回溯法理论基础 LeetCode 77. 组合 LeetCode 216.组合总和III LeetCode 17.电话号码的字母组合
目录
回溯法理论基础
回溯法
回溯法的效率
用回溯法解决的问题
如何理解回溯法
回溯法模板
LeetCode 77. 组合
回溯算法的剪枝操作
LeetCode 216.组合总和III
LeetCode 17.电话号码的字母组合
回溯法理论基础
回溯法
回溯法也可以叫做回溯搜索法,它是一种搜索的方式。回溯一般与递归相辅相成,并在递归后进行使用。回溯法是一种暴力搜索方法,你可以想象你现在在走迷宫,当你走到一个死路后,是否需要回退,而回退的这个过程就是回溯。
回溯法的效率
正如上面所说,回溯法是暴力搜索方法,其本质是穷举,穷举所有可能,然后选出我们想要的答案。如果想让回溯法高效一些,可以加一些剪枝的操作,但也改不了回溯法就是穷举的本质。
用回溯法解决的问题
那么既然回溯法并不高效为什么还要用它呢? 因为没得选,一些问题能暴力搜出来就不错了,撑死了再剪枝一下,还没有更高效的解法。
那什么问题适合用回溯法进行解决?
- 组合问题:N个数里面按一定规则找出k个数的集合
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 棋盘问题:N皇后,解数独等等
需要特别说明下组合和排列的问题,组合是没有顺序的,排列是有顺序,比如一对男女朋友,这是一个组合,但你问到他们之间谁先表白,这就变成排列了。
如何理解回溯法
回溯法解决的问题都可以抽象为树形结构。
因为回溯法解决的都是在集合中递归查找子集,集合的大小就构成了树的宽度,递归的深度就构成了树的深度。有递归,就必须要有终止条件,所以必然是一棵高度有限的树(N叉树)。
回溯法模板
回溯法也有模板,在将其模版前,复习下递归的模板。
- 终止条件
- 递归顺序
- 输入参数和输出参数
回溯法模板。
1.回溯函数终止条件
既然回溯可以抽象为树形结构,那么也像递归二叉树那样存在终止条件。什么时候达到了终止条件,树中就可以看出,一般来说搜到叶子节点了,也就找到了满足条件的一条答案,把这个答案存放起来,并结束本层递归。
回溯函数终止条件伪代码如下:
if (终止条件) {存放结果;return;
}2.回溯搜索的遍历过程
在上面我们提到了,回溯法一般是在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成的树的深度。
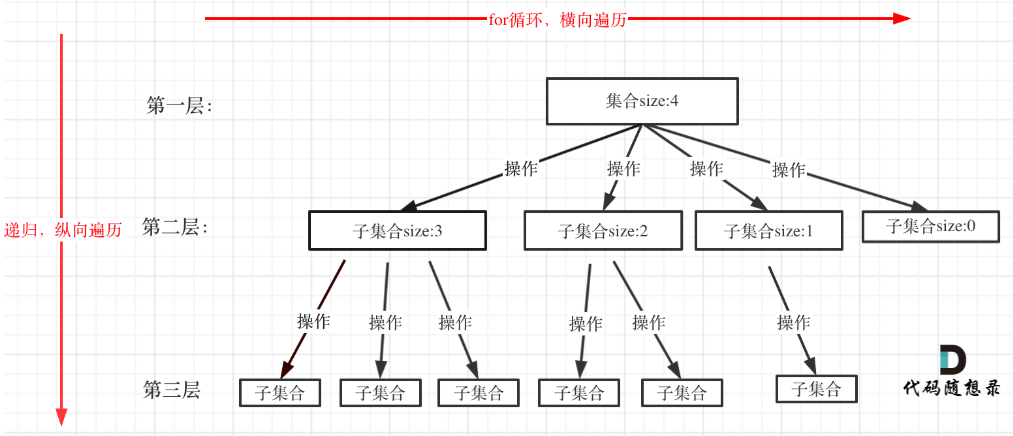
上图是特意举例集合大小和孩子的数量是相等的。size为4的集合有4个子集合。
回溯函数遍历过程伪代码如下:
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯,撤销处理结果
}for循环就是遍历集合区间,可以理解一个节点有多少个孩子,这个for循环就执行多少次。
backtracking这里自己调用自己,实现递归。
大家可以从图中看出for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历,这样就把这棵树全遍历完了,一般来说,搜索叶子节点就是找的其中一个结果了。
3.回溯函数模板返回值以及参数
回溯算法中函数返回值一般为void。
回溯算法需要的参数可不像二叉树递归的时候那么容易一次性确定下来,所以一般是先写逻辑,然后需要什么参数,就填什么参数。
回溯函数伪代码如下:
void backtracking(参数)回溯算法模板框架如下:
