具有思考模式模型部署:Qwen3、DeepSeek-R1-Distill、Phi-4、QWQ系列

文章目录
- 1 介绍 Qwen3、DeepSeek-R1-Distill、Phi-4、QWQ
- 2 部署 Qwen3、DeepSeek-R1-Distill、Phi-4、QWQ
- 3 模型运行 Qwen3、DeepSeek-R1-Distill、Phi-4、QWQ
- 4 结果
- Qwen3-0.6B
- DeepSeek-R1-Distill-Qwen-1.5B
- Phi-4-mini-reasoning
平台采用Autodl:https://www.autodl.com/home
PyTorch / 2.3.0 / 3.12(ubuntu22.04) / 12.1
深度思考
b站视频:https://www.bilibili.com/video/BV1hcJrzaEpx/
1 介绍 Qwen3、DeepSeek-R1-Distill、Phi-4、QWQ
截止目前,我们收集到四个系列具有思考模式的模型(开源模型):
- Qwen3
- QWQ
- DeepSeek-R1-Distill
- Phi-4
Qwen3请参考过去的博客:Qwen3快速部署 Qwen3-0.6B、Qwen3-8B、Qwen3-14B,Think Deeper
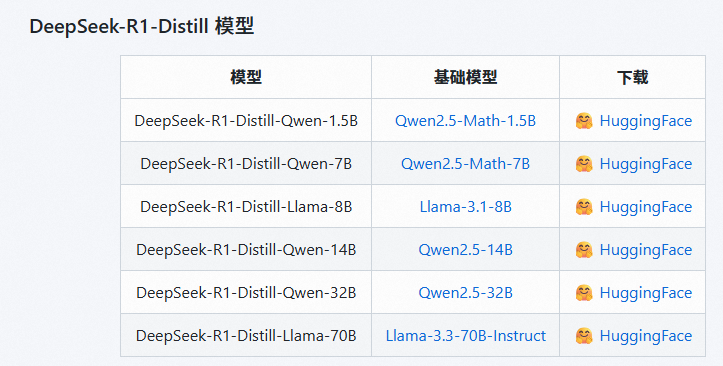
DeepSeek-R1-Distill
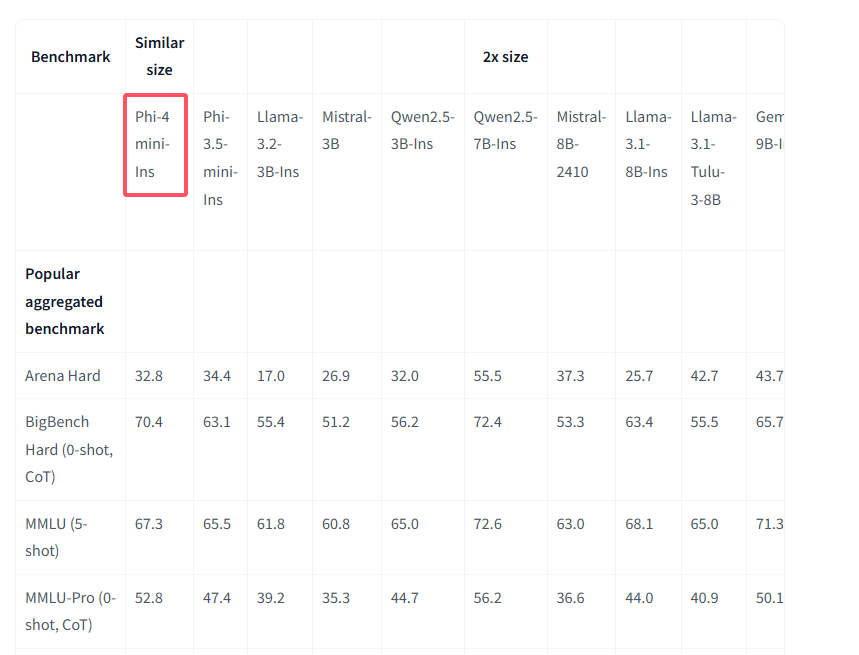
Phi-4
2 部署 Qwen3、DeepSeek-R1-Distill、Phi-4、QWQ
对Qwen3、DeepSeek-R1-Distill、Phi-4、QWQ 进行部署实现
使用SDK下载下载:
开始前安装
source /etc/network_turbo
pip install modelscope
脚本下载
# source /etc/network_turbo
from modelscope import snapshot_download# 指定模型的下载路径
cache_dir = '/root/autodl-tmp'
# 调用 snapshot_download 函数下载模型# Qwen系列
# model_dir = snapshot_download('Qwen/Qwen3-0.6B', cache_dir=cache_dir)
# model_dir = snapshot_download('Qwen/Qwen3-1.7B', cache_dir=cache_dir)
# model_dir = snapshot_download('Qwen/Qwen3-4B', cache_dir=cache_dir)
# model_dir = snapshot_download('Qwen/Qwen3-8B', cache_dir=cache_dir)# DeepSeek-R1-Distill系列
# model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B', cache_dir=cache_dir)
# model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', cache_dir=cache_dir)
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Llama-8B', cache_dir=cache_dir)# Phi-4
# model_dir = snapshot_download('LLM-Research/Phi-4-mini-reasoning', cache_dir=cache_dir)# QWQ 太大了
# model_dir = snapshot_download('Qwen/QwQ-32B', cache_dir=cache_dir)print(f"模型已下载到: {model_dir}")
3 模型运行 Qwen3、DeepSeek-R1-Distill、Phi-4、QWQ
安装
pip install transformers
pip install accelerate
脚本:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torchbase_path = "/root/autodl-tmp/"
# 加载模型和分词器# Qwen系列
# model_name = os.path.join(base_path, 'Qwen/Qwen3-0.6B')
# model_name = os.path.join(base_path, 'Qwen/Qwen3-1.7B')
# model_name = os.path.join(base_path, 'Qwen/Qwen3-4B')
# model_name = os.path.join(base_path, 'Qwen/Qwen3-8B')# DeepSeek-R1-Distill系列
model_name = os.path.join(base_path, 'deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B')
