TransMorph:用于无监督医学图像配准的变压器
1.简介
我们的小组之前已经展示了初步结果,即证明ViT和V-Net的桥梁在图像配准中提供了良好的性能。在这项工作中,我们扩展了初步工作,并研究了其他任务中的various Transformer模型。我们提出了一个混合Transformer-ConvNet框架TransMorph,用于3d医学图像配准。
在该方法中,SwinTransformer被用作编码器,以捕获输入移动图像和固定图像之间的空间对应关系。然后,ConvNet解码器将Transformer编码器提供的信息处理成密集的位移场。部署长跳过连接,以维持编码器和解码器阶段之间的定位信息流。我们还引入了TransMorph的微分同构变化,以确保平滑和保持拓扑的变形。此外,我们对TransMorph的参数进行了变分推理,得到了一个基于给定图像对预测配准不确定性的贝叶斯模型。实验结果的定性和定量评估证明了所提出方法的鲁棒性,并证实了Transformers对图像配准的有效性。
这项工作的主要贡献归纳如下:
Transformers的基础模型:本文介绍了使用Transformers进行图像配准的开创性工作。提出了一种新型的基于Transformer的神经网络TransMorph,用于仿射和可变形图像配准。
架构分析:本文中的实验表明,位置嵌入(按惯例是Transformer中常用的元素)对于提出的混合Transformer-ConvNet模型来说并不需要。其次,我们表明基于Transformer的模型比ConvNets具有更大的有效感受野。此外,我们证明了 TransMorph 能够促使配准损失景观(损失函数的分布情况)更加平坦。
微分同胚配准:我们证明,TransMorph可以轻松集成到两个现有框架中,作为配准主干以提供半微分同胚配准。
不确定性量化:本文还提供了TransMorph的Bayesian不确定性变体,该变体可产生Transformer不确定性和完美校准的外观不确定性估计。
最先进的结果:我们在两个脑MRI配准应用程序(患者间和图谱到患者配准)和XCAT到CT配准的新应用程序上广泛验证了所提出的配准模型,目的是创建一个解剖学变量XCAT体模群体。本研究中使用的数据集(包括公开可用的数据集IXI数据集)包含超过1000个用于训练和测试的图像对。所提出的模型进行了比较与各种配准方法,并表现出最先进的性能。采用八种配准方法作为基线,包括基于学习的方法和广泛使用的传统方法。四个最近提出的Transformer架构的性能从其他任务(例如,语义分割、分类等)还对图像配准任务进行了评估。
开源:我们为社区提供快速准确的可变形配准工具。源代码、预训练模型和我们预处理的IXI数据集可在https://bit.ly/37eJS6N上公开获取。
2.相关工作
2.1自我关注机制与Transformer
Transformer 利用了自注意力机制,通过 Query-Key-Value(QKV)模型来估计一个输入序列与另一个输入序列的相关性(Vaswani 等人,2017;Dosovitskiy 等人,2020)。输入序列通常来源于图像的展平块。假设 x 是定义在三维空间域上的图像体积(即 x∈RH×W×L)。图像首先被划分为 N 个展平的三维块 xp∈RN×P3,其中 (H,W,L) 是原始图像的尺寸,(P,P,P) 是每个图像块的尺寸,且 N=HWL/P3。然后,将一个可学习的线性嵌入 E 应用于 xp,将每个块投影到一个 D×1 的向量表示中:
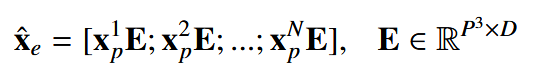
其中,维度 D 是一个用户定义的超参数。然后,为了保留块的位置信息,将一个可学习的位置嵌入 Epos 添加到 x^e 中,即 xe=x^e+Epos,其中 Epos∈RN×D。这些向量表示通常被称为“token”,随后被用作自注意力计算的输入。
-
位置嵌入 Epos 是一个可学习的参数矩阵,其形状也是 N×D。它的作用是为每个图像块提供一个唯一的位置标识。
-
在训练过程中,模型会自动学习 Epos 的值,以便在特征表示中保留每个图像块的位置信息。例如,如果两个图像块的特征非常相似,但它们在图像中的位置不同,位置嵌入可以帮助模型区分它们。
-
为什么需要位置嵌入?
在处理图像或序列数据时,位置信息是非常重要的。例如,在图像配准任务中,模型需要理解图像块之间的空间关系,以便正确地对齐图像。如果没有位置嵌入,模型可能会忽略图像块的空间位置,从而导致配准不准确。
通过添加位置嵌入,模型可以更好地理解图像块之间的相对位置关系,从而提高配准的准确性。
2.2贝叶斯深度学习
贝叶斯深度学习通过估计预测不确定性,为理解深度神经网络中的不确定性提供了一个现实的范式(Gal and Ghahramani 2016)。神经网络的参数所引起的不确定性被称为认识不确定性(epistemic uncertainty),它可以通过对网络参数施加先验分布(例如高斯先验分布:W∼N(0,I))来建模,并尝试捕捉这些权重在给定数据下的变化。
这一领域的最新努力包括贝叶斯后验传播(Blundell et al. 2015)、假设高斯先验分布的均值场变分推断(Tölle et al. 2021)、随机批量归一化(Atanov et al. 2018)以及蒙特卡洛(MC)Dropout(Gal and Ghahramani 2016;Kendall and Gal 2017)。贝叶斯深度学习在医学成像中的应用包括图像去噪(Tölle et al. 2021;Laves et al. 2020b)和图像分割(DeVries and Taylor 2018;Baumgartner et al. 2019;Mehrtash et al. 2020)。在基于深度学习的图像配准中,大多数方法仅提供一个单一的、确定性的未知几何变换解。了解认识不确定性有助于确定配准结果的可信度以及输入数据是否适合神经网络。
一般来说,可以通过深度学习模型的认识不确定性来模拟两种类型的配准不确定性:变换不确定性(transformation uncertainty) 和 外观不确定性(appearance uncertainty)(Luo et al. 2019;Xu et al. 2022)。变换不确定性衡量空间变换(即变形)的局部模糊性,而外观不确定性量化了配准体素的强度值或配准器官体积的不确定性。变换不确定性估计可用于不确定性加权配准(Simpson et al. 2011;Kybic 2009)、手术治疗计划,或直接用于定性评估(Yang et al. 2017b)。外观不确定性可以转化为放射治疗或放射性药物治疗中的剂量不确定性(Risholm et al. 2011;Vickress et al. 2017;Chetty and Rosu-Bubulac 2019;Gear et al. 2018)。这些配准不确定性估计还可以用于评估手术风险,从而做出更明智的临床决策(Luo et al. 2019)。Cui等人(Cui et al. 2021)和Yang等人(Yang et al. 2017b)在配准网络设计中引入了MC Dropout层,这使得网络可以通过采样多个变形场预测来估计变换不确定性。本文提出的图像配准框架扩展了这些想法。特别是,本文提出了一种新的配准框架,该框架利用Transformer进行网络设计。我们证明了该框架可以很容易地适应几种现有技术以实现图像配准的微分同胚性,并纳入贝叶斯深度学习以估计配准不确定性。