void backtracking(参数) {if (终止条件) {存放结果;return;}for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯,撤销处理结果}
}涉及回溯算法的题都可以基于上述模板进行实现,回溯算法模板 + 题目特性 → 解决回溯算法问题
LeetCode 77. 组合
为什么要用回溯算法,你用两个for循环也可以做到,第一个循环从左到右逐个遍历,第二个从第一个循环的下标的下一个位置开始遍历,这样的话也可以做到,时间复杂度是O(),那如果是k越大呢?此时不就需要更多个循环了吗,那此时时间复杂度就是
,显然时间复杂度太高。
回溯方法的做法其实就是用递归来替代循环。
思路:
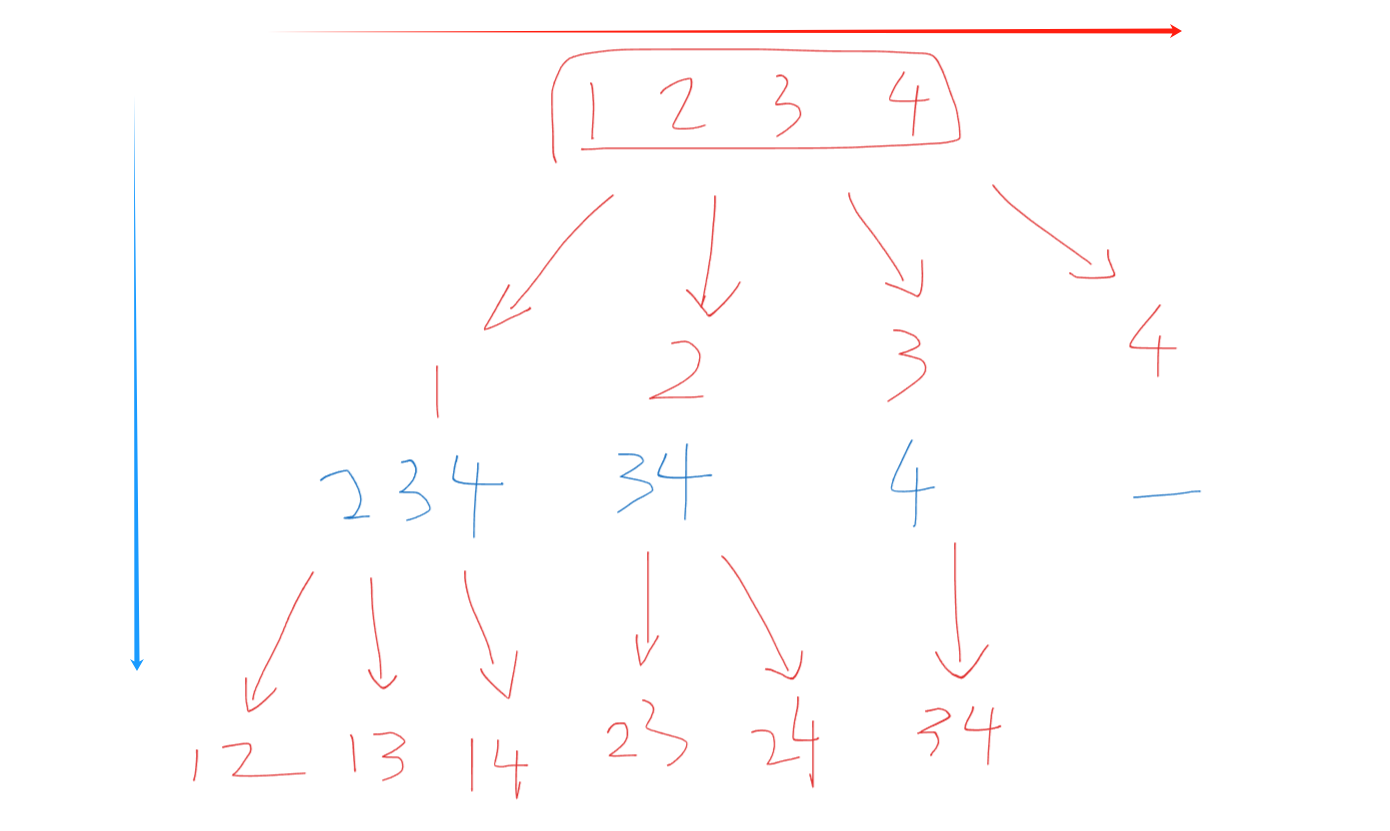
- 通过for循环横向遍历起始处理节点(红箭头)
- 通过递归深度遍历可能出现的组合(蓝箭头)
- 递归后进行回溯
- 当组合长度 == k 时,为终止条件
手撕Code
class Solution(object):def combine(self, n, k):""":type n: int:type k: int:rtype: List[List[int]]"""self.result = [] ## 二维数组self.path = []self.backtracking(n, k, 1)return self.resultdef backtracking(self, n, k, start_index):"""n 记录需要处理到的最大数字k 记录需要输出的数组数目start_index 记录当前处理的数字, 遍历范围是1到n"""### 终止条件if len(self.path) == k:# self.result.append(self.path) ### 这里是将指针给append了,self.path的内容是一直在变的,如果你将指针append的话,上一轮的递归的结果并没有进行保存,因为上一轮指向的数组已经变了。self.result.append(list(self.path))return### 递归逻辑for _ in range(start_index, n+1): ### 左闭右开self.path.append(start_index) ### 当前处理节点。处理同一层的逻辑self.backtracking(n, k, start_index + 1) ### 递归,往深度遍历。self.path.pop() ### 递归后进行回溯start_index += 1 ### 处理完当前节点后,处理下一个节点易错点:
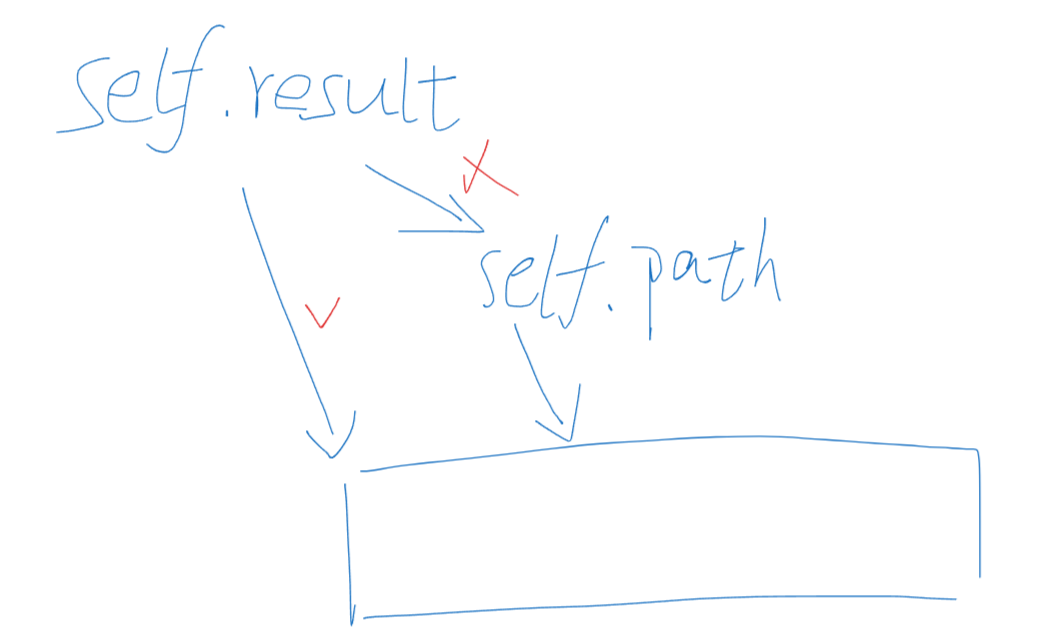
不能是self.result.append(self.path) ,这部分append只是当前self.path指针所指向的当前数组元素,如果self.path当前指向的数组是[1,3],上一轮self.result已经将[1,2]给存进去了,此时如果你要将[1,3]数组进行append,你应该append是这个数组,而不应该是这个指针,即你想要的结果是[ [1,2], [1,3] ],如果你是append这个指针的话,只会添加当前指针指向的数组,因为你存储的其实是指向当前数组的指针,即[ self.path, self.path ],再进行下一轮的append操作后,其实你获取的是[ [1,3], [1,3] ]。指针指向的是不断在变的数组,如果你存指针的话,最终的self.result只会是存储操作完毕后该指针下的元素,没有记录整个过程。