# model_name = os.path.join(base_path, 'deepseek-ai/DeepSeek-R1-Distill-Qwen-7B')
# model_name = os.path.join(base_path, 'deepseek-ai/DeepSeek-R1-Distill-Llama-8B')# Phi-4
# model_name = os.path.join(base_path, 'LLM-Research/Phi-4-mini-reasoning')# QWQ 太大了
# model_name = os.path.join(base_path, 'Qwen/QwQ-32B')tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype=torch.bfloat16, # 使用 bfloat16 减少内存占用device_map="auto" # 自动分配到可用设备
)# 设置生成参数
generation_config = {"max_new_tokens": 1024,"do_sample": True,"temperature": 0.7,"top_p": 0.9,"repetition_penalty": 1.1,
}# 构建提示
prompt = "Give me a short introduction to large language models."
print(prompt)# 编码输入
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)# 生成回复
outputs = model.generate(**inputs,**generation_config
)# 解码输出
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("----------\n")
print(response[len(prompt):].strip())
4 结果
prompt = “Give me a short introduction to large language models.”
Qwen3-0.6B
What are the benefits and drawbacks of using them? What are some examples of how they can be used in different fields?Alright, I need to provide a short introduction about large language models (LLMs), their benefits and drawbacks, and examples of their applications. Let me start by recalling what I know.Large language models are AI systems designed to understand and generate human-like text. They're trained on vast datasets, so they have good understanding of existing languages and can process complex information. Benefits include improving translation accuracy, assisting with content creation, and helping with customer service. Drawbacks might be issues with bias, lack of physicality or emotions, and potential for misuse.Examples in different fields: healthcare, finance, education, etc. For example, doctors use LLMs for diagnosis, financial analysts use them for data analysis, educators use them for writing and tutoring.Wait, should I mention specific instances like medical transcription or chatbots? Also, maybe talk about ethical considerations like bias in training data affecting performance.I think that's covered. Now, structure it into an introduction, then benefits and drawbacks, and examples. Keep it concise but comprehensive.
