P22:LSTM-火灾温度预测
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、实现思路
-
数据预处理:
- 读取和可视化数据,对目标特征进行归一化处理。
- 构建输入序列和目标序列,将前8个时间段的数据作为输入(X),第9个时间段的温度数据作为目标(y)。
-
数据集划分:
- 将数据分为训练集和测试集,并将它们转换为 PyTorch 张量。
- 使用 DataLoader 将数据集加载为批次,以便在训练过程中使用。
-
模型构建:
- 定义了一个包含两个 LSTM 层和一个全连接层的神经网络模型。
- 第一个 LSTM 层的输入大小为3(对应三个特征),隐藏层大小为320;第二个 LSTM 层的输入大小为320,隐藏层大小也为320;全连接层将隐藏层的输出映射到1个输出。
-
训练和测试:
- 定义了一个训练函数,使用均方误差(MSE)作为损失函数,随机梯度下降(SGD)作为优化器,并使用余弦退火学习率调度器。
- 定义了一个测试函数,用于在测试集上评估模型的性能。
- 在多个训练周期(epochs)中训练模型,记录训练和测试的损失,并在每个周期结束时调整学习率。
-
结果评估:
- 绘制训练和验证损失曲线,以评估模型的训练效果。
- 使用模型对测试集进行预测,并将预测结果和真实值反归一化,以便进行比较。
- 绘制真实值和预测值的对比图,计算并输出均方根误差(RMSE)和 R² 分数,以评估模型的预测性能。
- MSE 是“均方误差”,用于量化预测值与真实值之间的误差。重点是它是计算每个预测值和真实值的差值的平方,然后取平均值,这样可以放大误差的影响,尤其是当模型在某些点上预测得特别糟糕时,MSE 会显得很有意义。
- R²,它是“决定系数”,通常用来衡量模型对数据变异的解释能力。它有一个关键点,就是它是一个相对指标,范围在 0 到 1 之间,表示模型解释了多少数据的变异,剩下的部分则由随机误差或其他因素决定。R² 的好处在于它能够直观地告诉我们模型的好坏:越接近 1,说明模型越好。
二、前期工作
1. 导入库
import torch.nn.functional as F
import numpy as np
import pandas as pd
import torch
from torch import nn
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import TensorDataset, DataLoader
import copy
import matplotlib.pyplot as plt
from sklearn import metricsfrom datetime import datetime
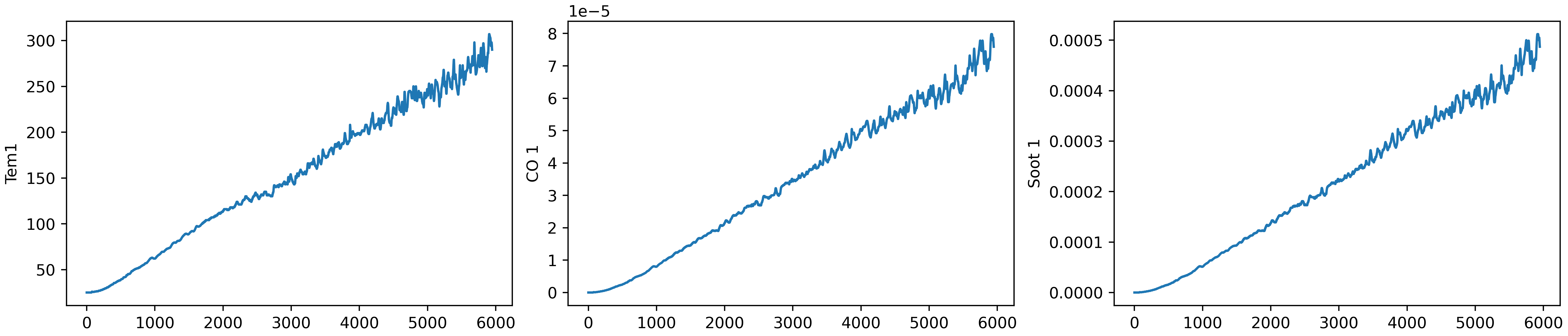
2. 导入数据并可视化
data = pd.read_csv("./data/woodpine2.csv")
plt.rcParams['savefig.dpi'] = 500 #图片像素
plt.rcParams['figure.dpi'] = 500 #分辨率
fig, ax =plt.subplots(1,3,constrained_layout=True, figsize=(14, 3))
sns.lineplot(data=data["Tem1"], ax=ax[0])
sns.lineplot(data=data["CO 1"], ax=ax[1])
sns.lineplot(data=data["Soot 1"], ax=ax[2])
plt.show()
3. 数据预处理
dataFrame = data.iloc[:,1:]dataFrame = data.iloc[:,1:].copy()
sc = MinMaxScaler(feature_range=(0, 1)) #将数据归一化,范围是0到1
for i in ['CO 1', 'Soot 1', 'Tem1']:dataFrame[i] = sc.fit_transform(dataFrame[i].values.reshape(-1, 1))width_X = 8
width_y = 1
##取前8个时间段的Tem1、CO 1、Soot 1为X,第9个时间段的Tem1为y。
X = []
y = []
in_start = 0
for _, _ in data.iterrows():in_end = in_start + width_Xout_end = in_end + width_yif out_end < len(dataFrame):X_ = np.array(dataFrame.iloc[in_start:in_end , ])y_ = np.array(dataFrame.iloc[in_end :out_end, 0])X.append(X_)y.append(y_)in_start += 1
4. 划分数据集
X = np.array(X)
y = np.array(y).reshape(-1,1,1)
X_train = torch.tensor(np.array(X[:5000]), dtype=torch.float32)
y_train = torch.tensor(np.array(y[:5000]), dtype=torch.float32)
X_test = torch.tensor(np.array(X[5000:]), dtype=torch.float32)
