生成方法,通过检索外部知识源中的相关信息来增强多模态LLMs(MLLMs)的生成能力。
-
外部知识源集成:将外部知识源(如维基百科)集成到模型中,通过检索相关文档和段落来提供额外的上下文信息。
-
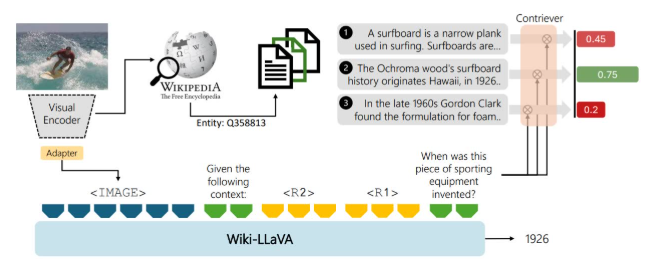
视觉编码器和检索模块:使用视觉编码器将图像编码为特征向量,并通过检索模块从知识源中检索与输入图像和问题相关的文档和段落。
-
多模态融合:将检索到的文档和段落与视觉特征和用户问题融合,作为MLLMs的输入,以生成更准确的答案
创新点:
-
分层检索机制:提出了分层检索机制,先检索相关文档,再从文档中检索相关段落,显著提高了检索的准确性和效率。
-
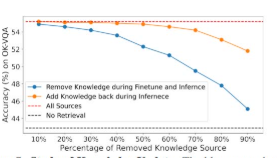
性能提升:在Encyclopedic-VQA和InfoSeek数据集上,与不使用外部知识源的模型相比,使用分层检索的Wiki-LLaVA模型在准确率上分别提高了13.8%和22.6%。
-
多模态融合:将视觉特征、检索到的文档和段落以及用户问题融合,为MLLMs提供了更丰富的上下文信息,提高了生成答案的质量。
-
扩展性:该方法可以扩展到其他多模态任务和数据集,为多模态LLMs的进一步发展提供了新的方向。
论文2
标题:
Advanced Embedding Techniques in Multimodal Retrieval Augmented Generation
多模态检索增强生成中的先进嵌入技术
方法:
-
多模态数据处理:处理包括图像、视频、音频和3D数据在内的多模态数据,通过检索增强生成(RAG)模型实现跨模态检索。
-
先进嵌入技术:使用先进的嵌入技术,如CLIP、Contriever等,将不同模态的数据嵌入到同一向量空间中,以便进行有效的检索。
-
检索增强生成:通过检索相关文档和段落,为生成模型提供额外的上下文信息,提高生成内容的质量和相关性。
-
多模态融合:将检索到的多模态数据与生成模型融合,生成更准确、更丰富的输出
创新点:
-
检索准确率提升:与现有基准相比,检索准确率提高了10%,达到85%。
-
检索效率提升:检索时间减少了40%,显著提高了实时应用的性能。
-
生成质量提升:BLEU和ROUGE分数分别提高了15%和12%,表明生成内容的质量和相关性显著提高。
-
多模态融合:通过将不同模态的数据嵌入到同一向量空间中,实现了有效的跨模态检索和生成。

论文3
标题:
Snap and Diagnose: An Advanced Multimodal Retrieval System for Identifying Plant Diseases in the Wild
Snap and Diagnose:用于识别野外植物疾病的先进多模态检索系统
方法:
-
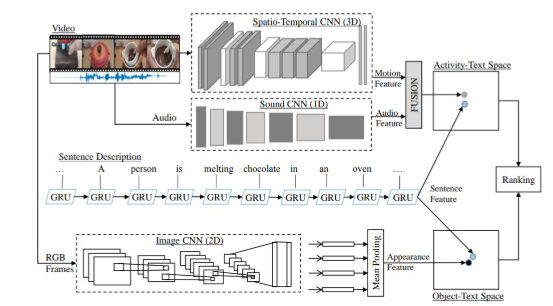
多模态检索系统:开发了一个多模态检索系统,支持基于图像或文本描述的植物疾病检索。
-
CLIP和MVPDR:使用CLIP和MVPDR技术提取图像和文本特征,并将它们嵌入到同一潜在空间中,以便进行跨模态检索。
-
PlantWild数据集:利用PlantWild数据集,包含超过18,000张图像和89个类别,提供丰富的植物疾病样本。
-
用户交互界面:提供了一个用户友好的交互界面,用户可以通过上传图像或输入文本描述来检索相关的植物疾病图像。
创新点:
-
检索准确率提升:与Zero-shot CLIP相比,Snap’n Diagnose在Top-1、Top-5、Top-10准确率和mAP上分别提高了26.4%、14.86%、13.29%和10.62%。
-
多模态融合:通过将图像和文本描述嵌入到同一潜在空间中,实现了有效的跨模态检索。
-
用户友好性:提供了一个用户友好的交互界面,简化了检索过程,使用户能够轻松地上传图像或输入文本描述。
-
数据集丰富性:利用丰富的PlantWild数据集,提供了多样化的植物疾病样本,提高了系统的准确性和实用性。
论文4
标题:
TheSurprisingEffectivenessofMultimodalLargeLanguage Models for Video Moment Retrieval
多模态大型语言模型在视频时刻检索中的惊人有效性
方法:
-
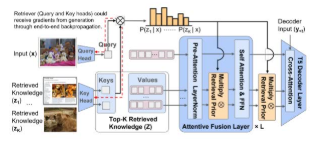
多模态大型语言模型(MLLMs):利用MLLMs进行视频时刻检索,通过生成与自然语言查询相关的视频时刻。
-
Mr. BLIP模型:提出了Mr. BLIP模型,将视频时刻检索任务转化为一个开放式的序列到序列问题,使用MLLMs生成相关的视频时刻。
-
多模态输入序列:设计了一个多模态输入序列,包括视频帧、时间戳、视频时长、查询文本和任务提示,以提供丰富的上下文信息。
-
参数高效微调:使用LoRA技术进行参数高效微调,只训练模型的一部分参数,显著减少了计算资源的需求。
创新点:
-
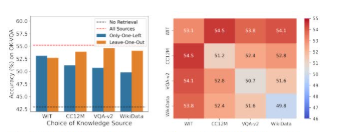
检索准确率提升:在Charades-STA、QVHighlights和ActivityNet Captions数据集上,Mr. BLIP模型分别在R1@0.5和R1@0.7指标上取得了新的最高性能,分别提高了10.84%、14.27%、15.21%、16.52%、13.32%和10.05%。
-
多模态融合:通过将视频帧、时间戳和查询文本嵌入到同一序列中,为MLLMs提供了丰富的上下文信息,提高了模型的检索能力。
-
参数高效微调:使用LoRA技术进行参数高效微调,只训练1900万参数,显著减少了计算资源的需求。
-
开放式的序列到序列问题:将视频时刻检索任务转化为一个开放式的序列到序列问题,使模型能够生成可变数量的相关时刻,提高了模型的灵活性和准确性。