-
什么是MC Dropout层?
MC Dropout(Monte Carlo Dropout)是一种贝叶斯深度学习方法,用于估计神经网络的不确定性。它通过在训练和推理阶段随机丢弃部分神经元,从而模拟模型参数的不确定性。MC Dropout的核心思想是利用Dropout的随机性来近似贝叶斯神经网络的后验分布,从而为模型的预测提供不确定性估计。
-
MC Dropout在推理阶段也保留Dropout操作,而不是简单地保留所有神经元。
-
通过多次前向传播(Monte Carlo采样),每次前向传播时随机丢弃不同的神经元,从而生成多个预测结果。
-
这些预测结果的分布可以用来估计模型的不确定性。
3.方法
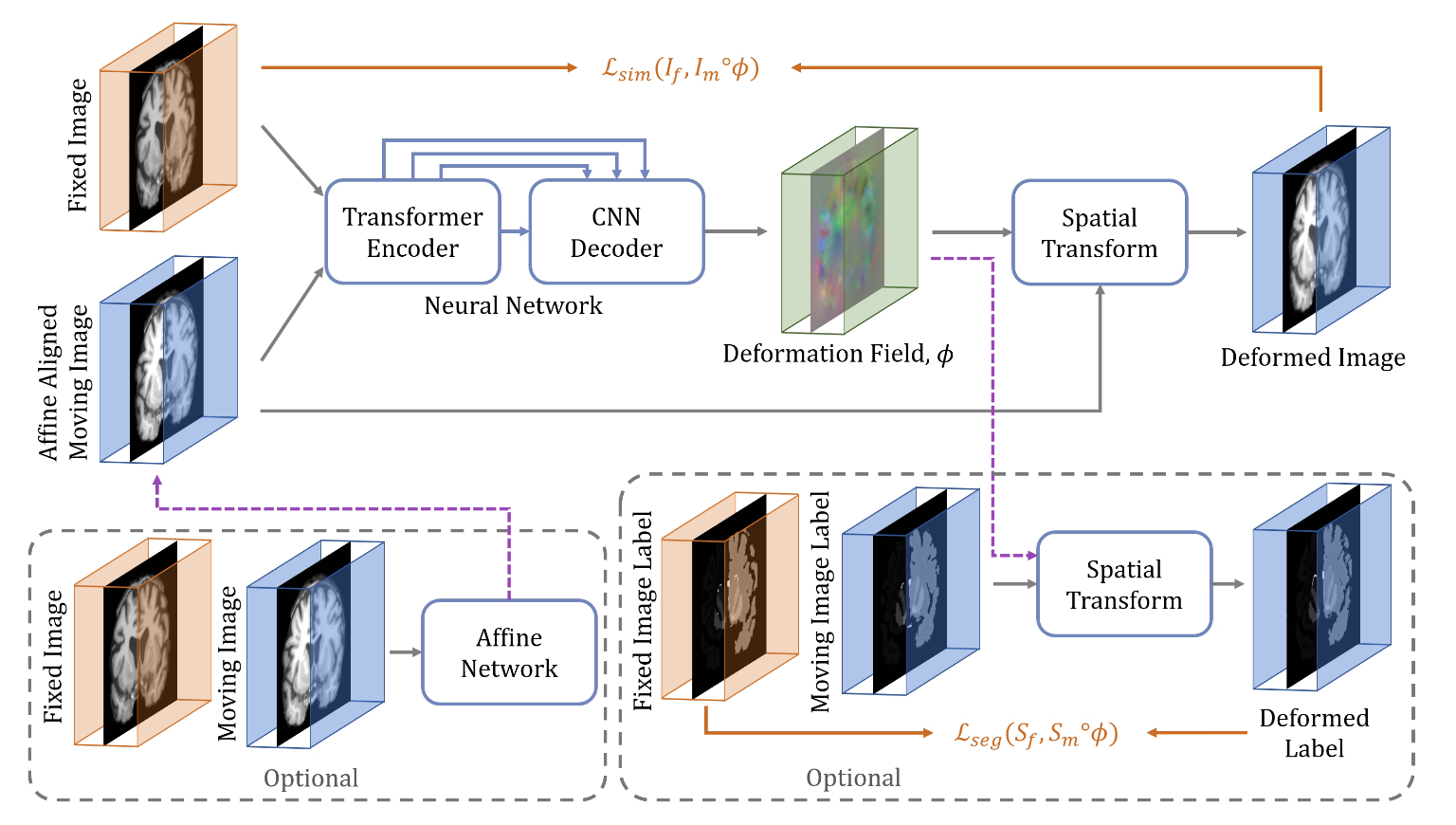
3.1仿射转换网络
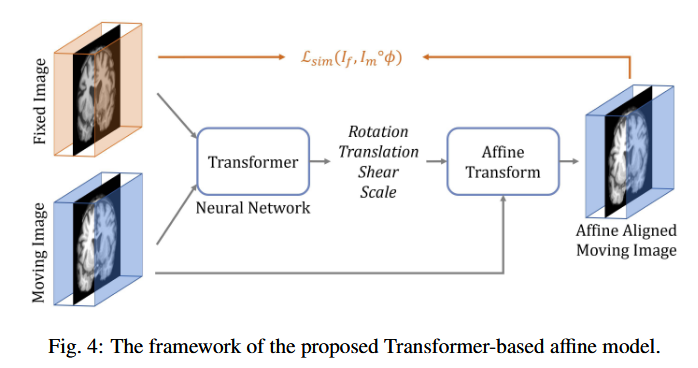
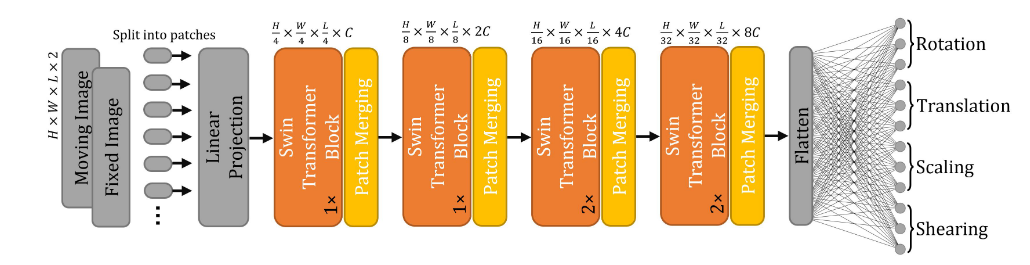
仿射变换通常被用作图像配准的初始阶段,因为它有助于优化以下更复杂的MIDI过程(de Vos等人,2019)。仿射网络全局检查一对运动图像和固定图像,并产生一组将运动图像与固定图像对齐的变换参数。这里,提出的基于Transformer的仿射网络的架构是修改后的Swin Transformer(Liu等人,2021 a),其采用两个3D体积作为输入(即,I f和I m)并生成12个仿射参数:三个旋转角、三个平移参数、三个缩放参数和三个剪切参数。附录中的图A.19显示了体系结构的详细信息和可视化。由于仿射配准相对简单,我们减少了原始Swin Transformer中的参数数量。接下来的部分将介绍Transformer的架构和参数设置的具体细节
3.2变形配准网络
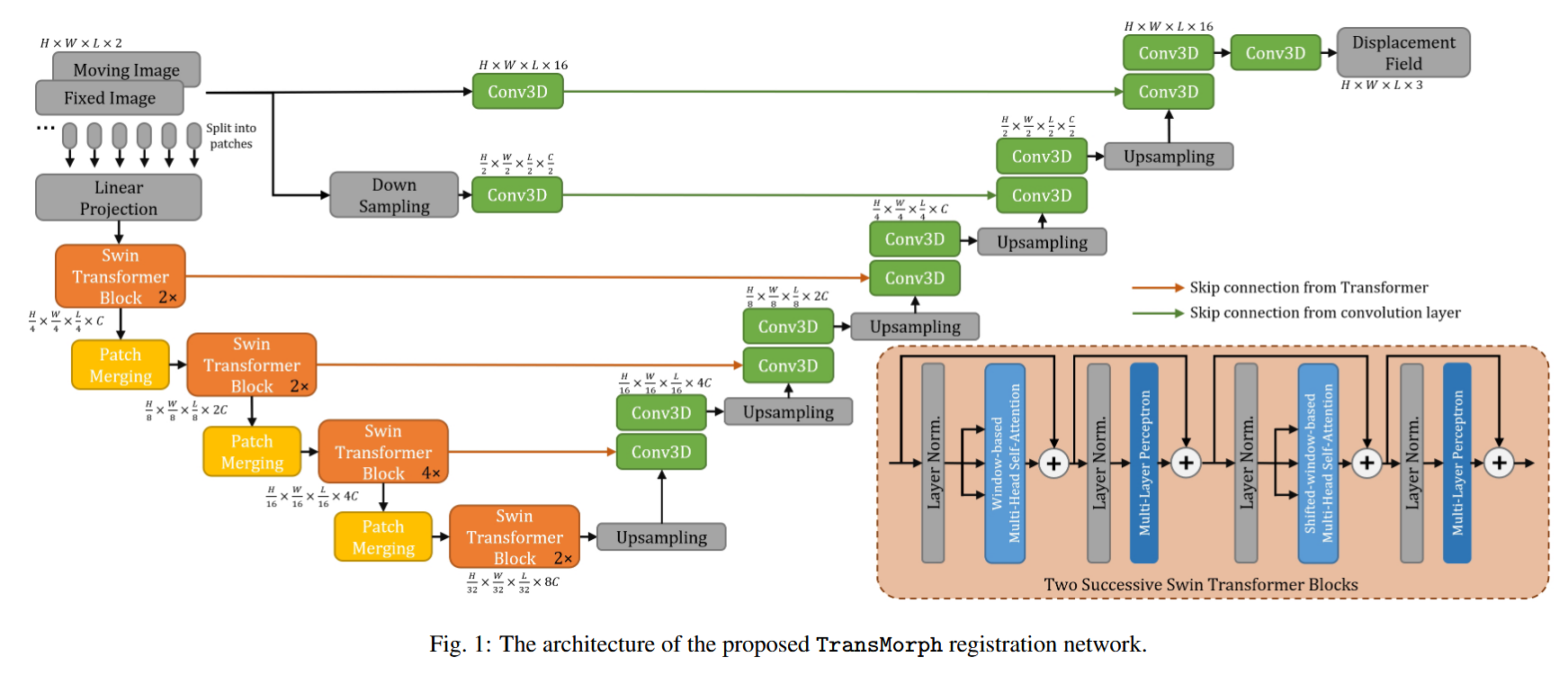
图1展示了所提出的TransMorph网络架构。网络的编码器首先将输入的活动图像和固定图像分割成非重叠的3D块,每个块的大小为 2×P×P×P,其中 P 通常设置为4(Dosovitskiy et al. 2020; Liu et al. 2021a; Dong et al. 2021)。我们将第 i 个块表示为 xip,其中 i∈{1,…,N},N=P/H×P/W×P/L 是块的总数。每个块被展平并被视为一个“标记”(token),然后通过线性投影层将每个标记投影到任意维度的特征表示(记为 C):
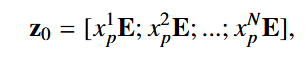
其中 E∈R2P^3×C 表示线性投影,输出 z0 的维度为 N×C。由于线性投影操作在图像块上进行,并不保留标记相对于整个图像的位置信息,以往的基于Transformer的模型通常会在线性投影后添加位置嵌入(positional embedding),以将位置信息整合到标记中,即 z0+Epos(Vaswani et al. 2017; Dosovitskiy et al. 2020; Liu et al. 2021a; Dong et al. 2021)。然而,对于像素级任务(如图像配准),网络通常包含一个解码器,用于生成与输入或目标图像分辨率相同的密集预测。通过比较输出与目标图像的损失函数来强制执行输出图像中体素的空间对应关系。输出与目标之间的任何空间不匹配都会对损失做出贡献,并通过反向传播反馈到Transformer编码器中。Transformer应该因此能够隐式地捕获标记的位置信息。在本工作中,我们观察到,正如将在第6.1.2节中展示的那样,位置嵌入对于图像配准并非必要,它只是为网络增加了额外的参数,而没有提高性能。
在经过线性投影层后,多个连续阶段的块合并和Swin Transformer块(Liu et al. 2021a)被应用于tokens z0。
块合并操作用于降低空间分辨率并增加特征的维度。
Swin Transformer块输出与输入相同数量的tokens,而块合并层将每组 2×2×2 邻近tokens的特征进行连接,从而将tokens数量减少了 2×2×2=8 倍(例如,从 H×W×L×C 减少到 H/2×W/2×L/2×8C)。然后,对8C维的连接特征应用一个线性层,以产生每个维度为2C的特征。
经过编码器中的四个Swin Transformer块阶段和三个块合并阶段(即图1中的橙色框)后,编码器最后一阶段的输出维度为 H/32×W/32×L/32×8C。
解码器由具有3×3卷积核的连续上采样和卷积层组成。解码阶段的每个上采样特征图都通过跳跃连接(skip connections)与编码路径中的相应特征图进行连接,然后跟随两个连续的卷积层。如图1所示,由于块操作的性质,Transformer编码器只能提供分辨率高达 H/P×W/P×L/P 的特征图(用橙色箭头表示)。因此,Transformer可能在提供高分辨率特征图和聚合低层局部信息方面存在不足(Raghu et al. 2021)。为了解决这一不足,我们使用原始图像对和下采样图像对作为输入的两个卷积层,以捕获局部信息并生成高分辨率特征图。
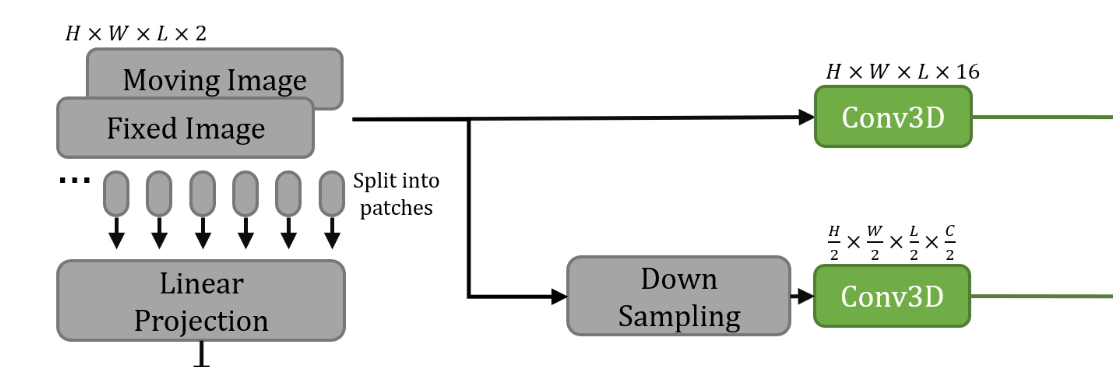
这些层的输出与解码器中的特征图进行连接,以产生变形场。通过应用十六个3×3卷积层生成输出变形场 ϕ。除了最后一层卷积层外,每层卷积层后都跟随一个Leaky ReLU(Maas et al. 2013)激活函数。最后,通过空间变换函数(Jaderberg et al. 2015)将变形场 ϕ(或位移场 u)应用于活动图像 Im,以实现非线性变形。在接下来的小节中,我们将详细讨论Swin Transformer块、空间变换函数和损失函数。
3.2.1 3D Swin Transformer块
Swin Transformer 最重要的组件之一(除了分块层之外)是基于移位窗口的自注意力机制。与 ViT(Dosovitskiy 等人,2020)不同,后者在自注意力模块的每一步中计算一个标记与其他所有标记之间的关系,而 Swin Transformer 在原始和低分辨率特征图的均匀划分的非重叠局部窗口内计算自注意力(如图 5(a) 所示)。划分的非重叠局部窗口内计算自注意力(如图 5(a) 所示)。与原始 Swin Transformer 相比,本研究使用矩形长方体窗口来适应非方形图像,每个窗口的形状为 Mx×My×Mz.