y_test = torch.tensor(np.array(y[5000:]), dtype=torch.float32)train_dl = DataLoader(TensorDataset(X_train, y_train),batch_size=64,shuffle=False)test_dl = DataLoader(TensorDataset(X_test, y_test),batch_size=64,shuffle=False)
三、模型训练
1. 构建模型
class model_lstm(nn.Module):def __init__(self):super(model_lstm, self).__init__()self.lstm0 = nn.LSTM(input_size=3 ,hidden_size=320,num_layers=1, batch_first=True)self.lstm1 = nn.LSTM(input_size=320 ,hidden_size=320,num_layers=1, batch_first=True)self.fc0 = nn.Linear(320, 1)def forward(self, x):out, hidden1 = self.lstm0(x)out, _ = self.lstm1(out, hidden1)out = self.fc0(out)return out[:, -1:, :] #取2个预测值,否则经过lstm会得到8*2个预测model = model_lstm()
print(model)
model_lstm((lstm0): LSTM(3, 320, batch_first=True)(lstm1): LSTM(320, 320, batch_first=True)(fc0): Linear(in_features=320, out_features=1, bias=True)
)
2.训练函数
def train(train_dl, model, loss_fn, opt, lr_scheduler=None):size = len(train_dl.dataset)num_batches = len(train_dl)train_loss = 0 # 初始化训练损失和正确率for x, y in train_dl:x, y = x.to(device), y.to(device)# 计算预测误差pred = model(x) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距# 反向传播opt.zero_grad() # grad属性归零loss.backward() # 反向传播opt.step() # 每一步自动更新# 记录losstrain_loss += loss.item()if lr_scheduler is not None:lr_scheduler.step()print("learning rate = {:.5f}".format(opt.param_groups[0]['lr']), end=" ")train_loss /= num_batchesreturn train_loss3. 测试函数
def test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小num_batches = len(dataloader) # 批次数目test_loss = 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for x, y in dataloader:x, y = x.to(device), y.to(device)# 计算lossy_pred = model(x)loss = loss_fn(y_pred, y)test_loss += loss.item()test_loss /= num_batchesreturn test_loss
4.模型训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = model_lstm()model = model.to(device)loss_fn = nn.MSELoss() # 创建损失函数learn_rate = 1e-1 # 学习率opt = torch.optim.SGD(model.parameters(),lr=learn_rate,weight_decay=1e-4)epochs = 50train_loss = []test_loss = []lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(opt,epochs, last_epoch=-1)for epoch in range(epochs):model.train()epoch_train_loss = train(train_dl, model, loss_fn, opt, lr_scheduler)model.eval()epoch_test_loss = test(test_dl, model, loss_fn)train_loss.append(epoch_train_loss)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_loss:{:.5f}, Test_loss:{:.5f}')print(template.format(epoch+1, epoch_train_loss, epoch_test_loss))print("="*20, 'Done', "="*20)