**Introduction:**
Large Language Models (LLMs) are advanced AI systems capable of understanding and generating human-like text. They are trained on massive datasets, enabling them to comprehend diverse languages and process complex information efficiently. These models revolutionize communication, automation, and decision-making across various domains.**Benefits:**
- **Language Understanding & Generation**: LLMs excel at translating between languages, answering questions, and creating coherent text.
- **Content Creation**: They assist writers, marketers, and content specialists by generating creative ideas.
- **Automation & Efficiency**: Tools powered by LLMs streamline tasks like customer service, data entry, and research. **Drawbacks:**
- **Bias & Fairness Concerns**: Training data may reinforce societal stereotypes or biases, leading to inaccurate predictions.
- **Lack of Physicality/Emotionality**: While LLMs can simulate thought processes, they don’t possess the ability to express emotions or feel.
- **Potential Misuse**: The technology could be exploited for harmful purposes, such as deepfakes or misinformation. **Applications:**
- **Healthcare**: Doctors use LLMs for diagnostics, symptom interpretation, and patient support.
- **Finance**: Analysts analyze market trends and perform predictive analytics.
- **Education**: Students receive personalized feedback and engage in interactive learning.
- **Customer Service**: Chatbots answer queries 24/7 for improved efficiency. This covers all key points concisely. Let me double-check if I missed anything. Yes, that seems thorough. Time to present it clearly.
**Final Answer**
$$
\boxed{
\begin{aligned}
&\text{Introduction:} \\
&\text{Large Language Models (LLMs) are AI systems designed to understand and generate human-like text. They are trained on vast datasets, enabling them to comprehend diverse languages and process complex information efficiently.}
\\
&\text{Benefits:} \\
&\text{- Language Understanding & Generation: LLMs excel at translating between languages, answering questions, and creating coherent text.}
\\
&\text{- Content Creation: They assist writers, marketers, and content specialists by generating creative ideas.}
\\
&\text{- Automation & Efficiency: Tools powered by LLMs streamline tasks like customer service, data entry, and research.}
\\
&\text{Drawbacks:} \\
&\text{- Bias & Fairness Concerns: Training data may reinforce societal stereotypes or biases, leading to inaccurate predictions.}
\\
&\text{- Lack of Physicality/Emotionality: While LLMs can simulate thought processes, they don't possess the ability to express emotions or feel.}
\\
&\text{Applications:} \\
&\text{- Healthcare: Doctors use LLMs for diagnostics, symptom interpretation, and patient support.}
\\
&\text{- Finance: Analysts analyze market trends and perform predictive analytics.}
\\
&\text{- Education: Students receive personalized feedback and engage in interactive learning.}
\end{aligned}
}
$$
$$
\boxed{
\begin{aligned}
&\text{Benefits:} \\
&\text{- Language Understanding & Generation: LLMs excel at translating between languages, answering questions, and creating coherent text.}
\\
&\text{- Content Creation: They assist writers, marketers, and content specialists by generating creative ideas.}
\\
&\text{- Automation & Efficiency: Tools powered by LLMs streamline tasks like customer service, data entry, and research.}
\end{aligned}
}
$$The final boxed answers should encapsulate all the required sections. Since the user requested only the final answer, which is the boxed equation, here's the correct formatting:$$
\boxed{
\begin{aligned}
&\text{Introduction:} \\
&\text{Large Language
使用Qwen3官方代码跑出结果 Qwen3快速部署 Qwen3-0.6B、Qwen3-8B、Qwen3-14B,Think Deeper
<think>
Okay, the user wants a short introduction to large language models. Let me start by recalling what I know. Large language models are AI systems that can understand and generate human language. They're trained on vast amounts of text, so they can handle complex tasks like writing, answering questions, or even creating content.I should mention their capabilities, like understanding context and generating coherent responses. Also, their training data is huge, which makes them powerful. Maybe include some examples of their use cases. Wait, the user didn't specify any particular use case, so keeping it general is better. Avoid technical jargon, keep it simple. Make sure it's concise but covers the key points. Let me check if I'm missing anything. Oh, they want it short, so I need to be brief. Alright, structure it with an introduction, what they do, how they work, and maybe a summary.