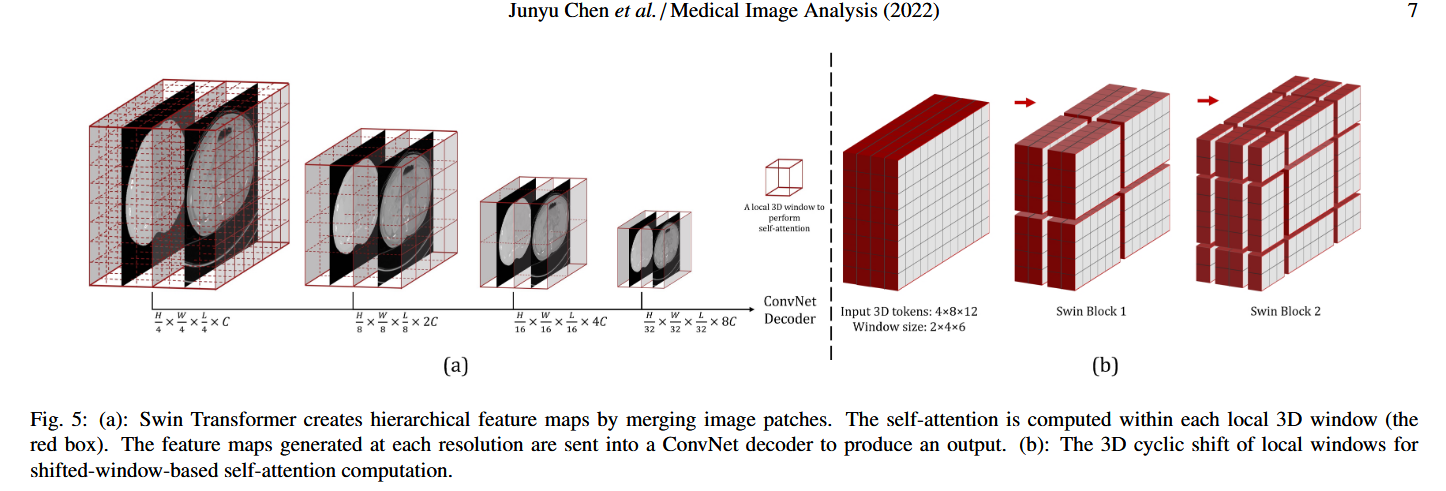
在每个分辨率下,第一个 Swin Transformer 块采用常规的窗口划分方法,从左上角的体素开始,将特征图均匀划分为大小为 Mx×My×Mz 的非重叠窗口。然后在每个窗口内局部计算自注意力。为了引入相邻窗口之间的连接,Swin Transformer 使用移位窗口设计:在连续的 Swin Transformer 块中,窗口配置会相对于前一个块发生偏移,通过将前一个块的窗口在每个方向上偏移 (⌊Mx/2⌋×⌊My/2⌋×⌊Mz/2⌋) 个体素来实现。例如,如图 5(b) 所示,输入特征图的大小为 4×8×12,窗口大小为 2×4×6,则在第一个 Swin Transformer 块中,特征图被均匀划分为 2×2×2=8 个窗口(图 5(b) 中的“Swin Block 1”)。然后,在下一个块中,窗口被偏移 (⌊22⌋×⌊24⌋×⌊26⌋)=(1×2×3),窗口数量变为 3×3×3=27。我们将原始的 2D 高效批量计算方法(即循环移位)(Liu 等人,2021a,b)扩展到 3D,并将其应用于这 27 个移位窗口,保持最终用于注意力计算的窗口数量为 8。基于窗口的注意力机制,两个连续的 Swin Transformer 块可以表示为:
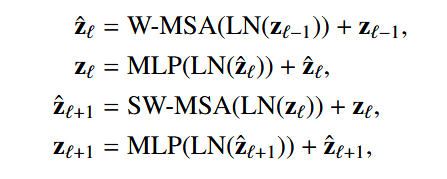
其中,W-MSA 和 SW-MSA 分别表示基于窗口的多头自注意力模块和基于移位窗口的多头自注意力模块;MLP 表示多层感知机模块(Vaswani 等人,2017);z^ℓ 和 zℓ 分别表示块 ℓ 的 (S)W-MSA 和 MLP 模块的输出特征。
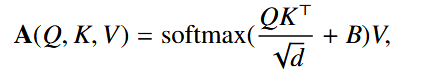
我们将在第 6.1.2 节中说明,对于所提出的网络,位置偏置 B 是不必要的,它只是增加了额外的参数,而没有提高配准性能。
3.2.2 损失函数
图像相似度度量
均方误差(Mean Squared Error, MSE)
局部归一化交叉相关系数(Local Normalized Cross-Correlation, LNCC)
变形场正则化
1. 扩散正则化(Balakrishnan 等人,2019):
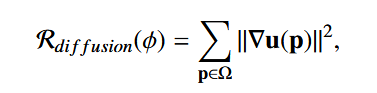
其中,u(p) 是位移场 u 的空间梯度。空间梯度通过前向差分近似计算,即
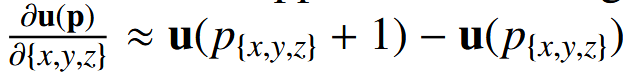
2. 弯曲能量(Rueckert 等人,1999):
惩罚过大的弯曲变形,因此对于腹部器官配准可能很有帮助。弯曲能量作用于位移场 u 的二阶导数,定义为:
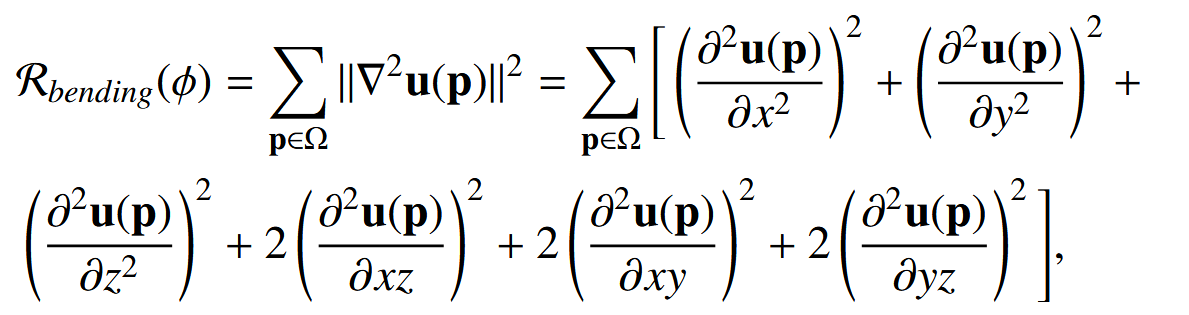
其中,导数的计算同样采用前面提到的前向差分方法。
辅助分割信息
在图像配准领域,通常使用 Dice 系数(Dice,1945)来量化配准性能。因此,我们直接最小化了分割结构 sf 和 sm∘φ 之间的 Dice 损失(Milletari 等人,2016),其中 k 表示第 k 个结构/器官:
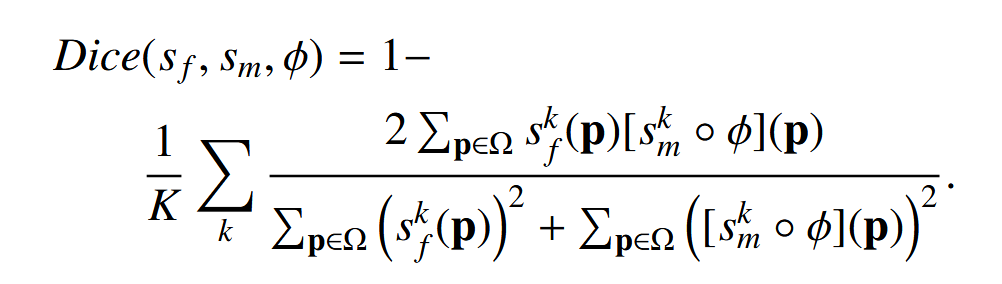 为了允许 Dice 损失的反向传播,我们采用了类似于 Balakrishnan 等人(2019)中描述的方法,将 sf 和 sm 设计为具有 K 个通道的图像体积(即结构或器官的数量),每个通道包含定义特定结构/器官分割的二进制掩模。然后,通过使用线性插值对 K 通道的 sm 进行变形,计算 sm∘φ,从而使 Lseg 的梯度能够反向传播到网络中。
为了允许 Dice 损失的反向传播,我们采用了类似于 Balakrishnan 等人(2019)中描述的方法,将 sf 和 sm 设计为具有 K 个通道的图像体积(即结构或器官的数量),每个通道包含定义特定结构/器官分割的二进制掩模。然后,通过使用线性插值对 K 通道的 sm 进行变形,计算 sm∘φ,从而使 Lseg 的梯度能够反向传播到网络中。
3.3 概率和B样条变体
在本节中,我们展示了通过简单地更改解码器,TransMorph 可以与先前研究中的概念结合使用,以确保可微分的变形,使得得到的可变形映射是连续的、可微分的,并且保持拓扑结构。通过缩放与平方方法(如第2.1.2节所述)和固定速度场表示(Arsigny 等人,2006)实现了可微分配准。我们采用了两个现有的可微分模型,VoxelMorph-diff(Dalca 等人,2019)和MIDIR(Qiu 等人,2021),并将它们作为所提出的TransMorph可微分变体的基础,分别命名为TransMorph-diff(附录H节)和TransMorph-bspl(附录I节)。这两种变体的架构如图6所示。
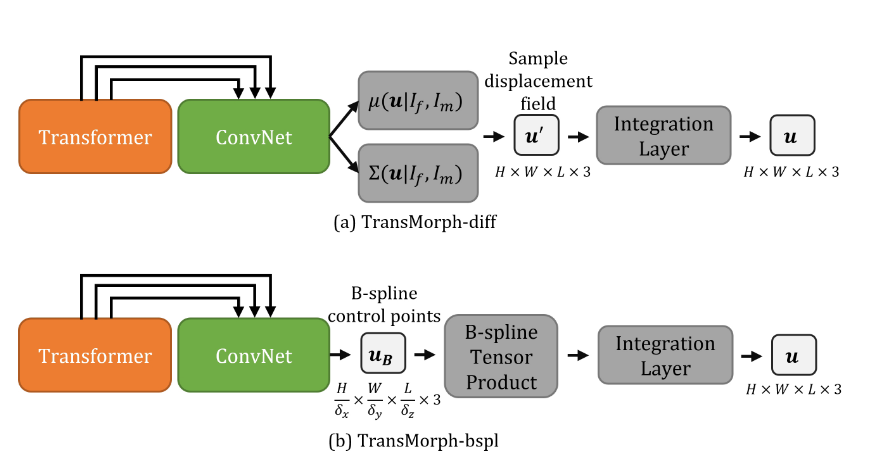
TransMorph-diff 使用与VoxelMorph-diff(Dalca 等人,2019)相同的损失函数进行训练:
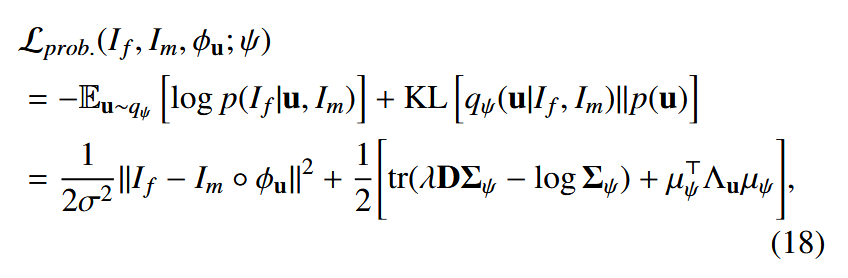
当有解剖标签图可用时:
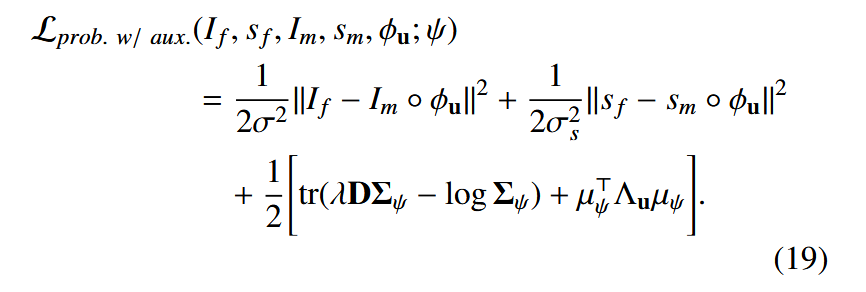
-
TransMorph-diff
-
需要精确的拓扑保持:TransMorph-diff 更适合需要精确保持拓扑结构的应用场景,例如在涉及复杂解剖结构的医学图像配准中。
-
处理不确定性:由于其概率模型,TransMorph-diff 在处理变形场的不确定性方面表现更好,适用于需要评估配准不确定性的场景。
-
-
TransMorph-bspl
-
平滑变形:TransMorph-bspl 更适合需要生成平滑变形的应用场景,例如在处理图像配准结果需要高度平滑的场合。
-
多尺度建模:B 样条参数化使得 TransMorph-bspl 在多尺度建模方面具有优势,能够更好地处理不同尺度的变形。
-
3.4 Bayesian不确定性变体
在本节中,我们将提出的 TransMorph 扩展为贝叶斯神经网络(Bayesian Neural Network, BNN),使用变分推断框架结合蒙特卡洛(Monte Carlo)Dropout(Gal 和 Ghahramani,2016)。我们称得到的模型为 TransMorph-Bayes。在该模型中,Dropout 层被插入到 TransMorph 架构的 Transformer 编码器中,但不插入到 ConvNet 解码器中,以避免对网络参数施加过多的正则化,从而降低性能。我们在 MLPs(多层感知机)的每个全连接层之后以及每次自注意力计算之后添加了 Dropout 层。这些位置是 Transformer 训练中通常使用 Dropout 层的地方。我们将 Dropout 概率 p 设置为 0.15,以进一步避免网络对权重施加过多的正则化。变形和外观的不确定性可以通过预测均值(即方差)的变异性来估计,其中变形场和变形图像的预测均值可以通过蒙特卡洛积分(Gal 和 Ghahramani,2016)来估计:
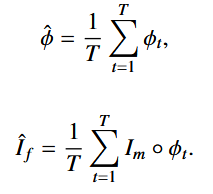
这相当于在推理过程中对网络进行 T 次前向传播的输出进行平均,其中 φt 表示第 t 次前向传播产生的变形场。变形和外观的不确定性可以通过变形场和变形图像的预测方差来估计,分别为:
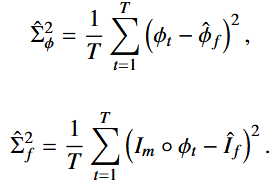
3.4.1 外观不确定性的校准
理想的不确定性估计应与配准结果的不准确性密切相关,即高不确定性值应表示较大的配准误差,反之亦然。否则,医生/外科医生可能会被错误的配准不确定性估计误导,对配准结果产生不应有的信心,从而导致严重后果(Luo 等人,2019;Risholm 等人,2013,2011)。当预测的不确定性值与预期模型误差紧密对应时,不确定性估计被认为是校准良好的(Laves 等人,2019;Levi 等人,2019)。在理想情况下,估计的配准不确定性应完全反映实际配准误差。例如,如果网络生成的一批配准图像的预测方差为 0.5,则平方误差的期望也应为 0.5。因此,如果用均方误差(MSE)量化预期模型误差,则外观不确定性的完美校准可以定义为以下(Guo 等人,2017;Levi 等人,2019;Laves 等人,2020c):
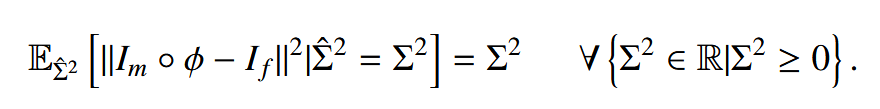
在传统的贝叶斯神经网络范式中,不确定性估计是从预测方差 Σ^2 相对于预测均值 I^f推导出来的(如方程 23)。然而,可以证明,由于过拟合训练数据集,这种预测方差可能会被校准错误(如附录 B 所示)。因此,基于 Σ^2 的不确定性估计可能有偏差。这种偏差必须在诸如图像去噪或分类等应用中得到纠正(Laves 等人,2019;Guo 等人,2017;Kuleshov 等人,2018;Phan 等人,2018;Laves 等人,2020c,a),以便使不确定性值更接近预期误差。在图像配准中,然而,预期的外观误差即使在测试时也可以计算,因为目标图像始终是已知的。因此,无需额外努力即可实现完美校准的外观不确定性量化。在这里,我们提出用目标图像 If 替换预测均值 I^f(如方程 23)。然后,外观不确定性等同于预期误差:
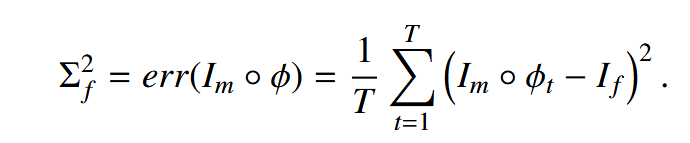
在本文后面部分,将展示两种外观不确定性估计方法(即 Σf^2 和 Σf2)的比较。
4.实验
4.1 数据集和预处理
使用包括1000多个图像对的三个数据集来彻底验证所提出的方法。以下部分描述了每个数据集的详细信息。
4.1.1 患者间脑部MRI配准
对于患者间脑部MR图像配准数据集,我们使用了在约翰·霍普金斯大学采集的260张T1加权脑部MRI图像的数据集。这些图像是匿名的,并在IRS批准下获取的。该数据集被分成182、26和52(7:1:2)卷,用于训练、验证和测试集。每个图像体积被用作运动图像,通过将其随机匹配到集合中的另外两个体积来形成两个图像对(即,固定图像)。然后,将运动图像和固定图像倒置以形成另外两个图像对,从而产生四个I f和IM的配准对。最终数据包括768、104和208个图像对,分别用于训练、验证和测试。FreeSurfer(Fischl 2012)用于执行结构脑部MRI的标准预处理程序,包括头骨剥除、重新采样和仿射变换。预处理后的图像体积均被裁剪为160 x 192 x 224的大小。使用FreeSurfer获得包括29个解剖结构的标签地图,以评估配准性能。
4.1.2 图谱到患者脑部 MRI 配准(IXI)
我们使用一个公开可用的数据集来评估所提出模型在图谱到患者脑部 MRI 配准任务中的表现。总共使用了576张来自信息提取图像(IXI)数据库的T1加权脑部 MRI 图像作为固定图像。活动图像为该任务是一个从(Kim 等人,2021)获得的图谱脑部 MRI。数据集被分为403、58和115(按7:1:2的比例)个体积,分别用于训练、验证和测试集。使用 FreeSurfer 对 MRI 体积进行预处理。我们对 IXI 数据集应用了与前一个数据集相同的预处理程序。所有图像体积均被裁剪为160×192×224的大小。使用29个解剖结构的标签图来评估配准性能。
4.1.3 Learn2Reg OASIS 脑部 MRI 配准
我们还在一个公开的配准挑战赛——OASIS(Marcus 等人,2007;Hoopes 等人,2021)中评估了 TransMorph,该挑战赛来自2021年 Learn2Reg 挑战赛(Hering 等人,2021)。这个数据集包含451张脑部T2 MRI图像,其中394张用于训练,19张用于验证,38张用于测试。使用 FreeSurfer(Fischl,2012)对脑部 MRI 图像进行预处理,提供了35个解剖结构的标签图用于评估。
4.1.4 XCAT 到 CT 配准
计算机化体模在医学成像领域被广泛用于算法优化和成像系统验证(Christoffersen 等人,2013;Chen 等人,2019;Zhang 等人,2017)。四维扩展心脏-躯干(XCAT)体模(Segars 等人,2010)是基于可见人体项目数据的解剖图像开发的。尽管当前的 XCAT 体模可以模拟器官和体模的解剖变化,但它无法完全复制人类的解剖变化。因此,XCAT 到 CT 配准(可以被视为图谱到图像配准)已成为创建解剖变化体模的关键方法(Chen 等人,2020;Fu 等人,2021;Segars 等人,2013)。本研究使用了来自(Segars 等人,2013)的 CT 数据集,该数据集包含50张非对比度胸部-腹部-盆腔(CAP)CT 扫描,这些扫描是杜克大学成像数据库的一部分。在每张患者的 CT 扫描中,选择了器官和结构进行手动分割。所分割的结构包括:身体轮廓、骨骼结构、肺部、心脏、肝脏、脾脏、肾脏、胃、胰腺、大肠、前列腺、膀胱、胆囊和甲状腺。手动分割由几位医学生完成,随后由杜克大学的一位经验丰富的放射科医师进行校正。CT 体积的体素大小范围从0.625×0.625×5mm 到0.926×0.926×5mm。我们使用三线性插值将所有体积重新采样为相同的体素间距2.5×2.5×5mm。所有体积均被裁剪并填充为160×160×160体素的大小。强度值首先被裁剪到[-1000, 700] Hounsfield 单位范围内,然后归一化到[0, 1]范围内。使用120 keV 下的材料组成和衰减系数生成 XCAT 衰减图,分辨率为1.1×1.1×1.1mm。然后对 XCAT 衰减图进行重新采样、裁剪和填充,使最终体积与 CT 体积大小匹配。XCAT 衰减图的强度值也被归一化到[0, 1]范围内。使用所提出的仿射网络对 XCAT 和 CT 图像进行刚性配准。数据集被分为35、5和10(按7:1:2的比例)个体积,分别用于训练、验证和测试。我们在五十个体积上进行了五折交叉验证,总共得到50个体积用于测试。