learning rate = 0.09990 Epoch: 1, Train_loss:0.00120, Test_loss:0.00318
learning rate = 0.09961 Epoch: 2, Train_loss:0.01379, Test_loss:0.00306
learning rate = 0.09911 Epoch: 3, Train_loss:0.01342, Test_loss:0.00294
learning rate = 0.09843 Epoch: 4, Train_loss:0.01302, Test_loss:0.00281
learning rate = 0.09755 Epoch: 5, Train_loss:0.01256, Test_loss:0.00267
learning rate = 0.09649 Epoch: 6, Train_loss:0.01202, Test_loss:0.00252
learning rate = 0.09524 Epoch: 7, Train_loss:0.01141, Test_loss:0.00235
learning rate = 0.09382 Epoch: 8, Train_loss:0.01070, Test_loss:0.00217
learning rate = 0.09222 Epoch: 9, Train_loss:0.00989, Test_loss:0.00197
learning rate = 0.09045 Epoch:10, Train_loss:0.00898, Test_loss:0.00177
learning rate = 0.08853 Epoch:11, Train_loss:0.00800, Test_loss:0.00155
learning rate = 0.08645 Epoch:12, Train_loss:0.00697, Test_loss:0.00133
learning rate = 0.08423 Epoch:13, Train_loss:0.00592, Test_loss:0.00112
learning rate = 0.08187 Epoch:14, Train_loss:0.00489, Test_loss:0.00092
learning rate = 0.07939 Epoch:15, Train_loss:0.00394, Test_loss:0.00074
learning rate = 0.07679 Epoch:16, Train_loss:0.00309, Test_loss:0.00058
learning rate = 0.07409 Epoch:17, Train_loss:0.00236, Test_loss:0.00045
learning rate = 0.07129 Epoch:18, Train_loss:0.00177, Test_loss:0.00034
learning rate = 0.06841 Epoch:19, Train_loss:0.00131, Test_loss:0.00026
learning rate = 0.06545 Epoch:20, Train_loss:0.00096, Test_loss:0.00020
learning rate = 0.06243 Epoch:21, Train_loss:0.00070, Test_loss:0.00015
learning rate = 0.05937 Epoch:22, Train_loss:0.00052, Test_loss:0.00012
learning rate = 0.05627 Epoch:23, Train_loss:0.00039, Test_loss:0.00009
learning rate = 0.05314 Epoch:24, Train_loss:0.00030, Test_loss:0.00007
learning rate = 0.05000 Epoch:25, Train_loss:0.00024, Test_loss:0.00006
learning rate = 0.04686 Epoch:26, Train_loss:0.00020, Test_loss:0.00005
learning rate = 0.04373 Epoch:27, Train_loss:0.00017, Test_loss:0.00004
learning rate = 0.04063 Epoch:28, Train_loss:0.00015, Test_loss:0.00004
learning rate = 0.03757 Epoch:29, Train_loss:0.00013, Test_loss:0.00003
learning rate = 0.03455 Epoch:30, Train_loss:0.00013, Test_loss:0.00003
learning rate = 0.03159 Epoch:31, Train_loss:0.00012, Test_loss:0.00003
learning rate = 0.02871 Epoch:32, Train_loss:0.00012, Test_loss:0.00002
learning rate = 0.02591 Epoch:33, Train_loss:0.00011, Test_loss:0.00002