总结:当你在终止条件 if len(self.path) == k: 中执行 self.result.append(self.path) 时,你并没有将 self.path 当前的内容复制一份,而是将 self.path 这个列表对象本身的引用添加到了 self.result 中。
回溯算法的剪枝操作
体现在for循环范围的限制。如还是组合问题,现在k变了,变为4。
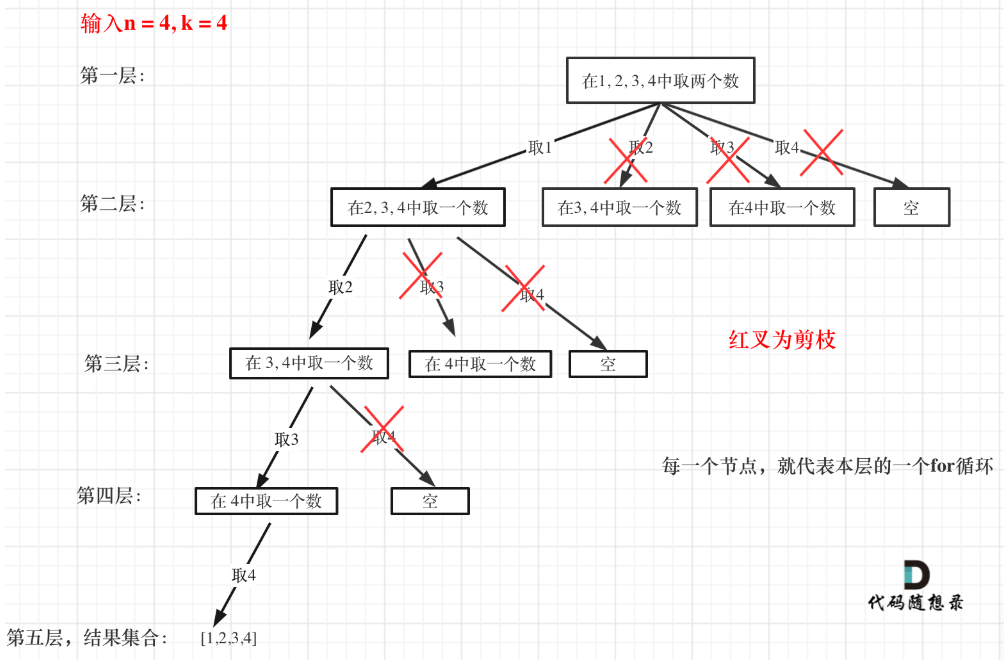
那么我们可以看到由于元素只有4个,因此只有从元素1开始的遍历才能得到最终符合数目为k的组合,而其他子树的遍历是不需要的,因为肯定数目是不符合的。那如果k是3呢?是不是只有从1开始和从2开始进行遍历才是有效的,且其子遍历中,有些分支也可以进行去掉,从而减少遍历的操作,这是与通过多个循环暴力搜索法相比所体现出的优势。
那要如何优化以实现剪枝呢?其实答案就体现在for循环范围的控制。优化过程如下:
i = start_index,表示处理节点的起始位置。
- 已经选择的元素个数:path.size();
- 所需需要的元素个数为: k - path.size();
- 列表中剩余元素(n-i) >= 所需需要的元素个数(k - path.size())
- 在集合n中至多要从该起始位置 : i <= n - (k - path.size()) + 1,开始遍历。
根据3得到的是 i <= n - (k - path.size()) ,为什么要+1?因为包括起始位置,我们要是一个左闭的集合。
这个优化条件 i <= n - (k - path.size()) + 1 实际上是在说: "当前的起始位置 i 必须小于或等于这样一个值:从这个值开始,到最大的元素 n 结束,能够恰好凑齐我们所需要的 k - path.size() 个元素,并且还考虑到起始位置 i 本身也算一个元素。"
n-i 是 指包含起始位置之后的列表元素个数,当n-i = k - path.size()时,此时有临界条件,i = n - (k - path.size),这表示i为这个值时,当前元素+后续元素刚好是符合k - path.size()的。但我们要的临界条件是i到了什么值时,后续遍历操作可以不用执行,因此要加1,1是表明i = n - (k - path.size)时,后序的元素可以进行遍历,再往后的就不用了。
举个例子,n = 4,k = 3, 目前已经选取的元素为0(path.size为0),n - (k - 0) + 1 即 4 - ( 3 - 0) + 1 = 2。表示最大的符合条件在当第二个元素开始时。因此,从2开始。
class Solution(object):def combine(self, n, k):""":type n: int:type k: int:rtype: List[List[int]]"""self.result = [] ## 二维数组self.path = []self.backtracking(n, k, 1)return self.resultdef backtracking(self, n, k, start_index):"""n 记录需要处理到的最大数字k 记录需要输出的数组数目start_index 记录当前处理的数字, 遍历范围是1到n"""### 终止条件if len(self.path) == k:# self.result.append(self.path) ### 这里是将指针给append了,self.path的内容是一直在变的,如果你将指针append的话,上一轮的递归的结果并没有进行保存,因为上一轮指向的数组已经变了。