4.2. Baseline Methods
为了评估 TransMorph 的性能,我们将 TransMorph 与多种已证明具有优异配准性能的配准方法进行了比较。比较包括传统的非深度学习方法和基于深度学习的方法。以下是这些方法及其超参数设置的详细描述:
传统非深度学习方法
-
SyN(Symmetric Normalization)(Avants 等人,2008):SyN 是一种基于梯度的配准方法,适用于非刚性配准。对于患者间和图谱到患者的脑部 MRI 配准任务,我们使用均方差(Mean Squared Difference, MSQ)作为目标函数,并采用默认的高斯平滑参数 3,以及三个尺度,每个尺度分别进行 180、80 和 40 次迭代。对于 XCAT 到 CT 配准,我们使用互相关(Cross-Correlation, CC)作为目标函数,高斯平滑参数为 5,三个尺度分别进行 160、100 和 40 次迭代。
-
NiftyReg(Modat 等人,2010):NiftyReg 是一种基于优化的配准工具,适用于刚性和非刚性配准。对于所有配准任务,我们使用平方和差异(Sum of Squared Differences, SSD)作为目标函数,并采用弯曲能量(Bending Energy)作为正则化项。对于患者间脑部 MRI 配准,我们经验性地将正则化权重设置为 0.0002,并在三个尺度上各进行 300 次迭代。对于图谱到患者的脑部 MRI 配准,正则化权重设置为 0.0006,并在三个尺度上各进行 500 次迭代。对于 XCAT 到 CT 配准,正则化权重设置为 0.0005,并在五个尺度上各进行 500 次迭代。
-
deedsBCV(Heinrich 等人,2015):deedsBCV 是一种基于块匹配的配准方法,适用于非刚性配准。对于患者间和图谱到患者的脑部 MRI 配准,我们使用自相似性上下文(Self-Similarity Context, SSC)作为目标函数,并采用推荐的神经影像学参数设置,其中网格间距、搜索半径和量化步长分别设置为 6×5×4×3×2、6×5×4×3×2 和 5×4×3×2×1。对于 XCAT 到 CT 配准,我们使用腹部 CT 配准的默认参数设置,其中网格间距、搜索半径和量化步长分别为 8×7×6×5×4、8×7×6×5×4 和 5×4×3×2×1。
-
LDDMM(Large Deformation Diffeomorphic Metric Mapping)(Beg 等人,2005):LDDMM 是一种基于优化的配准方法,适用于可微分变形配准。对于所有配准任务,我们使用均方误差(Mean Squared Error, MSE)作为目标函数。对于患者间和图谱到患者的脑部 MRI 配准,我们使用平滑核大小为 5、平滑核幂为 2、匹配项系数为 4、正则化项系数为 10,并进行 500 次迭代。对于 XCAT 到 CT 配准,我们使用相同的平滑核大小、核幂、匹配项系数和迭代次数,但正则化项系数经验性地设置为 3。
基于深度学习的方法
-
VoxelMorph(Balakrishnan 等人,2018, 2019):VoxelMorph 是一种基于深度学习的配准方法,适用于非刚性配准。我们使用了两个变体,VoxelMorph-1 和 VoxelMorph-2,其中 VoxelMorph-2 的卷积滤波器数量是 VoxelMorph-1 的两倍。对于患者间和图谱到患者的脑部 MRI 配准,我们分别将正则化超参数 λ 设置为 0.02 和 1,这些值在 Balakrishnan 等人(2019)中被证明是最佳值。对于 XCAT 到 CT 配准,我们将 λ 设置为 1。
-
VoxelMorph-diff(Dalca 等人,2019):VoxelMorph-diff 是 VoxelMorph 的可微分变体,适用于可微分变形配准。对于患者间和图谱到患者的脑部 MRI 配准任务,我们使用概率损失函数 Lprob.(如方程 18),其中 σ 设置为 0.01,λ 设置为 20。对于 XCAT 到 CT 配准,我们使用带辅助信息的概率损失函数 Lprob w/aux(如方程 19),其中 σ=σs=0.01 和 λ=20。
-
CycleMorph(Kim 等人,2021):CycleMorph 是一种基于循环一致性的配准方法,适用于非刚性配准。在 CycleMorph 中,超参数 α、β 和 λ 分别对应循环损失、恒等损失和变形场正则化的权重。对于患者间脑部 MRI 配准,我们分别将 α、β 和 λ 设置为 0.1、0.5 和 0.02。对于图谱到患者的脑部 MRI 配准,我们分别将 α、β 和 λ 设置为 0.1、0.5 和 1。这些值是 Kim 等人(2021)中推荐的神经影像学最佳值。对于 XCAT 到 CT 配准,我们通过添加 Dice 损失(权重为 1)来修改 CycleMorph,以在训练过程中引入器官分割信息,并将 α 设置为 0.1,β 设置为 1。我们观察到,Kim 等人(2021)中建议的 λ 值 1 在我们的应用中会导致过度平滑的变形场。因此,我们将 λ 的值降低到 0.1。
-
MIDIR(Multi-scale Intensity- and Gradient-based Diffeomorphic Image Registration)(Qiu 等人,2021):MIDIR 是一种基于多尺度强度和梯度的可微分配准方法。我们使用与 VoxelMorph 相同的损失函数和 λ 值。此外,我们将 B 样条变换的控制点间距 δ 设置为 2,这在 Qiu 等人(2021)中被证明是最佳值。
此外,为了评估所提出的基于 Swin Transformer 的网络架构,我们将性能与在其他应用(如图像分割、目标检测等)中实现最佳性能的现有 Transformer 基网络进行了比较。我们将这些模型进行了调整,使其适用于图像配准。它们被修改为生成三维变形场,以对给定的活动图像进行变形。需要注意的是,这些方法与 VoxelMorph 的唯一区别是网络架构,空间变换函数、损失函数和网络训练过程保持不变。第一个到第三个模型使用了混合的 Transformer-ConvNet 架构(即 ViT-V-Net、PVT 和 CoTr),而最后一个模型使用了纯 Transformer 基架构(即 nnFormer)。它们的网络超参数设置如下:
-
ViT-V-Net(Chen 等人,2021a):该配准网络基于 ViT(Dosovitskiy 等人,2020)开发。我们应用了 Chen 等人(2021a)中建议的默认网络超参数设置。
-