learning rate = 0.02321 Epoch:34, Train_loss:0.00011, Test_loss:0.00002
learning rate = 0.02061 Epoch:35, Train_loss:0.00011, Test_loss:0.00002
learning rate = 0.01813 Epoch:36, Train_loss:0.00012, Test_loss:0.00002
learning rate = 0.01577 Epoch:37, Train_loss:0.00012, Test_loss:0.00002
learning rate = 0.01355 Epoch:38, Train_loss:0.00012, Test_loss:0.00002
learning rate = 0.01147 Epoch:39, Train_loss:0.00013, Test_loss:0.00002
learning rate = 0.00955 Epoch:40, Train_loss:0.00013, Test_loss:0.00002
learning rate = 0.00778 Epoch:41, Train_loss:0.00013, Test_loss:0.00002
learning rate = 0.00618 Epoch:42, Train_loss:0.00014, Test_loss:0.00003
learning rate = 0.00476 Epoch:43, Train_loss:0.00014, Test_loss:0.00003
learning rate = 0.00351 Epoch:44, Train_loss:0.00014, Test_loss:0.00003
learning rate = 0.00245 Epoch:45, Train_loss:0.00014, Test_loss:0.00003
learning rate = 0.00157 Epoch:46, Train_loss:0.00014, Test_loss:0.00003
learning rate = 0.00089 Epoch:47, Train_loss:0.00014, Test_loss:0.00003
learning rate = 0.00039 Epoch:48, Train_loss:0.00014, Test_loss:0.00003
learning rate = 0.00010 Epoch:49, Train_loss:0.00014, Test_loss:0.00003
learning rate = 0.00000 Epoch:50, Train_loss:0.00014, Test_loss:0.00003
四、模型评估
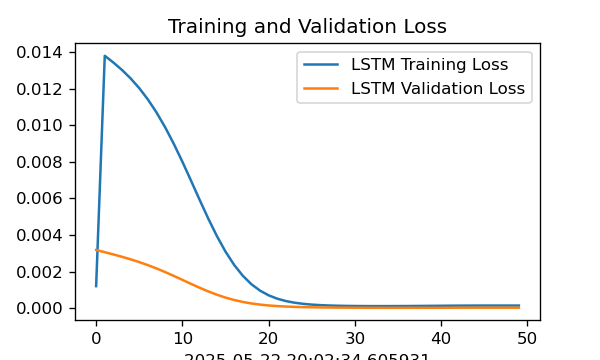
1.损失函数图
current_time = datetime.now() # 获取当前时间plt.figure(figsize=(5, 3),dpi=120)plt.plot(train_loss , label='LSTM Training Loss')plt.plot(test_loss, label='LSTM Validation Loss')plt.title('Training and Validation Loss')plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效plt.legend()plt.show()
2. 调用函数进行预测
predicted_y_lstm = sc.inverse_transform(model(X_test).detach().numpy().reshape(-1,1)) # 测试集输入模型进行预测
y_test_1 = sc.inverse_transform(y_test.reshape(-1,1))
y_test_one = [i[0] for i in y_test_1]
predicted_y_lstm_one = [i[0] for i in predicted_y_lstm]
plt.figure(figsize=(5, 3),dpi=120)
# 画出真实数据和预测数据的对比曲线
plt.plot(y_test_one[:2000], color='red', label='real_temp')
plt.plot(predicted_y_lstm_one[:2000], color='blue', label='prediction')
plt.title('Title')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.show()
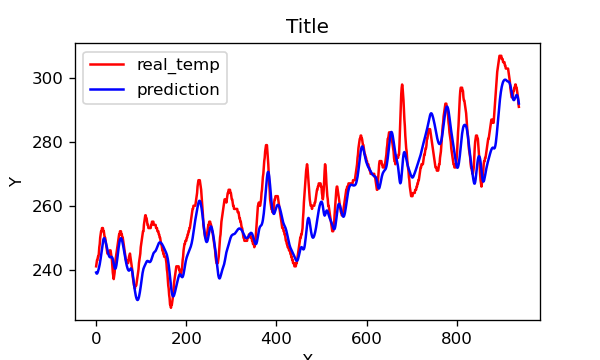
3. 均方根误差
RMSE_lstm = metrics.mean_squared_error(predicted_y_lstm_one, y_test_1) ** 0.5
R2_lstm = metrics.r2_score(predicted_y_lstm_one, y_test_1)print('均方根误差: %.5f' % RMSE_lstm)
print('R2: %.5f' % R2_lstm)
均方根误差: 7.19289
R2: 0.81598