self.result.append(list(self.path))returnfor _ in range(start_index, (n -(k-len(self.path))+1) +1): ### 剪枝操作self.path.append(start_index) self.backtracking(n, k, start_index + 1) self.path.pop() start_index += 1 LeetCode 216.组合总和III
思路
- 与LeetCode组合类似,只不过这里是求和,判断是否有满足数目的path == sum
- 思路基本一致,注意循环中不要忘了对start_index进行修改。
手撕Code
class Solution(object):def combinationSum3(self, k, n):""":type k: int:type n: int:rtype: List[List[int]]"""self.result = []self.path = []self.nums = []for i in range(1,10):self.nums.append(i) ### 创建一个数组用于存储用于遍历的数字self.backtracking(0, k, n)return self.resultdef backtracking(self, start_index, k, n):if len(self.path) == k:sum = 0for i in range(len(self.path)):sum += self.path[i]if sum == n:self.result.append(list(self.path))returnfor _ in range(start_index, len(self.nums)-(k-len(self.path)) +1):self.path.append(self.nums[start_index])self.backtracking(start_index+1, k, n)self.path.pop()start_index += 1LeetCode 17.电话号码的字母组合
思路1 —— 朴实无华
- 分级处理思想,之前操作是都是在同一个数组内,现在是多个数组,那只要修改回溯函数对应的输入和处理方法就行。具体地,输入两个数组,第一个数组进行横向遍历,第二个数据进行遍历。为什么在一个集合里使用start_index,是为了实现去重操作;在多个集合的操作,多个集合无交集的情况下,直接从0开始遍历,不用考虑去重操作。
- 针对k=2时,传入两个数组就可以直接处理。而针对k=3,需要将k=2时的处理结果拿出来后,作为新的数组,与第三个数组输入到回溯函数中,从而实现k=3的计算逻辑。
- k=4也是类似,就是逐步将前面的输出结果作为新的输入与下一个进行计算。
上述这种思路,跟用循环进行实现没什么区别了,没体现回溯的特点。另外,在处理数字为1的时候要注意,字符串不是像数组那般可以进行修改,因此当遇到1时,直接跳过就行,可以用一个new_digits来存储对旧digits进行判断修改后的结果。