PVT(Pyramid Vision Transformer)(Wang 等人,2021c):我们应用了默认设置,但将嵌入维度设置为 {20, 40, 200, 320},头的数量设置为 {2, 4, 8, 16},并将深度增加到 {3, 10, 60, 3},以实现与 TransMorph 相当的参数数量。
-
CoTr(Collaborative Transformers)(Xie 等人,2021):我们使用了所有配准任务的默认网络设置。
-
nnFormer(Zhou 等人,2021):由于 nnFormer 也是基于 Swin Transformer 开发的,我们应用了与 TransMorph 相同的 Transformer 超参数值,以进行公平比较。
ViT-V-Net https://bit.ly/3bWDynR
PVT https://github.com/whai362/PVT
CoTr https://github.com/YtongXie/CoTr
nnFormer https://github.com/282857341/nnFormer
4.3.实现细节
TransMorph 使用 PyTorch(Paszke 等人,2019)在一台配备 NVIDIA TITAN RTX GPU 和 NVIDIA RTX 3090 GPU 的个人电脑上实现。所有模型均训练了 500 个周期,使用 Adam 优化算法,学习率为 1×10−4,批量大小为 1。在训练过程中,脑部 MRI 数据集通过随机方向的翻转进行了数据增强,而 CT 数据集则未应用任何数据增强。由于图像体积的大小限制,Swin Transformer 中的窗口大小(即 {Mx,My,Mz})在脑部 MRI 配准中设置为 {5,6,7},在 XCAT 到 CT 配准中设置为 {5,5,5}。TransMorph 的 Transformer 超参数设置列于表 2 的第一行。需要注意的是,TransMorph 的变体(即 TransMorph-Bayes、TransMorph-bspl 和 TransMorph-diff)与 TransMorph 共享相同的 Transformer 设置。每种提出的变体的超参数设置如下:
-
TransMorph:所有任务均使用与 VoxelMorph 相同的损失函数参数。
-
TransMorph-Bayes:所有任务均应用了与 VoxelMorph 相同的损失函数参数。Dropout 概率设置为 0.15。
-
TransMorph-bspl:所有任务的损失函数设置与 VoxelMorph 相同。B 样条变换的控制点间距 δ 也设置为 2,这与 MIDIR 中使用的值相同。
-
TransMorph-diff:我们应用了与 VoxelMorph-diff 相同的损失函数参数。
在本工作中提出的仿射模型包含一个紧凑的 Swin Transformer。该 Transformer 的参数设置与 TransMorph 相同,但嵌入维度设置为 12,Swin Transformer 块的数量设置为 {1,1,2,2},头的数量设置为 {1,1,2,2}。得到的仿射模型总共有 1955 万个参数,计算复杂度为 0.4 GMacs。由于 MRI 数据集在预处理过程中已经进行了仿射对齐,因此仿射模型仅用于 XCAT 到 CT 配准。
5 结果
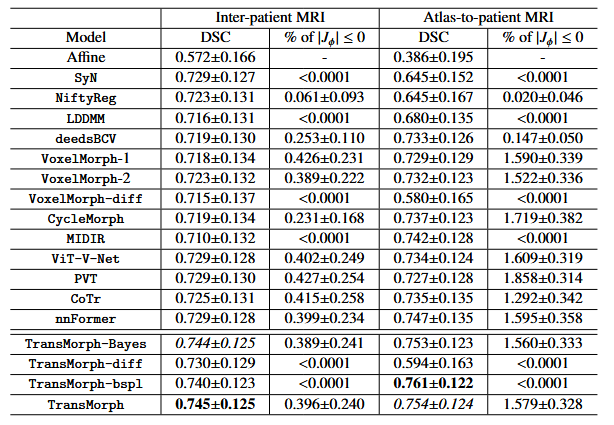
消融结果
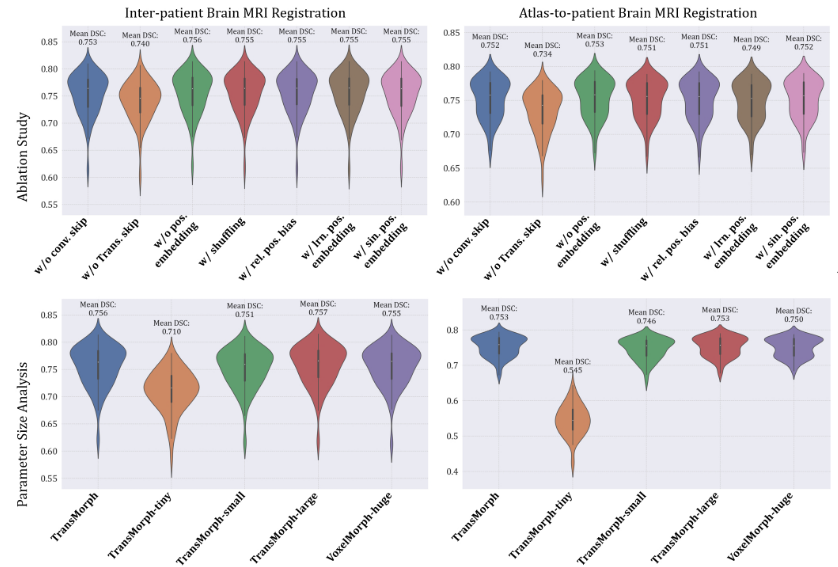
在第五部分中,消融实验的结果揭示了 TransMorph 架构中各个组件对配准性能的影响。以下是主要发现:
1. 跳跃连接(Skip Connections)的影响
-
卷积层跳跃连接:移除卷积层的跳跃连接后,TransMorph 的平均 Dice 分数从 0.756 降至 0.753(如表 1 所示)。这表明卷积层的跳跃连接对配准性能有一定的提升作用,但影响相对较小。
-
Transformer 块跳跃连接:移除 Transformer 块的跳跃连接后,平均 Dice 分数从 0.756 降至 0.740。这说明 Transformer 块的跳跃连接对性能的提升更为显著,尤其是在处理复杂的配准任务时。
结论:跳跃连接,尤其是来自 Transformer 块的跳跃连接,对 TransMorph 的配准性能有显著的正面影响。这些连接有助于网络更好地捕捉图像的细节信息,从而提高配准精度。
2. 位置嵌入(Positional Embedding)的影响
-
无位置嵌入:在不使用任何位置嵌入的情况下,TransMorph 的平均 Dice 分数为 0.755,与使用位置嵌入的版本相当(如表 1 所示)。
-
随机打乱位置:即使在训练和测试过程中随机打乱 token 的位置,TransMorph 仍然能够实现与不使用位置嵌入时相似的性能(平均 Dice 分数为 0.593)。
-
不同位置嵌入方式:无论是使用可学习的位置嵌入、正弦位置嵌入还是相对位置偏差,TransMorph 的性能几乎没有显著差异。
结论:位置嵌入在 TransMorph 中并非必要。网络能够通过解码器中的连续上采样和损失反向传播隐式地学习到 token 的位置信息。因此,位置嵌入的添加并不会显著提升配准性能,反而会增加模型的复杂度。
3. 模型复杂度(Model Complexity)的影响
-
不同模型大小:TransMorph 的不同变体(如 TransMorph-tiny、TransMorph-small 和 TransMorph-large)在参数数量和计算复杂度上有所不同。随着模型复杂度的增加,Dice 分数也有所提高(如表 2 所示)。例如,TransMorph-large 的平均 Dice 分数为 0.757,略高于基础模型 TransMorph(0.756)。
-
与 VoxelMorph-huge 的比较:尽管 VoxelMorph-huge 的参数数量与 TransMorph 相当,但其在所有配准任务中的表现均不如 TransMorph。这表明 TransMorph 的架构设计在处理复杂配准任务时具有明显优势。
结论:模型复杂度对配准性能有一定的影响,但并非唯一决定因素。TransMorph 的架构设计,尤其是结合了 Transformer 和 ConvNet 的混合架构,使其在保持较高性能的同时,能够有效控制计算复杂度。
6.讨论
6.1. TransMorph中的网络组件
6.1.1跳过连接(Skip Connections)
如第 5.5 节所示,跳跃连接有助于提升配准精度。本节进一步探讨跳跃连接的功能。
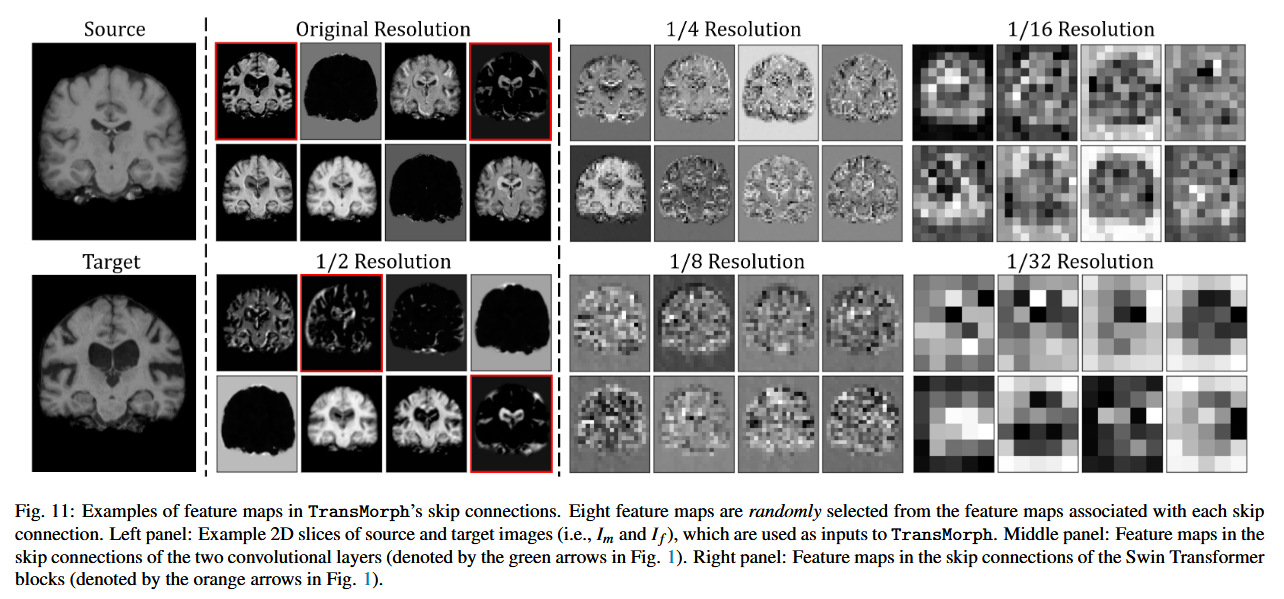
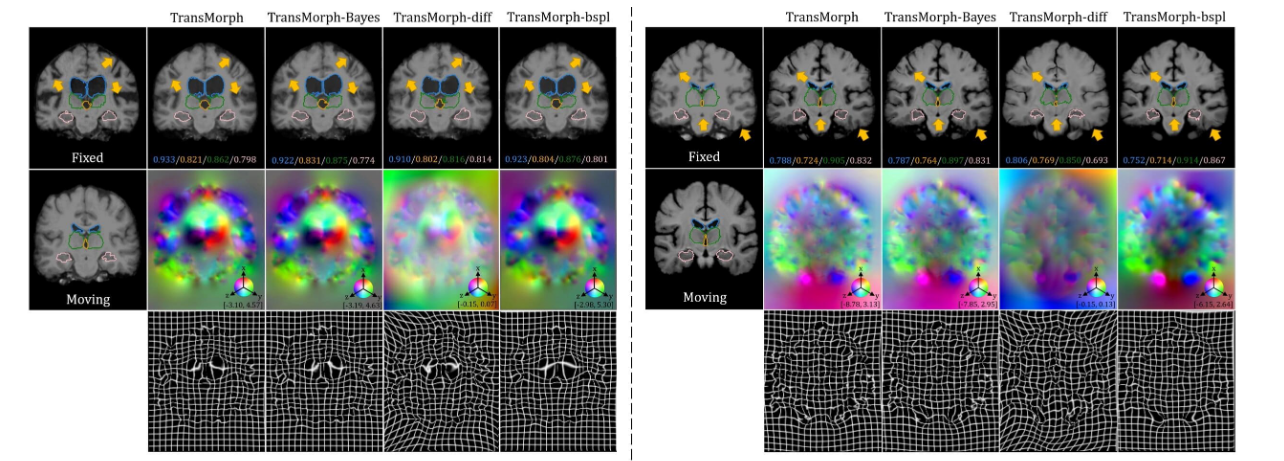