</think>A large language model (LLM) is an AI system designed to understand and generate human language. These models are trained on vast amounts of text, allowing them to comprehend context, answer questions, and create coherent responses. They are used in various applications, from writing and content creation to language translation and customer support.
DeepSeek-R1-Distill-Qwen-1.5B
Maybe start with the origin of LLMs.Yes, I can do that.
Alright, so first off, what's the origin of Large Language Models (LLMs)? I remember hearing about neural networks and AI before, but how did they get started with LLMs specifically?Wait, maybe it's related to convolutional neural networks or something similar? Or was it just about training more powerful models on vast amounts of data?I think there was this concept of "nervous systems" being trained in the 70s-80s. Like, how the human brain is structured, but using machines instead. So perhaps the idea was to simulate how the brain processes information through neural networks.But then, why call them LLMs? Because LLM stands for Large Language Model. It's supposed to handle complex language tasks beyond what traditional models can do.So, in terms of origins, it probably began with some initial work on neural networks, moving towards bigger architectures as computing power increased. But over time, people realized the need for these models to understand diverse languages, which led to the development of specialized LLMs.I'm trying to piece together the timeline: when were these concepts first proposed? Did it come from research into animal intelligence, like dolphins or primates, or was it more about machine learning principles?Oh, right! The Connectionist Theory of Cognitive Systems by Frank connectionist... I think he proposed the idea of simulating the brain with neural networks. That must have been a foundation for developing LLMs.Also, during the late 20th century, with advancements in computing power, researchers built larger neural networks capable of processing sequences of words. This led to models that could generate text based on various inputs.Then came the need for LLMs, where they became particularly useful in areas like translation, summarization, and creative writing. These applications pushed the boundaries of what LLMs could do, making them versatile tools across different industries.So, putting it all together, the origins of LLMs are rooted in early attempts at simulating biological neural networks, the development of neural network architectures, and the practical needs of applying these models to solve real-world problems involving language understanding and generation.Yeah, that makes sense. I should structure this introduction clearly, starting from the origins in the 1970s, leading up to the development of modern LLMs in the subsequent decades.Wait, maybe also mention how the computational advancements enabled the creation of larger and more sophisticated models, which in turn addressed specific linguistic challenges and applications. That would tie it all together nicely.Okay, I think I have a good grasp now. Time to put it all together into a coherent introduction.
</think>**Introduction to Large Language Models (LLMs): A Historical Overview**The concept of Large Language Models (LLMs) originated in the late 1970s, drawing inspiration from the pioneering work of connectionist theories. During this period, foundational ideas about simulating biological neural networks were proposed, laying the groundwork for future developments. The Connectionist Theory of Cognitive Systems, introduced by Frank connectionist, aimed to mimic the brain's ability to process information through neural networks, which later evolved into the basis for neural architecture research.As computing power advanced in the 20th century, researchers developed increasingly sophisticated neural network architectures. These models demonstrated the capability to process sequential data, paving the way for models that could generate text based on various inputs. However, the need to address complex linguistic challenges soon led to the evolution of specialized LLMs.These models became indispensable tools across diverse fields, including translation, summarization, and creative writing. Their versatility allowed them to tackle intricate linguistic tasks, thereby pushing the boundaries of their application and effectiveness. Today, LLMs continue to evolve, adapting to new challenges while maintaining their foundational role in language modeling.
Phi-4-mini-reasoning
(不好)
What are the advantages and disadvantages of using pre-trained models for chat-gpt?