class Solution(object):def letterCombinations(self, digits):""":type digits: str:rtype: List[str]"""### 采用一个Hashmap存储对应数字和字母的关系### 对输入的数字进行判断已获得其对应的字母hash_map = dict()hash_map[2] = ['a','b','c']hash_map[3] = ['d','e','f']hash_map[4] = ['g','h','i']hash_map[5] = ['j','k','l']hash_map[6] = ['m','n','o']hash_map[7] = ['p','q','r', 's']hash_map[8] = ['t','u','v']hash_map[9] = ['w','x','y', 'z']### 构造一个函数,第一个数组作为横向遍历,第二个数组作为纵向遍历self.result = []self.path = [] k = len(digits)# left = right = 0 #### python中的字符串是无法直接修改的,因此碰到1的话,应该是选择跳过,而不是进行修改# while right < k: # if digits[left] != '1':# left += 1# right += 1# elif digits[left] == '1':# right += 1# digits[left] = digits[right] cur = 0digits_list = []while cur < k:if digits[cur] != '1':digits_list.append(digits[cur])cur += 1new_digits = ''.join(digits_list)k = len(new_digits)if k == 0:return self.resultif k == 1:return hash_map[int(digits[0])]first_str = hash_map[int(digits[0])]second_str = hash_map[int(digits[1])]if k == 2:self.backtracking(0, first_str, second_str, k)if k == 3:self.backtracking(0, first_str, second_str, 2)first_second_str = list(self.result)self.result = []third_str = hash_map[int(digits[2])]self.backtracking(0, first_second_str, third_str, 2)if k == 4:self.backtracking(0, first_str, second_str, 2)first_second_str = list(self.result)self.result = []third_str = hash_map[int(digits[2])]first_str = self.backtracking(0, first_second_str, third_str, 2)first_second_third_str = list(self.result)self.result = []forth_str = hash_map[int(digits[3])]self.backtracking(0, first_second_third_str, forth_str, 2)return self.resultdef backtracking(self, start_index, first_str, second_str, k):"""first_str : 第一个字符串数组,横向遍历second_str : 第二个字符串数组,深度遍历k : path的长度 == digits.length"""if len(self.path) == k:path_str = ''.join(self.path)self.result.append(path_str)returnfor _ in range(start_index, len(first_str)):self.path.append(first_str[start_index])self.backtracking(0, second_str, None, k)self.path.pop()start_index += 1 思路2:
- 关键还是在对回溯的理解,回溯的结构可以抽象成一颗树,在单个集合中,你是将单个元素分到树的每一层中。现在是多个集合,其实也就是把单个集合分到树的每一层中。
- 在了解上述思想后,我们就可以设计index了,index表示的是digits的长度,其长度决定了有几个集合,有N个集合就决定了有N-1个回溯递归的深度(因为第一个是横向遍历)。
Code
class Solution(object):def letterCombinations(self, digits):""":type digits: str:rtype: List[str]"""self.letterMap = [ ### 一个一维数组,数字的大小刚好对应去在数组中去获得该数字对应字符串的下标"", # 0"", # 1"abc", # 2"def", # 3"ghi", # 4"jkl", # 5"mno", # 6"pqrs", # 7"tuv", # 8"wxyz" # 9]self.result = []self.path = []new_digits = []for dig in digits: ### 判断数字是否在[2,9]之内,如果有不存在的需要进行删除if dig != '1' or dig != '0':new_digits.append(dig)new_digits = "".join(new_digits)length = len(new_digits) ### 数字的长度index = 0 ### 树的深度if length == 0:return self.resultself.backtracking(index, new_digits, length)return self.resultdef backtracking(self, index, new_digits, length):if index == length:self.result.append("".join(list(self.path)))return ### 终止条件cur = int(new_digits[index]) ### 当前处理的数字cur_str = self.letterMap[cur] ### 当前处理的数字 对应的字符串for i in range (len(cur_str)):self.path.append(cur_str[i])self.backtracking(index+1, new_digits, length)self.path.pop()# index += 1 注意,在self.path.pop()之后,index不需要+1,与start_index进行区分开来。start_index + 1是为了获得一个数组中后续的元素。而在不同的集合中,你index是操作不同集合,index为0传进后是第一层,如何往下进行深度遍历操作,已经在index+1作为输入参数进行输入时已经确定了,后序递归结束时,重新执行for循环,进行横向遍历,再一步递归去深度遍历。