图 11 展示了每个跳跃连接中的一些示例特征图(完整的特征图可视化见附录中的图 G.31)。具体来说,左侧面板显示了输入体积的样本切片;中间面板展示了卷积层跳跃连接中的选定特征图,而右侧面板则展示了 Swin Transformer 块跳跃连接中的选定特征图。从这些特征图可以看出,与卷积层(中间面板)相比,Swin Transformer 块提供了更抽象的信息。由于 Transformer 将输入图像划分为 patch 来创建用于自注意力操作的 token(如第 3.2 节所述),因此它只能提供最高为 patch 大小的一定分辨率的信息(例如,H/P×W/P×L/P,其中 P=4 是我们的 patch 大小)。相比之下,卷积层生成的特征图具有更高的分辨率,并包含更详细且易于人类理解的信息(例如,边缘和边界信息)。某些特征图甚至揭示了活动图像和固定图像之间的差异(用红色框标出)。
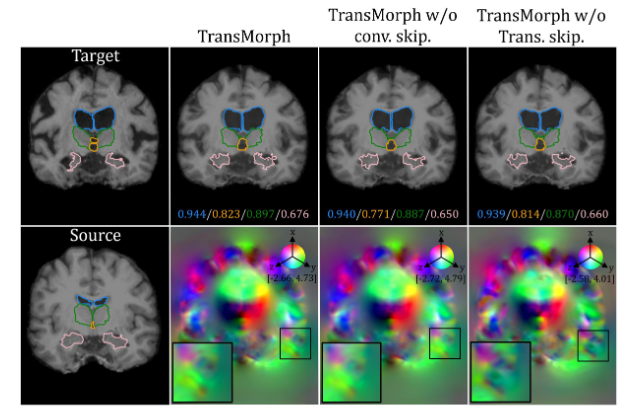
图 12 展示了具有和不具有特定类型跳跃连接的模型之间的定性比较。从放大区域可以看出,带有两种跳跃连接类型的 TransMorph 提供了更详细且更准确的位移场。因此,尽管在验证数据集上实际的 Dice 改进幅度较小(患者间脑部 MRI 配准为 0.003,图谱到患者脑部 MRI 配准为 0.001,XCAT 到 CT 配准为 0.009),但仍然建议添加来自卷积层的跳跃连接。
6.1.2 位置嵌入(Positional Embedding)
最初,计算机视觉中的 Transformer 是为图像分类任务设计的(Dosovitskiy 等人,2020;Liu 等人,2021a;Dong 等人,2021;Wang 等人,2021c)。此类 Transformer 产生的是一个压缩的概率向量,该向量不在图像域中,而是对属于某个类别的可能性的描述。基于该向量计算的损失不会将任何空间信息反向传播到网络中。因此,对 patch token 编码位置信息至关重要,否则,随着网络的加深,Transformer 会丢失 token 相对于输入图像的位置信息,从而导致训练不稳定和预测结果不准确。
然而,对于像素级任务(如图像配准),Transformer 生成的压缩特征通常会通过解码器进行扩展,其输出是与输入和目标图像分辨率相同的图像。输出与目标之间的任何空间不匹配都会对损失做出贡献,而该损失随后会反向传播到整个网络。因此,Transformer 隐式地学习了 token 的位置信息,从而无需位置嵌入。在本工作中,我们在第 5.5 节中比较了有无位置嵌入的 TransMorph 在脑部 MRI 和 XCAT 到 CT 配准中的配准性能。结果显示,位置嵌入并未提升配准性能;相反,它为网络引入了更多参数。在本节中,我们将进一步讨论位置嵌入。
在本研究中,我们探讨了三种位置嵌入:正弦(Vaswani 等人,2017)、可学习(Dosovitskiy 等人,2020)和相对(Liu 等人,2021a)嵌入,这些也是主要的位置嵌入类型。在正弦位置嵌入中,每个 patch token 的位置由根据 token 相对于输入图像的位置从预定义的正弦信号中提取的值来表示。而可学习位置嵌入则允许网络从训练数据集中学习 token 位置的表示,而不是赋予一个硬编码的值。相对位置偏差在查询和键表示的点积中硬编码了任意两个 token 之间的相对位置关系(即公式 (10) 中的 B)。为了验证网络是否学习了位置信息,Dosovitskiy 等人(2020)计算了某个 token 的学习嵌入与其他所有 token 的学习嵌入之间的余弦相似度。然后,使用获得的相似度值形成图像。如果学习到了位置信息,则该图像应反映出 token 及其附近 token 位置之间的相似度增加。

图 13 的左侧面板和右侧面板分别显示了本研究中使用的正弦和可学习位置嵌入的余弦相似度图像。这些图像是基于输入图像大小为 160×192×224 和 patch 大小为 4×4×4(得到 40×48×56 个 patch)生成的。每个图像的大小为 40×48,表示在 z=28(即中间切片)平面上的余弦相似度图像。理论上,每个面板应包含 40×48 张图像。然而,为了更好地可视化,这里仅展示了部分图像。这些图像是以 5 和 8 为步长在 x 和 y 方向上选择的,结果得到 6×5 张图像。从左侧面板可以看出,正弦嵌入的图像呈现出结构化模式,显示出 token 相对位置与图像强度值之间的高度相关性。需要注意的是,每个图像中最亮的像素代表了 token 的位置嵌入与自身的余弦相似度,这反映了 token 相对于所有其他 token 的实际位置。随着距离 token 的位置越来越远,相似度逐渐降低。相比之下,使用可学习嵌入生成的图像(图 13 的右侧面板)缺乏这种结构化模式,表明网络并未在可学习嵌入中学习到与 token 相关的位置信息。为了进一步证明网络隐式地学习了 token 的位置信息,我们在训练和测试过程中随机打乱了计算自注意力时的 token 位置。因此,自注意力模块无法明确感知输入 token 的位置信息。然而,正如图 9 中的 Dice 分数所示,无论是否打乱位置以及使用哪种位置嵌入,平均 Dice 分数和小提琴图都与不使用位置嵌入时相当。因此,这些发现证实了 TransMorph 隐式地学习了 token 的位置信息,而可学习的、正弦的和相对的位置嵌入在模型中是多余的,对配准性能的影响可以忽略不计。
6.2 TransMorph-Bayes 的不确定性量化
-
传统方法的局限性:
基于预测方差的外观不确定性估计存在校准错误,即不确定性值与预测模型误差之间的相关性不足。这是因为传统方法使用预测均值而非目标图像来计算方差,导致不确定性估计不准确。
-
TransMorph-Bayes 的解决方案:
提出直接使用预期模型误差来量化外观不确定性。由于目标图像在配准过程中始终可用,这种方法能够提供完美校准的不确定性估计。
-
实验验证:
使用不确定性校准误差(UCE)量化校准误差,结果显示 TransMorph-Bayes 的不确定性估计与预期模型误差高度一致,实现了完美校准(UCE = 0)。
可视化比较表明,TransMorph-Bayes 捕捉配准失败的能力优于传统方法,显示出更强的相关性。
-
局限性与展望:
尽管 TransMorph-Bayes 在单模态配准中表现出色,但在多模态配准(如 PET 到 CT)中,由于图像外观和体素值差异较大,均方误差(MSE)可能不是最佳的不确定性量化指标。
提议在多模态配准中使用预测方差作为外观不确定性的替代指标,以提高不确定性的估计效果。
6.3 有效感受野(Effective Receptive Fields, ERFs)的比较
本小节通过比较 ConvNet 基模型(如 VoxelMorph)和 Transformer 基模型(如 TransMorph)的有效感受野(ERFs),揭示了两者在处理医学图像配准时感知能力的差异。

-
有效感受野(ERFs)的定义:
有效感受野量化了输入图像中的每个体素对网络输出的影响程度。它通过计算输入体素对输出位移场中心体素的偏导数来衡量,反映了网络对输入图像中不同区域的敏感性。
-
ConvNet 基模型的局限性:
ConvNet 基模型(如 VoxelMorph)由于卷积操作的局部性,其有效感受野在编码阶段非常局部化。即使在网络末端,其有效感受野也主要集中在图像的一小部分,无法全面感知整个输入图像。这限制了 ConvNet 在处理需要大范围空间关系的任务(如大变形配准)时的能力。
-
Transformer 基模型的优势:
Transformer 基模型(如 TransMorph)通过自注意力机制,能够实现更大的有效感受野。在编码阶段,TransMorph 采用较大的核,使得其有效感受野覆盖整个图像。这使得 TransMorph 能够更好地捕捉输入图像中远距离体素之间的空间关系,从而在需要大变形的配准任务中表现更优。
-
实验结果:
通过可视化 VoxelMorph 和 TransMorph 的有效感受野,结果显示 TransMorph 的有效感受野在每个阶段都显著大于 VoxelMorph,并且在解码阶段能够覆盖整个图像。这表明 TransMorph 在处理医学图像配准时具有更强的全局感知能力。
6.4 变形幅度的比较
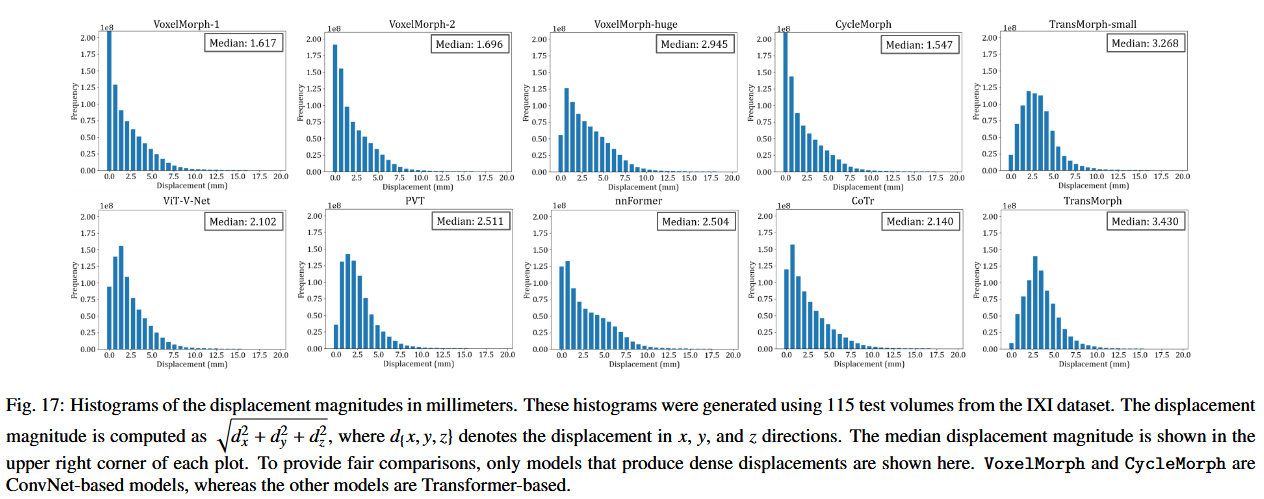
如第 6.3 节所述,TransMorph 的有效感受野(ERFs)比 VoxelMorph 大得多,这可能有助于捕捉语义信息,以应对大变形。在本节中,我们进一步提供证据表明 Transformer 基模型比 ConvNet 基模型更擅长产生大变形。我们使用 IXI 数据集中的 115 个测试体积来生成以毫米为单位的变形幅度直方图。图 17 显示了各种方法的变形幅度直方图。为了进行公平的比较,这里只展示了生成密集变形场的模型。所有模型都在相同的设置下进行训练(例如,损失函数、训练周期数、优化器等),唯一的变量是网络架构。如直方图所示,所有基于 Transformer 的模型产生的变形幅度都比基于 ConvNet 的模型大得多。基于 ConvNet 的模型的变形幅度分布模式接近于 0,且具有更多的小变形。此外,我们还展示了 VoxelMorph-huge 和 TransMorph-small 的直方图,前者有 6325 万个参数,后者有 1176 万个参数。尽管 VoxelMorph-huge 的参数数量大约是 TransMorph-small 的 6 倍,但 VoxelMorph-huge 仍然表现出比 TransMorph-small 更小的变形幅度。这进一步表明,TransMorph 产生的较大变形并非是由于参数数量的增加,而是由于网络架构本身。鉴于上述所示的 Transformer 基模型在改进配准性能方面的优势,这些直方图表明,在需要较大变形的情况下,Transformer 基模型很可能会提供更好的配准效果。
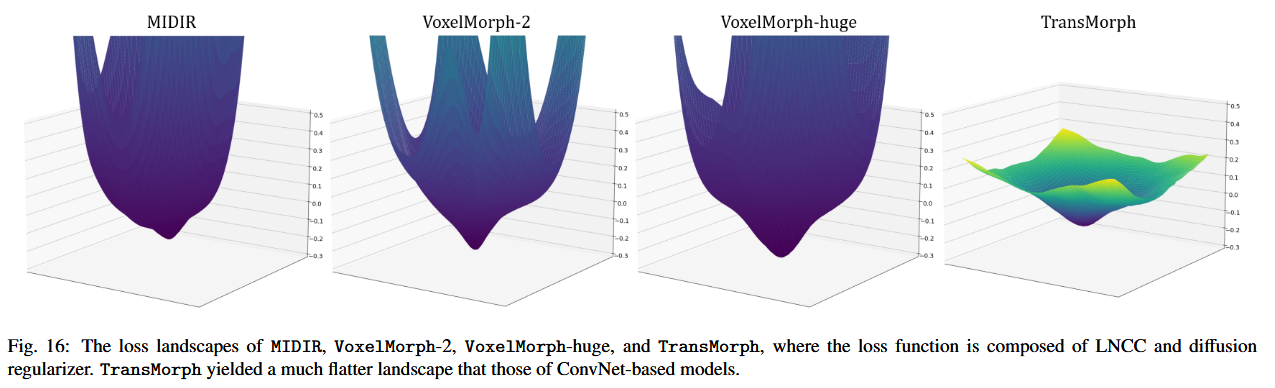
6.5 损失景观的比较
在本节中,我们比较了 TransMorph 和基于 ConvNet 的模型的损失景观。我们采用了在(Li 等人,2018;Goodfellow 等人,2014;Im 等人,2016)中描述的损失景观可视化方法,其中通过在两个随机方向(分别记为 δ 和 η)上扰动一组预训练模型参数(记为 θ),并以步长 α 和 β 来获取不同位置的损失值。基于以下形式的函数绘制损失景观:
f(α,β)=L(θ+αδ+βη),
其中,L 表示由局部归一化交叉相关(LNCC)和扩散正则化组成的损失函数。我们取自图谱到患者配准任务验证集的十个样本的平均损失景观,以获得每个模型的最终三维等高线图。为了比较基于 ConvNet 的模型和 TransMorph,我们创建了 VoxelMorph、MIDIR 和 TransMorph 的损失景观,如图 16 所示。TransMorph 产生了一个比基于 ConvNet 的模型更平坦的损失景观。这一观察结果与(Park 和 Kim,2022)中的发现一致,表明 Transformer 倾向于促进更平坦的损失景观。许多研究表明,更平坦的景观能够带来更好的性能和泛化能力(Park 和 Kim,2022;Keskar 等人,2016;Santurkar 等人,2018;Foret 等人,2020;Li 等人,2018)。TransMorph 的更平坦的损失景观进一步证明了 Transformer 基模型在图像配准中的优势。
6.6 收敛速度和训练效率
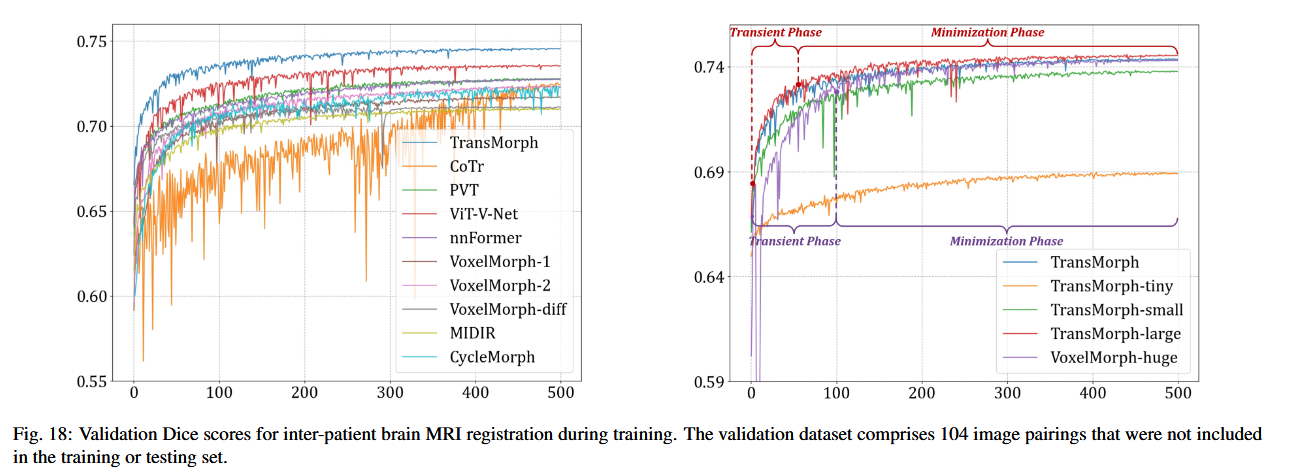
-
TransMorph 在训练初期(前 20 个周期)就迅速达到超过 0.7 的 Dice 分数,表明其在学习图像对空间对应关系方面速度快于其他模型。尽管 TransMorph 和其他基于 Transformer 的模型在参数数量和计算复杂度上相近,但 TransMorph 在所有评估任务中表现更优,这归功于其采用的 Swin Transformer 架构。相比之下,基于 ConvNet 的模型(如 CoTr)在训练过程中验证分数波动较大,收敛困难,这可能是因为其架构设计导致特征传递不畅。
-
TransMorph 变体的“过渡”阶段(确定局部最小值邻域)比 VoxelMorph-huge 更短,意味着它们能更快地找到合适的解空间。这种快速收敛能力使 TransMorph 在训练效率上具有优势,可减少训练周期、时间和计算资源消耗。
-
TransMorph 的训练速度适中,比 VoxelMorph-2 慢 1.5 倍,但比 VoxelMorph-huge 快 0.5 倍。在推理时间上,TransMorph 比 VoxelMorph-huge 快 3 倍,这得益于其较低的计算复杂度(687 GMACs)。基于学习的方法普遍比传统配准方法快,而 TransMorph-Bayes 由于需要进行多次采样以估计不确定性,其推理时间相对较长。
6.7.限制
本研究存在一些限制。首先,对于基线方法,超参数是根据经验确定的,或者是基于原始论文中建议的值,而不是通过广泛的网格搜索来寻找最优超参数。由于训练某些基线方法需要耗费大量时间,以及 GPU 上可用内存有限,我们无法承担进行密集网格搜索的开销。此外,由于本研究引入了一种通用的网络架构用于图像配准,我们专注于架构比较,而不是为损失函数或复杂的训练方法选择最优超参数。然而,所提出的 TransMorph 架构很容易适应,例如使用 CycleMorph(Kim 等人,2021)中使用的循环一致性训练方法,或者(Mok 和 Chung,2020)中提出的对称训练方法。此外,所提出的网络可以与任何配准损失函数结合使用。在未来,我们将探索使用互信息等替代损失函数,以拓展所提方法在多模态配准任务中的潜力。